DASB - Discrete Audio and Speech Benchmark
Pith reviewed 2026-05-24 00:25 UTC · model grok-4.3
The pith
Discrete audio tokens are less robust than continuous features and need careful tuning of architecture, data size, learning rate, and capacity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
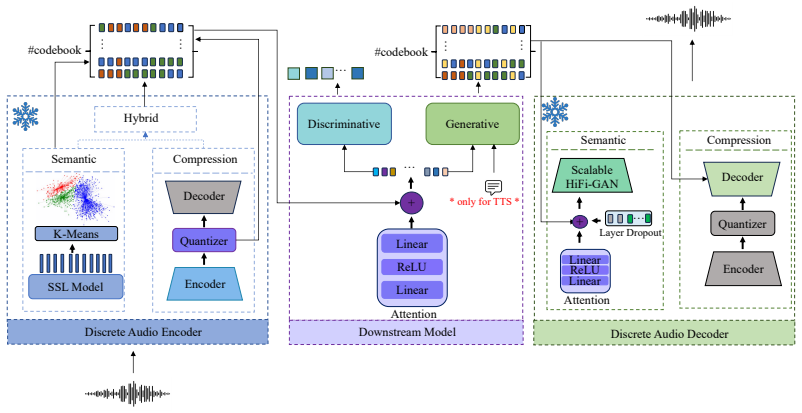
DASB provides a standardized framework for evaluating discrete audio tokens on a range of tasks in speech, audio, and music domains. The evaluation shows discrete representations are less robust than continuous ones and require careful tuning of model architecture, data size, learning rate, and capacity. Semantic tokens outperform acoustic tokens, but a performance gap to continuous features persists, indicating that further research is needed to make discrete tokens reliable for multimodal language models.
What carries the argument
The DASB benchmark framework, which applies consistent tasks and metrics across domains to compare discrete tokens against continuous features.
If this is right
- Semantic tokens should be preferred over acoustic tokens for most speech and audio tasks when using discrete representations.
- Model capacity, data volume, and learning rate must be tuned specifically for each discrete tokenizer to achieve reliable results.
- A performance gap to continuous features will persist until new tokenizer designs or training methods are developed.
- Inconsistent evaluation settings in prior work likely masked the full extent of robustness issues with discrete tokens.
Where Pith is reading between the lines
- Developers of multimodal language models may need to combine discrete and continuous representations to reach full performance on audio understanding and generation.
- The benchmark setup could be extended to additional languages or noisy environments to test whether the observed gaps hold under more varied conditions.
- Results may encourage work on hybrid tokenizers that aim to retain the efficiency of discrete units while approaching continuous feature robustness.
Load-bearing premise
The chosen tasks, domains, and metrics are representative enough to reveal general limitations of discrete tokens compared to continuous features.
What would settle it
A follow-up experiment on the same models but with a new set of tasks outside the benchmark's covered domains that finds discrete tokens matching or exceeding continuous performance on key metrics.
Figures

read the original abstract
Discrete audio tokens have recently gained considerable attention for their potential to bridge audio and language processing, enabling multimodal language models that can both generate and understand audio. However, preserving key information such as phonetic content, speaker identity, and paralinguistic cues remains a major challenge. Identifying the optimal tokenizer and configuration is further complicated by inconsistent evaluation settings across existing studies. To address this, we introduce the Discrete Audio and Speech Benchmark (DASB), a comprehensive framework for benchmarking discrete audio tokens across speech, general audio, and music domains on a range of discriminative and generative tasks. Our results show that discrete representations are less robust than continuous ones and require careful tuning of factors such as model architecture, data size, learning rate, and capacity. Semantic tokens generally outperform acoustic tokens, but a gap remains between discrete tokens and continuous features, highlighting the need for further research. DASB codes, evaluation setup, and leaderboards are publicly available at https://poonehmousavi.github.io/DASB-website/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Discrete Audio and Speech Benchmark (DASB), a standardized framework for evaluating discrete audio tokens on discriminative and generative tasks spanning speech, general audio, and music domains. It reports empirical comparisons showing that discrete representations are less robust than continuous features, require careful tuning of model architecture, data size, learning rate, and capacity, that semantic tokens generally outperform acoustic tokens, and that a performance gap to continuous features persists; the benchmark, code, and leaderboards are released publicly.
