Computing k-means in mixed precision
Pith reviewed 2026-05-23 22:31 UTC · model grok-4.3
The pith
Lloyd's k-means remains stable when distance computations drop to lower precision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
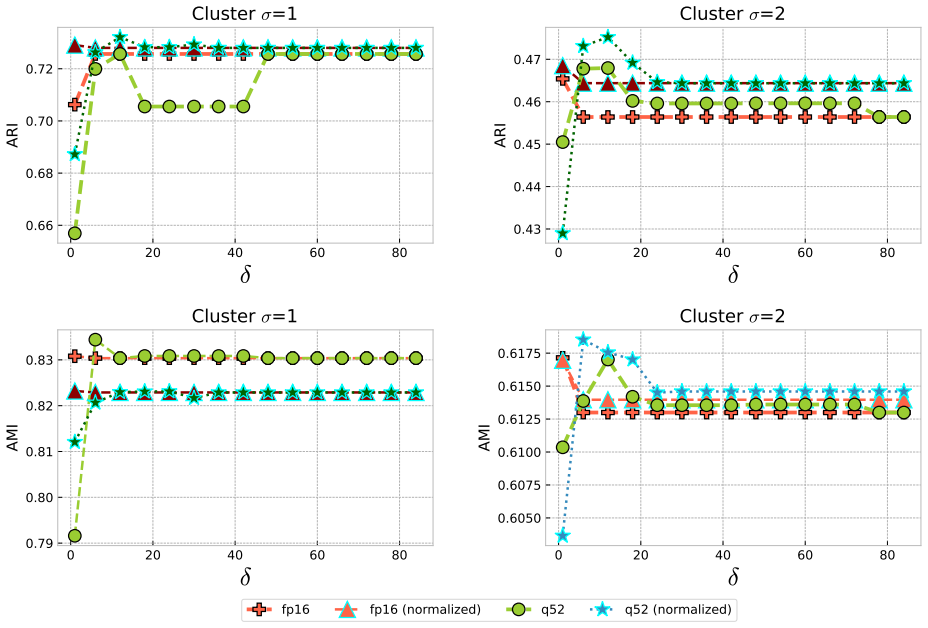
We confirm the stability of the widely used distance computation formula. We propose a mixed-precision framework for k-means computation and investigate the effects of low-precision distance computation within the framework. Through extensive simulations on various data clustering and image segmentation tasks, we verify the applicability and robustness of the mixed precision k-means method. We find that, in k-means computation, normalized data is more tolerant to the reduction of precision in the distance computation, while for unnormalized data more care is needed in the use of reduced precision, mainly to avoid overflow.
What carries the argument
Mixed-precision framework that performs distance calculations in low precision inside Lloyd's iteration while retaining higher precision for other operations.
If this is right
- Normalized input data tolerates lower precision in distance kernels with little change in clustering quality.
- Unnormalized data requires safeguards against overflow when reduced precision is used for distances.
- The mixed-precision distance kernel can be reused to accelerate other distance-based machine-learning routines.
- Hardware support for low-precision arithmetic offers a practical route to faster k-means execution.
Where Pith is reading between the lines
- If the stability holds beyond the tested cases, then k-means implementations on GPUs or AI accelerators could default to mixed-precision distances for an immediate performance gain.
- The same distance-kernel substitution might be tested on streaming or online variants of k-means where data arrives continuously.
- A natural next measurement is the exact speedup and energy saving on specific mixed-precision hardware when the framework is implemented in a production library.
Load-bearing premise
The chosen simulation datasets and tasks represent the numerical behavior that will appear in other k-means workloads.
What would settle it
A dataset and cluster count where switching only the distance kernel to low precision produces measurably different final assignments or higher within-cluster sum of squares than the full-precision run.
