Vision-Language and Large Language Model Performance in Gastroenterology: GPT, Claude, Llama, Phi, Mistral, Gemma, and Quantized Models
Pith reviewed 2026-05-23 22:13 UTC · model grok-4.3
The pith
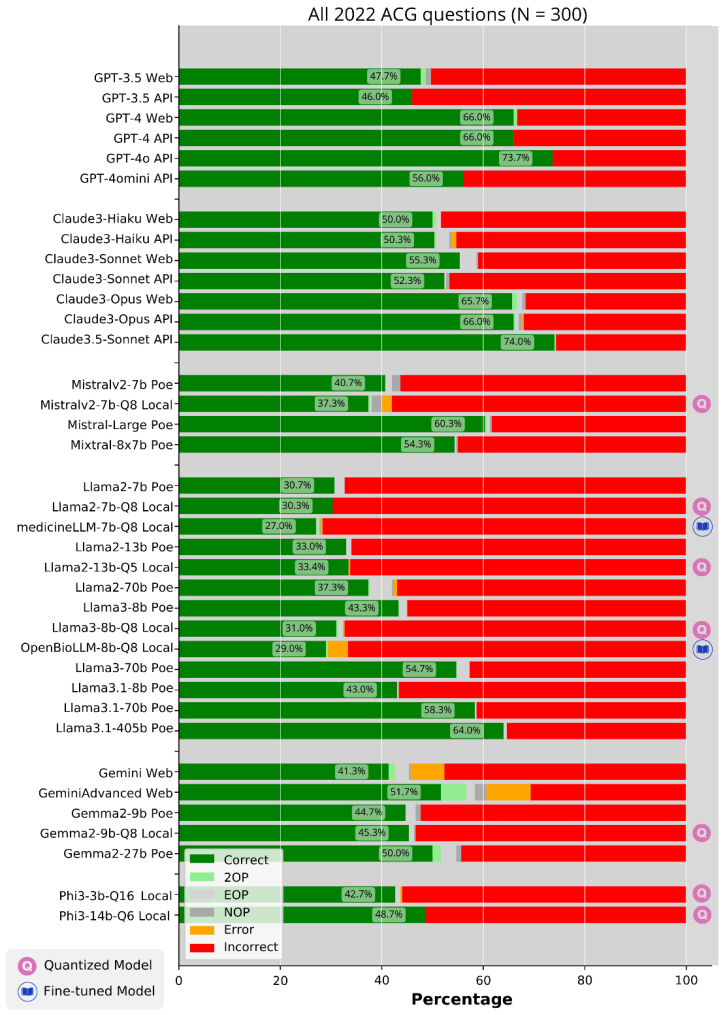
Proprietary models GPT-4o and Claude 3.5 Sonnet reach 74 percent accuracy on gastroenterology board questions while vision-language models gain nothing from raw images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
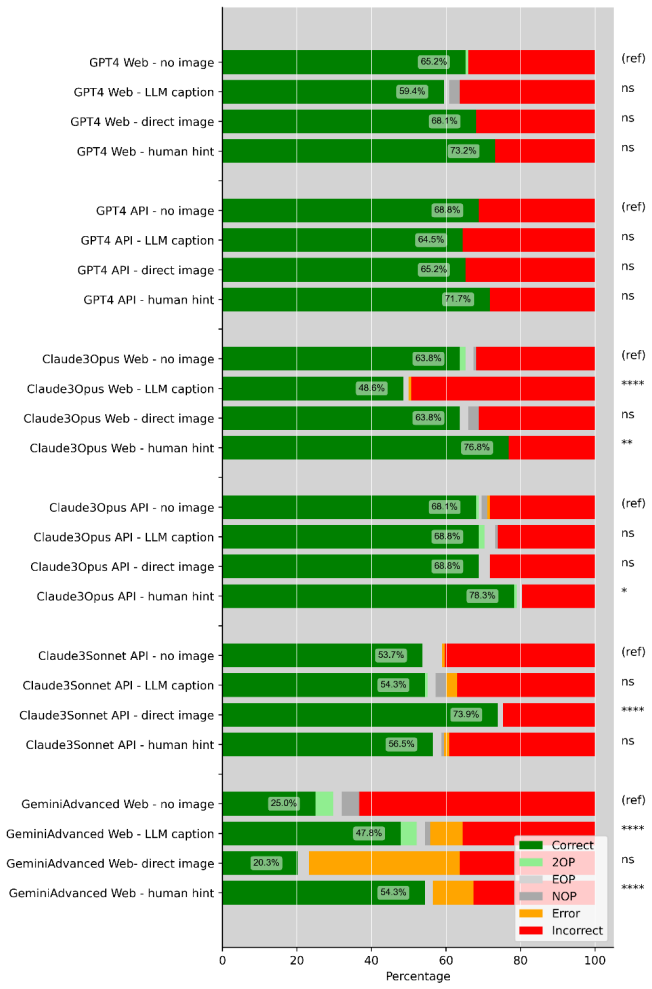
Among the proprietary models, GPT-4o (73.7 percent) and Claude 3.5 Sonnet (74.0 percent) achieved the highest accuracy on the 300-question set, outperforming the top open-source models Llama 3.1 405B (64 percent), Llama 3.1 70B (58.3 percent), and Mixtral 8x7B (54.3 percent). The 6-bit quantized Phi 3 14B reached 48.7 percent, comparable to several full-precision smaller models. Vision-language model accuracy on image-containing questions did not rise when images were provided and fell when LLM-generated captions were supplied, but rose 10 percent with human-crafted image descriptions.
What carries the argument
The 300 gastroenterology board-exam-style multiple-choice questions (138 with images) used as a fixed zero-shot benchmark across model families, interfaces, precisions, and prompt strategies.
If this is right
- Proprietary models currently deliver the highest zero-shot accuracy on gastroenterology reasoning tasks.
- Open-source models remain several points behind but offer flexibility for local deployment and further adaptation.
- Quantization to 6 bits preserves most performance for several smaller open-source models.
- Vision-language models require human-crafted image descriptions rather than raw images or LLM captions to improve on this task.
- Careful selection of model family, precision, and interface is needed for any clinical deployment.
Where Pith is reading between the lines
- The 10 percent lift from human descriptions points to a training gap in how current vision-language models encode gastroenterology-specific visual features.
- If open-source models were fine-tuned on similar board-style questions, the gap with proprietary models could narrow without sacrificing local control.
- The finding that LLM-generated captions hurt performance suggests that automatic captioning pipelines may introduce errors that compound visual-reasoning failures in medical domains.
Load-bearing premise
The 300 board-exam-style questions constitute a representative and unbiased sample of gastroenterology medical reasoning that generalizes beyond the specific test set.
What would settle it