Significance. If the controlled comparisons hold, DASB provides a valuable public resource for consistent evaluation of discrete audio tokens, addressing the inconsistency noted in prior work and highlighting practical challenges for multimodal models. The explicit controls for architecture, data size, LR, and capacity, together with public code and leaderboards, are strengths that support reproducibility and community follow-up.
minor comments (2)
- The abstract and benchmark description reference comparative findings; the manuscript should include explicit details on data splits, statistical tests, error bars, and hyperparameter search ranges in the experimental sections to allow full verification of the robustness claims.
- Task and domain selection (speech, audio, music) should include a short justification subsection explaining why the chosen metrics and tasks are expected to be representative for identifying general limitations of discrete versus continuous representations.
Simulated Author's Rebuttal
We thank the referee for the constructive and positive review, which recognizes the value of DASB as a standardized benchmark and the importance of the controlled comparisons. We are pleased with the recommendation for minor revision and will incorporate any minor suggestions in the revised version.
Circularity Check
No circularity: empirical benchmark with no derivations or self-referential predictions
full rationale
The paper presents DASB as an empirical evaluation framework for discrete audio tokens across tasks and domains, reporting comparative results on robustness, semantic vs. acoustic tokens, and gaps to continuous features. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear; all claims rest on controlled experiments with public code. The work is therefore self-contained against external benchmarks and contains no circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing discriminative and generative tasks in speech, audio, and music are appropriate proxies for measuring preservation of phonetic, speaker, and paralinguistic information.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our results show that discrete representations are less robust than continuous ones... semantic tokens generally outperform acoustic tokens, but a gap remains between discrete tokens and continuous features.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
bitrate = log2 V · C · R; semantic vs compression vs hybrid tokenizers
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
StableToken: A Noise-Robust Semantic Speech Tokenizer for Resilient SpeechLLMs
StableToken introduces a multi-branch architecture with bit-wise voting to create noise-robust semantic speech tokens, achieving lower Unit Edit Distance and better SpeechLLM robustness than prior single-path tokenizers.
-
On The Landscape of Spoken Language Models: A Comprehensive Survey
A literature survey that organizes spoken language models by architecture, training, and evaluation choices and identifies key challenges and future directions.
Reference graph
Works this paper leans on
-
[1]
Fundamentals of Speech Recognition
Lawrence Rabiner and Biing-Hwang Juang. Fundamentals of Speech Recognition. Prentice-Hall Signal Processing Series, 1993
work page 1993
-
[2]
wav2vec 2.0: A framework for self-supervised learning of speech representations
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: A framework for self-supervised learning of speech representations. In International Conference on Neural Information Processing Systems (NeurIPS), volume 33, pages 12449–12460, 2020
work page 2020
-
[3]
WavLM: Large-scale self-supervised pre-training for full stack speech processing
Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, et al. WavLM: Large-scale self-supervised pre-training for full stack speech processing. IEEE Journal of Selected Topics in Signal Processing, 16(6):1505–1518, 2022