Figures







read the original abstract
The k-means algorithm is one of the most popular and critical techniques in data mining and machine learning, and it has achieved significant success in numerous science and engineering domains. Computing k-means to a global optimum is NP-hard in Euclidean space, yet there are a variety of efficient heuristic algorithms, such as Lloyd's algorithm, that converge to a local optimum with superpolynomial complexity in the worst case. Motivated by the emergence and prominence of mixed precision capabilities in hardware, a current trend is to develop low and mixed precision variants of algorithms in order to improve the runtime and energy consumption. In this paper we study the numerical stability of Lloyd's k-means algorithm, and, in particular, we confirm the stability of the widely used distance computation formula. We propose a mixed-precision framework for k-means computation and investigate the effects of low-precision distance computation within the framework. Through extensive simulations on various data clustering and image segmentation tasks, we verify the applicability and robustness of the mixed precision k-means method. We find that, in k-means computation, normalized data is more tolerant to the reduction of precision in the distance computation, while for unnormalized data more care is needed in the use of reduced precision, mainly to avoid overflow. Our study demonstrates the potential for the use of mixed precision distance kernels to accelerate the k-means computation and offers insights into other distance-based machine learning methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the widely used distance computation formula in Lloyd's k-means is numerically stable, proposes a mixed-precision framework for k-means, and verifies the applicability and robustness of low-precision distance computation within this framework via extensive simulations on data clustering and image segmentation tasks. It concludes that normalized data tolerates reduced precision better than unnormalized data, which requires care mainly to avoid overflow, and highlights potential for accelerating k-means with mixed-precision kernels.
Significance. If the empirical results hold, the work provides concrete evidence that mixed-precision distance kernels can be used to accelerate k-means while preserving stability on the tested workloads, offering practical insights for other distance-based ML algorithms. The explicit distinction between normalized and unnormalized data behaviors, together with the empirical validation against external datasets, strengthens the contribution in the context of emerging mixed-precision hardware.
major comments (2)
- [Simulation and results sections] The central stability and robustness claims rest on the simulation results, yet the manuscript summarizes (rather than fully specifies) the exact precision formats, datasets, overflow handling, and error-bar analysis; this limits the ability to assess reproducibility and generality of the reported outcomes.
- [Discussion and conclusions] No analytic bounds or conditions are derived on data norms relative to low-precision exponent ranges or on accumulation error in the ||x||² + ||y||² – 2<x,y> formula under varying k or dimension; while the paper is empirical, the absence of such guidance leaves open the possibility of divergence outside the tested regimes.
minor comments (1)
- [Abstract and results] The abstract states that 'normalized data is more tolerant' but the corresponding quantitative comparison (e.g., failure rates or assignment differences) should be highlighted with a dedicated table or figure reference in the main text.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, the recommendation of minor revision, and the constructive comments on reproducibility and guidance. We address each major comment below.
read point-by-point responses
-
Referee: [Simulation and results sections] The central stability and robustness claims rest on the simulation results, yet the manuscript summarizes (rather than fully specifies) the exact precision formats, datasets, overflow handling, and error-bar analysis; this limits the ability to assess reproducibility and generality of the reported outcomes.
Authors: We agree that additional detail is required. In the revised manuscript we will add a new subsection that explicitly lists all precision formats employed (including FP32, FP16, and BF16), provides the full set of datasets with sources, dimensions, and preprocessing (normalization or lack thereof), describes the overflow-handling strategy (dynamic scaling when the exponent range is approached), and reports error bars obtained from multiple independent runs together with standard deviations. revision: yes
-
Referee: [Discussion and conclusions] No analytic bounds or conditions are derived on data norms relative to low-precision exponent ranges or on accumulation error in the ||x||² + ||y||² – 2<x,y> formula under varying k or dimension; while the paper is empirical, the absence of such guidance leaves open the possibility of divergence outside the tested regimes.
Authors: The work is deliberately empirical. We will expand the discussion section to supply practical, experiment-derived guidance on observed safe ranges of data norms relative to the tested exponent widths and to comment on accumulation behavior across the range of k and dimensions examined. We will also state explicitly that general analytic bounds are outside the paper’s scope and note the consequent limitation on extrapolation beyond the tested regimes. revision: partial
Circularity Check
No circularity: empirical validation against external datasets
full rationale
The paper's central claims rest on proposing a mixed-precision framework for Lloyd's k-means and confirming stability of the standard distance formula via direct numerical simulations on chosen clustering and segmentation datasets. No equations, fitted parameters, or predictions are defined in terms of the reported outcomes; the verification steps use external data and do not reduce to self-referential inputs or self-citation chains. The work is self-contained as empirical evidence without load-bearing derivations that collapse by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Standard properties of floating-point arithmetic (IEEE 754 rounding, overflow behavior) govern the distance computations.
- domain assumption The simulation data sets and tasks are representative of typical k-means workloads.