Accuracy measurements on a fresh, larger collection of gastroenterology board-style questions with images where vision-language models improve when raw images are supplied without human descriptions.
Figures






read the original abstract
Background and Aims: This study evaluates the medical reasoning performance of large language models (LLMs) and vision language models (VLMs) in gastroenterology. Methods: We used 300 gastroenterology board exam-style multiple-choice questions, 138 of which contain images to systematically assess the impact of model configurations and parameters and prompt engineering strategies utilizing GPT-3.5. Next, we assessed the performance of proprietary and open-source LLMs (versions), including GPT (3.5, 4, 4o, 4omini), Claude (3, 3.5), Gemini (1.0), Mistral, Llama (2, 3, 3.1), Mixtral, and Phi (3), across different interfaces (web and API), computing environments (cloud and local), and model precisions (with and without quantization). Finally, we assessed accuracy using a semiautomated pipeline. Results: Among the proprietary models, GPT-4o (73.7%) and Claude3.5-Sonnet (74.0%) achieved the highest accuracy, outperforming the top open-source models: Llama3.1-405b (64%), Llama3.1-70b (58.3%), and Mixtral-8x7b (54.3%). Among the quantized open-source models, the 6-bit quantized Phi3-14b (48.7%) performed best. The scores of the quantized models were comparable to those of the full-precision models Llama2-7b, Llama2--13b, and Gemma2-9b. Notably, VLM performance on image-containing questions did not improve when the images were provided and worsened when LLM-generated captions were provided. In contrast, a 10% increase in accuracy was observed when images were accompanied by human-crafted image descriptions. Conclusion: In conclusion, while LLMs exhibit robust zero-shot performance in medical reasoning, the integration of visual data remains a challenge for VLMs. Effective deployment involves carefully determining optimal model configurations, encouraging users to consider either the high performance of proprietary models or the flexible adaptability of open-source models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates the performance of proprietary and open-source LLMs and VLMs on 300 gastroenterology board exam-style multiple-choice questions (138 with images). It reports that GPT-4o (73.7%) and Claude 3.5-Sonnet (74.0%) achieve the highest accuracy among proprietary models, outperforming top open-source models such as Llama 3.1-405b (64%), examines effects of quantization, interfaces, and prompt strategies, and finds that VLMs do not benefit from provided images (and worsen with LLM-generated captions) but improve with human-crafted image descriptions.
