Position: Multimodal Large Language Models Can Significantly Advance Scientific Reasoning
Pith reviewed 2026-05-23 04:28 UTC · model grok-4.3
The pith
Multimodal large language models can advance scientific reasoning by integrating text and images across math, physics, chemistry, and biology.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
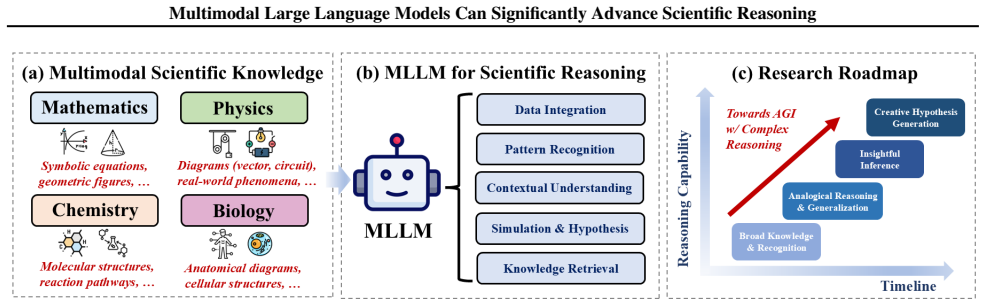
The paper claims that MLLMs, which integrate text, images, and other modalities, present an opportunity to overcome limitations in generalization and multimodal perception and thereby significantly advance scientific reasoning across disciplines such as mathematics, physics, chemistry, and biology. It proposes a four-stage research roadmap, summarizes the current state of MLLM applications, identifies key remaining challenges, and offers actionable suggestions toward artificial general intelligence.
What carries the argument
A four-stage research roadmap of scientific reasoning capabilities that tracks MLLM progress in integrating and reasoning over diverse data types.
If this is right
- MLLMs will support reasoning that draws on both textual evidence and visual data in scientific tasks.
- A staged roadmap will guide incremental improvements from basic perception to full cross-domain generalization.
- Addressing listed challenges will move MLLM use closer to artificial general intelligence.
- Applications will expand in mathematics, physics, chemistry, and biology through combined modality processing.
Where Pith is reading between the lines
- If the roadmap holds, MLLMs could eventually propose and test new hypotheses without human prompts in lab settings.
- Persistent perception gaps may require targeted datasets of paired scientific images and equations beyond current training.
- Cross-field transfer success would imply similar gains in non-scientific multimodal tasks like medical diagnosis.
Load-bearing premise
The assumption that MLLMs' ability to integrate and reason over diverse data types will overcome current limitations in generalization and multimodal perception.
What would settle it
A controlled comparison on multimodal scientific reasoning benchmarks where MLLMs show no improvement over text-only models in generalization or accuracy.
Figures




read the original abstract
Scientific reasoning, the process through which humans apply logic, evidence, and critical thinking to explore and interpret scientific phenomena, is essential in advancing knowledge reasoning across diverse fields. However, despite significant progress, current scientific reasoning models still struggle with generalization across domains and often fall short of multimodal perception. Multimodal Large Language Models (MLLMs), which integrate text, images, and other modalities, present an exciting opportunity to overcome these limitations and enhance scientific reasoning. Therefore, this position paper argues that MLLMs can significantly advance scientific reasoning across disciplines such as mathematics, physics, chemistry, and biology. First, we propose a four-stage research roadmap of scientific reasoning capabilities, and highlight the current state of MLLM applications in scientific reasoning, noting their ability to integrate and reason over diverse data types. Second, we summarize the key challenges that remain obstacles to achieving MLLM's full potential. To address these challenges, we propose actionable insights and suggestions for the future. Overall, our work offers a novel perspective on MLLM integration with scientific reasoning, providing the LLM community with a valuable vision for achieving Artificial General Intelligence (AGI).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This position paper argues that Multimodal Large Language Models (MLLMs) can significantly advance scientific reasoning across mathematics, physics, chemistry, and biology. It proposes a four-stage research roadmap for scientific reasoning capabilities, reviews the current state of MLLM applications noting their multimodal integration, summarizes remaining challenges, and offers actionable suggestions to realize their potential toward AGI.
Significance. If the roadmap and suggestions were grounded in concrete mechanisms or existing results, the paper could provide a useful organizing vision for multimodal AI in science. As written, the lack of any analysis connecting MLLM integration to gains in generalization or perception limits its potential impact on the field.
major comments (2)
- [Abstract] Abstract: the claim that MLLMs 'present an exciting opportunity to overcome these limitations' (generalization across domains and multimodal perception) is asserted without any supporting analysis, derivation, illustrative case, or reference to specific MLLM results demonstrating such gains.