Reference graph
Works this paper leans on
- [1]
-
[2]
H. J ´egou, M. Douze, C. Schmid, Product quantization for nearest neighbor search, IEEE Transactions on Pattern Analysis and Machine Intelligence 33 (1) (2010) 117–128. doi:10.1109/TPAMI.2010.57
-
[3]
M. Norouzi, D. J. Fleet, Cartesian K-means, in: 2013 IEEE Conference on Computer Vision and Pattern Recognition, IEEE, 2013, pp. 3017–3024. doi:10.1109/CVPR.2013.388
-
[4]
J. Jorda, A. V . Kajava, T-REKS: identification of Tandem REpeats in sequences with a K-meanS based algorithm, Bioinformatics 25 (20) (2009) 2632–2638. doi:10.1093/bioinformatics/btp482
-
[5]
P. A. Marin Zapata, S. Roth, D. Schmutzler, T. Wolf, E. Manesso, D. Clevert, Self-supervised feature extraction from image time series in plant phenotyping using triplet networks, Bioinformatics 37 (6) (2020) 861–867. doi:10.1093/bioinformatics/btaa905
-
[6]
J. H. Young, M. Peyton, H.-S. Kim, E. McMillan, J. D. Minna, M. A. White, E. M. Marcotte, Computational discovery of pathway-level genetic vulnerabilities in non-small-cell lung cancer, Bioinformatics 32 (9) (2016) 1373–1379. doi:10.1093/bioinformatics/btw010
-
[7]
Z. Chen, Q. Sun, Extracting class activation maps from non-discriminative features as well, in: 2023 IEEE /CVF Conference on Computer Vision and Pattern Recognition, IEEE, 2023, pp. 3135–3144. doi:10.1109/CVPR52729.2023.00306
-
[8]
J. Puzicha, T. Hofmann, J. M. Buhmann, Histogram clustering for unsupervised image segmentation, in: Proceedings. 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, IEEE, 1999, pp. 602–608. doi:10.1109/CVPR.1999.784981
-
[9]
C. Zhong, Z. Sun, T. Tan, Robust 3D face recognition using learned visual codebook, in: IEEE Conference on Computer Vision and Pattern Recognition, IEEE, 2007. doi:10.1109/CVPR.2007.383279
-
[10]
S. R. Gaddam, V . V . Phoha, K. S. Balagani, K-means+ID3: A novel method for supervised anomaly detection by cascading k-means clustering and ID3 decision tree learning methods, IEEE Transactions on Knowledge and Data Engineering 19 (3) (2007) 345–354. doi:10.1109/ TKDE.2007.44
work page 2007
-
[11]
S. Gupta, R. Kumar, K. Lu, B. Moseley, S. Vassilvitskii, Local search methods for k-means with outliers, Proc. VLDB Endow. 10 (7) (2017) 757–768. doi:10.14778/3067421.3067425
-
[12]
C. Ordonez, E. Omiecinski, E fficient disk-based k-means clustering for relational databases, IEEE Transactions on Knowledge and Data Engineering 16 (8) (2004) 909–921. doi:10.1109/TKDE.2004.25
-
[13]
S. Wang, Y . Sun, Z. Bao, On the e fficiency of K-means clustering: Evaluation, optimization, and algorithm selection, Proc. VLDB Endow. 14 (2) (2020) 163–175. doi:10.14778/3425879.3425887
-
[14]
S. Guo, N. Yao, Document vector extension for documents classification, IEEE Transactions on Knowledge and Data Engineering 33 (8) (2021) 3062–3074. doi:10.1109/TKDE.2019.2961343
-
[15]
D. Arthur, S. Vassilvitskii, How slow is the k-means method?, in: SCG’06: Proceedings of the 22nd annual symposium on Computational geometry, ACM Press, New York, USA, 2006, pp. 144–153. doi:10.1145/1137856.1137880
-
[16]
D. Arthur, S. Vassilvitskii, k-means++: the advantages of careful seeding, in: H. Gabow (Ed.), SODA’07: Proceedings of the 8th annual ACM-SIAM symposium on Discrete algorithms, Society for Industrial and Applied Mathematics, 2007, pp. 1027–1035. URL https://dl.acm.org/doi/10.5555/1283383.1283494
-
[17]
