ChinaTravel: An Open-Ended Travel Planning Benchmark with Compositional Constraint Validation for Language Agents
Pith reviewed 2026-05-23 07:06 UTC · model grok-4.3
The pith
ChinaTravel introduces an open-ended travel planning benchmark that uses a compositionally generalizable DSL to validate agent plans against real human queries, showing neuro-symbolic methods reach 37 percent constraint satisfaction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
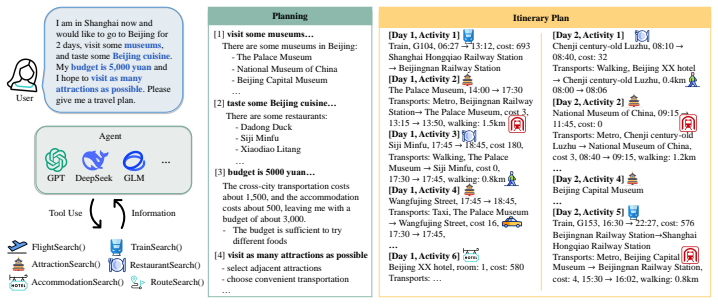
ChinaTravel supplies a practical multi-POI sandbox, a compositionally generalizable DSL that validates plans on feasibility, constraint satisfaction, and preference comparison, and an open-ended dataset of diverse travel requirements collected from 1154 human participants. On this dataset neuro-symbolic agents attain 37.0 percent constraint satisfaction, a 10× gain over purely neural models, yet both approaches exhibit substantial remaining difficulty with compositional generalization.
What carries the argument
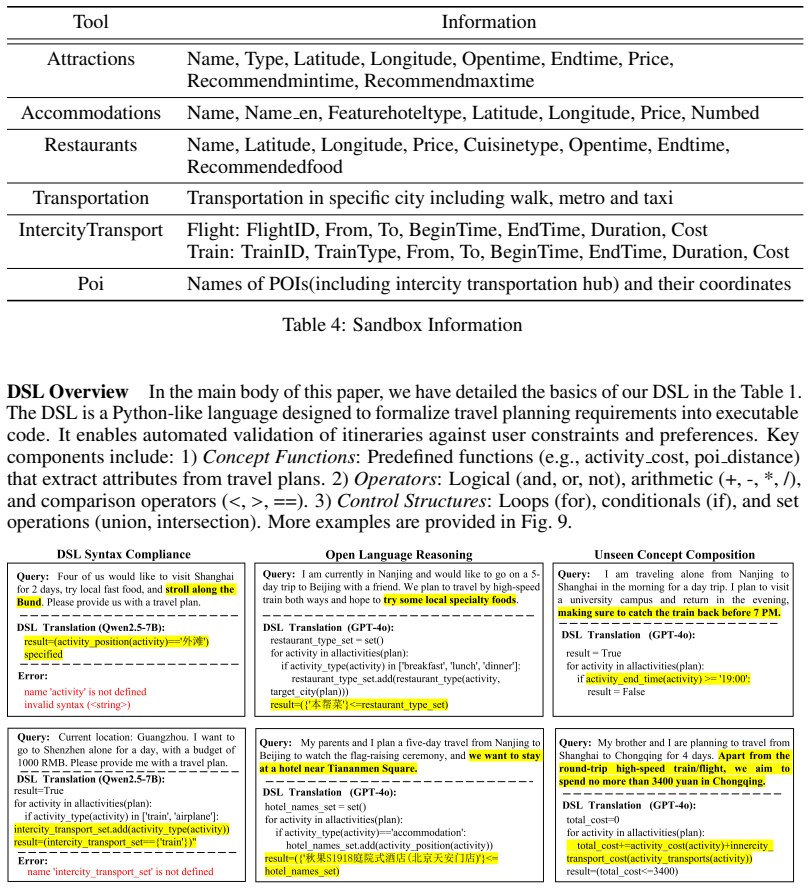
The compositionally generalizable domain-specific language (DSL) that performs scalable validation of feasibility, constraint satisfaction, and preference comparison for multi-day travel plans.