work page 2022
-
[4]
HuBERT: Self-supervised speech representation learning by masked prediction of hidden units
Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. HuBERT: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:3451–3460, 2021
work page 2021
-
[5]
Speech resynthesis from discrete disentangled self-supervised representations
Adam Polyak, Yossi Adi, Jade Copet, Eugene Kharitonov, Kushal Lakhotia, Wei-Ning Hsu, Abdelrah- man Mohamed, and Emmanuel Dupoux. Speech resynthesis from discrete disentangled self-supervised representations. In Interspeech, pages 3615–3619, 2021
work page 2021
-
[6]
Phonetic analysis of self-supervised representations of English speech
Dan Wells, Hao Tang, and Korin Richmond. Phonetic analysis of self-supervised representations of English speech. In Interspeech, pages 3583–3587, 2022
work page 2022
-
[7]
Yu-An Chung, Yu Zhang, Wei Han, Chung-Cheng Chiu, James Qin, Ruoming Pang, and Yonghui Wu. w2v-BERT: Combining contrastive learning and masked language modeling for self-supervised speech pre-training. In IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pages 244–250, 2021. 9
work page 2021
-
[8]
SpeechTokenizer: Unified speech tokenizer for speech large language models
Xin Zhang, Dong Zhang, Shimin Li, Yaqian Zhou, and Xipeng Qiu. SpeechTokenizer: Unified speech tokenizer for speech large language models. In International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[9]
FunCodec: A fundamental, reproducible and integrable open-source toolkit for neural speech codec
Zhihao Du, Shiliang Zhang, Kai Hu, and Siqi Zheng. FunCodec: A fundamental, reproducible and integrable open-source toolkit for neural speech codec. arXiv preprint arXiv:2309.07405, 2023
-
[10]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
PaLM: scaling language modeling with pathways
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. PaLM: scaling language modeling with pathways. Journal of Machine Learning Research, 24, 2024
work page 2024
-
[12]
BERT: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In Jill Burstein, Christy Doran, and Thamar Solorio, editors, Conference of the North American Chapter of the Association for Computational Linguistics (NAACL): Human Language Technologies, Volume 1 (Long and ...
work page 2019
-
[13]
Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. GPT understands, too. AI Open, 2023
work page 2023
-
[14]
Neural discrete representation learning
Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural discrete representation learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, 2017
work page 2017
-
[15]
Paul K. Rubenstein, Chulayuth Asawaroengchai, Duc Dung Nguyen, Ankur Bapna, Zalán Borsos, Félix de Chaumont Quitry, Peter Chen, Dalia El Badawy, Wei Han, Eugene Kharitonov, Hannah Muckenhirn, et al. AudioPaLM: A large language model that can speak and listen. arXiv preprint arXiv:2306.12925, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
LauraGPT: Listen, attend, understand, and regenerate audio with GPT
Jiaming Wang, Zhihao Du, Qian Chen, Yunfei Chu, Zhifu Gao, Zerui Li, Kai Hu, Xiaohuan Zhou, Jin Xu, Ziyang Ma, Wen Wang, Siqi Zheng, Chang Zhou, Zhijie Yan, and Shiliang Zhang. LauraGPT: Listen, attend, understand, and regenerate audio with GPT. arXiv preprint arXiv:2310.04673, 2023
-
[17]
VioLA: Unified codec language models for speech recognition, synthesis, and translation
Tianrui Wang, Long Zhou, Ziqiang Zhang, Yu Wu, Shujie Liu, Yashesh Gaur, Zhuo Chen, Jinyu Li, and Furu Wei. VioLA: Unified codec language models for speech recognition, synthesis, and translation. arXiv preprint arXiv:2305.16107, 2023
-
[19]
SpeechX: Neural codec language model as a versatile speech transformer
Xiaofei Wang, Manthan Thakker, Zhuo Chen, Naoyuki Kanda, Sefik Emre Eskimez, Sanyuan Chen, Min Tang, Shujie Liu, Jinyu Li, and Takuya Yoshioka. SpeechX: Neural codec language model as a versatile speech transformer. arXiv preprint arXiv:2308.06873, 2023