- [Four-stage research roadmap] Four-stage research roadmap section: the stages are enumerated and current MLLM applications are noted, but no mechanism is supplied showing how multimodal integration produces the claimed improvements in cross-domain generalization; the challenges are listed but never connected back to a concrete MLLM capability or result.
minor comments (1)
- The manuscript would benefit from explicit definitions or criteria for each of the four stages so that the roadmap can be evaluated for novelty and testability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. As this is a position paper, our aim is to articulate a forward-looking vision rather than deliver new empirical derivations. We address the major comments below and indicate where revisions are feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that MLLMs 'present an exciting opportunity to overcome these limitations' (generalization across domains and multimodal perception) is asserted without any supporting analysis, derivation, illustrative case, or reference to specific MLLM results demonstrating such gains.
Authors: We agree the abstract states the central thesis without an immediate supporting reference or example. The manuscript is a position paper, so the claim is developed through the review of current MLLM applications in later sections rather than through new analysis. We will revise the abstract to include one or two concise references to existing MLLM results that illustrate multimodal gains in scientific tasks. revision: yes
-
Referee: [Four-stage research roadmap] Four-stage research roadmap section: the stages are enumerated and current MLLM applications are noted, but no mechanism is supplied showing how multimodal integration produces the claimed improvements in cross-domain generalization; the challenges are listed but never connected back to a concrete MLLM capability or result.
Authors: The roadmap is intentionally high-level to organize future research directions. Explicit causal mechanisms are not derived because the paper does not claim to introduce new technical results. We will revise the section to add brief, literature-based connections between specific MLLM capabilities (such as diagram interpretation) and potential generalization benefits, and to tie listed challenges more directly to those capabilities. revision: partial
Circularity Check
No circularity: position paper contains no derivations or self-referential constructions
full rationale
The paper is a position paper that advances an argument about MLLMs advancing scientific reasoning. It contains no equations, no fitted parameters, no derivations, and no load-bearing self-citations that reduce the central claim to its own inputs by construction. The four-stage roadmap and listed challenges are enumerated as suggestions rather than derived results. The claim is presented as a perspective, not as a prediction or theorem that collapses to prior definitions or fits within the paper itself. This is the expected outcome for a non-technical position paper with no quantitative chain to inspect.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
A Survey of Large Audio Language Models: Generalization, Trustworthiness, and Outlook
A survey of Large Audio Language Models that establishes a taxonomy of trustworthiness vulnerabilities and proposes a Defense-in-Depth roadmap for audio intelligence.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Improving multimodal interactive agents with reinforcement learning from human feedback
Abramson, J., Ahuja, A., Carnevale, F., Georgiev, P., Goldin, A., Hung, A., Landon, J., Lhotka, J., Lillicrap, T., Muldal, A., et al. Improving multimodal interactive agents with reinforcement learning from human feedback. arXiv preprint arXiv:2211.11602, 2022
-
[3]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Agarwal, L. and Verma, B. From methods to datasets: A survey on image-caption generators. Multimedia Tools and Applications, 83 0 (9): 0 28077--28123, 2024
work page 2024
-
[5]
S., Krishnan, N., and Jablonka, K
Alampara, N., Schilling-Wilhelmi, M., R \' os-Garc \' a, M., Mandal, I., Khetarpal, P., Grover, H. S., Krishnan, N., and Jablonka, K. M. Probing the limitations of multimodal language models for chemistry and materials research. arXiv preprint arXiv:2411.16955, 2024
-
[6]
arXiv preprint arXiv:2402.16827
Albalak, A., Elazar, Y., Xie, S. M., Longpre, S., Lambert, N., Wang, X., Muennighoff, N., Hou, B., Pan, L., Jeong, H., et al. A survey on data selection for language models. arXiv preprint arXiv:2402.16827, 2024
