StereoSpace: Depth-Free Synthesis of Stereo Geometry via End-to-End Diffusion in a Canonical Space
Pith reviewed 2026-05-16 22:45 UTC · model grok-4.3
The pith
A diffusion model generates accurate stereo pairs from single images by conditioning only on viewpoint in a canonical rectified space, without depth maps or warping.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
StereoSpace shows that viewpoint conditioning inside a canonical rectified space allows a diffusion generator to produce stereo geometry end-to-end, inferring correspondences and disocclusions directly from monocular input without explicit depth or warping, and it outperforms warp-and-inpaint, latent-warping, and warped-conditioning baselines on perceptual and geometric metrics.
What carries the argument
Viewpoint conditioning inside a canonical rectified space that guides the diffusion process to infer stereo correspondences and disocclusions end-to-end.
If this is right
- Stereo synthesis becomes possible without running any depth estimator or warping operation at runtime.
- Performance gains appear on scenes with distinct layers and non-Lambertian surfaces where explicit geometry often fails.
- Evaluation metrics focused on perceptual comfort and 3D consistency replace reliance on depth error numbers.
- The same conditioning principle can scale to new viewpoint pairs without retraining separate geometry modules.
Where Pith is reading between the lines
- Extending the canonical space conditioning to video sequences could enforce temporal coherence across frames without additional depth networks.
- Removing depth as an intermediate step may reduce cascading errors when depth estimates are noisy in real-world captures.
- The approach opens a path for synthesizing other multi-view configurations, such as light-field or surround views, using the same viewpoint-only signal.
Load-bearing premise
Conditioning on viewpoint inside a canonical rectified space is sufficient for the diffusion model to infer accurate correspondences and disocclusions without any explicit geometry signal at inference time.
What would settle it
A controlled test on layered or non-Lambertian scenes where StereoSpace produces mismatched horizontal disparities or visible artifacts while a depth-based method does not.
Figures









read the original abstract
We introduce StereoSpace, a diffusion-based framework for monocular-to-stereo synthesis that models geometry purely through viewpoint conditioning, without explicit depth or warping. A canonical rectified space and the conditioning guide the generator to infer correspondences and fill disocclusions end-to-end. To ensure fair and leakage-free evaluation, we introduce an end-to-end protocol that excludes any ground truth or proxy geometry estimates at test time. The protocol emphasizes metrics reflecting downstream relevance: iSQoE for perceptual comfort and MEt3R for geometric consistency. StereoSpace surpasses other methods from the warp & inpaint, latent-warping, and warped-conditioning categories, achieving sharp parallax and strong robustness on layered and non-Lambertian scenes. This establishes viewpoint-conditioned diffusion as a scalable, depth-free solution for stereo generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces StereoSpace, a diffusion-based framework for monocular-to-stereo synthesis that models geometry purely through viewpoint conditioning in a canonical rectified space, without explicit depth or warping. It proposes an end-to-end evaluation protocol that excludes ground-truth or proxy geometry at test time and reports superior performance over warp-and-inpaint, latent-warping, and warped-conditioning baselines on iSQoE (perceptual comfort) and MEt3R (geometric consistency) metrics, with claimed robustness on layered and non-Lambertian scenes.
Significance. If the central claims hold, the work would be significant for establishing viewpoint-conditioned diffusion as a scalable depth-free alternative for stereo generation, potentially simplifying pipelines that currently rely on explicit geometry estimation. The leakage-free evaluation protocol and focus on downstream-relevant metrics (iSQoE, MEt3R) are positive contributions that strengthen the practical relevance of the results.
major comments (2)
- [Section 3.1] The core claim that the diffusion model infers accurate correspondences and disocclusions solely from viewpoint conditioning (without implicit geometry leakage from stereo training pairs) is load-bearing for the depth-free assertion and the reported robustness on non-Lambertian scenes. Section 3.1 and the training protocol description do not include an ablation that isolates viewpoint conditioning (e.g., performance when viewpoint input is replaced by a constant or removed), leaving open the possibility that the model has internalized depth-like mappings.
- [Table 2] Table 2 and the quantitative results on iSQoE and MEt3R report clear gains over baselines, but the absence of error bars, multiple random seeds, or statistical significance tests makes it difficult to assess whether the superiority is robust or could be explained by scene selection or training variance.
minor comments (3)
- [Section 2.2] The canonical rectified space is introduced in Section 2.2 but its exact parameterization (e.g., how rectification is enforced during diffusion sampling) is only sketched; a short pseudocode block or explicit equation for the conditioning injection would improve reproducibility.