If this is right
- Neuro-symbolic agents satisfy complex, implicit constraints in open-ended planning tasks at markedly higher rates than neural-only agents.
- Purely neural models remain far below usable performance on realistic travel queries that combine multiple implicit requirements.
- Compositional generalization continues to limit agent reliability even after neuro-symbolic integration.
- The benchmark enables fine-grained measurement of how well agents handle feasibility checks, hard constraints, and preference ordering in one unified framework.
Where Pith is reading between the lines
- The same DSL validation pattern could be adapted to other constraint-heavy agent domains such as logistics routing or event scheduling.
- Extending the DSL to capture additional forms of implicit user intent would likely raise measured satisfaction rates further.
- The observed tenfold gain indicates that hybrid symbolic-neural designs merit targeted investment for practical deployment of planning agents.
Load-bearing premise
The DSL fully and correctly represents the feasibility, constraint satisfaction, and preference requirements present in the human travel queries.
What would settle it
A collection of human travel queries in which plans that satisfy user intent are rejected by the DSL rules, or plans accepted by the DSL fail to satisfy user intent.
Figures


















read the original abstract
Travel planning stands out among real-world applications of \emph{Language Agents} because it couples significant practical demand with a rigorous constraint-satisfaction challenge. However, existing benchmarks primarily operate on a slot-filling paradigm, restricting agents to synthetic queries with pre-defined constraint menus, which fails to capture the open-ended nature of natural language interaction, where user requirements are compositional, diverse, and often implicitly expressed. To address this gap, we introduce \emph{ChinaTravel}, with four key contributions: 1) a practical sandbox aligned with the multi-day, multi-POI travel planning, 2) a compositionally generalizable domain-specific language (DSL) for scalable evaluation, covering feasibility, constraint satisfaction, and preference comparison 3) an open-ended dataset that integrates diverse travel requirements and implicit intent from 1154 human participants, and 4) fine-grained analysis reveal the potential of neuro-symbolic agents in travel planning, achieving a 37.0% constraint satisfaction rate on human queries, a 10 \times improvement over purely neural models, yet highlighting significant challenges in compositional generalization. Overall, ChinaTravel provides a foundation for advancing language agents through compositional constraint validation in complex, real-world planning scenarios. Project Page: https://www.lamda.nju.edu.cn/shaojj/ChinaTravel/index.html
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ChinaTravel, a benchmark for language agents on open-ended multi-day travel planning. It contributes a practical sandbox, a compositionally generalizable DSL for validating feasibility, constraint satisfaction, and preference comparison, an open-ended dataset collected from 1154 human participants capturing diverse and implicit requirements, and an evaluation showing neuro-symbolic agents reach 37.0% constraint satisfaction (10× over purely neural baselines) while exposing compositional generalization challenges.
Significance. If the DSL faithfully encodes the collected human intents, the benchmark would fill a clear gap between slot-filling synthetic queries and realistic compositional planning, supplying the community with an executable validation layer, reproducible sandbox, and human-derived test cases. The project page and open resources are explicit strengths that support follow-on work on neuro-symbolic methods.
major comments (2)
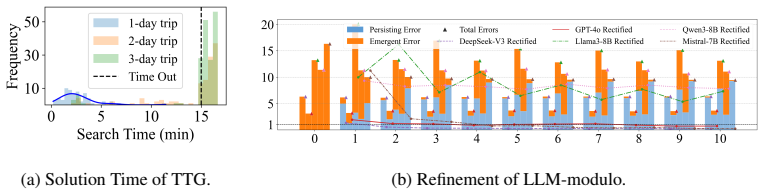
- [DSL definition and dataset construction (§3–4)] The 37.0% constraint satisfaction rate and 10× improvement are obtained by executing the DSL on the 1154 human queries (abstract and §4). The manuscript states that the DSL covers feasibility, constraint satisfaction, and preference comparison and is compositionally generalizable, yet reports no quantitative validation (inter-annotator agreement, coverage audit, or human-DSL alignment study) that every implicit requirement is correctly and completely encoded. This is load-bearing: any non-trivial mismatch between the DSL and the original participant intents directly undermines both the absolute performance number and the relative gain claimed for neuro-symbolic agents.