Significance. If the results hold, the work supplies a direct empirical benchmark of medical reasoning capabilities across a range of current models in a specialized clinical domain. Strengths include the systematic comparison of model families, quantization levels, and multimodal conditions on a fixed question set, which can inform practical model selection for gastroenterology applications.
major comments (3)
- [Methods] Methods: The 300 board-exam-style questions lack any description of sourcing, exclusion criteria, topic distribution against board blueprints, difficulty stratification, or diversity metrics. This directly undermines the generalizability of the headline accuracy rankings (e.g., GPT-4o 73.7% vs. Llama 3.1-405b 64%), as the observed differences could be artifacts of an uncharacterized test distribution.
- [Results] Results: The semiautomated accuracy assessment pipeline is mentioned but provides no details on inter-rater reliability for image descriptions, handling of ambiguous answers, or statistical comparisons (confidence intervals, significance tests) between model scores. These omissions affect the reliability of all reported percentages.
- [Results] Results (VLM section): The claim of a 10% accuracy increase with human-crafted image descriptions versus worsening with LLM-generated captions requires explicit controls for prompt length, content, and generation method to establish that the effect is attributable to description quality rather than other variables.
minor comments (2)
- [Abstract] Abstract: The list of evaluated models and versions is incomplete; the text mentions 'versions' but does not enumerate all tested configurations (e.g., exact Llama 3.1 variants or quantization bits) in one place.
- The paper would benefit from a table summarizing all model accuracies, interfaces, and precisions for quick reference.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important areas for improving the transparency and rigor of our manuscript. We respond to each major comment below.
read point-by-point responses
-
Referee: [Methods] Methods: The 300 board-exam-style questions lack any description of sourcing, exclusion criteria, topic distribution against board blueprints, difficulty stratification, or diversity metrics. This directly undermines the generalizability of the headline accuracy rankings (e.g., GPT-4o 73.7% vs. Llama 3.1-405b 64%), as the observed differences could be artifacts of an uncharacterized test distribution.
Authors: We agree that the Methods section would benefit from greater detail on the question set to better support assessments of generalizability. The 300 questions were compiled as representative gastroenterology board exam-style multiple-choice items (with 138 containing images), but the manuscript does not specify sourcing, exclusion criteria, topic distribution against blueprints, difficulty stratification, or diversity metrics. In revision we will expand the Methods to include all available information on question selection and characteristics. We note that the study's core contribution is the head-to-head comparison of models on this fixed question set; relative rankings are therefore less sensitive to the precise distribution than absolute performance claims would be, but we accept that additional context strengthens the work. revision: yes
-
Referee: [Results] Results: The semiautomated accuracy assessment pipeline is mentioned but provides no details on inter-rater reliability for image descriptions, handling of ambiguous answers, or statistical comparisons (confidence intervals, significance tests) between model scores. These omissions affect the reliability of all reported percentages.
Authors: We acknowledge that the description of the semiautomated accuracy assessment pipeline is incomplete. The manuscript references the pipeline without providing details on inter-rater reliability for image descriptions, procedures for ambiguous answers, or statistical comparisons such as confidence intervals and significance tests. We will revise the Results section to supply these specifics, including the exact process used to determine correctness, any reliability checks performed, and the statistical methods applied to model-score differences. This will directly address concerns about the reliability of the reported percentages. revision: yes
-
Referee: [Results] Results (VLM section): The claim of a 10% accuracy increase with human-crafted image descriptions versus worsening with LLM-generated captions requires explicit controls for prompt length, content, and generation method to establish that the effect is attributable to description quality rather than other variables.