-
[7]
Multimodal large language models in health care: applications, challenges, and future outlook
AlSaad, R., Abd-Alrazaq, A., Boughorbel, S., Ahmed, A., Renault, M.-A., Damseh, R., and Sheikh, J. Multimodal large language models in health care: applications, challenges, and future outlook. Journal of medical Internet research, 26: 0 e59505, 2024
work page 2024
-
[8]
Claude 3.5 sonnet model card addendum
Anthropic, A. Claude 3.5 sonnet model card addendum. Claude-3.5 Model Card, 3, 2024
work page 2024
- [9]
-
[10]
Llemma: An Open Language Model For Mathematics
Azerbayev, Z., Schoelkopf, H., Paster, K., Santos, M. D., McAleer, S. M., Jiang, A. Q., Deng, J., Biderman, S., and Welleck, S. Llemma: An open language model for mathematics. ArXiv, abs/2310.10631, 2023. URL https://api.semanticscholar.org/CorpusID:264172303
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Bagal, V., Aggarwal, R., Vinod, P. K., and Priyakumar, U. D. Molgpt: Molecular generation using a transformer-decoder model. Journal of chemical information and modeling, 2021. URL https://api.semanticscholar.org/CorpusID:263484152
work page 2021
-
[12]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., and Zhou, J. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
A survey of multimodal large language model from a data-centric perspective
Bai, T., Liang, H., Wan, B., Xu, Y., Li, X., Li, S., Yang, L., Li, B., Wang, Y., Cui, B., et al. A survey of multimodal large language model from a data-centric perspective. arXiv preprint arXiv:2405.16640, 2024 a
-
[14]
Bai, Z., Wang, P., Xiao, T., He, T., Han, Z., Zhang, Z., and Shou, M. Z. Hallucination of multimodal large language models: A survey. arXiv preprint arXiv:2404.18930, 2024 b
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Learning and scientific reasoning
Bao, L., Cai, T., Koenig, K., Fang, K., Han, J., Wang, J., Liu, Q., Ding, L., Cui, L., Luo, Y., et al. Learning and scientific reasoning. Science, 323 0 (5914): 0 586--587, 2009
work page 2009
-
[16]
Barman, K. G., Caron, S., Sullivan, E., de Regt, H. W., de Austri, R. R., Boon, M., F \"a rber, M., Fr \"o se, S., Hasibi, F., Ipp, A., et al. Large physics models: Towards a collaborative approach with large language models and foundation models. arXiv preprint arXiv:2501.05382, 2025
-
[17]
Bayoudh, K., Knani, R., Hamdaoui, F., and Mtibaa, A. A survey on deep multimodal learning for computer vision: advances, trends, applications, and datasets. The Visual Computer, 38 0 (8): 0 2939--2970, 2022
work page 2022
-
[18]
C., Jiang, A., Li, J., Lipkin, B., Qina, Z., Rasul, K., Shen, Z., Soletskyi, R., and Tunstall, L
Beeching, E., Huang, S. C., Jiang, A., Li, J., Lipkin, B., Qina, Z., Rasul, K., Shen, Z., Soletskyi, R., and Tunstall, L. Numinamath 7b tir. https://huggingface.co/AI-MO/NuminaMath-7B-TIR, 2024
work page 2024
-
[19]
Reasoning language models: A blueprint
Besta, M., Barth, J., Schreiber, E., Kubicek, A., Catarino, A., Gerstenberger, R., Nyczyk, P., Iff, P., Li, Y., Houliston, S., et al. Reasoning language models: A blueprint. arXiv preprint arXiv:2501.11223, 2025
-
[20]
Science in the age of large language models
Birhane, A., Kasirzadeh, A., Leslie, D., and Wachter, S. Science in the age of large language models. Nature Reviews Physics, 5 0 (5): 0 277--280, 2023
work page 2023
-
[21]
Xai meets llms: A survey of the relation between explainable ai and large language models
Cambria, E., Malandri, L., Mercorio, F., Nobani, N., and Seveso, A. Xai meets llms: A survey of the relation between explainable ai and large language models. arXiv preprint arXiv:2407.15248, 2024
-
[23]
Cao, H., Liu, Z., Lu, X., Yao, Y., and Li, Y. Instructmol: Multi-modal integration for building a versatile and reliable molecular assistant in drug discovery. arXiv preprint arXiv:2311.16208, 2023 b
-
[24]
Chakraborty, N., Ornik, M., and Driggs-Campbell, K. Hallucination detection in foundation models for decision-making: A flexible definition and review of the state of the art. arXiv preprint arXiv:2403.16527, 2024
-
[25]
Chang, J. and Ye, J.-C. Bidirectional generation of structure and properties through a single molecular foundation model. Nature Communications, 15, 2022. URL https://api.semanticscholar.org/CorpusID:256827263
work page 2022
-
[26]
Generic attention-model explainability for interpreting bi-modal and encoder-decoder transformers
