DissolveStereo: Coarse Depth Injection for Zero-Shot Stereo Video Generation
Pith reviewed 2026-05-23 17:14 UTC · model grok-4.3
The pith
DissolveStereo generates consistent stereo videos from monocular diffusion models by injecting coarse depth maps without paired training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
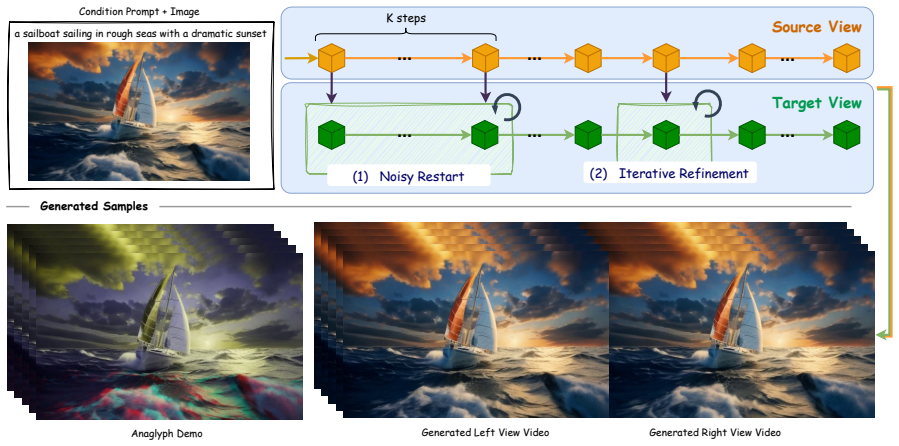
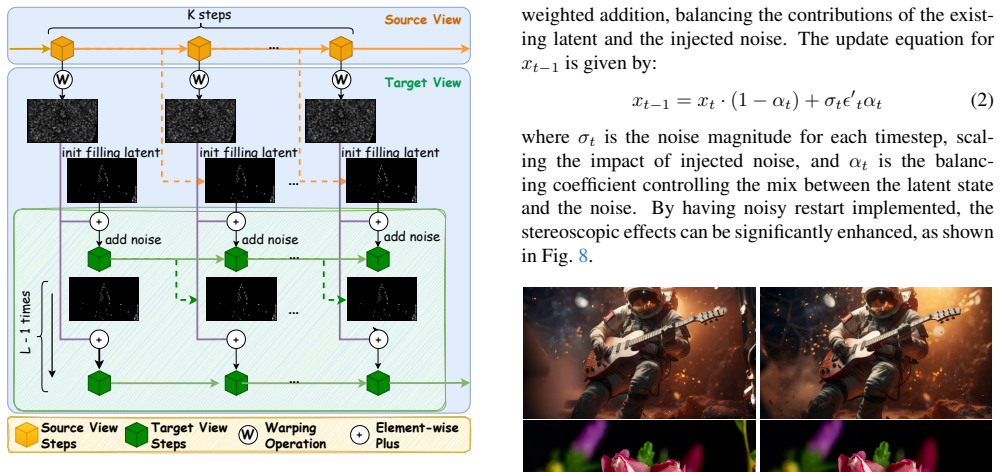
DissolveStereo shows that a noisy restart strategy combined with iterative refinement and dissolved depth maps allows zero-shot stereo video generation from video diffusion priors, producing higher epipolar consistency and temporal smoothness than prior approaches.
What carries the argument
dissolved depth maps that reduce high-frequency depth information to simplify and align latent representations across views during refinement.
Load-bearing premise
That noisy restarts plus dissolved depth maps will reliably align left and right latent spaces without introducing new artifacts that later steps cannot fix.
What would settle it
A generated stereo video that exhibits visible left-right mismatches or increased flickering when the dissolved depth maps are replaced by full-resolution depth maps or when the noisy restart is removed.
