Graph Retention Networks for Dynamic Graphs
Pith reviewed 2026-05-23 17:41 UTC · model grok-4.3
The pith
Graph Retention Networks extend retention to dynamic graphs for parallel training and O(1) inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Graph Retention Networks (GRNs) are proposed as a unified architecture for deep learning on dynamic graphs. By extending retention into graph retention, the model gains three computational paradigms: parallelizable training, O(1) inference, and long-term chunkwise training. This achieves an optimal balance between efficiency, effectiveness, and scalability, with competitive performance on benchmark datasets for edge-level prediction and node-level classification tasks.
What carries the argument
The graph retention mechanism that adapts retention concepts to dynamic graph data to enable parallelizable training, O(1) inference, and chunkwise training.
Load-bearing premise
The retention mechanism extends to dynamic graph structures while preserving parallel training, O(1) inference, and chunkwise properties without extra overheads or loss of expressiveness.
What would settle it
Experiments on standard benchmarks where GRN does not show reduced training latency or memory use and fails to achieve the claimed inference speedups while matching performance.
Figures



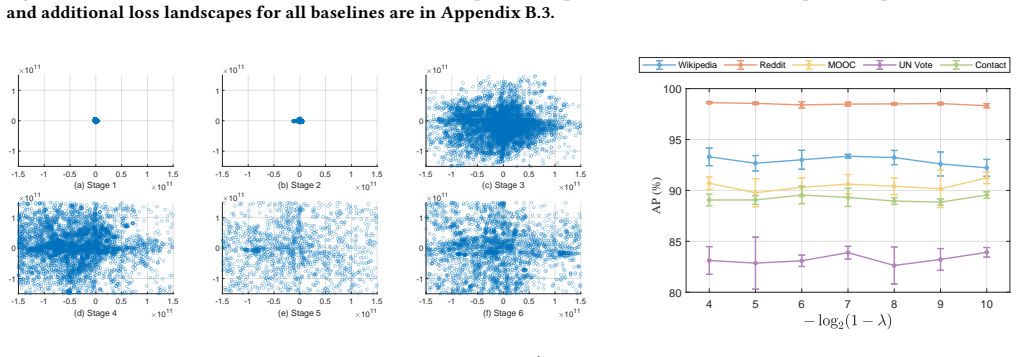


read the original abstract
In this paper, we propose Graph Retention Networks (GRNs) as a unified architecture for deep learning on dynamic graphs. The GRN extends the concept of retention into dynamic graph data as graph retention, equipping the model with three key computational paradigms: parallelizable training, low-cost $\mathcal{O}(1)$ inference, and long-term chunkwise training. This architecture achieves an optimal balance between efficiency, effectiveness, and scalability. Extensive experiments on benchmark datasets demonstrate its strong performance in both edge-level prediction and node-level classification tasks with significantly reduced training latency, lower GPU memory overhead, and improved inference throughput by up to 86.7x compared to SOTA baselines. The proposed GRN architecture achieves competitive performance across diverse dynamic graph benchmarks, demonstrating its adaptability to a wide range of tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Graph Retention Networks (GRNs) as a unified architecture for deep learning on dynamic graphs. It extends the retention mechanism to graph retention, claiming three computational paradigms: parallelizable training, low-cost O(1) inference, and long-term chunkwise training. The architecture is asserted to achieve an optimal balance of efficiency, effectiveness, and scalability, with experiments on benchmark datasets showing competitive performance on edge-level prediction and node-level classification tasks alongside reduced training latency, lower GPU memory, and inference throughput improvements up to 86.7x over SOTA baselines.
Significance. If the extension of retention to dynamic graphs preserves the stated asymptotic properties without hidden recomputation costs, the work could provide a scalable alternative to existing dynamic graph models, with potential impact on temporal network applications requiring efficient long-term modeling.
major comments (1)
- [Architecture description (following abstract claims on graph retention)] The central claim that graph retention inherits parallel training, O(1) inference, and chunkwise properties from the base retention mechanism when applied to evolving graphs requires an explicit derivation of the node/edge update rule (likely in the architecture section) showing that it incurs no extra asymptotic cost or auxiliary structures; absent this, the 86.7x inference claim and asserted optimal balance do not necessarily follow.