Authors: The referee correctly identifies that stronger attribution would require explicit controls for prompt length, content, and generation method. The reported 10% accuracy gain with human-crafted descriptions (and degradation with LLM-generated captions) was observed under the specific conditions tested, but the manuscript does not report or control for those variables. We will revise the VLM section to provide fuller details on how the human-crafted descriptions were produced and to discuss potential confounds. Because new controlled experiments are not feasible at this stage, we will also note the limitation explicitly; the directional finding still illustrates the value of high-quality descriptions, but we accept the need for greater methodological transparency. revision: partial
Circularity Check
Pure empirical benchmark with no derivations or self-referential steps
full rationale
The paper consists entirely of direct accuracy measurements of LLMs and VLMs on an external set of 300 board-exam-style questions. No equations, fitted parameters, predictions derived from inputs, uniqueness theorems, or ansatzes are present. Results are reported as raw percentages (e.g., GPT-4o at 73.7%) obtained via a semiautomated pipeline against fixed test items. No load-bearing self-citations or reductions to the paper's own inputs occur. This is a standard non-circular empirical evaluation.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Self-Reported Confidence of Large Language Models in Gastroenterology: Analysis of Commercial, Open-Source, and Quantized Models
LLMs show improved accuracy on gastroenterology questions but remain overconfident in self-reported certainty across commercial, open-source, and quantized variants.
Reference graph
Works this paper leans on
-
[1]
J. B. Henson, J. R. Glissen Brown, J. P. Lee, A. Patel, and D. A. Leiman, ‘Evaluation of the Potential Utility of an Artificial Intelligence Chatbot in Gastroesophageal Reflux Disease Management’, American Journal of Gastroenterology, vol. 118, no. 12, pp. 2276–2279, Dec. 2023, doi: 10.14309/ajg.0000000000002397
-
[2]
S. A. A. Safavi-Naini, Z. Tajabadi, B. El Kurdi, J. A. Abrams, G. N. Nadkarni, and A. Soroush, ‘Su1962 GI -COPILOT: AUGMENTING CHATGPT WITH GUIDELINE-BASED KNOWLEDGE’, Gastroenterology, vol. 166, no. 5, p. S-882, 2024
work page 2024
-
[3]
J. Clusmann et al., ‘The future landscape of large language models in medicine’, Communications Medicine, vol. 3, no. 1, Oct. 2023, doi: 10.1038/s43856-023-00370- 1
-
[4]
L. Tang et al. , ‘Evaluating large language models on medical evidence summarization’, NPJ Digit Med, vol. 6, no. 1, Dec. 2023, doi: 10.1038/s41746-023- 00896-7
-
[5]
S. Ali et al., ‘Large Language Models Are Poor Medical Coders — Benchmarking of Medical Code Querying’, NEJM AI, vol. 1, no. 5, p. AIdbp2300040, Apr. 2024, doi: 10.1056/AIdbp2300040
-
[6]
Holistic Evaluation of Language Models
P. Liang et al. , ‘Holistic Evaluation of Language Models’, Nov. 2022, [Online]. Available: http://arxiv.org/abs/2211.09110
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
E. Klang, A. Sourosh , and G. N. Nadkarni, ‘Evaluating the role of ChatGPT in gastroenterology: a comprehensive systematic review of applications, benefits, and limitations’, Jan. 01, 2023, SAGE Publications Ltd . doi: 10.1177/17562848231218618
-
[8]
Towards Expert-Level Medical Question Answering with Large Language Models
K. Singhal et al., ‘Towards Expert-Level Medical Question Answering with Large Language Models’, May 2023, [Online]. Available: http://arxiv.org/abs/2305.09617
work page internal anchor Pith review arXiv 2023
- [9]
-
[10]