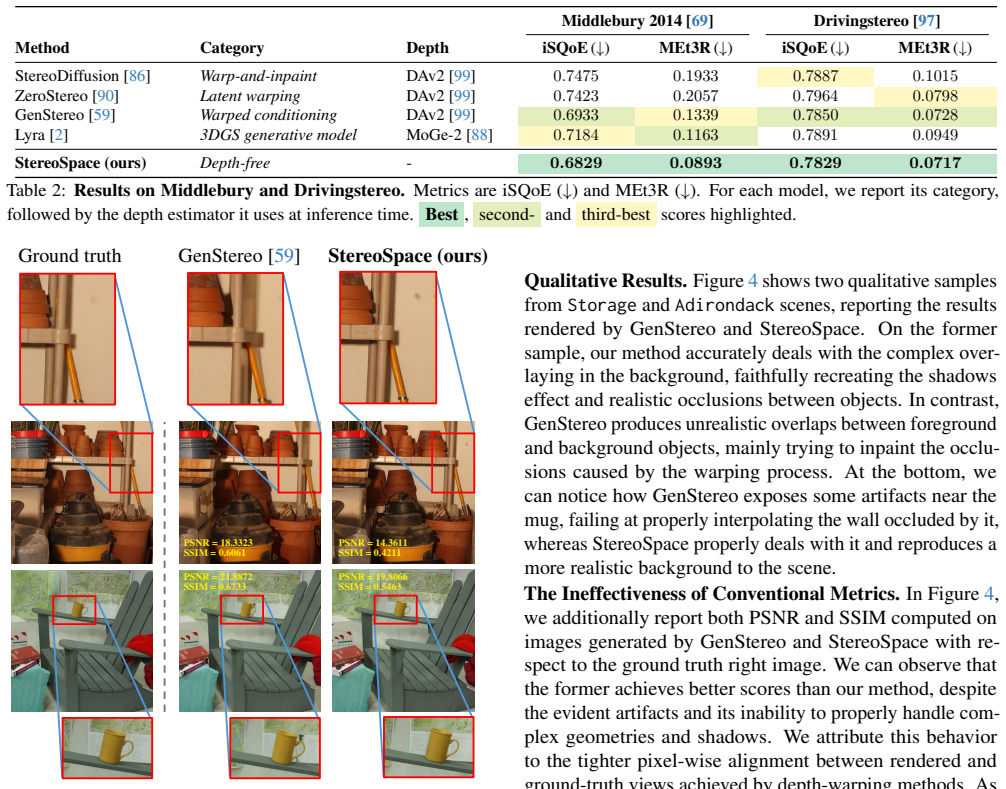
- [Figure 4] Figure 4 (qualitative results) shows sharp parallax on selected examples, but the caption does not indicate whether these scenes were part of the held-out test set or cherry-picked; adding this clarification would strengthen the visual evidence.
- [Section 1.1] The related-work discussion of prior diffusion-based stereo methods is brief; citing and contrasting with the most recent concurrent works on latent diffusion for view synthesis would better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of viewpoint-conditioned diffusion for depth-free stereo synthesis. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [Section 3.1] The core claim that the diffusion model infers accurate correspondences and disocclusions solely from viewpoint conditioning (without implicit geometry leakage from stereo training pairs) is load-bearing for the depth-free assertion and the reported robustness on non-Lambertian scenes. Section 3.1 and the training protocol description do not include an ablation that isolates viewpoint conditioning (e.g., performance when viewpoint input is replaced by a constant or removed), leaving open the possibility that the model has internalized depth-like mappings.
Authors: We agree that an explicit ablation isolating viewpoint conditioning would provide stronger support for the depth-free claim. In the revised manuscript, we will add this ablation to Section 3.1: we will replace the viewpoint condition with a constant vector (or remove it) and quantify the resulting degradation on iSQoE and MEt3R. This will demonstrate reliance on viewpoint input rather than internalized depth mappings. We note that the canonical rectified space and monocular training with viewpoint conditioning already limit leakage, and the leakage-free test protocol excludes geometry at inference; the new ablation will make this explicit. revision: yes
-
Referee: [Table 2] Table 2 and the quantitative results on iSQoE and MEt3R report clear gains over baselines, but the absence of error bars, multiple random seeds, or statistical significance tests makes it difficult to assess whether the superiority is robust or could be explained by scene selection or training variance.
