AVSD: Adaptive-View Self-Distillation by Balancing Consensus and Teacher-Specific Privileged Signals
Pith reviewed 2026-05-21 06:21 UTC · model grok-4.3
The pith
AVSD improves language model self-distillation by separating stable cross-view consensus signals from view-specific residuals and adding the latter only when aligned and proportionate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AVSD reconstructs token-level supervision signals by extracting the stable consensus component shared across multiple privileged-information views and then selectively incorporating the view-specific residual component only when that residual both aligns with the consensus direction and remains proportionate to it, thereby producing an update that is reliable at training time yet usable without the extra views at inference time.
What carries the argument
The separation of cross-view consensus signals from view-specific residual signals, followed by conditional addition of residuals only when they align and scale appropriately with the consensus.
If this is right
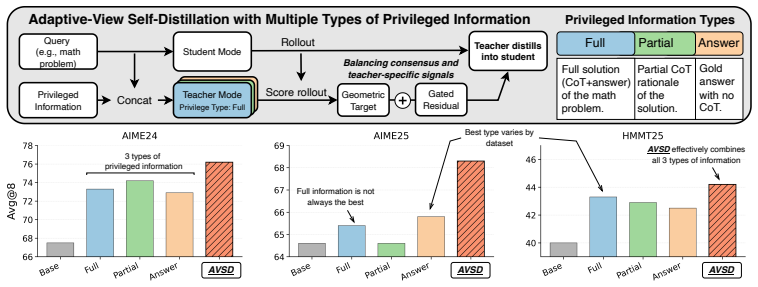
- Performance on AIME24, AIME25, and HMMT25 rises by average gains of 3.1 percent and 2.2 percent over the strongest baselines when using Qwen3-8B and Qwen3-4B models.
- On code-generation tasks such as Codeforces and LiveCodeBench v6 the method yields a 2.4 percent average improvement over single-view self-distillation with the Qwen3-8B model.
- The same training procedure works for both mathematical reasoning and code generation without requiring an external teacher model.
- The approach removes the need to select a single privileged-information view in advance because multiple views are combined through consensus.
Where Pith is reading between the lines
- The same consensus-plus-selective-residual logic could be tested on tasks that supply other forms of on-policy feedback, such as chain-of-thought traces or execution traces.
- If the proportion and alignment checks can be made differentiable, the method might be folded into larger end-to-end training pipelines that currently rely on hand-chosen teacher views.
- The explicit separation of consensus and residual might make it easier to diagnose when a particular view is adding noise rather than signal.
Load-bearing premise
The cross-view consensus signal supplies a reliable update direction and selectively adding view-specific residuals only when they align with and stay proportionate to that consensus improves outcomes without adding harmful noise.
What would settle it
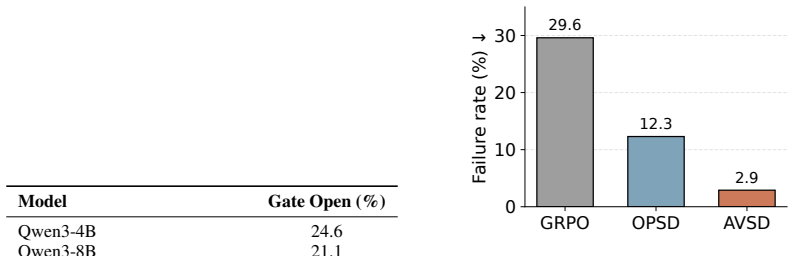
Training runs on the same math and code benchmarks in which the selective residual addition step is replaced by either always adding residuals or never adding them, and performance falls to or below the single-view self-distillation baseline.
Figures






read the original abstract
Self-distillation enables language models to learn on-policy from their own trajectories by using the same model as both student and teacher, with the teacher being conditioned on privileged information unavailable to the student. Such information can come in different types or views, such as solutions, demonstrations, feedback, or final answers. This setup provides dense token-level feedback without relying on a separate external model, but creates a fundamental asymmetry: the teacher may rely on view-specific information that the student cannot access at inference time. Moreover, the best type of privileged information is often task-dependent, making it difficult to choose a single teacher view. In this work, we address both these challenges jointly by introducing AVSD (Adaptive-View Self-Distillation), a novel method of self-distillation with multiple privileged-information views, which reconstructs token-level supervision by separating stable cross-view consensus from view-specific residual signals. AVSD identifies the consensus signal shared across views, which provides a reliable update direction, and then selectively adds the view-specific residual signal to adjust the update magnitude when it both aligns with the consensus direction and remains proportionate to the consensus signal. Experiments on math competition benchmarks (AIME24, AIME25, and HMMT25) show that AVSD consistently outperforms both single-view self-distillation baselines and GRPO, achieving average Avg@8 gains of 3.1% and 2.2% over the strongest baselines on Qwen3-8B and Qwen3-4B, respectively. Moreover, on code-generation benchmarks (Codeforces, LiveCodeBench v6) using Qwen3-8B, AVSD outperforms the single-view self-distillation baseline by 2.4% on average.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AVSD, a self-distillation method for language models that uses multiple views of privileged information (e.g., solutions, demonstrations). It reconstructs token-level supervision by identifying a stable cross-view consensus signal for reliable update direction and selectively adding view-specific residual signals only when they align with the consensus and remain proportionate to it. Experiments on math competition benchmarks (AIME24, AIME25, HMMT25) report average Avg@8 gains of 3.1% and 2.2% over strongest baselines on Qwen3-8B and Qwen3-4B, respectively, with additional 2.4% average gains on code-generation benchmarks (Codeforces, LiveCodeBench v6) using Qwen3-8B, outperforming single-view self-distillation and GRPO.
