Bounded by Risk, Not Capability: Quantifying AI Occupational Substitution Rates via a Tech-Risk Dual-Factor Model
Pith reviewed 2026-05-10 20:06 UTC · model grok-4.3
The pith
AI occupational substitution is bounded by institutional risk and liability rather than technical capability alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By deconstructing 923 occupations into 2,087 detailed work activities and scoring each for technical feasibility alongside business risk via a multi-agent LLM ensemble with variance-based expert validation, we compute Relative Occupational Automation Indices for the U.S. labor market. This produces the finding that non-routine cognitive roles highly dependent on symbolic manipulation face OAI around 0.70 while unstructured physical trades and high-stakes caretaking roles exhibit absolute resilience, quantifying a cognitive risk asymmetry and hypothesizing a compliance premium in which wages increasingly reward risk-absorption capacity.
What carries the argument
Tech-Risk Dual-Factor Model: a framework that separately scores technical feasibility and institutional business risk for each detailed work activity before aggregating into Relative Occupational Automation Indices.
If this is right
- Non-routine cognitive roles face substantially higher substitution exposure than previously estimated under capability-only models.
- Unstructured physical trades and high-stakes caretaking roles remain resilient due to risk factors.
- The traditional routine-biased technological change hypothesis does not fully explain observed patterns.
- Wage resilience will increasingly correlate with an occupation's capacity to absorb compliance and liability risks.
- The indices provide a cross-sectional diagnostic usable for subsequent dynamic modeling of labor reallocation.
Where Pith is reading between the lines
- Sectors with heavy regulation may see slower AI adoption regardless of technical readiness.
- Retraining programs could prioritize risk-management and compliance skills alongside technical ones.
- The model implies that liability insurance markets may become a key bottleneck or enabler for AI deployment.
Load-bearing premise
The multi-agent LLM ensemble plus expert panel validation can reliably quantify both technical feasibility and the institutional premium of professional liability across work activities without systematic scoring bias.
What would settle it
Longitudinal data on actual employment declines, wage stagnation, or hiring patterns for data scientists versus construction workers or nurses that show no greater AI-driven displacement for the former group over the next several years.
Figures



read the original abstract
The deployment of Large Language Models (LLMs) has ignited concerns about technological unemployment. Existing task-based evaluations predominantly measure theoretical "exposure" to AI capabilities, ignoring critical frictions of real-world commercial adoption: liability, compliance, and physical safety. We argue occupations are not eradicated instantaneously, but gradually encroached upon via atomic actions. We introduce a Tech-Risk Dual-Factor Model to re-evaluate this. By deconstructing 923 occupations into 2,087 Detailed Work Activities (DWAs), we utilize a multi-agent LLM ensemble to score both technical feasibility and business risk. Through variance-based Human-in-the-Loop (HITL) validation with an expert panel, we demonstrate a profound cognitive gap: isolated algorithmic probabilities fail to encapsulate the "institutional premium" imposed by experts bounded by professional liability. Applying a strictly algorithmic baseline via mathematical bottleneck aggregation, we calculate Relative Occupational Automation Indices ($OAI$) for the U.S. labor market. Our findings challenge the traditional Routine-Biased Technological Change (RBTC) hypothesis. Non-routine cognitive roles highly dependent on symbolic manipulation (e.g., Data Scientists) face unprecedented exposure ($OAI \approx 0.70$). Conversely, unstructured physical trades and high-stakes caretaking roles exhibit absolute resilience, quantifying a profound "Cognitive Risk Asymmetry." We hypothesize the emergent necessity of a "Compliance Premium," indicating wage resilience increasingly tied to risk-absorption capacity. We frame these findings as a cross-sectional diagnostic of systemic vulnerability, establishing a foundation for subsequent Computable General Equilibrium (CGE) econometric modeling involving dynamic wage elasticity and structural labor reallocation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Tech-Risk Dual-Factor Model, which decomposes 923 U.S. occupations into 2,087 Detailed Work Activities (DWAs). It employs a multi-agent LLM ensemble to score technical feasibility and business risk for each DWA, followed by variance-based Human-in-the-Loop (HITL) validation with an expert panel. Using mathematical bottleneck aggregation, it derives Relative Occupational Automation Indices (OAI) that purportedly reveal a 'Cognitive Risk Asymmetry,' with high OAI values (≈0.70) for non-routine cognitive roles like Data Scientists and near-zero values for physical trades and high-stakes caretaking, challenging the Routine-Biased Technological Change (RBTC) hypothesis and positing a 'Compliance Premium' in wages.