Authors: We concur that reporting variability and significance would improve confidence in the quantitative results. In the revision, we will rerun all experiments with at least three random seeds, add standard-deviation error bars to Table 2, and include paired statistical significance tests (e.g., t-tests) between StereoSpace and each baseline to confirm the improvements are robust. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The paper presents StereoSpace as a trained diffusion model that uses viewpoint conditioning inside a canonical rectified space to synthesize stereo views end-to-end. No equations, fitted parameters, or self-citations are described that reduce any claimed prediction or result to the inputs by construction. The evaluation protocol explicitly excludes ground-truth or proxy geometry at test time, and performance claims rest on empirical metrics (iSQoE, MEt3R) computed on held-out data. This is a standard generative-model training and evaluation setup whose central claims do not collapse into tautology or self-referential fitting.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
UniFixer: A Universal Reference-Guided Fixer for Diffusion-Based View Synthesis
UniFixer is a universal reference-guided framework that fixes spatial, temporal, and backbone-related degradations in diffusion-based view synthesis via coarse-to-fine modules and achieves zero-shot SOTA results on no...
Reference graph
Works this paper leans on
-
[1]
MEt3R: Measuring multi-view consistency in generated images
Mohammad Asim, Christopher Wewer, Thomas Wimmer, Bernt Schiele, and Jan Eric Lenssen. MEt3R: Measuring multi-view consistency in generated images. InIEEE/CVF Conference on Computer Vision and Pattern Recogition (CVPR), 2025. 2, 5, 16, 17, 18
work page 2025
-
[2]
Sherwin Bahmani, Tianchang Shen, Jiawei Ren, Jiahui Huang, Yifeng Jiang, Haithem Turki, Andrea Tagliasacchi, David B Lindell, Zan Gojcic, Sanja Fidler, et al. Lyra: Gen- erative 3d scene reconstruction via video diffusion model self-distillation.preprint arXiv:2509.19296, 2025. 1, 2, 6, 7, 8, 17, 18, 19, 20
-
[3]
AC3D: Analyzing and improving 3d camera control in video diffusion trans- formers
Sherwin Bahmani, Ivan Skorokhodov, Guocheng Qian, Ali- aksandr Siarohin, Willi Menapace, Andrea Tagliasacchi, David B Lindell, and Sergey Tulyakov. AC3D: Analyzing and improving 3d camera control in video diffusion trans- formers. InIEEE/CVF Conference on Computer Vision and Pattern Recogition (CVPR), 2025. 2
work page 2025
-
[4]
Label-efficient se- mantic segmentation with diffusion models
Dmitry Baranchuk, Andrey V oynov, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko. Label-efficient se- mantic segmentation with diffusion models. InInternational Conference on Learning Representations (ICLR), 2022. 2
work page 2022
-
[5]
Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P
Jonathan T. Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P. Srinivasan. Mip-NeRF: A multiscale representation for anti-aliasing neu- ral radiance fields. InIEEE/CVF International Conference on Computer Vision (ICCV), 2021. 2
work page 2021
-
[6]
Barron, Ben Mildenhall, Dor Verbin, Pratul P
Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, and Peter Hedman. Mip-NeRF 360: Unbounded anti-aliased neural radiance fields.IEEE/CVF Conference on Computer Vision and Pattern Recogition (CVPR), 2022. 2
work page 2022
-
[7]
Align your latents: High-resolution video synthesis with latent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dock- horn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. InIEEE/CVF Conference on Com- puter Vision and Pattern Recogition (CVPR), 2023. 2
work page 2023
-
[8]
D. J. Butler, J. Wulff, G. B. Stanley, and M. J. Black. A naturalistic open source movie for optical flow evaluation. InEuropean Conference on Computer Vision (ECCV), 2012. 4, 14
work page 2012
-
[9]
Yohann Cabon, Naila Murray, and Martin Humenberger. Virtual Kitti 2.preprint arXiv:2001.10773, 2020. 4, 14