Significance. If the selective balancing mechanism is robust, AVSD offers a practical advance in handling task-dependent privileged views within self-distillation without external models, potentially improving on-policy learning efficiency for LLMs. The evaluation on recent, challenging competition benchmarks and direct comparisons to GRPO provide concrete evidence of utility; the consistent directional gains support the claim that separating consensus from residuals can mitigate asymmetry in teacher-student views.
major comments (2)
- [§3 (Method)] The alignment metric (e.g., cosine similarity, sign agreement) and proportionality bound for deciding when to add view-specific residuals are described only procedurally in the method without explicit definitions, thresholds, or equations. This leaves the core selection rule underspecified and risks the reported gains arising from implicit ensembling rather than the claimed noise-reduction mechanism.
- [§4 (Experiments)] Table or results section reporting the 3.1% / 2.2% Avg@8 gains on AIME/HMMT and 2.4% on code tasks provides no statistical significance tests, standard deviations across runs, or ablation isolating the effect of the alignment/proportion checks versus extra compute or reweighting. This directly affects verifiability of the central claim that the balancing improves outcomes without harmful noise.
minor comments (2)
- [Abstract] The abstract states gains but omits any mention of run count, variance, or exact threshold values used for residual addition; adding these would improve clarity without altering the claims.
- [§3 (Method)] Notation for consensus signal versus residual signal should be introduced with a clear equation or pseudocode early in §3 to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below. Where the manuscript was underspecified, we have revised it to add formal definitions and additional empirical controls; we believe these changes directly strengthen the verifiability of the central claims.
read point-by-point responses
-
Referee: [§3 (Method)] The alignment metric (e.g., cosine similarity, sign agreement) and proportionality bound for deciding when to add view-specific residuals are described only procedurally in the method without explicit definitions, thresholds, or equations. This leaves the core selection rule underspecified and risks the reported gains arising from implicit ensembling rather than the claimed noise-reduction mechanism.
Authors: We agree that the original description in Section 3 was primarily procedural and would benefit from explicit formalization. In the revised manuscript we have added the following definitions: the alignment metric is the cosine similarity cos(c, r_v) between the consensus vector c and each view-specific residual r_v, supplemented by a sign-agreement check; the proportionality bound is enforced by the condition ||r_v||_2 / ||c||_2 < τ with τ = 1.5 (chosen via a small validation sweep reported in the appendix). The selection rule is now expressed as an equation: the final supervision signal is c + 1_{cos(c,r_v)>0.6 and ||r_v||/||c||<τ} · r_v. We have also included a short variance-reduction argument showing why this selective addition reduces update noise relative to unfiltered averaging. These additions clarify that the mechanism is not equivalent to implicit ensembling. revision: yes
-
Referee: [§4 (Experiments)] Table or results section reporting the 3.1% / 2.2% Avg@8 gains on AIME/HMMT and 2.4% on code tasks provides no statistical significance tests, standard deviations across runs, or ablation isolating the effect of the alignment/proportion checks versus extra compute or reweighting. This directly affects verifiability of the central claim that the balancing improves outcomes without harmful noise.
Authors: We acknowledge that the original submission lacked statistical tests, run-to-run variability, and targeted ablations. In the revision we have added: (i) means and standard deviations computed over five independent random seeds for all main tables; (ii) paired t-tests comparing AVSD against the strongest single-view baseline and GRPO (p < 0.05 for the reported average gains on both model sizes); and (iii) a new ablation table that isolates the alignment/proportionality checks by comparing AVSD against (a) a simple multi-view average with matched compute and (b) a version that omits the selection rule entirely. The ablation results show that removing the checks reduces the gains by roughly half, supporting that the selective mechanism, rather than extra compute or reweighting, drives the improvement. revision: yes
Circularity Check
No significant circularity: method defined procedurally and evaluated on external benchmarks
full rationale
The AVSD method is introduced as a procedural definition that separates cross-view consensus signals from view-specific residuals using alignment and proportionality rules derived directly from the multi-view privileged information setup. Performance claims rest on empirical results from external benchmarks (AIME24/25, HMMT25, Codeforces, LiveCodeBench) rather than any fitted parameters or predictions that reduce to the same data. No equations, self-citations, or imported ansatzes are shown to make the central claims equivalent to their inputs by construction, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- alignment and proportion thresholds for residual addition
axioms (1)
- domain assumption Cross-view consensus provides a stable and reliable update direction for token-level supervision.