A. Gilson et al. , ‘How Does ChatGPT Perform on the United States Medical Licensing Examination? The Implications of Large Language Models for Medical Education and Knowledge Assessment’, JMIR Med Educ , vol. 9, 2023, doi: 10.2196/45312
-
[11]
T. H. Kung et al., ‘Performance of ChatGPT on USMLE: Potential for AI -assisted medical education using large language models’, PLOS Digital Health, vol. 2, no. 2, p. e0000198, Feb. 2023, doi: 10.1371/journal.pdig.0000198
-
[12]
M. Moshirfar, A. W. Altaf, I. M. Stoakes, J. J. Tuttle, and P. C. Hoopes, ‘Artificial Intelligence in Ophthalmology: A Comparative Analysis of GPT -3.5, GPT-4, and Human Expertise in Answering StatPearls Questions’, Cureus, Jun. 2023, doi: 10.7759/cureus.40822
-
[13]
A. Mihalache, M. M. Popovic, and R. H. Muni, ‘Performance of an Artificial Intelligence Chatbot in Ophthalmic Knowledge Assessment’, JAMA Ophthalmol , vol. 141, no. 6, pp. 589–597, Jun. 2023, doi: 10.1001/jamaophthalmol.2023.1144
-
[14]
L. Z. Cai et al. , ‘Performance of Generative Large Language Models on Ophthalmology Board–Style Questions’, Am J Ophthalmol, vol. 254, pp. 141 –149, Oct. 2023, doi: 10.1016/j.ajo.2023.05.024
-
[15]
K. Suchman, S. Garg, and A. J. Trindade, ‘Chat Generative Pretrained Transformer Fails the Multiple -Choice American College of Gastroenterology Self -Assessment Test’, American Journal of Gastroenterology, vol. 118, no. 12, pp. 2280–2282, Dec. 2023, doi: 10.14309/ajg.0000000000002320
-
[16]
R. Noda, Y . Izaki, F. Kitano, J. Komatsu, D. Ichikawa, and Y . Shibagaki , ‘Title Performance of ChatGPT and Bard in Self -Assessment Questions for Nephrology Board Renewal Author’, doi: 10.1101/2023.06.06.23291070
-
[17]
I. Skalidis et al. , ‘ChatGPT takes on the European Exam in Core Cardiology: an artificial intelligence success story?’, European Heart Journal - Digital Health, vol. 4, no. 3, pp. 279–281, May 2023, doi: 10.1093/ehjdh/ztad029. 30
-
[18]
L. Passby, N. Jenko, and A. Wernham, ‘Performance of ChatGPT on Specialty Certificate Examination in Dermatology multiple -choice questions’, Clin Exp Dermatol, Jun. 2023, doi: 10.1093/ced/llad197
-
[19]
P. Humar, M. Asaad, F. B. Bengur, and V . Nguyen, ‘ChatGPT Is Equivalent to First- Year Plastic Surgery Residents: Evaluation of ChatGPT on the Plastic Surgery In - Service Examination’, Aesthet Surg J , vol. 43, no. 12, pp. NP1085 –NP1089, Dec. 2023, doi: 10.1093/asj/sjad130
-
[20]
C. C. Hoch et al., ‘ChatGPT’s quiz skills in different otolaryngology subspecialties: an analysis of 2576 single-choice and multiple-choice board certification preparation questions’, European Archives of Oto-Rhino-Laryngology, vol. 280, no. 9, pp. 4271– 4278, Sep. 2023, doi: 10.1007/s00405-023-08051-4
-
[21]
Z. C. Lum, ‘Can Artificial Intelligence Pass the American Board of Orthopaedic Surgery Examination? Orthopaedic Residents Versus ChatGPT’, Clin Orthop Relat Res, vol. 481, no. 8, pp. 1623 –1630, Aug. 2023, doi: 10.1097/CORR.0000000000002704
-
[22]
R. Ali et al., ‘Performance of ChatGPT, GPT-4, and Google Bard on a Neurosurgery Oral Boards Preparation Question Bank’, Neurosurgery, vol. 93, no. 5, pp. 1090 – 1098, Nov. 2023, doi: 10.1227/neu.0000000000002551
-
[23]
H. Khorshidi et al., ‘Application of ChatGPT in multilingual medical education: How does ChatGPT fare in 2023’s Iranian residency entrance examination’, Inform Med Unlocked, vol. 41, p. 101314, 2023, doi: https://doi.org/10.1016/j.imu.2023.101314
-
[24]
D. Brin et al., ‘Comparing ChatGPT and GPT -4 performance in USMLE soft skill assessments’, Sci Rep, vol. 13, no. 1, p. 16492, Oct. 2023, doi: 10.1038/s41598-023- 43436-9
-
[25]
Anthropic Official Website, ‘Consumer Terms of Service [Date Published: February 3, 2024; Date Accessed: April 10, 2024]’. Accessed: May 10, 2024. [Online]. Available: https://www.anthropic.com/legal/consumer-terms 31