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[10]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. In IEEE/CVF International Conference on Computer Vision (ICCV), 2021. 5
work page 2021
-
[11]
pixelSplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction
David Charatan, Sizhe Lester Li, Andrea Tagliasacchi, and Vincent Sitzmann. pixelSplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction. InIEEE/CVF Conference on Computer Vision and Pattern Recogition (CVPR), 2024. 2
work page 2024
-
[12]
MVSNeRF: Fast generalizable radiance field reconstruction from multi-view stereo
Anpei Chen, Zexiang Xu, Fuqiang Zhao, Xiaoshuai Zhang, Fanbo Xiang, Jingyi Yu, and Hao Su. MVSNeRF: Fast generalizable radiance field reconstruction from multi-view stereo. InIEEE/CVF International Conference on Computer Vision (ICCV), 2021. 2
work page 2021
-
[13]
TensoRF: Tensorial radiance fields
Anpei Chen, Zexiang Xu, Andreas Geiger, Jingyi Yu, and Hao Su. TensoRF: Tensorial radiance fields. InEuropean Conference on Computer Vision (ECCV), 2022. 2
work page 2022
-
[14]
Diffu- sionDet: Diffusion model for object detection
Shoufa Chen, Peize Sun, Yibing Song, and Ping Luo. Diffu- sionDet: Diffusion model for object detection. InIEEE/CVF International Conference on Computer Vision (ICCV), 2023. 2
work page 2023
-
[15]
MVSplat: Efficient 3d gaussian splatting from sparse multi-view images
Yuedong Chen, Haofei Xu, Chuanxia Zheng, Bohan Zhuang, Marc Pollefeys, Andreas Geiger, Tat-Jen Cham, and Jianfei Cai. MVSplat: Efficient 3d gaussian splatting from sparse multi-view images. InEuropean Conference on Computer Vision (ECCV), 2024. 2
work page 2024
-
[16]
SVG: 3d stereoscopic video generation via denoising frame matrix
Peng Dai, Feitong Tan, Qiangeng Xu, David Futschik, Ruofei Du, Sean Fanello, Xiaojuan Qi, and Yinda Zhang. SVG: 3d stereoscopic video generation via denoising frame matrix. InInternational Conference on Learning Represen- tations (ICLR), 2025. 3
work page 2025
-
[17]
Diffusion mod- els beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion mod- els beat gans on image synthesis. InAdvances in Neural Information Processing Systems (NeurIPS), 2021. 2
work page 2021
-
[18]
Brandt, Axel Feld- mann, Zhoutong Zhang, and William T
Stephanie Fu, Mark Hamilton, Laura E. Brandt, Axel Feld- mann, Zhoutong Zhang, and William T. Freeman. FeatUp: A model-agnostic framework for features at any resolution. InInternational Conference on Learning Representations (ICLR), 2024. 5
work page 2024
-
[19]
Geowizard: Unleashing the diffusion priors for 3d geometry estimation from a single image
Xiao Fu, Wei Yin, Mu Hu, Kaixuan Wang, Yuexin Ma, Ping Tan, Shaojie Shen, Dahua Lin, and Xiaoxiao Long. Geowizard: Unleashing the diffusion priors for 3d geometry estimation from a single image. InEuropean Conference on Computer Vision (ECCV), 2024. 2
work page 2024
-
[20]
Dynamic view synthesis from dynamic monocular video
Chen Gao, Ayush Saraf, Johannes Kopf, and Jia-Bin Huang. Dynamic view synthesis from dynamic monocular video. In IEEE/CVF International Conference on Computer Vision (ICCV), 2021. 2
work page 2021
-
[21]
Ruiqi Gao*, Aleksander Holynski*, Philipp Henzler, Arthur Brussee, Ricardo Martin-Brualla, Pratul P. Srinivasan, Jonathan T. Barron, and Ben Poole*. CAT3D: Create any- thing in 3d with multi-view diffusion models.Advances in Neural Information Processing Systems (NeurIPS), 2024. 2, 3
work page 2024
-
[22]
CameraCtrl: Enabling Camera Control for Text-to-Video Generation
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. CameraCtrl: En- abling camera control for text-to-video generation.preprint arXiv:2404.02101, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
A diffusion-based framework for multi-class anomaly detection
Haoyang He, Jiangning Zhang, Hongxu Chen, Xuhai Chen, Zhishan Li, Xu Chen, Yabiao Wang, Chengjie Wang, and Lei Xie. A diffusion-based framework for multi-class anomaly detection. InAAAI Conference on Artificial Intelligence,
-
[24]
Heiko Hirschmuller. Stereo processing by semiglobal match- ing and mutual information.IEEE Transactions on Pattern Analysis and Machine Intelligence, 30(2):328–341, 2008. 5