Figures
















read the original abstract
Generating high-quality stereo videos requires consistent depth perception and temporal coherence across frames. Despite advances in image and video synthesis using diffusion models, producing high-quality stereo videos remains a challenging task due to the difficulty of maintaining consistent temporal and spatial coherence between left and right views. We introduce DissolveStereo, a novel framework for zero-shot stereo video generation that leverages video diffusion priors without requiring paired training data. Our key innovations include a noisy restart strategy to initialize stereo-aware latent representations and an iterative refinement process that progressively harmonizes the latent space, addressing issues like temporal flickering and view inconsistencies. Importantly, we propose the use of dissolved depth maps to streamline latent space operations by reducing high-frequency depth information. Our comprehensive evaluations, including quantitative metrics and user studies, demonstrate that DissolveStereo produces high-quality stereo videos with enhanced depth consistency and temporal smoothness. In terms of epipolar consistency, our method achieves an 11.7% improvement in MEt3R score over the current state-of-the-art. Furthermore, user studies indicate strong perceptual gains over the previous arts, with an 8.0% higher perceived frame quality and 10.9% higher perceived temporal coherence. Our code is in https://github.com/shijianjian/DissolveStereo.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DissolveStereo, a zero-shot stereo video generation framework that builds on video diffusion priors without paired training data. It proposes a noisy restart strategy to initialize stereo-aware latent representations, an iterative refinement process to harmonize left/right views, and dissolved depth maps to reduce high-frequency depth information during latent operations. The central empirical claims are an 11.7% MEt3R improvement over prior state-of-the-art and 8.0–10.9% gains in user-study scores for frame quality and temporal coherence.
Significance. If the reported gains are reproducible and the mechanism is shown to be robust, the work would constitute a practical engineering contribution to consistent stereo video synthesis. The dissolved-depth injection and noisy-restart approach are concrete, testable ideas that could be adopted or extended by others working on view-consistent diffusion models.
major comments (2)
- [Abstract and §3] Abstract and §3 (framework): the claim that dissolved depth maps plus noisy restart reliably harmonize latents without introducing uncorrectable artifacts rests on the reported MEt3R and user-study deltas, yet no ablation isolating the dissolved-depth component, no failure-case analysis, and no error bars are supplied; this makes the 11.7% figure difficult to interpret as load-bearing evidence.
- [§4] §4 (experiments): the MEt3R improvement and user-study percentages are presented without baseline implementation details, exact hyper-parameter settings for the iterative refinement, or cross-validation across multiple seeds; these omissions directly affect the defensibility of the quantitative claims.
minor comments (2)
- The GitHub link is given but the manuscript does not state whether the released code includes the exact evaluation scripts used for MEt3R and the user study.
- [§3] Notation for “dissolved depth map” is introduced without an explicit equation or pseudocode showing how high-frequency components are removed before injection.
Simulated Author's Rebuttal
Thank you for your thoughtful review and for recognizing the practical contributions of DissolveStereo. We address each major comment below and commit to revisions that strengthen the empirical support and reproducibility of the work.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (framework): the claim that dissolved depth maps plus noisy restart reliably harmonize latents without introducing uncorrectable artifacts rests on the reported MEt3R and user-study deltas, yet no ablation isolating the dissolved-depth component, no failure-case analysis, and no error bars are supplied; this makes the 11.7% figure difficult to interpret as load-bearing evidence.
Authors: We acknowledge that an ablation isolating the dissolved-depth component would strengthen the evidence for its specific role. In the revised manuscript we will add a targeted ablation comparing the full model to a variant without dissolved depth maps. We will also add a dedicated limitations subsection discussing observed failure cases and potential artifacts. Regarding error bars, the primary experiments used fixed seeds for direct comparability; we will run additional trials with varied seeds and report standard deviations where feasible. revision: yes
-
Referee: [§4] §4 (experiments): the MEt3R improvement and user-study percentages are presented without baseline implementation details, exact hyper-parameter settings for the iterative refinement, or cross-validation across multiple seeds; these omissions directly affect the defensibility of the quantitative claims.