- [Experimental comparison (§5)] §5 (experimental results): the comparison between neuro-symbolic and purely neural models does not state whether the neural baselines received equivalent prompt-engineering effort, identical model sizes, or the same number of inference calls. Because the 10× claim is central to the significance paragraph, the absence of these controls leaves open the possibility that the gap is partly attributable to implementation differences rather than architectural paradigm.
minor comments (2)
- [Results tables] Table 2 or the corresponding results table: clarify whether the reported percentages are macro-averaged across queries or micro-averaged across individual constraints; the distinction affects interpretation of compositional generalization.
- [Reproducibility statement] The project page is referenced but the manuscript does not list the exact commit hash or version of the released code and DSL interpreter used to produce the numbers in §5.
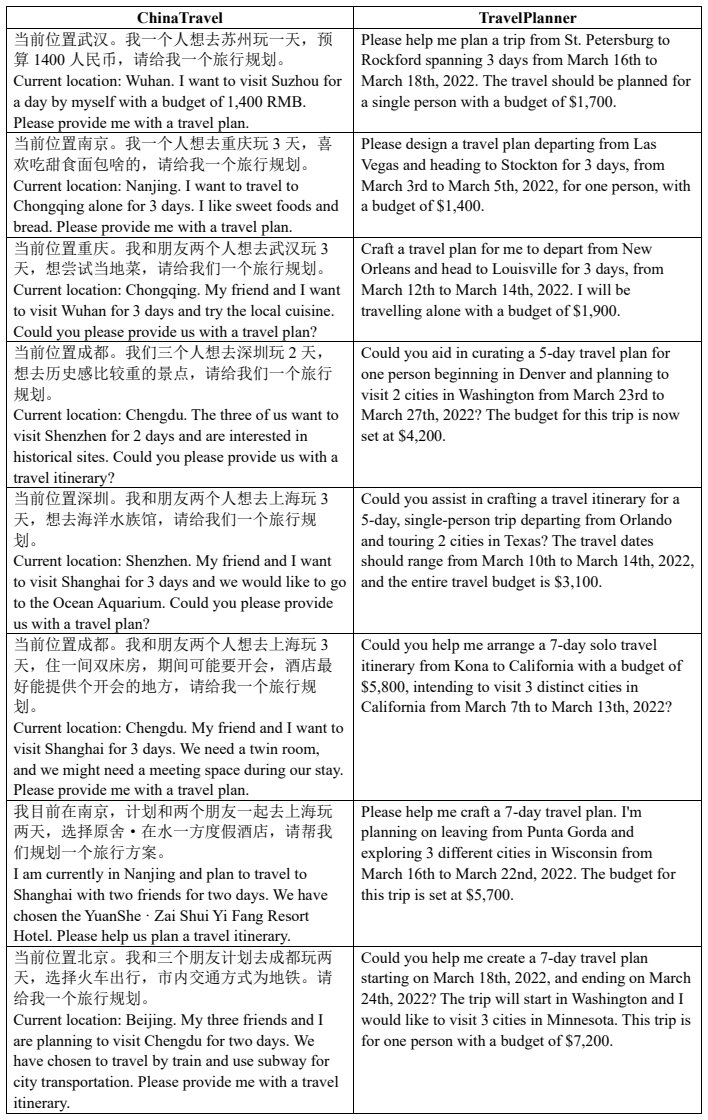
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of benchmark reliability and experimental fairness. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [DSL definition and dataset construction (§3–4)] The 37.0% constraint satisfaction rate and 10× improvement are obtained by executing the DSL on the 1154 human queries (abstract and §4). The manuscript states that the DSL covers feasibility, constraint satisfaction, and preference comparison and is compositionally generalizable, yet reports no quantitative validation (inter-annotator agreement, coverage audit, or human-DSL alignment study) that every implicit requirement is correctly and completely encoded. This is load-bearing: any non-trivial mismatch between the DSL and the original participant intents directly undermines both the absolute performance number and the relative gain claimed for neuro-symbolic agents.