work page 2008
-
[25]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu- sion probabilistic models.Advances in Neural Information Processing Systems (NeurIPS), 2020. 2 9
work page 2020
-
[26]
Video dif- fusion models.Advances in Neural Information Processing Systems (NeurIPS), 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video dif- fusion models.Advances in Neural Information Processing Systems (NeurIPS), 2022. 2
work page 2022
-
[27]
Animate anyone: Consistent and controllable image- to-video synthesis for character animation
Li Hu. Animate anyone: Consistent and controllable image- to-video synthesis for character animation. InIEEE/CVF Conference on Computer Vision and Pattern Recogition (CVPR), pages 8153–8163, 2024. 3
work page 2024
-
[28]
2d gaussian splatting for geometrically accurate radiance fields
Binbin Huang, Zehao Yu, Anpei Chen, Andreas Geiger, and Shenghua Gao. 2d gaussian splatting for geometrically accurate radiance fields. InACM SigGraph, pages 1–11,
-
[29]
Restereo: Diffusion stereo video generation and restoration.preprint arXiv:2506.06023, 2025
Xingchang Huang, Ashish Kumar Singh, Florian Dubost, Cristina Nader Vasconcelos, Sakar Khattar, Liang Shi, Chris- tian Theobalt, Cengiz Oztireli, and Gurprit Singh. Restereo: Diffusion stereo video generation and restoration.preprint arXiv:2506.06023, 2025. 3
-
[30]
Pl ¨ucker coordinates for lines in the space
Yan-Bin Jia. Pl ¨ucker coordinates for lines in the space. COMS 4770/5770 Notes, Iowa State University, 2024. Lec- ture notes. 3, 14, 15
work page 2024
-
[31]
GaussianShader: 3d gaussian splatting with shading functions for reflective surfaces
Yingwenqi Jiang, Jiadong Tu, Yuan Liu, Xifeng Gao, Xiaox- iao Long, Wenping Wang, and Yuexin Ma. GaussianShader: 3d gaussian splatting with shading functions for reflective surfaces. InIEEE/CVF Conference on Computer Vision and Pattern Recogition (CVPR), 2024. 2
work page 2024
-
[32]
Match stereo videos via bidirectional alignment
Junpeng Jing, Ye Mao, Anlan Qiu, and Krystian Mikola- jczyk. Match stereo videos via bidirectional alignment. preprint arXiv:2409.20283, 2024. 4, 14
-
[33]
Laurent Jospin, Allen Antony, Lian Xu, Hamid Laga, Farid Boussaid, and Mohammed Bennamoun. Active-passive simstereo-benchmarking the cross-generalization capabil- ities of deep learning-based stereo methods.Advances in Neural Information Processing Systems (NeurIPS), 2022. 4, 14
work page 2022
-
[34]
SPAD: Spatially aware multi-view diffusers
Yash Kant, Aliaksandr Siarohin, Ziyi Wu, Michael Vasilkovsky, Guocheng Qian, Jian Ren, Riza Alp Guler, Bernard Ghanem, Sergey Tulyakov, and Igor Gilitschenski. SPAD: Spatially aware multi-view diffusers. InIEEE/CVF Conference on Computer Vision and Pattern Recogition (CVPR), 2024. 15
work page 2024
-
[35]
Dy- namicStereo: Consistent dynamic depth from stereo videos
Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Dy- namicStereo: Consistent dynamic depth from stereo videos. InIEEE/CVF Conference on Computer Vision and Pattern Recogition (CVPR), 2023. 4, 14
work page 2023
-
[36]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. InAdvances in Neural Information Processing Systems (NeurIPS), 2022. 3
work page 2022
-
[37]
Repurpos- ing diffusion-based image generators for monocular depth estimation
Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Met- zger, Rodrigo Caye Daudt, and Konrad Schindler. Repurpos- ing diffusion-based image generators for monocular depth estimation. InIEEE/CVF Conference on Computer Vision and Pattern Recogition (CVPR), 2024. 2
work page 2024
-
[38]
Bingxin Ke, Kevin Qu, Tianfu Wang, Nando Metzger, Shengyu Huang, Bo Li, Anton Obukhov, and Konrad Schindler. Marigold: Affordable adaptation of diffusion- based image generators for image analysis.preprint arXiv:2505.09358, 2025. 2
-
[39]
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics (TOG), 42(4):139–1, 2023. 2
work page 2023
-
[40]
EscherNet: A generative model for scalable view synthesis