-
[20]
MusicLM: Generating Music From Text
Andrea Agostinelli et al. MusicLM: Generating music from text. arXiv preprint arXiv:2301.11325, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
AudioGen: Textually guided audio generation
Felix Kreuk, Gabriel Synnaeve, Adam Polyak, Uriel Singer, Alexandre Défossez, Jade Copet, Devi Parikh, Yaniv Taigman, and Yossi Adi. AudioGen: Textually guided audio generation. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[22]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Google. Gemini: A family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Goodfellow, Yoshua Bengio, and Aaron Courville
Ian J. Goodfellow, Yoshua Bengio, and Aaron Courville. Deep Learning. MIT Press, 2016
work page 2016
-
[24]
Codec-SUPERB: An in-depth analysis of sound codec models
Haibin Wu, Ho-Lam Chung, Yi-Cheng Lin, Yuan-Kuei Wu, Xuanjun Chen, Yu-Chi Pai, Hsiu-Hsuan Wang, Kai-Wei Chang, Alexander H Liu, and Hung-yi Lee. Codec-SUPERB: An in-depth analysis of sound codec models. arXiv preprint arXiv:2402.13071, 2024
-
[25]
Puvvada, Nithin Rao Koluguri, Kunal Dhawan, Jagadeesh Balam, and Boris Ginsburg
Krishna C. Puvvada, Nithin Rao Koluguri, Kunal Dhawan, Jagadeesh Balam, and Boris Ginsburg. Discrete audio representation as an alternative to Mel-spectrograms for speaker and speech recognition. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages 12111–12115, 2024
work page 2024
-
[26]
SELM: Speech enhancement using discrete tokens and language models
Ziqian Wang, Xinfa Zhu, Zihan Zhang, YuanJun Lv, Ning Jiang, Guoqing Zhao, and Lei Xie. SELM: Speech enhancement using discrete tokens and language models. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 11561–11565, 2024
work page 2024
-
[27]
DUB: Discrete unit back-translation for speech translation
Dong Zhang, Rong Ye, Tom Ko, Mingxuan Wang, and Yaqian Zhou. DUB: Discrete unit back-translation for speech translation. In Findings of the Association for Computational Linguistics: ACL, pages 7147– 7164, 2023. 10
work page 2023
-
[28]
Xuankai Chang, Brian Yan, Kwanghee Choi, Jee-Weon Jung, Yichen Lu, Soumi Maiti, Roshan Sharma, Jiatong Shi, Jinchuan Tian, Shinji Watanabe, Yuya Fujita, et al. Exploring speech recognition, translation, and understanding with discrete speech units: A comparative study. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), p...
work page 2024
-
[29]
High fidelity neural audio compression
Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. High fidelity neural audio compression. Transactions on Machine Learning Research (TMLR), 2023
work page 2023
-
[30]
High-fidelity au- dio compression with improved RVQGAN
Rithesh Kumar, Prem Seetharaman, Alejandro Luebs, Ishaan Kumar, and Kundan Kumar. High-fidelity au- dio compression with improved RVQGAN. In International Conference on Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[31]
Salah Zaiem, Youcef Kemiche, Titouan Parcollet, Slim Essid, and Mirco Ravanelli. Speech self-supervised representation benchmarking: Are we doing it right? In Interspeech, pages 2873–2877, 2023
work page 2023
-
[32]
SpeechBrain: A general- purpose speech toolkit
Mirco Ravanelli, Titouan Parcollet, Peter Plantinga, Aku Rouhe, Samuele Cornell, Loren Lugosch, Cem Subakan, Nauman Dawalatabad, Abdelwahab Heba, Jianyuan Zhong, et al. SpeechBrain: A general- purpose speech toolkit. arXiv preprint arXiv:2106.04624, 2021
-
[33]
Exploration of efficient end-to-end ASR using discretized input from self-supervised learning
Xuankai Chang, Brian Yan, Yuya Fujita, Takashi Maekaku, and Shinji Watanabe. Exploration of efficient end-to-end ASR using discretized input from self-supervised learning. In Interspeech, pages 1399–1403, 2023
work page 2023
-
[34]
Towards universal speech discrete tokens: A case study for ASR and TTS