Authors: We agree that the absence of quantitative validation metrics for DSL-human alignment is a limitation that affects the strength of the reported results. The DSL was constructed iteratively from the 1154 human queries to encode implicit and compositional requirements, but no inter-annotator agreement or alignment audit was included in the original submission. In the revised manuscript we will add a new subsection in §4 reporting a human-DSL alignment study on a stratified sample of 150 queries (including inter-annotator agreement, coverage statistics, and discrepancy analysis), along with any adjustments made to the DSL based on that study. revision: yes
-
Referee: [Experimental comparison (§5)] §5 (experimental results): the comparison between neuro-symbolic and purely neural models does not state whether the neural baselines received equivalent prompt-engineering effort, identical model sizes, or the same number of inference calls. Because the 10× claim is central to the significance paragraph, the absence of these controls leaves open the possibility that the gap is partly attributable to implementation differences rather than architectural paradigm.
Authors: We acknowledge that the original §5 did not explicitly document the prompt-engineering effort, model sizes, and inference budgets applied to the neural baselines. All neural baselines used the same base models (GPT-4 and Llama-3-70B) as the neuro-symbolic variants, with prompt templates optimized via the same number of development iterations; inference call counts were matched for the core planning step, though neuro-symbolic agents incur additional symbolic verification calls. In the revised manuscript we will expand §5 with a dedicated paragraph and table detailing model sizes, prompt strategies, and exact inference budgets for each baseline to enable direct comparison. revision: yes
Circularity Check
No significant circularity; empirical benchmark with independent DSL and dataset contributions
full rationale
The paper introduces a new sandbox, DSL, and human-collected dataset for travel planning evaluation, then reports direct empirical results (37% constraint satisfaction for neuro-symbolic agents). No equations, fitted parameters, or derivations are present that reduce reported metrics to quantities defined inside the paper. The DSL is presented as a novel contribution covering feasibility and constraints, not derived from or equivalent to prior self-citations or ansatzes. Performance numbers arise from executing agents on the collected queries rather than any self-referential construction. This is a standard benchmark release whose central claims rest on external human data and agent runs, not internal tautologies.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Travel planning tasks can be faithfully represented and validated using a compositionally generalizable domain-specific language covering feasibility, constraint satisfaction, and preference comparison.
Forward citations
Cited by 1 Pith paper
-
Decoupled Travel Planning with Behavior Forest
Behavior Forest decouples multi-constraint travel planning into parallel behavior trees with LLM nodes and global coordination, yielding 6.67% and 11.82% gains over prior methods on two benchmarks.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Zipf’s law and the internet.Glottometrics, 3(1): 143–150, 2002
Lada A Adamic and Bernardo A Huberman. Zipf’s law and the internet.Glottometrics, 3(1): 143–150, 2002
work page 2002
-
[3]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwi...
work page 1901
-
[4]
Deep blue.Artificial intelligence, 134(1-2):57–83, 2002
Murray Campbell, A Joseph Hoane Jr, and Feng-hsiung Hsu. Deep blue.Artificial intelligence, 134(1-2):57–83, 2002
work page 2002
-
[5]
TravelAgent: An AI assistant for personalized travel planning.arXiv preprint arXiv:2409.08069, 2024