minor comments (1)
- [Abstract] The abstract states 'significantly reduced training latency' and 'improved inference throughput by up to 86.7x' without specifying the exact baselines or conditions under which the maximum speedup is achieved; this should be clarified with reference to specific tables or figures.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the single major comment below regarding the need for an explicit derivation of the graph retention update rules.
read point-by-point responses
-
Referee: [Architecture description (following abstract claims on graph retention)] The central claim that graph retention inherits parallel training, O(1) inference, and chunkwise properties from the base retention mechanism when applied to evolving graphs requires an explicit derivation of the node/edge update rule (likely in the architecture section) showing that it incurs no extra asymptotic cost or auxiliary structures; absent this, the 86.7x inference claim and asserted optimal balance do not necessarily follow.
Authors: We agree that an explicit derivation of the node/edge update rules is necessary to rigorously establish inheritance of the three computational paradigms without hidden costs. The current manuscript describes the extension at a high level but does not include the full step-by-step recurrence and chunkwise formulations for dynamic graphs. In the revised version we will add a dedicated subsection in the architecture section that derives the update rules from the base retention mechanism, proves the O(1) per-step inference cost, confirms parallel training complexity, and shows that no auxiliary structures or recomputation are introduced beyond standard graph operations. This addition will directly support the reported efficiency gains. revision: yes
Circularity Check
No circularity detected in GRN derivation chain
full rationale
The paper defines Graph Retention Networks by extending the retention mechanism to dynamic graphs via new architectural components for node/edge updates. The claimed properties (parallel training, O(1) inference, chunkwise training) are presented as following directly from these design choices and are validated through experiments on external benchmarks rather than by fitting parameters or self-referential definitions. No load-bearing self-citations, uniqueness theorems from prior author work, or reductions of predictions to inputs by construction appear in the abstract or described claims. The derivation remains self-contained with independent empirical content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Unai Alvarez-Rodriguez, Federico Battiston, Guilherme Ferraz de Arruda, Yamir Moreno, Matjaž Perc, and Vito Latora. 2021. Evolutionary dynamics of higher- order interactions in social networks.Nature Human Behaviour5, 5 (2021), 586–595
work page 2021
-
[2]
Jimmy Lei Ba. 2016. Layer normalization.arXiv preprint arXiv:1607.06450(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
- [3]
-
[4]
Claudio DT Barros, Matheus RF Mendonça, Alex B Vieira, and Artur Ziviani
-
[5]
A survey on embedding dynamic graphs.ACM Computing Surveys (CSUR) 55, 1 (2021), 1–37
work page 2021
-
[6]
Peter Battaglia, Razvan Pascanu, Matthew Lai, Danilo Jimenez Rezende, et al
-
[7]
Advances in neural information processing systems29 (2016)
Interaction networks for learning about objects, relations and physics. Advances in neural information processing systems29 (2016)
work page 2016
- [8]
-
[9]
Stephen Bonner, Amir Atapour-Abarghouei, Philip T Jackson, John Brennan, Ibad Kureshi, Georgios Theodoropoulos, Andrew Stephen McGough, and Boguslaw Obara. 2019. Temporal neighbourhood aggregation: Predicting future links in temporal graphs via recurrent variational graph convolutions. In2019 IEEE international conference on big data (Big Data). IEEE, 5336–5345
work page 2019
- [10]
-
[11]
Peng Cui, Xiao Wang, Jian Pei, and Wenwu Zhu. 2018. A survey on network embedding.IEEE transactions on knowledge and data engineering31 (2018), 833– 852
work page 2018