B. Bahmani, B. Moseley, A. Vattani, R. Kumar, S. Vassilvitskii, Scalable k-means ++, Proc. VLDB Endow. 5 (7) (2012) 622–633. doi: 10.14778/2180912.2180915
-
[18]
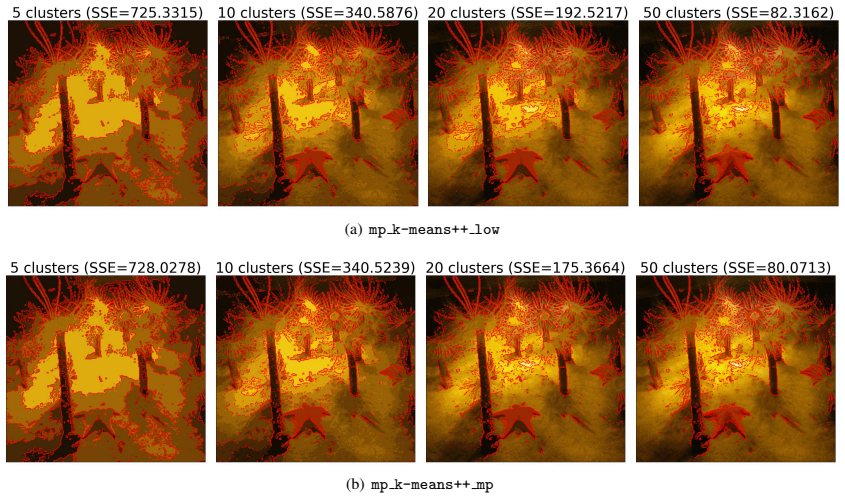
J. Newling, F. Fleuret, Nested mini-batch K-means, in: D. D. Lee, U. von Luxburg, R. Garnett, I. G. Masashi Sugiyama (Eds.), NIPS’16: 19 (a) mp k-means++ low (b) mp k-means++ mp Figure 7.5: Results of image segmentation I (q52). Proceedings of the 30th International Conference on Neural Information Processing Systems, Curran Associates Inc., New York, USA...
-
[19]
D. Sculley, Web-scale k-means clustering, in: WWW’10: Proceedings of the 19th international conference on World wide web, ACM Press, New York, USA, 2010, pp. 1177–1178. doi:10.1145/1772690.1772862
-
[20]
H. Ismkhan, I-k-means- +: An iterative clustering algorithm based on an enhanced version of the k-means, Pattern Recognition 79 (2018) 402–413. doi:10.1016/j.patcog.2018.02.015
-
[22]
P. Fr ¨anti, S. Sieranoja, How much can k-means be improved by using better initialization and repeats?, Pattern Recognition 93 (C) (2019) 95–112. doi:10.1016/j.patcog.2019.04.014
-
[23]
Y . Xu, W. Qu, Z. Li, G. Min, K. Li, Z. Liu, E fficient k-means++ approximation with MapReduce, IEEE Transactions on Parallel and Distributed Systems 25 (12) (2014) 3135–3144. doi:10.1109/TPDS.2014.2306193
-
[24]
W. Zhao, H. Ma, Q. He, Parallel K-means clustering based on mapreduce, in: CloudCom’09: Proceedings of the 1st International Conference on Cloud Computing, Springer, 2009, pp. 674–679. doi:10.1007/978-3-642-10665-1_71
-
[25]
IEEE Standard for Floating-Point Arithmetic,IEEE Std 754-2019 (Revision of IEEE Std 754-2008), IEEE, 2019. doi:10.1109/IEEESTD. 2019.8766229
-
[26]
E. Carson, N. J. Higham, Accelerating the solution of linear systems by iterative refinement in three precisions, SIAM J. Sci. Comput. 40 (2) (2018) A817–A847. doi:10.1137/17M1140819
-
[27]
A. Haidar, H. Bayraktar, S. Tomov, J. Dongarra, N. J. Higham, Mixed-precision iterative refinement using tensor cores on GPUs to accelerate solution of linear systems, Proc. Roy. Soc. London A 476 (2243) (2020) 20200110. doi:10.1098/rspa.2020.0110
-
[28]
E. Carson, N. J. Higham, S. Pranesh, Three-precision GMRES-based iterative refinement for least squares problems, SIAM J. Sci. Comput. 42 (6) (2020) A4063–A4083. doi:10.1137/20m1316822
-
[29]
N. J. Higham, S. Pranesh, Exploiting lower precision arithmetic in solving symmetric positive definite linear systems and least squares problems, SIAM J. Sci. Comput. 43 (1) (2021) A258–A277. doi:10.1137/19M1298263
-
[30]
Training deep neural networks with low precision multiplications
M. Courbariaux, Y . Bengio, J.-P. David, Training deep neural networks with low precision multiplications, ArXiv:1412.7024v5 (2015). URL https://arxiv.org/abs/1412.7024v5
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[31]
P. Micikevicius, S. Narang, J. Alben, G. Diamos, E. Elsen, D. Garcia, B. Ginsburg, M. Houston, O. Kuchaiev, G. Venkatesh, H. Wu, Mixed precision training, in: ICLR 2018: 6th International Conference on Learning Representations, 2018. URL https://openreview.net/forum?id=r1gs9JgRZ
work page 2018
-
[32]
N. J. Higham, S. Pranesh, M. Zounon, Squeezing a matrix into half precision, with an application to solving linear systems, SIAM Journal on Scientific Computing 41 (4) (2019) A2536–A2551
work page 2019
-
[33]