Aili Chen, Xuyang Ge, Ziquan Fu, Yanghua Xiao, and Jiangjie Chen. TravelAgent: An AI assistant for personalized travel planning.arXiv preprint arXiv:2409.08069, 2024
-
[6]
Bridging machine learning and logical reasoning by abductive learning
Wang-Zhou Dai, Qiu-Ling Xu, Yang Yu, and Zhi-Hua Zhou. Bridging machine learning and logical reasoning by abductive learning. InAdvances in Neural Information Processing Systems, pages 2811–2822, 2019
work page 2019
-
[7]
Enhancing and evaluating logical reasoning abilities of large language models
Shujie Deng, Honghua Dong, and Xujie Si. Enhancing and evaluating logical reasoning abilities of large language models. InProceedings of the ICLR 2024 Workshop on Secure and Trustworthy Large Language Models, 2024
work page 2024
-
[8]
Ambros Gleixner, Gregor Hendel, Gerald Gamrath, Tobias Achterberg, Michael Bastubbe, Timo Berthold, Philipp Christophel, Kati Jarck, Thorsten Koch, Jeff Linderoth, et al. Miplib 2017: data-driven compilation of the 6th mixed-integer programming library.Mathematical Programming Computation, 13(3):443–490, 2021
work page 2017
-
[9]
Atharva Gundawar, Mudit Verma, Lin Guan, Karthik Valmeekam, Siddhant Bhambri, and Subbarao Kambhampati. Robust planning with llm-modulo framework: Case study in travel planning.arXiv preprint arXiv:2405.20625, 2024
-
[10]
Visual programming: Compositional visual reasoning without training
Tanmay Gupta and Aniruddha Kembhavi. Visual programming: Compositional visual reasoning without training. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14953–14962, 2023
work page 2023
-
[11]
Sajal Halder, Kwan Hui Lim, Jeffrey Chan, and Xiuzhen Zhang. A survey on personalized itinerary recommendation: From optimisation to deep learning.Applied Soft Computing, 152: 111200, 2024
work page 2024
-
[12]
Large language models can solve real-world planning rigorously with formal verification tools
Yilun Hao, Yongchao Chen, Yang Zhang, and Chuchu Fan. Large language models can solve real-world planning rigorously with formal verification tools. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics, Albuquerque, New Mexico, 2025. 10
work page 2025
-
[13]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. Swe-bench: Can language models resolve real-world github issues? In Proceedings of the 12th International Conference on Learning Representations, 2024
work page 2024
-
[14]
To the globe (ttg): Towards language- driven guaranteed travel planning
Da Ju, Song Jiang, Andrew Cohen, Aaron Foss, Sasha Mitts, Arman Zharmagambetov, Brandon Amos, Xian Li, Justine Kao, Maryam Fazel-Zarandi, et al. To the globe (ttg): Towards language- driven guaranteed travel planning. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 240–249, 2024
work page 2024
-
[15]
Position: Llms can’t plan, but can help planning in llm-modulo frameworks
Subbarao Kambhampati, Karthik Valmeekam, Lin Guan, Mudit Verma, Kaya Stechly, Siddhant Bhambri, Lucas Saldyt, and Anil Murthy. Position: Llms can’t plan, but can help planning in llm-modulo frameworks. InForty-first International Conference on Machine Learning, Vienna, Austria, 2024
work page 2024
-
[16]
Learning planning abstractions from language
Weiyu Liu, Geng Chen, Joy Hsu, Jiayuan Mao, and Jiajun Wu. Learning planning abstractions from language. InProceedings of the 12th International Conference on Learning Representa- tions, 2024
work page 2024
-
[17]
Deepproblog: Neural probabilistic logic programming
Robin Manhaeve, Sebastijan Dumancic, Angelika Kimmig, Thomas Demeester, and Luc De Raedt. Deepproblog: Neural probabilistic logic programming. InAdvances in Neural Informa- tion Processing Systems, pages 3753–3763, 2018
work page 2018
-
[18]
Playing Atari with Deep Reinforcement Learning
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin A. Riedmiller. Playing Atari with deep reinforcement learning.CoRR, abs/1312.5602, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[19]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human fee...