Yifan Yang, Feiyu Shen, Chenpeng Du, Ziyang Ma, Kai Yu, Daniel Povey, and Xie Chen. Towards universal speech discrete tokens: A case study for ASR and TTS. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 10401–10405, 2024
work page 2024
-
[35]
Hakan Erdogan, Scott Wisdom, Xuankai Chang, Zalán Borsos, Marco Tagliasacchi, Neil Zeghidour, and John R Hershey. TokenSplit: Using discrete speech representations for direct, refined, and transcript- conditioned speech separation and recognition. In Interspeech, pages 3462–3466, 2023
work page 2023
-
[36]
Evaluating text-to-speech synthesis from a large discrete token-based speech language model
Siyang Wang and Éva Székely. Evaluating text-to-speech synthesis from a large discrete token-based speech language model. In Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING), pages 6464–6474, 2024
work page 2024
-
[37]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, et al. Neural codec language models are zero-shot text to speech synthesizers. arXiv preprint arXiv:2301.02111, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Speak, read and prompt: High-fidelity text-to-speech with minimal supervision
Eugene Kharitonov, Damien Vincent, Zalán Borsos, Raphaël Marinier, Sertan Girgin, Olivier Pietquin, Matt Sharifi, Marco Tagliasacchi, and Neil Zeghidour. Speak, read and prompt: High-fidelity text-to-speech with minimal supervision. Transactions of the Association for Computational Linguistics, 11:1703–1718, 2023
work page 2023
-
[39]
How should we extract discrete audio tokens from self-supervised models?, 2024
Pooneh Mousavi, Jarod Duret, Salah Zaiem, Luca Della Libera, Artem Ploujnikov, Cem Subakan, and Mirco Ravanelli. How should we extract discrete audio tokens from self-supervised models?, 2024
work page 2024
-
[40]
Shu wen Yang, Po-Han Chi, Yung-Sung Chuang, Cheng-I Jeff Lai, Kushal Lakhotia, Yist Y . Lin, Andy T. Liu, Jiatong Shi, Xuankai Chang, Guan-Ting Lin, et al. SUPERB: Speech Processing Universal PERfor- mance Benchmark. In Interspeech, pages 1194–1198, 2021
work page 2021
-
[41]
Definition of the Opus audio codec
Jean-Marc Valin, Koen V os, and Timothy Terriberry. Definition of the Opus audio codec. Technical report, 2012
work page 2012
-
[42]
Overview of the EVS codec architecture
Martin Dietz, Markus Multrus, Vaclav Eksler, Vladimir Malenovsky, Erik Norvell, Harald Pobloth, Lei Miao, Zhe Wang, Lasse Laaksonen, Adriana Vasilache, et al. Overview of the EVS codec architecture. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5698–5702, 2015
work page 2015
-
[43]
SoundStream: An end-to-end neural audio codec
Neil Zeghidour, Alejandro Luebs, Ahmed Omran, Jan Skoglund, and Marco Tagliasacchi. SoundStream: An end-to-end neural audio codec. IEEE/ACM Transactions on Audio, Speech, and Language Processing, pages 495–507, 2021
work page 2021
-
[44]
AudioLM: A language modeling approach to audio generation
Zalán Borsos, Raphaël Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matt Sharifi, Dominik Roblek, Olivier Teboul, David Grangier, Marco Tagliasacchi, and Neil Zeghidour. AudioLM: A language modeling approach to audio generation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31:2523–2533, 2023
work page 2023
-
[45]
HiFi- Codec: Group-residual vector quantization for high fidelity audio codec
Dongchao Yang, Songxiang Liu, Rongjie Huang, Jinchuan Tian, Chao Weng, and Yuexian Zou. HiFi- Codec: Group-residual vector quantization for high fidelity audio codec. arXiv preprint arXiv:2305.02765, 2023
-
[46]
Free English and Czech telephone speech corpus shared under the CC-BY-SA 3.0 license
Matˇej Korvas, Ondˇrej Plátek, Ondˇrej Dušek, Lukáš Žilka, and Filip Jur ˇcíˇcek. Free English and Czech telephone speech corpus shared under the CC-BY-SA 3.0 license. InInternational Conference on Language Resources and Evaluation (LREC), pages 4423–4428, 2014. 11
work page 2014
-
[47]