Authors: We agree that greater implementation transparency is needed. The revised §4 will include full baseline implementation details (including any code adaptations), the precise hyper-parameter values used for iterative refinement, and results across multiple random seeds to supply error bars and assess variability of the reported gains. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical engineering framework for zero-shot stereo video generation via diffusion models, relying on a noisy restart strategy and dissolved depth maps. All reported gains (MEt3R, user scores) are presented as experimental outcomes from evaluations rather than predictions derived from equations or first-principles results. No load-bearing self-citations, uniqueness theorems, ansatzes, or fitted-input predictions appear in the abstract or framework description; the central claims rest on external benchmarks and perceptual studies that remain independent of internal parameter definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Video diffusion models trained on monocular video contain latent representations that can be steered toward consistent stereo pairs by depth injection.
invented entities (1)
-
dissolved depth map
no independent evidence
Forward citations
Cited by 1 Pith paper
-
StereoSpace: Depth-Free Synthesis of Stereo Geometry via End-to-End Diffusion in a Canonical Space
A viewpoint-conditioned diffusion model generates stereo image pairs from monocular input in a canonical rectified space without using depth or explicit warping.
Reference graph
Works this paper leans on
-
[1]
Met3r: Measuring multi-view consistency in generated images
Mohammad Asim, Christopher Wewer, Thomas Wimmer, Bernt Schiele, and Jan Eric Lenssen. Met3r: Measuring multi-view consistency in generated images. arXiv preprint arXiv:2501.06336, 2025. 6
-
[2]
Sherwin Bahmani, Ivan Skorokhodov, Victor Rong, Gordon Wetzstein, Leonidas Guibas, Peter Wonka, Sergey Tulyakov, Jeong Joon Park, Andrea Tagliasacchi, and David B. Lindell. 4d-fy: Text-to-4d generation using hybrid score distillation sampling. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 2
work page 2024
-
[3]
Structure-from- motion with oriented points
Jonathan T Barron and Jovan Popovi ´c. Structure-from- motion with oriented points. In IEEE Transactions on Pat- tern Analysis and Machine Intelligence, 2015. 2
work page 2015
-
[4]
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
Aleksei Bochkovskii, Ama ¨el Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R Richter, and Vladlen Koltun. Depth pro: Sharp monocular metric depth in less than a second. arXiv preprint arXiv:2410.02073, 2024. 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Shengqu Cai, Eric Ryan Chan, Songyou Peng, Mohamad Shahbazi, Anton Obukhov, Luc Van Gool, and Gordon Wetzstein. Diffdreamer: Towards consistent unsupervised single-view scene extrapolation with conditional diffusion models. In Proceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 2139–2150, 2023. 6
work page 2023
-
[6]
Generative rendering: Controllable 4d-guided video generation with 2d diffusion models
Shengqu Cai, Duygu Ceylan, Matheus Gadelha, Chun- Hao Paul Huang, Tuanfeng Yang Wang, and Gordon Wet- zstein. Generative rendering: Controllable 4d-guided video generation with 2d diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7611–7620, 2024. 6
work page 2024
-
[7]
Masactrl: Tuning-free mu- tual self-attention control for consistent image synthesis and editing
Mingdeng Cao, Xintao Wang, Zhongang Qi, Ying Shan, Xi- aohu Qie, and Yinqiang Zheng. Masactrl: Tuning-free mu- tual self-attention control for consistent image synthesis and editing. In Proceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 22560–22570, 2023. 1
work page 2023
-
[8]
Fec: Three finetuning- free methods to enhance consistency for real image edit- ing