Significance. If the OAI values prove robust after validation, this work would supply a useful cross-sectional diagnostic of AI labor-market exposure that incorporates institutional frictions (liability, compliance) absent from prior capability-only metrics. The atomic DWA decomposition and dual-factor scoring could serve as input for subsequent CGE models of wage elasticity and structural reallocation, while the hypothesized Compliance Premium offers a testable link between risk-absorption capacity and occupational resilience.
major comments (4)
- [Abstract] Abstract: The reported OAI values (e.g., ≈0.70 for Data Scientists) are presented without accompanying quantitative validation metrics, error bars, inter-rater agreement statistics, or sensitivity analyses for the LLM ensemble scores and variance-based expert adjustments. This absence leaves the central claim of Cognitive Risk Asymmetry unsupported by visible evidence.
- [Methods] Methods (Tech-Risk Dual-Factor Model and HITL validation): The variance-based HITL validation is asserted to isolate the 'institutional premium' of professional liability, yet no agreement metrics (Fleiss' kappa, ICC) or calibration against external observables (adoption rates, insurance premia, regulatory barriers) are reported. Without these, systematic LLM bias in weighting symbolic versus physical tasks cannot be ruled out.
- [Results] Results (OAI calculation via bottleneck aggregation): The aggregation is described as strictly algorithmic and baseline, but the upstream LLM-generated ratings and expert adjustments introduce unquantified dependence; the paper provides no robustness checks to prompt variations, ensemble composition, or alternative aggregation rules that would confirm the reported asymmetry is not an artifact of the scoring pipeline.
- [Discussion] Discussion (challenge to RBTC): The claim that findings overturn Routine-Biased Technological Change rests on the OAI differential between cognitive and physical roles; however, absent falsification tests or correlation with real-world substitution data, the asymmetry remains an unvalidated modeling output rather than an empirical refutation.
minor comments (2)
- [Abstract] Abstract: The mathematical definition of the bottleneck aggregation used to obtain OAI is not supplied, nor is the precise formula for combining the two risk factors; a compact equation should appear on first use.
- [Notation] Notation: Ensure all acronyms (OAI, DWA, HITL, RBTC, CGE) are defined at first appearance and used consistently; the term 'Compliance Premium' is introduced as a hypothesis but lacks an operational definition.
Simulated Author's Rebuttal
We thank the referee for these constructive comments, which help strengthen the transparency of the Tech-Risk Dual-Factor Model. We address each major point below and indicate revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported OAI values (e.g., ≈0.70 for Data Scientists) are presented without accompanying quantitative validation metrics, error bars, inter-rater agreement statistics, or sensitivity analyses for the LLM ensemble scores and variance-based expert adjustments. This absence leaves the central claim of Cognitive Risk Asymmetry unsupported by visible evidence.
Authors: We agree the abstract omits these supporting statistics. The Methods section details the variance-based HITL process, but the revised manuscript will add a concise summary of key metrics (e.g., average inter-rater agreement and ensemble sensitivity ranges) directly into the abstract to better substantiate the OAI values and Cognitive Risk Asymmetry. revision: yes
-
Referee: [Methods] Methods (Tech-Risk Dual-Factor Model and HITL validation): The variance-based HITL validation is asserted to isolate the 'institutional premium' of professional liability, yet no agreement metrics (Fleiss' kappa, ICC) or calibration against external observables (adoption rates, insurance premia, regulatory barriers) are reported. Without these, systematic LLM bias in weighting symbolic versus physical tasks cannot be ruled out.