A. Abdelfattah, H. Anzt, E. G. Boman, E. Carson, T. Cojean, J. Dongarra, A. Fox, M. Gates, N. J. Higham, X. S. Li, J. Loe, P. Luszczek, S. Pranesh, S. Rajamanickam, T. Ribizel, B. F. Smith, K. Swirydowicz, S. Thomas, S. Tomov, Y . M. Tsai, U. M. Yang, A survey of numerical linear algebra methods utilizing mixed-precision arithmetic, Int. J. High Perform. ...
work page 2021
-
[34]
N. J. Higham, T. Mary, Mixed precision algorithms in numerical linear algebra, Acta Numerica 31 (2022) 347–414. doi:10.1017/ s0962492922000022
work page 2022
-
[35]
B. Rokh, A. Azarpeyvand, A. Khanteymoori, A comprehensive survey on model quantization for deep neural networks in image classification, ACM Trans. Intell. Syst. Technol. 14 (6) (2023) 1–50. doi:10.1145/3623402
-
[36]
N. Wang, J. Choi, D. Brand, C.-Y . Chen, K. Gopalakrishnan, Training deep neural networks with 8-bit floating point numbers, in: S. Bengio, H. M. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi (Eds.), NIPS’18: Proceedings of the 32nd International Conference on Neural Information Processing Systems, Curran Associates Inc., New York, USA, 2018, pp. 76...
-
[37]
M. F. Balcan, S. Ehrlich, Y . Liang, Distributedk-means and k-median clustering on general topologies, in: C. J. Burges, L. Bottou, M. Welling, Z. Ghahramani, K. Q. Weinberger (Eds.), NIPS’2013: Proceedings of the 26th International Conference on Neural Information Processing Systems - V olume 2, Curran Associates Inc., New York, USA, 2013, pp. 1995–2003
work page 2013
-
[38]
P. K. Agarwal, S. Har-Peled, K. R. Varadarajan, Geometric approximation via coresets, Combinatorial and Computational Geometry 52 (2005) 1–30
work page 2005
-
[39]
S. Har-Peled, S. Mazumdar, On coresets for k-means and k-median clustering, in: L. Babai (Ed.), STOC04: Symposium of Theory of Computing 2004, ACM Press, New York, 2004, pp. 291–300. doi:10.1145/1007352.1007400
-
[40]
J. Dean, S. Ghemawat, MapReduce: simplified data processing on large clusters, Communications of the ACM 51 (1) (2008) 107–113. doi:10.1145/1327452.1327492
- [41]
-
[42]
C. Lutz, S. Breß, T. Rabl, S. Zeuch, V . Markl, E fficient k-means on GPUs, in: W. Lehner, K. Salem (Eds.), DAMON’18: Proceedings of the 14th International Workshop on Data Management on New Hardware, ACM Press, New York, USA, 2018, pp. 3:1–3:3. doi: 10.1145/3211922.3211925
-
[43]
M. Li, E. Frank, B. Pfahringer, Large scale K-means clustering using GPUs, Data Mining and Knowledge Discovery 37 (1) (2023) 67–109. doi:10.1007/s10618-022-00869-6
-
[44]
T. Hastie, R. Tibshirani, J. Friedman, The Elements of Statistical Learning: Data Mining, Inference and Prediction, 2nd Edition, Springer- Verlag, New York, USA, 2009. doi:10.1007/978-0-387-84858-7
-
[45]
S. Io ffe, C. Szegedy, Batch normalization: Accelerating deep network training by reducing internal covariate shift, in: F. Bach, D. Blei (Eds.), ICML’15: Proceedings of the 32nd International Conference on International Conference on Machine Learning, V ol. 37, JMLR.org, 2015, pp. 448–456. URL https://dl.acm.org/doi/10.5555/3045118.3045167
-
[46]
J. L. Ba, J. R. Kiros, G. E. Hinton, Layer normalization, ArXiv:1607.06450 (2016). URL https://arxiv.org/abs/1607.06450
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[47]
R. Xiong, Y . Yang, D. He, K. Zheng, S. Zheng, C. Xing, H. Zhang, Y . Lan, L. Wang, T. Liu, On layer normalization in the transformer architecture, in: H. Daum ´e, A. Singh (Eds.), ICML’20: Proceedings of the 37th International Conference on Machine Learning, JMLR.org, 2020, pp. 10524–10533. 21 (a) mp k-means++ low (b) mp k-means++ mp Figure 7.7: Results ...