Wei Han, Zhengdong Zhang, Yu Zhang, Jiahui Yu, Chung-Cheng Chiu, James Qin, Anmol Gulati, Ruoming Pang, and Yonghui Wu. ContextNet: Improving convolutional neural networks for automatic speech recognition with global context. In Interspeech, pages 3610–3614, 2020
work page 2020
-
[48]
Common V oice: A massively-multilingual speech corpus
Rosana Ardila, Megan Branson, Kelly Davis, Michael Kohler, Josh Meyer, Michael Henretty, Reuben Morais, Lindsay Saunders, Francis Tyers, and Gregor Weber. Common V oice: A massively-multilingual speech corpus. In Language Resources and Evaluation Conference (LREC), pages 4218–4222, 2020
work page 2020
-
[49]
V oxCeleb: A large-scale speaker identification dataset
Arsha Nagrani, Joon Son Chung, and Andrew Zisserman. V oxCeleb: A large-scale speaker identification dataset. In Interspeech, pages 2616–2620, 2017
work page 2017
-
[50]
X-vectors: Robust DNN embeddings for speaker recognition
David Snyder, Daniel Garcia-Romero, Gregory Sell, Daniel Povey, and Sanjeev Khudanpur. X-vectors: Robust DNN embeddings for speaker recognition. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5329–5333, 2018
work page 2018
-
[51]
Additive margin softmax for face verification
Feng Wang, Jian Cheng, Weiyang Liu, and Haijun Liu. Additive margin softmax for face verification. IEEE Signal Processing Letters, 25(7):926–930, 2018
work page 2018
-
[52]
Brecht Desplanques, Jenthe Thienpondt, and Kris Demuynck. ECAPA-TDNN: Emphasized channel attention, propagation and aggregation in TDNN based speaker verification. In Interspeech, pages 3830– 3834, 2020
work page 2020
-
[53]
IEMOCAP: Interactive emotional dyadic motion capture database
Carlos Busso, Murtaza Bulut, Chi-Chun Lee, Abe Kazemzadeh, Emily Mower, Samuel Kim, Jeannette N Chang, Sungbok Lee, and Shrikanth S Narayanan. IEMOCAP: Interactive emotional dyadic motion capture database. Language resources and evaluation, 42:335–359, 2008
work page 2008
-
[54]
SLURP: A spoken language understanding resource package
Emanuele Bastianelli, Andrea Vanzo, Pawel Swietojanski, and Verena Rieser. SLURP: A spoken language understanding resource package. In Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 7252–7262, 2020
work page 2020
-
[55]
Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition
Pete Warden. Speech Commands: A dataset for limited-vocabulary speech recognition. arXiv preprint arXiv:1804.03209, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[56]
Investigating RNN-based speech enhancement methods for noise-robust text-to-speech
Cassia Valentini-Botinhao, Xin Wang, Shinji Takaki, and Junichi Yamagishi. Investigating RNN-based speech enhancement methods for noise-robust text-to-speech. In Speech Synthesis Workshop, pages 146–152, 2016
work page 2016
-
[57]
Conformer: Convolution-augmented transformer for speech recognition
Anmol Gulati, James Qin, Chung-Cheng Chiu, Niki Parmar, Yu Zhang, Jiahui Yu, Wei Han, Shibo Wang, Zhengdong Zhang, Yonghui Wu, and Ruoming Pang. Conformer: Convolution-augmented transformer for speech recognition. In Interspeech, pages 5036–5040, 2020
work page 2020
-
[58]
Chandan KA Reddy, Vishak Gopal, and Ross Cutler. DNSMOS P.835: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022
work page 2022
-
[59]
Sequential multi-frame neural beamforming for speech separation and enhancement
Zhong-Qiu Wang et al. Sequential multi-frame neural beamforming for speech separation and enhancement. In IEEE Spoken Language Technology (SLT) Workshop, pages 905–911, 2021
work page 2021
-
[60]
Robust Speech Recognition via Large-Scale Weak Supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. arXiv preprint arXiv:2212.04356, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[61]
LibriMix: An open-source dataset for generalizable speech separation
Joris Cosentino, Manuel Pariente, Samuele Cornell, Antoine Deleforge, and Emmanuel Vincent. LibriMix: An open-source dataset for generalizable speech separation. arXiv preprint arXiv:2005.11262, 2020