Xin Kong, Shikun Liu, Xiaoyang Lyu, Marwan Taher, Xiao- juan Qi, and Andrew J Davison. EscherNet: A generative model for scalable view synthesis. InIEEE/CVF Conference on Computer Vision and Pattern Recogition (CVPR), 2024. 15
work page 2024
-
[41]
Ground- ing image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and J´erˆome Revaud. Ground- ing image matching in 3d with mast3r. InEuropean Confer- ence on Computer Vision, pages 71–91. Springer, 2024. 5, 16
work page 2024
-
[42]
Dreamscene: 3d gaussian-based text-to-3d scene generation via formation pattern sampling
Ruilong Li, Brent Yi, Junchen Liu, Hang Gao, Yi Ma, and Angjoo Kanazawa. Cameras as relative positional encoding. preprint arXiv:2507.10496, 2025. 6, 15
-
[43]
SceneSplat: Gaussian splatting-based scene understanding with vision-language pretraining
Yue Li, Qi Ma, Runyi Yang, Huapeng Li, Mengjiao Ma, Bin Ren, Nikola Popovic, Nicu Sebe, Ender Konukoglu, Theo Gevers, et al. SceneSplat: Gaussian splatting-based scene understanding with vision-language pretraining. In IEEE/CVF International Conference on Computer Vision (ICCV), 2025. 2, 4, 14
work page 2025
-
[44]
Hanwen Liang, Junli Cao, Vidit Goel, Guocheng Qian, Sergei Korolev, Demetri Terzopoulos, Konstantinos N Pla- taniotis, Sergey Tulyakov, and Jian Ren. Wonderland: Navi- gating 3d scenes from a single image.IEEE/CVF Conference on Computer Vision and Pattern Recogition (CVPR), 2025. 2
work page 2025
-
[45]
Zero-1-to-3: Zero-shot one image to 3d object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tok- makov, Sergey Zakharov, and Carl V ondrick. Zero-1-to-3: Zero-shot one image to 3d object. InIEEE/CVF Interna- tional Conference on Computer Vision (ICCV), 2023. 2
work page 2023
-
[46]
Zihua Liu, Yizhou Li, Songyan Zhang, and Masatoshi Oku- tomi. DMS: Diffusion-based multi-baseline stereo gener- ation for improving self-supervised depth estimation. In IEEE/CVF Conference on Computer Vision and Pattern Recogition (CVPR), 2025. 3
work page 2025
-
[47]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.preprint arXiv:1711.05101, 2017. 5
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[48]
Repaint: Inpainting using denoising diffusion probabilistic models
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models. InIEEE/CVF Conference on Computer Vision and Pattern Recogition (CVPR), 2022. 2
work page 2022
-
[49]
Dynamic 3d gaussians: Tracking by persis- tent dynamic view synthesis
Jonathon Luiten, Georgios Kopanas, Bastian Leibe, and Deva Ramanan. Dynamic 3d gaussians: Tracking by persis- tent dynamic view synthesis. InInternational Conference on 3D Vision (3DV), 2024. 2
work page 2024
-
[50]
SpatialDreamer: Self-supervised stereo video synthesis from monocular input
Zhen Lv, Yangqi Long, Congzhentao Huang, Cao Li, Chengfei Lv, Hao Ren, and Dian Zheng. SpatialDreamer: Self-supervised stereo video synthesis from monocular input. InIEEE/CVF Conference on Computer Vision and Pattern Recogition (CVPR), 2025. 3
work page 2025
-
[51]
Lukas Mehl, Jenny Schmalfuss, Azin Jahedi, Yaroslava Nali- vayko, and Andr´es Bruhn. Spring: A high-resolution high- detail dataset and benchmark for scene flow, optical flow 10 and stereo. InIEEE/CVF Conference on Computer Vision and Pattern Recogition (CVPR), 2023. 4, 14
work page 2023
-
[52]
Object scene flow for autonomous vehicles
Moritz Menze and Andreas Geiger. Object scene flow for autonomous vehicles. InProceedings of the IEEE Confer- ence on Computer Vision and Pattern Recognition (CVPR),
-
[53]
GTA: A geometry-aware attention mechanism for multi-view transformers
Takeru Miyato, Bernhard Jaeger, Max Welling, and Andreas Geiger. GTA: A geometry-aware attention mechanism for multi-view transformers. InInternational Conference on Learning Representations (ICLR), 2024. 15
work page 2024
-
[54]
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, and Ying Shan. T2I-Adapter: Learn- ing adapters to dig out more controllable ability for text-to- image diffusion models. InAAAI Conference on Artificial Intelligence, 2024. 2
work page 2024
-
[55]
Thomas M¨uller, Alex Evans, Christoph Schied, and Alexan- der Keller. Instant neural graphics primitives with a mul- tiresolution hash encoding.ACM Transactions on Graphics (TOG), 41(4):1–15, 2022. 2