-
[48]
J. Xu, X. Sun, Z. Zhang, G. Zhao, J. Lin, Understanding and improving layer normalization, in: H. M. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alch´e-Buc, E. B. Fox (Eds.), NIPS’19: Proceedings of the 33rd International Conference on Neural Information Processing Systems, Curran Associates Inc., 2019, p. 4381–4391. URL https://dl.acm.org/doi/10.5555/34...
-
[49]
Lloyd, Least squares quantization in PCM, IEEE Trans
S. Lloyd, Least squares quantization in PCM, IEEE Trans. Inform. Theory 28 (2) (1982) 129–137. doi:10.1109/TIT.1982.1056489
-
[50]
J. Bl ¨omer, C. Lammersen, M. Schmidt, C. Sohler, Theoretical analysis of the k-means algorithm–a survey, in: L. Kliemann, P. Sanders (Eds.), Algorithm Engineering, V ol. 9220 of Lecture Notes in Computer Science, Springer-Verlag, Cham, Switzerland, 2016, pp. 81–116. doi:10.1007/978-3-319-49487-6_3
-
[51]
S. Z. Selim, M. A. Ismail, K-means-type algorithms: A generalized convergence theorem and characterization of local optimality, IEEE Transactions on pattern analysis and machine intelligence PAMI-6 (1) (1984) 81–87. doi:10.1109/TPAMI.1984.4767478
-
[52]
T. Kanungo, D. M. Mount, N. S. Netanyahu, C. D. Piatko, R. Silverman, A. Y . Wu, A local search approximation algorithm for k-means clustering, in: SCG’02: Proceedings of the 18th annual symposium on Computational geometry, ACM Press, New York, USA, 2002, pp. 10–18. doi:10.1145/513400.513402
-
[53]
S. Bubeck, M. Meil ˘a, U. von Luxburg, How the initialization affects the stability of the k-means algorithm, ESAIM: Probability and Statistics 16 (2012) 436–452. doi:10.1051/ps/2012013
-
[54]
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, E. Duchesnay, Scikit-learn: Machine Learning in Python, Journal of Machine Learning Research 12 (2011) 2825–2830
work page 2011
-
[55]
L. S. Blackford, J. Demmel, J. Dongarra, I. Du ff, S. Hammarling, G. Henry, M. Heroux, L. Kaufman, A. Lumsdaine, A. Petitet, R. Pozo, K. Remington, R. C. Whaley, An updated set of basic linear algebra subprograms (BLAS), ACM Trans. Math. Softw. (TOMS) 28 (2) (2002) 135–151. doi:10.1145/567806.567807
-
[56]
X. Chen, S. G ¨uttel, Fast and explainable clustering based on sorting, Pattern Recognition 150 (2024) 110298. doi:10.1016/j.patcog. 2024.110298
-
[57]
N. J. Higham, Accuracy and Stability of Numerical Algorithms, 2nd Edition, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 2002. doi:10.1137/1.9780898718027
-
[58]
G. H. Golub, C. F. Van Loan, Matrix Computations, 4th Edition, Johns Hopkins University Press, Baltimore, MD, USA, 2013
work page 2013
-
[59]
N. J. Higham, Functions of Matrices: Theory and Computation, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA,
-
[60]
doi:10.1137/1.9780898717778
-
[61]
M. Fasi, N. J. Higham, F. Lopez, T. Mary, M. Mikaitis, Matrix multiplication in multiword arithmetic: Error analysis and application to GPU tensor cores, SIAM J. Sci. Comput. 45 (1) (2023) C1–C19. doi:10.1137/21m1465032
-
[62]
X. Liu, Mixed-precision Paterson–Stockmeyer method for evaluating polynomials of matrices, ArXiv:2312.17396v2 (2023). URL https://arxiv.org/abs/2312.17396v2
-
[63]