- [62]
-
[63]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In International Conference on Neural Information Processing Systems (NeurIPS), pages 6000–6010, 2017
work page 2017
-
[64]
Keith Ito. The LJ speech dataset. https://keithito.com/LJ-Speech-Dataset/, 2017
work page 2017
-
[65]
UTMOS: UTokyo-SaruLab System for V oiceMOS Challenge 2022
Saeki Takaaki et al. UTMOS: UTokyo-SaruLab System for V oiceMOS Challenge 2022. InInterspeech, pages 4521–4525, 2022
work page 2022
-
[66]
A comparison of discrete and soft speech units for improved voice conversion
Benjamin van Niekerk, Marc-André Carbonneau, Julian Zaïdi, Matthew Baas, Hugo Seuté, and Herman Kamper. A comparison of discrete and soft speech units for improved voice conversion. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6562–6566, 2022
work page 2022
-
[67]
Gebru, Dejan Markovi ´c, and Alexander Richard
Yi-Chiao Wu, Israel D. Gebru, Dejan Markovi ´c, and Alexander Richard. Audiodec: An open-source streaming high-fidelity neural audio codec. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5, 2023
work page 2023
-
[68]
ICASSP 2023 deep noise suppression challenge
Harishchandra Dubey, Ashkan Aazami, Vishak Gopal, Babak Naderi, Sebastian Braun, Ross Cutler, Alex Ju, Mehdi Zohourian, Min Tang, Mehrsa Golestaneh, et al. ICASSP 2023 deep noise suppression challenge. IEEE Open Journal of Signal Processing, 2024. 12
work page 2023
-
[69]
Audio Set: An ontology and human-labeled dataset for audio events
Jort F Gemmeke, Daniel PW Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R Channing Moore, Manoj Plakal, and Marvin Ritter. Audio Set: An ontology and human-labeled dataset for audio events. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 776–780, 2017
work page 2017
-
[70]
FSD50K: an open dataset of human-labeled sound events
Eduardo Fonseca, Xavier Favory, Jordi Pons, Frederic Font, and Xavier Serra. FSD50K: an open dataset of human-labeled sound events. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30:829–852, 2021
work page 2021
-
[71]
The MTG-Jamendo dataset for automatic music tagging
Dmitry Bogdanov, Minz Won, Philip Tovstogan, Alastair Porter, and Xavier Serra. The MTG-Jamendo dataset for automatic music tagging. In International Conference on Machine Learning (ICML), 2019
work page 2019
-
[72]
Gautham J Mysore. Can we automatically transform speech recorded on common consumer devices in real-world environments into professional production quality speech?—A dataset, insights, and challenges. IEEE Signal Processing Letters, 22(8):1006–1010, 2014
work page 2014
-
[73]
CSTR VCTK Corpus: English multi- speaker corpus for CSTR voice cloning toolkit (version 0.92), 2019
Junichi Yamagishi, Christophe Veaux, and Kirsten MacDonald. CSTR VCTK Corpus: English multi- speaker corpus for CSTR voice cloning toolkit (version 0.92), 2019
work page 2019
-
[74]
The MUSDB18 corpus for music separation
Zafar Rafii, Antoine Liutkus, Fabian-Robert Stöter, Stylianos Ioannis Mimilakis, and Rachel Bittner. The MUSDB18 corpus for music separation. https://doi.org/10.5281/zenodo.1117372, 2017
-
[75]
Jonathan Shen, Ruoming Pang, Ron J. Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, Rj Skerrv-Ryan, Rif A. Saurous, Yannis Agiomvrgiannakis, and Yonghui Wu. Natural TTS synthesis by conditioning WaveNet on Mel spectrogram predictions. In IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (I...
work page 2018
-
[76]
Hideyuki Tachibana, Katsuya Uenoyama, and Shunsuke Aihara. Efficiently trainable text-to-speech system based on deep convolutional networks with guided attention. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 4784–4788, 2018. 13 A General Information A.1 Computational Resources We designed our benchmark to be ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.