Songyan Chen and Jiancheng Huang. Fec: Three finetuning- free methods to enhance consistency for real image edit- ing. In 2023 International Conference on Image Processing, Computer Vision and Machine Learning (ICICML) , pages 76–87. IEEE, 2023. 1
work page 2023
-
[9]
Video depth anything: Consistent depth estimation for super-long videos
Sili Chen, Hengkai Guo, Shengnan Zhu, Feihu Zhang, Zi- long Huang, Jiashi Feng, and Bingyi Kang. Video depth anything: Consistent depth estimation for super-long videos. arXiv preprint arXiv:2501.12375, 2025. 2, 8
-
[10]
Anydoor: Zero-shot object-level im- age customization
Xi Chen, Lianghua Huang, Yu Liu, Yujun Shen, Deli Zhao, and Hengshuang Zhao. Anydoor: Zero-shot object-level im- age customization. In Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 6593–6602, 2024. 1
work page 2024
-
[11]
Luciddreamer: Domain-free gen- eration of 3d gaussian splatting scenes
Jaeyoung Chung, Suyoung Lee, Hyeongjin Nam, Jaerin Lee, and Kyoung Mu Lee. Luciddreamer: Domain-free gen- eration of 3d gaussian splatting scenes. arXiv preprint arXiv:2311.13384, 2023. 2
-
[12]
Svg: 3d stereoscopic video generation via denoising frame matrix
Peng Dai, Feitong Tan, Qiangeng Xu, David Futschik, Ruofei Du, Sean Fanello, Xiaojuan Qi, and Yinda Zhang. Svg: 3d stereoscopic video generation via denoising frame matrix. arXiv preprint arXiv:2407.00367, 2024. 3
-
[13]
Denoising dif- fusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models. In Advances in Neural Informa- tion Processing Systems, 2020. 2
work page 2020
-
[14]
Depthcrafter: Generating consistent long depth sequences for open-world videos
Wenbo Hu, Xiangjun Gao, Xiaoyu Li, Sijie Zhao, Xiaodong Cun, Yong Zhang, Long Quan, and Ying Shan. Depthcrafter: Generating consistent long depth sequences for open-world videos. arXiv preprint arXiv:2409.02095, 2024. 2, 5
-
[15]
Kv inversion: Kv embeddings learning for text-conditioned real image action editing
Jiancheng Huang, Yifan Liu, Jin Qin, and Shifeng Chen. Kv inversion: Kv embeddings learning for text-conditioned real image action editing. In Chinese Conference on Pattern Recognition and Computer Vision (PRCV) , pages 172–184. Springer, 2023. 1
work page 2023
-
[16]
Infusion: Inject and attention fusion for multi concept zero-shot text-based video editing
Anant Khandelwal. Infusion: Inject and attention fusion for multi concept zero-shot text-based video editing. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, pages 3017–3026, 2023. 1
work page 2023
-
[17]
Ro- bust consistent video depth estimation
Johannes Kopf, Xuejian Rong, and Jia-Bin Huang. Ro- bust consistent video depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1611–1621, 2021. 2
work page 2021
- [18]
-
[19]
Dynibar: Neural dynamic image-based rendering
Zhengqi Li, Qianqian Wang, Forrester Cole, Richard Tucker, and Noah Snavely. Dynibar: Neural dynamic image-based rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 4273–4284, 2023. 2
work page 2023
-
[20]
Robust dynamic radiance fields
Yu-Lun Liu, Chen Gao, Andreas Meuleman, Hung-Yu Tseng, Ayush Saraf, Changil Kim, Yung-Yu Chuang, Jo- hannes Kopf, and Jia-Bin Huang. Robust dynamic radiance fields. In Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, 2023. 2
work page 2023
-
[21]
Consistent video depth estimation.ACM Transactions on Graphics (ToG), 39(4):71–1, 2020
Xuan Luo, Jia-Bin Huang, Richard Szeliski, Kevin Matzen, and Johannes Kopf. Consistent video depth estimation.ACM Transactions on Graphics (ToG), 39(4):71–1, 2020. 2
work page 2020
-
[22]
Stereo conversion with disparity-aware warp- ing, compositing and inpainting
Lukas Mehl, Andr ´es Bruhn, Markus Gross, and Christo- pher Schroers. Stereo conversion with disparity-aware warp- ing, compositing and inpainting. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 4260–4269, 2024. 1
work page 2024
-
[23]
Dragondiffusion: Enabling drag-style manipula- tion on diffusion models