invented entities (2)
-
consensus signal
no independent evidence
-
view-specific residual signal
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Geometric Consensus Target … qG_t(v) = (∏ q(m)_t(v))^{1/M} … Arithmetic Marginal Target qA_t(v) = (1/M) ∑ q(m)_t(v) … residual J_t(v) := log qA − log qG … gate λ_t(v) = C_t(v) R_t(v) with C_t = |AG| / avg|Δm| and R_t = |AG| / (|AG| + J)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
reconstructs token-level supervision by separating stable cross-view consensus from view-specific residual signals
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
URLhttps://arxiv.org/abs/2501.12948. Ken Ding. Hdpo: Hybrid distillation policy optimization via privileged self-distillation, 2026. URL https://arxiv.org/abs/2603.23871. Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. MiniLLM: Knowledge distillation of large language models. InThe Twelfth International Conference on Learning Representations, 2024. URLhtt...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
**Expand and rearrange the products**: ac−ad+bc−bd= 9 ac−bc+ad−bd= 25
-
[4]
**Add the two equations to eliminate terms**: 2(ac−bd) = 34 =⇒ac−bd= 17
-
[5]
**Establish a lower bound fora 2 +b 2 +c 2 +d 2**: Since a2 +c 2 ≥2ac (which follows from the AM-GM inequality (a−c) 2 ≥0 ) and b2 +d 2 ≥ −2bd(which follows from(b+d) 2 ≥0): a2 +c 2 ≥2ac 20 b2 +d 2 ≥ −2bd Adding these inequalities yields: a2 +b 2 +c 2 +d 2 ≥2(ac−bd) Givenac−bd= 17: a2 +b 2 +c 2 +d 2 ≥2×17 = 34
-
[6]
Substitutea=candb=−dinto the original equations
**Check if the equality can be achieved**: Equality in the inequalities a2 +c 2 ≥2ac and b2 +d 2 ≥ −2bd is achieved when a=c and b=−d. Substitutea=candb=−dinto the original equations. The first equation becomes: a+b= 9 c−d =⇒a−d= 9 a−d =⇒(a−d) 2 = 9. The second equation becomes: c+d= 25 a−b =⇒a+d= 25 a+d =⇒(a+d) 2 = 25. Taking positive roots gives a−d= 3 ...
-
[7]
**Multiply both given equations by their respective denominators**: (a+b)(c−d) = 9 (c+d)(a−b) = 25
-
[8]
**Expand and rearrange the products**: ac−ad+bc−bd= 9 ac−bc+ad−bd= 25 Final Answer View 34 Example of Multi-View Privileged Information in Math Question.In a company, employees have a combined monthly salary of $10,000. A kind manager proposes to triple the salaries of those earning up to $500, and to increase the salaries of others by $1,000, resulting i...
-
[11]
The firm’s total monthly salary expenditure before any changes is 10,000 dollars. This can be written as: 500x+ yX i=1 si = 10,000 where si represents the individual salaries of the employees earning more than 500 dollars
-
[12]
- Increasing the salaries of employees earning more than 500 dollars by 1000 dollars each
The kind manager proposes the following changes: - Tripling the salaries of employees earning 500 dollars or less. - Increasing the salaries of employees earning more than 500 dollars by 1000 dollars each. The new total salary expenditure proposed by the kind manager is 24,000 dollars. This can be expressed as: 3·500x+ yX i=1 (si + 1000) = 24000
-
[13]
Simplifying the equation: 1500x+ yX i=1 si + 1000y= 24000
-
[14]
Since we know that Py i=1 si = 10000−500x from the original total monthly salary equation, substituting this we get: 1500x+ (10000−500x) + 1000y= 24000
-
[15]
Simplifying further, we obtain: 1000x+ 1000y= 14000 =⇒x+y= 14
-
[16]
- Keeping the salaries of employees earning 500 dollars or less unchanged
The cruel manager proposes the following changes: - Reducing the salaries of employees earning more than 500 dollars to 500 dollars each. - Keeping the salaries of employees earning 500 dollars or less unchanged. The new total salary can be calculated as: 500x+ 500y= 500(x+y)
-
[17]
From step 7, we know that x+y= 14 , so substituting this into the equation for the total salary proposed by the cruel manager: 500·14 = 7000
-
[18]
Conclusion: The new total salary expenditure after the cruel manager’s proposed changes will be: 7000 Partial Solution View
-
[19]
Let us denote by x the total number of employees whose monthly salary is less than or equal to 500 dollars
-
[20]
Letybe the total number of employees whose monthly salary is more than 500 dollars
-
[21]
The firm’s total monthly salary expenditure before any changes is 10,000 dollars. This can be written as: 500x+ yX i=1 si = 10,000 wheres i represents the individual salaries of the employees earning more than 500 dollars. Final Answer View 7000 22 Example of Multi-View Privileged Information in Code Question. Given n sticks with lengths ai, find the maxi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.