N. X. Vinh, J. Epps, J. Bailey, Information theoretic measures for clusterings comparison: Variants, properties, normalization and correction for chance, Journal of Machine Learning Research 11 (95) (2010) 2837–2854. 22
work page 2010
-
[64]
N. J. Higham, S. Pranesh, Simulating low precision floating-point arithmetic, SIAM J. Sci. Comput. 41 (5) (2019) C585–C602. doi: 10.1137/19M1251308
-
[65]
A. Rosenberg, J. Hirschberg, V-measure: A conditional entropy-based external cluster evaluation measure, in: J. Eisner (Ed.), Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Asso- ciation for Computational Linguistics, 2007, p. 410–420. URL https://aclanthology.org/D07-1043
work page 2007
-
[66]
P. Fr ¨anti, O. Virmajoki, Iterative shrinking method for clustering problems, Pattern Recognition 39 (5) (2006) 761–775. doi:10.1016/j. patcog.2005.09.012
work page doi:10.1016/j 2006
-
[67]
D. Dua, C. Gra ff, UCI machine learning repository, http://archive.ics.uci.edu/ml (2017)
work page 2017
-
[68]
H. A. G ¨uvenir, G. Demir ¨oz, N. Ilter, Learning di fferential diagnosis of erythemato-squamous diseases using voting feature intervals, Artif. Intell. Med. 13 (3) (1998) 147–165. doi:10.1016/s0933-3657(98)00028-1
-
[69]
K. Nakai, M. Kanehisa, Expert system for predicting protein localization sites in gram-negative bacteria, Proteins 11 (2) (1991) 95–110. doi:10.1002/prot.340110203
-
[70]
K. Nakai, M. Kanehisa, A knowledge base for predicting protein localization sites in eukaryotic cells, Genomics 14 (4) (1992) 897–911. doi:10.1016/s0888-7543(05)80111-9
-
[71]
Anderson, The species problem in Iris, Annals of the Missouri Botanical Garden 23 (3) (1936) 457–509
E. Anderson, The species problem in Iris, Annals of the Missouri Botanical Garden 23 (3) (1936) 457–509. doi:10.2307/2394164
-
[72]
R. A. Fisher, The use of multiple measurements in taxonomic problems, Annals of Eugenics 7 (2) (1936) 179–188. doi:10.1111/j. 1469-1809.1936.tb02137.x
work page doi:10.1111/j 1936
- [73]
-
[74]
J. Deng, W. Dong, R. Socher, L.-J. Li, L. Kai, F.-F. Li, ImageNet: A large-scale hierarchical image database, in: 2009 IEEE Conference on Computer Vision and Pattern Recognition, IEEE, 2009, pp. 248–255. doi:10.1109/CVPR.2009.5206848
-
[75]
J. Jang, H. Jiang, DBSCAN ++: Towards fast and scalable density clustering, in: K. Chaudhuri, R. Salakhutdinov (Eds.), Proceedings of the 36th International Conference on Machine Learning, V ol. 97, PMLR, 2019, pp. 3019–3029. URL https://proceedings.mlr.press/v97/jang19a.html
work page 2019
-
[76]
M. Ester, H.-P. Kriegel, J. Sander, X. Xu, A density-based algorithm for discovering clusters in large spatial databases with noise, in: E. Simoudis, J. H. U. Fayyad (Eds.), KDD’96: Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, AAAI Press, 1996, pp. 226–231. URL https://dl.acm.org/doi/10.5555/3001460.3001507
-
[77]
J. B. Tenenbaum, V . de Silva, J. C. Langford, A global geometric framework for nonlinear dimensionality reduction, Science 290 (5500) (2000) 2319–2323. doi:10.1126/science.290.5500.2319
-
[78]
X. Chen, S. G ¨uttel, Fast and exact fixed-radius neighbor search based on sorting, PeerJ Computer Science (2024) 10:e1929 doi:10.7717/ peerj-cs.1929. 23
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.