Chong Mou, Xintao Wang, Jiechong Song, Ying Shan, and Jian Zhang. Dragondiffusion: Enabling drag-style manipula- tion on diffusion models. arXiv preprint arXiv:2307.02421,
-
[24]
Jisu Nam, Heesu Kim, DongJae Lee, Siyoon Jin, Seungry- ong Kim, and Seunggyu Chang. Dreammatcher: Appearance matching self-attention for semantically-consistent text-to- image personalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 8100–8110, 2024. 1
work page 2024
-
[25]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. 9 Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image gener- ation with clip latents. arXiv preprint arXiv:2204.06125, 1 (2):3, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer
Rene Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, 44(3):1623–1637, 2022. 1
work page 2022
-
[28]
High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. In arXiv preprint arXiv:2112.10752, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
Immersepro: End- to-end stereo video synthesis via implicit disparity learning
Jian Shi, Zhenyu Li, and Peter Wonka. Immersepro: End- to-end stereo video synthesis via implicit disparity learning. arXiv preprint arXiv:2410.00262, 2024. 2
-
[30]
Dissolving is amplifying: Towards fine-grained anomaly detection
Jian Shi, Pengyi Zhang, Ni Zhang, Hakim Ghazzai, and Pe- ter Wonka. Dissolving is amplifying: Towards fine-grained anomaly detection. In European Conference on Computer Vision, pages 377–394. Springer, 2024. 5
work page 2024
-
[31]
3d photography using context-aware layered depth inpainting
Meng-Li Shih, Shih-Yang Su, Johannes Kopf, and Jia-Bin Huang. 3d photography using context-aware layered depth inpainting. In IEEE Conference on Computer Vision and Pat- tern Recognition (CVPR), 2020. 1
work page 2020
-
[32]
Realmdreamer: Text-driven 3d scene gener- ation with inpainting and depth diffusion
Jaidev Shriram, Alex Trevithick, Lingjie Liu, and Ravi Ra- mamoorthi. Realmdreamer: Text-driven 3d scene gener- ation with inpainting and depth diffusion. arXiv preprint arXiv:2404.07199, 2024. 2
-
[33]
Dreamcraft3d: Hierarchi- cal 3d generation with bootstrapped diffusion prior
Jingxiang Sun, Bo Zhang, Ruizhi Shao, Lizhen Wang, Wen Liu, Zhenda Xie, and Yebin Liu. Dreamcraft3d: Hierarchi- cal 3d generation with bootstrapped diffusion prior. arXiv preprint arXiv:2310.16818, 2023. 2
-
[34]
Make-it-3d: High-fidelity 3d creation from a single image with diffusion prior, 2023
Junshu Tang, Tengfei Wang, Bo Zhang, Ting Zhang, Ran Yi, Lizhuang Ma, and Dong Chen. Make-it-3d: High-fidelity 3d creation from a single image with diffusion prior, 2023. 2
work page 2023
-
[35]
Web stereo video supervision for depth prediction from dynamic scenes
Chaoyang Wang, Simon Lucey, Federico Perazzi, and Oliver Wang. Web stereo video supervision for depth prediction from dynamic scenes. In 2019 International Conference on 3D Vision (3DV), pages 348–357. IEEE, 2019. 1, 2
work page 2019
-
[36]
Stereodiffusion: Training-free stereo image generation using latent diffusion models
Lezhong Wang, Jeppe Revall Frisvad, Mark Bo Jensen, and Siavash Arjomand Bigdeli. Stereodiffusion: Training-free stereo image generation using latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition , pages 7416–7425, 2024. 2, 1
work page 2024
-
[37]
Jamie Watson, Oisin Mac Aodha, Daniyar Turmukhambetov, Gabriel J. Brostow, and Michael Firman. Learning stereo from single images. In European Conference on Computer Vision (ECCV), 2020. 1
work page 2020
-
[38]
Learning stereo from single images
Jamie Watson, Oisin Mac Aodha, Daniyar Turmukhambe- tov, Gabriel J Brostow, and Michael Firman. Learning stereo from single images. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part I 16, pages 722–740. Springer, 2020. 1
work page 2020
-
[39]
Deep3d: Fully automatic 2d-to-3d video conversion with deep convo- lutional neural networks