work page 2022
-
[20]
Logic-LM: Empowering large language models with symbolic solvers for faithful logical reasoning
Liangming Pan, Alon Albalak, Xinyi Wang, and William Yang Wang. Logic-LM: Empowering large language models with symbolic solvers for faithful logical reasoning. InFindings of the Association for Computational Linguistics: EMNLP, pages 3806–3824, 2023
work page 2023
-
[21]
Vibhor Sharma, Monika Goyal, and Drishti Malik. An intelligent behaviour shown by chatbot system.International Journal of New Technology and Research, 3(4):263312, 2017
work page 2017
-
[22]
Re- flexion: language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Re- flexion: language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[23]
Lillicrap, Fan Hui, Laurent Sifre, George van den Driessche, Thore Graepel, and Demis Hassabis
David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, Yutian Chen, Timothy P. Lillicrap, Fan Hui, Laurent Sifre, George van den Driessche, Thore Graepel, and Demis Hassabis. Mastering the game of Go without human knowledge.Nature, 550(7676):354–359, 2017
work page 2017
-
[24]
Yihong Tang, Zhaokai Wang, Ao Qu, Yihao Yan, Kebing Hou, Dingyi Zhuang, Xiaotong Guo, Jinhua Zhao, Zhan Zhao, and Wei Ma. Synergizing spatial optimization with large language models for open-domain urban itinerary planning.CoRR, abs/2402.07204, 2024
-
[25]
Po-Wei Wang, Priya L. Donti, Bryan Wilder, and J. Zico Kolter. SATNet: Bridging deep learning and logical reasoning using a differentiable satisfiability solver. InProceedings of the 36th International Conference on Machine Learning, pages 6545–6554, 2019
work page 2019
-
[26]
The Rise and Potential of Large Language Model Based Agents: A Survey
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, Rui Zheng, Xiaoran Fan, Xiao Wang, Limao Xiong, Yuhao Zhou, Weiran Wang, Changhao Jiang, Yicheng Zou, Xiangyang Liu, Zhangyue Yin, Shihan Dou, Rongxiang Weng, Wensen Cheng, Qi Zhang, Wenjuan Qin, Yongyan Zheng, Xipeng Qiu, Xuanjing Huang, a...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Travelplanner: A benchmark for real-world planning with language agents
Jian Xie, Kai Zhang, Jiangjie Chen, Tinghui Zhu, Renze Lou, Yuandong Tian, Yanghua Xiao, and Yu Su. Travelplanner: A benchmark for real-world planning with language agents. In Proceedings of the 41st International Conference on Machine Learning, 2024
work page 2024
-
[28]
Siheng Xiong, Ali Payani, Yuan Yang, and Faramarz Fekri. Deliberate reasoning for llms as structure-aware planning with accurate world model.CoRR, abs/2410.03136, 2024
-
[29]
Tree of thoughts: Deliberate problem solving with large language models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. InAd- vances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, New Orleans, LA, 2023
work page 2023
-
[30]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InProceedings of the 11th International Conference on Learning Representations, 2023
work page 2023
-
[31]
Xi Ye, Fangcong Yin, Yinghui He, Joie Zhang, Howard Yen, Tianyu Gao, Greg Durrett, and Danqi Chen. Longproc: Benchmarking long-context language models on long procedural generation.arXiv preprint arXiv:2501.05414, 2025
-
[32]
Huatuogpt, towards taming language model to be a doctor
Hongbo Zhang, Junying Chen, Feng Jiang, Fei Yu, Zhihong Chen, Guiming Chen, Jianquan Li, Xiangbo Wu, Zhiyi Zhang, Qingying Xiao, Xiang Wan, Benyou Wang, and Haizhou Li. Huatuogpt, towards taming language model to be a doctor. InFindings of the Association for Computational Linguistics: EMNLP, pages 10859–10885, 2023
work page 2023
-
[33]
Huaixiu Steven Zheng, Swaroop Mishra, Hugh Zhang, Xinyun Chen, Minmin Chen, Azade Nova, Le Hou, Heng-Tze Cheng, Quoc V Le, Ed H Chi, et al. Natural plan: Benchmarking llms on natural language planning.arXiv preprint arXiv:2406.04520, 2024. 12 Contents 1 Introduction 1 2 ChinaTravel Benchmark 2 2.1 Environment Information . . . . . . . . . . . . . . . . . ...
-
[34]
The specific constraints the agent can handle and the corresponding details, including the types and specific names of attractions, restaurants, and hotels; requirements for intercity transportation (airplane or train) and urban transportation (walk, taxi or subway); as well as budget limitations for overall expenses or specific activities (such as accomm...