- [12]
-
[13]
Shihong Gao, Yiming Li, Yanyan Shen, Yingxia Shao, and Lei Chen. 2024. ETC: Efficient Training of Temporal Graph Neural Networks over Large-scale Dynamic Graphs.Proceedings of the VLDB Endowment17 (2024), 1060–1072
work page 2024
-
[14]
Mingyu Guan, Anand Padmanabha Iyer, and Taesoo Kim. 2022. DynaGraph: dynamic graph neural networks at scale. InProceedings of the 5th ACM SIGMOD Joint International Workshop on Graph Data Management Experiences & Systems (GRADES) and Network Data Analytics (NDA). 1–10
work page 2022
-
[15]
Shengnan Guo, Youfang Lin, Huaiyu Wan, Xiucheng Li, and Gao Cong. 2021. Learning dynamics and heterogeneity of spatial-temporal graph data for traffic forecasting.IEEE Transactions on Knowledge and Data Engineering34, 11 (2021), 5415–5428
work page 2021
-
[16]
Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingx- ing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, et al. 2019. Searching for mobilenetv3. InProceedings of the IEEE/CVF international conference on computer vision. 1314–1324
work page 2019
-
[17]
Shenyang Huang, Farimah Poursafaei, Jacob Danovitch, Matthias Fey, Weihua Hu, Emanuele Rossi, Jure Leskovec, Michael Bronstein, Guillaume Rabusseau, and Reihaneh Rabbany. 2024. Temporal graph benchmark for machine learning on temporal graphs.Advances in Neural Information Processing Systems36 (2024)
work page 2024
-
[18]
Srijan Kumar, Xikun Zhang, and Jure Leskovec. 2019. Predicting dynamic em- bedding trajectory in temporal interaction networks. InProceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining. 1269–1278
work page 2019
-
[19]
Hanjie Li, Changsheng Li, Kaituo Feng, Ye Yuan, Guoren Wang, and Hongyuan Zha. 2024. Robust knowledge adaptation for dynamic graph neural networks. IEEE Transactions on Knowledge and Data Engineering(2024)
work page 2024
-
[20]
Jie Li and Matteo Convertino. 2021. Inferring ecosystem networks as information flows.Scientific reports11, 1 (2021), 7094
work page 2021
-
[21]
Jintang Li, Zhouxin Yu, Zulun Zhu, Liang Chen, Qi Yu, Zibin Zheng, Sheng Tian, Ruofan Wu, and Changhua Meng. 2023. Scaling up dynamic graph representation learning via spiking neural networks. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 8588–8596
work page 2023
- [22]
-
[23]
Franco Manessi, Alessandro Rozza, and Mario Manzo. 2020. Dynamic graph convolutional networks.Pattern Recognition97 (2020), 107000
work page 2020
- [24]
-
[25]
Shengjie Min, Zhan Gao, Jing Peng, Liang Wang, Ke Qin, and Bo Fang. 2021. Stgsn—a spatial–temporal graph neural network framework for time-evolving social networks.Knowledge-Based Systems214 (2021), 106746
work page 2021
-
[26]
Jayanta Mondal and Amol Deshpande. 2012. Managing large dynamic graphs efficiently. InProceedings of the 2012 ACM SIGMOD International Conference on Management of Data. 145–156
work page 2012
-
[27]
Mandani Ntekouli, Gerasimos Spanakis, Lourens Waldorp, and Anne Roefs. 2024. Exploiting Individual Graph Structures to Enhance Ecological Momentary As- sessment (EMA) Forecasting. In2024 IEEE 40th International Conference on Data Engineering Workshops (ICDEW). IEEE, 158–166
work page 2024
-
[28]
Aldo Pareja, Giacomo Domeniconi, Jie Chen, Tengfei Ma, Toyotaro Suzumura, Hiroki Kanezashi, Tim Kaler, Tao Schardl, and Charles Leiserson. 2020. Evolvegcn: Evolving graph convolutional networks for dynamic graphs. InProceedings of the AAAI conference on artificial intelligence, Vol. 34. 5363–5370
work page 2020
-
[29]
Farimah Poursafaei, Shenyang Huang, Kellin Pelrine, and Reihaneh Rabbany
-
[30]
Towards better evaluation for dynamic link prediction.Advances in Neural Information Processing Systems35 (2022), 32928–32941
work page 2022
-
[31]
Xiafei Qiu, Wubin Cen, Zhengping Qian, You Peng, Ying Zhang, Xuemin Lin, and Jingren Zhou. 2018. Real-time constrained cycle detection in large dynamic graphs.Proceedings of the VLDB Endowment11, 12 (2018), 1876–1888
work page 2018
-
[32]