Junyuan Xie, Ross Girshick, and Ali Farhadi. Deep3d: Fully automatic 2d-to-3d video conversion with deep convo- lutional neural networks. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part IV 14 , pages 842–
work page 2016
-
[40]
Springer, 2016. 1, 2
work page 2016
-
[41]
Dynamicrafter: Animating open-domain images with video diffusion priors
Jinbo Xing, Menghan Xia, Yong Zhang, Haoxin Chen, Wangbo Yu, Hanyuan Liu, Xintao Wang, Tien-Tsin Wong, and Ying Shan. Dynamicrafter: Animating open-domain images with video diffusion priors. arXiv preprint arXiv:2310.12190, 2023. 5
-
[42]
Depth anything: Unleash- ing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Ji- ashi Feng, and Hengshuang Zhao. Depth anything: Unleash- ing the power of large-scale unlabeled data. arXiv preprint arXiv:2401.10891, 2024. 8
-
[43]
4real: Towards photorealistic 4d scene generation via video diffusion models, 2024
Heng Yu, Chaoyang Wang, Peiye Zhuang, Willi Mena- pace, Aliaksandr Siarohin, Junli Cao, Laszlo A Jeni, Sergey Tulyakov, and Hsin-Ying Lee. 4real: Towards photorealistic 4d scene generation via video diffusion models, 2024. 2
work page 2024
-
[44]
Hifi-123: Towards high-fidelity one image to 3d content gen- eration
Wangbo Yu, Li Yuan, Yan-Pei Cao, Xiangjun Gao, Xiaoyu Li, Wenbo Hu, Long Quan, Ying Shan, and Yonghong Tian. Hifi-123: Towards high-fidelity one image to 3d content gen- eration. arXiv preprint arXiv:2310.06744, 2023. 2
-
[45]
ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis
Wangbo Yu, Jinbo Xing, Li Yuan, Wenbo Hu, Xiaoyu Li, Zhipeng Huang, Xiangjun Gao, Tien-Tsin Wong, Ying Shan, and Yonghong Tian. Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis.arXiv preprint arXiv:2409.02048, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
4diffusion: Multi-view video diffusion model for 4d generation
Haiyu Zhang, Xinyuan Chen, Yaohui Wang, Xihui Liu, Yunhong Wang, and Yu Qiao. 4diffusion: Multi-view video diffusion model for 4d generation. arXiv preprint arXiv:2405.20674, 2024. 2
-
[47]
Text2nerf: Text-driven 3d scene generation with neu- ral radiance fields
Jingbo Zhang, Xiaoyu Li, Ziyu Wan, Can Wang, and Jing Liao. Text2nerf: Text-driven 3d scene generation with neu- ral radiance fields. IEEE Transactions on Visualization and Computer Graphics, 2024. 2
work page 2024
-
[48]
Temporal3d: 2d-to- 3d video conversion network with multi-frame fusion
Zheyu Zhang and Ronggang Wang. Temporal3d: 2d-to- 3d video conversion network with multi-frame fusion. In 2022 4th International Conference on Advances in Com- puter Technology, Information Science and Communications (CTISC), pages 1–5. IEEE, 2022. 2
work page 2022
-
[49]
Sijie Zhao, Wenbo Hu, Xiaodong Cun, Yong Zhang, Xi- aoyu Li, Zhe Kong, Xiangjun Gao, Muyao Niu, and Ying Shan. Stereocrafter: Diffusion-based generation of long and high-fidelity stereoscopic 3d from monocular videos. arXiv preprint arXiv:2409.07447, 2024. 2, 1
-
[50]
clip-score: CLIP Score for Py- Torch
SUN Zhengwentai. clip-score: CLIP Score for Py- Torch. https : / / github . com / taited / clip - score, 2023. Version 0.1.1. 6 10 StereoCrafter-Zero: Zero-Shot Stereo Video Generation with Noisy Restart Supplementary Material A. Preliminaries Image Warping for Stereo View Synthesis Generating a stereo pair of a single input image includes warping the im-...
work page 2023
-
[51]
Frame Quality (5 is best, 1 is poor)
-
[52]
Temporal Coherence (5 is best, 1 is poor)
-
[53]
Stereoscopic Effects (5 is best, 1 is poor)
-
[54]
Overall Conformity (5 is best, 1 is poor) Specifically, we define frame quality as the quality of the generated 2D images, temporal coherence as the consis- tency between frames, and stereoscopic effects as a subjec- tive experience of the stereo videos. For the overall confor- mity, while some stereo videos may exhibit stronger stereo effects, they can a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.