-
[35]
The necessary information should be provided in the query, including the departure and destination cities of the trip, the number of travel days and constraint information
-
[36]
A detailed example with the query and travel planning response. Fig. 16 and Fig. 17 respectively show the questionnaire and its translated version. 34 开放旅行规划问题搜集 本问卷旨在构建一个开放环境下的旅行规划数据集,以便于相关研究的开展。由于填写的问题将作为公开数据集的一部分,存 在无法撤销的风险;请勿在填写内容中包含任何敏感的个人信息,感谢大家的参与!
-
[37]
出发城市: (从北京、南京、上海、杭州、深圳、武汉、广州、成都、重庆、苏州中选择)
-
[38]
目标旅游城市: (从北京、南京、上海、杭州、深圳、武汉、广州、成都、重庆、苏州中选择)
-
[39]
旅行天数: (1-5) 您作为用户可以向智能代理发起査询请求。查询内容可以包括对景点、餐饮、住宿、跨城交通(如火车、飞机)以及城内交通 (如地铁、步行、出租车)的具体要求。同时,您也可以提供个人偏好。请确保查询中包含以下三个信息:目标城市、人数和天 数,并确保这些信息相互匹配。智能代理将根据您的请求提供一个旅行规划结果,包括这几天的交通安排、住宿地点、推荐的 景点及餐饮建议。 用户问题的例子: 当前位置苏州。我一个人想去南京玩 2天,预算 3000 人民币,往返都坐高铁,请给我一个旅行规划。 智能代理回复的例子: 起点:苏州 目的地:南京 交通:苏州北站 -> 南京南站 列车:G4,07:24->08:15 费用:122.9 元 车票:1 张 游览:玄武湖景区 交通:地铁(南京南站 ->南京林业大学·新庄...
-
[40]
The participants included 121 undergraduate students, 86 master’s students, and 43 doctoral students
请给出用户问题: Figure 16: Questionnaire J.2 Recruitment And Payment For the collection of Human-154, we recruited a total of 250 student volunteers to provide authentic Chinese travel requirements. The participants included 121 undergraduate students, 86 master’s students, and 43 doctoral students. The task of understanding the query background and providing tr...
-
[41]
Departure City: (Choose from Beijing, Nanjing, Shanghai, Hangzhou, Shenzhen, Wuhan, Guangzhou, Chengdu, Chongqing, Suzhou)
-
[42]
Destination City: (Choose from Beijing, Nanjing, Shanghai, Hangzhou, Shenzhen, Wuhan, Guangzhou, Chengdu, Chongqing, Suzhou)
-
[43]
Number of Travelers: (1-5)
-
[44]
I want to know the itinerary for a 2-day trip to Shanghai from Hangzhou
Number of Travel Days: (1-5) As a user, you can submit queries to the intelligent agent. Your query may include specific requirements for attractions, dining, accommodation, intercity transportation (e.g., train, plane), and intra-city transportation (e.g., subway, walking, taxi). You may also provide personal preferences. Please ensure that your query in...
-
[45]
For Human-1000, we partnered with WJX (a professional survey platform) to scale data collection
Please provide a user query: Figure 17: The translated (English) version of the questionnaire and the straightforward nature of the natural language requirements, ensuring a fair and reasonable reward for the participants. For Human-1000, we partnered with WJX (a professional survey platform) to scale data collection. Each valid query was incentivized wit...
work page 2017
-
[46]
R e s t a u r a n t name
-
[47]
R e c o m m e n d e d food Additionally , keep in mind that the user ’s budget is a ll oc at ed across multiple expenses , i nc lu di ng i nt er ci ty t r a n s p o r t a t i o n and hotel a c c o m m o d a t i o n s . Ensure that the r e s t a u r a n t r e c o m m e n d a t i o n s fit within the re ma in in g budget c o n s t r a i n t s after a c c o ...
-
[48]
A t t r a c t i o n name
-
[49]
A t t r a c t i o n type
-
[50]
R e c o m m e n d e d duration Additionally , keep in mind that the user ’s budget is a ll oc at ed across multiple expenses , i nc lu di ng i nt er ci ty t r a n s p o r t a t i o n and hotel a c c o m m o d a t i o n s . Ensure that the a t t r a c t i o n r e c o m m e n d a t i o n s fit within the re ma in in g budget c o n s t r a i n t s after a c ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.