work page 2022
-
[56]
Nerfies: Deformable neural radiance fields
Keunhong Park, Utkarsh Sinha, Jonathan T Barron, Sofien Bouaziz, Dan B Goldman, Steven M Seitz, and Ricardo Martin-Brualla. Nerfies: Deformable neural radiance fields. InIEEE/CVF International Conference on Computer Vision (ICCV), 2021. 2
work page 2021
-
[57]
On a new geometry of space.Philosophical Transactions of the Royal Society of London, 155:725–791,
Julius Pl¨ucker. On a new geometry of space.Philosophical Transactions of the Royal Society of London, 155:725–791,
-
[58]
D-NeRF: Neural radiance fields for dynamic scenes
Albert Pumarola, Enric Corona, Gerard Pons-Moll, and Francesc Moreno-Noguer. D-NeRF: Neural radiance fields for dynamic scenes. InIEEE/CVF Conference on Computer Vision and Pattern Recogition (CVPR), 2020. 2
work page 2020
-
[59]
GenStereo: Towards open-world generation of stereo images and unsupervised matching
Feng Qiao, Zhexiao Xiong, Eric Xing, and Nathan Jacobs. GenStereo: Towards open-world generation of stereo images and unsupervised matching. InIEEE/CVF Conference on Computer Vision and Pattern Recogition (CVPR), 2025. 1, 3, 5, 6, 7, 8, 14, 17, 18, 19, 20
work page 2025
-
[60]
RichDreamer: A generalizable normal-depth diffusion model for detail richness in text- to-3d
Lingteng Qiu, Guanying Chen, Xiaodong Gu, Qi Zuo, Mu- tian Xu, Yushuang Wu, Weihao Yuan, Zilong Dong, Liefeng Bo, and Xiaoguang Han. RichDreamer: A generalizable normal-depth diffusion model for detail richness in text- to-3d. InIEEE/CVF Conference on Computer Vision and Pattern Recogition (CVPR), 2024. 2
work page 2024
-
[61]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InInternational Conference on Machine Learning (ICML), 2021. 6
work page 2021
-
[62]
Ambiguous medical image segmentation using diffusion models
Aimon Rahman, Jeya Maria Jose Valanarasu, Ilker Haci- haliloglu, and Vishal M Patel. Ambiguous medical image segmentation using diffusion models. InIEEE/CVF Confer- ence on Computer Vision and Pattern Recogition (CVPR),
-
[63]
Open chal- lenges in deep stereo: the booster dataset
Pierluigi Zama Ramirez, Fabio Tosi, Matteo Poggi, Samuele Salti, Stefano Mattoccia, and Luigi Di Stefano. Open chal- lenges in deep stereo: the booster dataset. InIEEE/CVF Con- ference on Computer Vision and Pattern Recogition (CVPR),
- [64]
-
[65]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InIEEE/CVF Con- ference on Computer Vision and Pattern Recogition (CVPR), pages 10684–10695, 2022. 3
work page 2022
-
[66]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InIEEE/CVF Con- ference on Computer Vision and Pattern Recogition (CVPR),
-
[67]
Progressive distillation for fast sampling of diffusion models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. InInternational Confer- ence on Learning Representations (ICLR), 2022. 2, 3
work page 2022
-
[68]
ZeroNVS: Zero-shot 360-degree view synthesis from a single image
Kyle Sargent, Zizhang Li, Tanmay Shah, Charles Herrmann, Hong-Xing Yu, Yunzhi Zhang, Eric Ryan Chan, Dmitry Lagun, Li Fei-Fei, Deqing Sun, and Jiajun Wu. ZeroNVS: Zero-shot 360-degree view synthesis from a single image. InIEEE/CVF Conference on Computer Vision and Pattern Recogition (CVPR), 2024. 2
work page 2024
-
[69]
High- resolution stereo datasets with subpixel-accurate ground truth
Daniel Scharstein, Heiko Hirschm¨uller, York Kitajima, Greg Krathwohl, Nera Neˇsi´c, Xi Wang, and Porter Westling. High- resolution stereo datasets with subpixel-accurate ground truth. InPattern Recognition, pages 31–42, 2014. 6, 7, 15, 16, 17, 19
work page 2014
-
[70]
LAION-5b: An open large-scale dataset for training next generation image-text models
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade W Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Worts- man, Patrick Schramowski, Srivatsa R Kundurthy, Katherine Crowson, Ludwig Schmidt, Robert Kaczmarczyk, and Jenia Jitsev. LAION-5b: An open large-scale dataset for training next generation image-text m...