Emanuele Rossi, Ben Chamberlain, Fabrizio Frasca, Davide Eynard, Federico Monti, and Michael Bronstein. 2020. Temporal graph networks for deep learning on dynamic graphs.arXiv preprint arXiv:2006.10637(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [33]
-
[34]
Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jiany- ong Wang, and Furu Wei. 2023. Retentive network: A successor to transformer for large language models.arXiv preprint arXiv:2307.08621(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Rakshit Trivedi, Mehrdad Farajtabar, Prasenjeet Biswal, and Hongyuan Zha. 2019. Dyrep: Learning representations over dynamic graphs. InInternational conference on learning representations
work page 2019
-
[36]
A Vaswani. 2017. Attention is all you need.Advances in Neural Information Processing Systems(2017)
work page 2017
-
[37]
Jana Vatter, Ruben Mayer, and Hans-Arno Jacobsen. 2023. The evolution of dis- tributed systems for graph neural networks and their origin in graph processing and deep learning: A survey.Comput. Surveys56, 1 (2023), 1–37
work page 2023
-
[38]
Xinchen Wan, Kaiqiang Xu, Xudong Liao, Yilun Jin, Kai Chen, and Xin Jin. 2023. Scalable and efficient full-graph gnn training for large graphs.Proceedings of the ACM on Management of Data1 (2023), 1–23
work page 2023
- [39]
- [40]
-
[41]
Jason Weston, Sumit Chopra, and Antoine Bordes. 2014. Memory networks. arXiv preprint arXiv:1410.3916(2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[42]
Yuxia Wu, Yuan Fang, and Lizi Liao. 2024. On the Feasibility of Simple Trans- former for Dynamic Graph Modeling. InProceedings of the ACM on Web Confer- ence 2024. 870–880
work page 2024
-
[43]
Yuxin Wu and Kaiming He. 2018. Group normalization. InProceedings of the European conference on computer vision (ECCV). 3–19
work page 2018
-
[44]
Zonghan Wu, Shirui Pan, Guodong Long, Jing Jiang, and Chengqi Zhang. 2019. Graph wavenet for deep spatial-temporal graph modeling.arXiv preprint arXiv:1906.00121(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[45]
Da Xu, Chuanwei Ruan, Evren Korpeoglu, Sushant Kumar, and Kannan Achan
- [46]
-
[47]
Nan Yin, Mengzhu Wang, Zhenghan Chen, Giulia De Masi, Huan Xiong, and Bin Gu. 2024. Dynamic spiking graph neural networks. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 16495–16503
work page 2024
-
[48]
Bing Yu, Haoteng Yin, and Zhanxing Zhu. 2017. Spatio-temporal graph con- volutional networks: A deep learning framework for traffic forecasting.arXiv preprint arXiv:1709.04875(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[49]
Le Yu, Leilei Sun, Bowen Du, and Weifeng Lv. 2023. Towards better dynamic graph learning: New architecture and unified library.Advances in Neural Information Processing Systems36 (2023), 67686–67700
work page 2023
-
[50]
Siwei Zhang, Xi Chen, Yun Xiong, Xixi Wu, Yao Zhang, Yongrui Fu, Yinglong Zhao, and Jiawei Zhang. 2024. Towards adaptive neighborhood for advancing temporal interaction graph modeling. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 4290–4301
work page 2024
- [51]
- [52]
-
[53]
Hongkuan Zhou, Da Zheng, Xiang Song, George Karypis, and Viktor Prasanna
-
[54]
Disttgl: Distributed memory-based temporal graph neural network training. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. 1–12. WWW ’26, April 13–17, 2026, Dubai, United Arab Emirates Qian Chang et al
work page 2026
-
[55]
Yangjie Zhou, Jingwen Leng, Yaoxu Song, Shuwen Lu, Mian Wang, Chao Li, Minyi Guo, Wenting Shen, Yong Li, Wei Lin, et al. 2023. Ugrapher: High-performance graph operator computation via unified abstraction for graph neural networks. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Syste...
work page 2023
-
[56]
Dingyuan Zhu, Peng Cui, Ziwei Zhang, Jian Pei, and Wenwu Zhu. 2018. High- order proximity preserved embedding for dynamic networks.IEEE Transactions on Knowledge and Data Engineering30, 11 (2018), 2134–2144. A Additional Descriptions A.1 Time and Space Complexity Analysis Algorithm 1:Overall process of GRNs Input:Dynamic graphG=(V,E), node featuresX, edge...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.