work page 2024
-
[26]
Poe Official Website, ‘Poe Privacy Center [Date Published: NA; Date Accessed: April 10, 2024]’. Accessed: May 10, 2024. [Online]. Available: https://poe.com/privacy_center
work page 2024
-
[27]
OpenAI Official Website, ‘Data Controls FAQ [Last update: April 2024; Date Accessed: April 10, 2024]’. Accessed: May 10, 2024. [Online]. Available: https://help.openai.com/en/articles/7730893-data-controls-faq
- [28]
-
[29]
Hugging Face, ‘Qunatization’. Accessed: May 13, 2024. [Online]. Available: https://huggingface.co/docs/optimum/en/concept_guides/quantization
work page 2024
-
[30]
B. Jacob et al., ‘Quantization and Training of Neural Networks for Efficient Integer- Arithmetic-Only Inference’, 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 2704 –2713, 2017, [Online]. Available: https://api.semanticscholar.org/CorpusID:39867659
work page 2018
- [31]
- [32]
- [33]
-
[34]
O. Shahab, B. El Kurdi, A. Shaukat, G. Nadkarni, and A. Soroush, ‘Large language models: a primer and gastroenterology applications’, Jan. 01, 2024, SAGE Publications Ltd. doi: 10.1177/17562848241227031. 32
-
[35]
S. Lin, J. Hilton, and O. Evans, ‘Teaching Models to Express Their Uncertainty in Words’, May 2022, [Online]. Available: http://arxiv.org/abs/2205.14334
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
T. Savage et al., ‘Large Language Model Uncertainty Measurement and Calibration for Medical Diagnosis and Treatment’, medRxiv, p. 2024.06.06.24308399, Jan. 2024, doi: 10.1101/2024.06.06.24308399
-
[37]
American Board of Internal Medicine (ABIM) Official Website, ‘GASTROENTEROLOGY CERTIFICATION EXAM CONTENT’. Accessed: May 14, 2024. [Online]. Available: https://www.abim.org/certification/exam - information/gastroenterology/exam-content
work page 2024
-
[38]
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, ‘QLoRA: Efficient Finetuning of Quantized LLMs’, in Advances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, Eds., Curran Associates, Inc., 2023, pp. 10088 –10115. [Online]. Available: https://proceedings.neurips.cc/paper_files/paper/20...
work page 2023
-
[39]
Xiao, ‘Some basic knowledge of LLM: Parameters and Memory Estimation’, Medium
B. Xiao, ‘Some basic knowledge of LLM: Parameters and Memory Estimation’, Medium. Accessed: May 14, 2024. [Online]. Available: https://medium.com/@baicenxiao/some-basic-knowledge-of-llm-parameters-and- memory-estimation-b25c713c3bd8
work page 2024
-
[40]
ggml authors (Github Repository: ggerganov/ggml), ‘GGUF’. Accessed: May 15,
-
[41]
Available: https://github.com/ggerganov/ggml/blob/master/docs/gguf.md
[Online]. Available: https://github.com/ggerganov/ggml/blob/master/docs/gguf.md
-
[42]
M. Kowalczyk, ‘A step -by-step guide to prompt engineering: Best practices, challenges, and examples’, Lakera.ai. Accessed: Mar. 15, 2024. [Online]. Available: https://www.lakera.ai/blog/prompt-engineering-guide
work page 2024
-
[43]
B. Meskó, ‘Prompt Engineering as an Important Emerging Skill for Medical Professionals: Tutorial’, J Med Internet Res , vol. 25, no. 1, Jan. 2023, doi: 10.2196/50638. 33
-
[44]
Large Language Models Are Human-Level Prompt Engineers
Y . Zhou et al., ‘Large Language Models Are Human-Level Prompt Engineers’, Nov. 2022, [Online]. Available: http://arxiv.org/abs/2211.01910
work page internal anchor Pith review arXiv 2022
-
[45]
N. Zaidi, ‘Modified Bloom’s Taxonomy for Evaluating Multiple Choice Questions’, Baylor College of Medicine. Accessed: May 20, 2024. [Online]. Available: https://www.bcm.edu/sites/default/files/2019/04/principles-and-guidelines-for- assessments-6.15.15.pdf 1 This is a supplementary file to "Vision-Language and Large Language Model Performance in Gastroente...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.