work page 2022
-
[71]
Junyoung Seo, Kazumi Fukuda, Takashi Shibuya, Takuya Narihira, Naoki Murata, Shoukang Hu, Chieh-Hsin Lai, Se- ungryong Kim, and Yuki Mitsufuji. GenWarp: Single image to novel views with semantic-preserving generative warp- ing.Advances in Neural Information Processing Systems (NeurIPS), 2024. 3
work page 2024
-
[72]
DissolveStereo: Coarse Depth Injection for Zero-Shot Stereo Video Generation
Jian Shi, Qian Wang, Zhenyu Li, Ramzi Idoughi, and Peter Wonka. StereoCrafter-Zero: Zero-shot stereo video gener- ation with noisy restart.preprint arXiv:2411.14295, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[73]
MVDream: Multi-view diffusion for 3d generation
Yichun Shi, Peng Wang, Jianglong Ye, Long Mai, Kejie Li, and Xiao Yang. MVDream: Multi-view diffusion for 3d generation. InInternational Conference on Learning Representations (ICLR), 2024. 2
work page 2024
-
[74]
M2SVid: End-to-end inpainting and refinement for monocular-to-stereo video conversion
Nina Shvetsova, Goutam Bhat, Prune Truong, Hilde Kuehne, and Federico Tombari. M2SVid: End-to-end inpainting and refinement for monocular-to-stereo video conversion. preprint arXiv:2505.16565, 2025. 3
-
[75]
Denois- ing diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denois- ing diffusion implicit models. InInternational Conference on Learning Representations, 2021. 4 11
work page 2021
-
[76]
Julian Straub, Thomas Whelan, Lingni Ma, Yufan Chen, Erik Wijmans, Simon Green, Jakob J. Engel, Raul Mur-Artal, Carl Ren, Shobhit Verma, Anton Clarkson, Mingfei Yan, Brian Budge, Yajie Yan, Xiaqing Pan, June Yon, Yuyang Zou, Kimberly Leon, Nigel Carter, Jesus Briales, Tyler Gillingham, Elias Mueggler, Luis Pesqueira, Manolis Savva, Dhruv Batra, Hauke M. S...
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[77]
RoFormer: enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. RoFormer: enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
-
[78]
Netanel Tamir, Shir Amir, Ranel Itzhaky, Noam Atia, Shob- hita Sundaram, Stephanie Fu, Ron Sokolovsky, Phillip Isola, Tali Dekel, Richard Zhang, and Miriam Farber. What makes for a good stereoscopic image? InIEEE/CVF Conference on Computer Vision and Pattern Recogition (CVPR), 2025. 2, 5
work page 2025
-
[79]
Shitao Tang, Fuyang Zhang, Jiacheng Chen, Peng Wang, and Yasutaka Furukawa. MVDiffusion: Enabling holistic multi-view image generation with correspondence-aware dif- fusion.Advances in Neural Information Processing Systems (NeurIPS), 2023. 2
work page 2023
-
[80]
Diffuse attend and segment: Unsupervised zero-shot segmentation using stable diffusion
Junjiao Tian, Lavisha Aggarwal, Andrea Colaco, Zsolt Kira, and Mar Gonzalez-Franco. Diffuse attend and segment: Unsupervised zero-shot segmentation using stable diffusion. InIEEE/CVF Conference on Computer Vision and Pattern Recogition (CVPR), 2024. 2
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.