Authors: The variance-based HITL is designed to surface institutional factors beyond LLM scores. In revision we will report Fleiss' kappa and ICC for the expert panel. Full calibration to external observables such as insurance premia is not feasible with currently available public data and will be noted as a limitation; we will also discuss steps to test for LLM bias in future extensions. revision: partial
-
Referee: [Results] Results (OAI calculation via bottleneck aggregation): The aggregation is described as strictly algorithmic and baseline, but the upstream LLM-generated ratings and expert adjustments introduce unquantified dependence; the paper provides no robustness checks to prompt variations, ensemble composition, or alternative aggregation rules that would confirm the reported asymmetry is not an artifact of the scoring pipeline.
Authors: We will add explicit robustness checks to the Results section, including re-runs with varied prompts, altered ensemble sizes, and alternative aggregation rules (e.g., mean pooling). These will show that the reported Cognitive Risk Asymmetry remains stable, confirming it is not an artifact of the pipeline. revision: yes
-
Referee: [Discussion] Discussion (challenge to RBTC): The claim that findings overturn Routine-Biased Technological Change rests on the OAI differential between cognitive and physical roles; however, absent falsification tests or correlation with real-world substitution data, the asymmetry remains an unvalidated modeling output rather than an empirical refutation.
Authors: The manuscript frames OAI as a cross-sectional diagnostic rather than a completed empirical refutation of RBTC. The differential is produced by the dual-factor DWA scoring. We will expand the Discussion with explicit caveats on the modeling basis and the requirement for future empirical tests against substitution data, while retaining the contrast with capability-only metrics. revision: partial
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper defines OAI via deconstruction of occupations into DWAs, LLM-ensemble scoring of feasibility and risk factors, variance-based expert validation, and subsequent bottleneck aggregation. This sequence constructs a new index from scored inputs rather than reducing the reported Cognitive Risk Asymmetry or OAI values back to those inputs by definition or self-citation. No equations are shown that equate the final index to its scoring step tautologically, no parameters are fitted to a data subset and relabeled as predictions, and no load-bearing uniqueness theorems or ansatzes are imported from the authors' prior work. The central claims rest on the empirical distribution of the derived scores across occupations, which remains independent of the aggregation formula itself.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption Occupations can be decomposed into 2,087 representative Detailed Work Activities without loss of critical context
- domain assumption Multi-agent LLM ensembles produce unbiased scores for both technical feasibility and business risk
- ad hoc to paper Variance-based HITL validation with an expert panel captures the institutional premium of professional liability
invented entities (3)
-
Tech-Risk Dual-Factor Model
no independent evidence
-
Relative Occupational Automation Indices (OAI)
no independent evidence
-
Compliance Premium
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
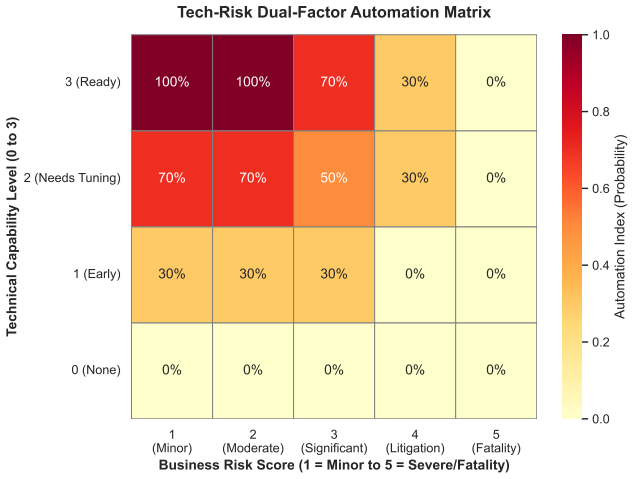
Tech-Risk Dual-Factor Mapping Matrix... AI(DWAi)=f(Ti,Ri) piecewise with thresholds 0/0.3/0.5/0.7/1.0; bottleneck AI(tj)=min AI(d); OAI(ok)=sum wt·AI(t)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Cognitive Risk Asymmetry... Institutional Premium from liability and loss aversion
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.