Chefer, H., Gur, S., and Wolf, L. Generic attention-model explainability for interpreting bi-modal and encoder-decoder transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp.\ 397--406, 2021
work page 2021
-
[27]
Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors
Chen, W., Su, Y., Zuo, J., Yang, C., Yuan, C., Chan, C.-M., Yu, H., Lu, Y., Hung, Y.-H., Qian, C., et al. Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors. In The Twelfth International Conference on Learning Representations, 2023 a
work page 2023
-
[28]
Theoremqa: A theorem-driven question answering dataset
Chen, W., Yin, M., Ku, M., Lu, P., Wan, Y., Ma, X., Xu, J., Wang, X., and Xia, T. Theoremqa: A theorem-driven question answering dataset. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp.\ 7889--7901, 2023 b
work page 2023
-
[29]
Fine-tuning large language models in education
Chen, Y., Chen, H., and Su, S. Fine-tuning large language models in education. In 2023 13th International Conference on Information Technology in Medicine and Education (ITME), pp.\ 718--723. IEEE, 2023 c
work page 2023
-
[30]
Chen, Z., Chen, S., Ning, Y., Zhang, Q., Wang, B., Yu, B., Li, Y., Liao, Z., Wei, C., Lu, Z., et al. Scienceagentbench: Toward rigorous assessment of language agents for data-driven scientific discovery. arXiv preprint arXiv:2410.05080, 2024 a
-
[31]
How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites
Chen, Z., Wang, W., Tian, H., Ye, S., Gao, Z., Cui, E., Tong, W., Hu, K., Luo, J., Ma, Z., et al. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites. Science China Information Sciences, 67 0 (12): 0 220101, 2024 b
work page 2024
-
[32]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 24185--24198, 2024 c
work page 2024
-
[33]
Chern, E., Zou, H., Li, X., Hu, J., Feng, K., Li, J., and Liu, P. Generative ai for math: Abel. https://github.com/GAIR-NLP/abel, 2023
work page 2023
-
[34]
Chi, H., Li, H., Yang, W., Liu, F., Lan, L., Ren, X., Liu, T., and Han, B. Unveiling causal reasoning in large language models: Reality or mirage? In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[35]
Exploring response uncertainty in mllms: An empirical evaluation under misleading scenarios
Dang, Y., Gao, M., Yan, Y., Zou, X., Gu, Y., Liu, A., and Hu, X. Exploring response uncertainty in mllms: An empirical evaluation under misleading scenarios. arXiv preprint arXiv:2411.02708, 2024 a
-
[36]
Explainable and interpretable multimodal large language models: A comprehensive survey
Dang, Y., Huang, K., Huo, J., Yan, Y., Huang, S., Liu, D., Gao, M., Zhang, J., Qian, C., Wang, K., et al. Explainable and interpretable multimodal large language models: A comprehensive survey. arXiv preprint arXiv:2412.02104, 2024 b
-
[37]
Das, R., Hristov, S., Li, H., Dimitrov, D., Koychev, I., and Nakov, P. EXAMS - V : A multi-discipline multilingual multimodal exam benchmark for evaluating vision language models. In Ku, L.-W., Martins, A., and Srikumar, V. (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 7768--7...
-
[38]
Dehimi, N. E. H. and Tolba, Z. Attention mechanisms in deep learning: Towards explainable artificial intelligence. In 2024 6th International Conference on Pattern Analysis and Intelligent Systems (PAIS), pp.\ 1--7. IEEE, 2024
work page 2024
-
[39]
Desirable characteristics for ai teaching assistants in programming education
Denny, P., MacNeil, S., Savelka, J., Porter, L., and Luxton-Reilly, A. Desirable characteristics for ai teaching assistants in programming education. In Proceedings of the 2024 on Innovation and Technology in Computer Science Education V. 1, pp.\ 408--414. 2024
work page 2024
-
[40]
Codefuse-13b: A pretrained multi-lingual code large language model
Di, P., Li, J., Yu, H., Jiang, W., Cai, W., Cao, Y., Chen, C., Chen, D., Chen, H., Chen, L., et al. Codefuse-13b: A pretrained multi-lingual code large language model. In Proceedings of the 46th International Conference on Software Engineering: Software Engineering in Practice, pp.\ 418--429, 2024
work page 2024
-
[41]
Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
A survey on rag meeting llms: Towards retrieval-augmented large language models
Fan, W., Ding, Y., Ning, L., Wang, S., Li, H., Yin, D., Chua, T.-S., and Li, Q. A survey on rag meeting llms: Towards retrieval-augmented large language models. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp.\ 6491--6501, 2024
work page 2024
-
[43]
Towards artificial general intelligence via a multimodal foundation model
Fei, N., Lu, Z., Gao, Y., Yang, G., Huo, Y., Wen, J., Lu, H., Song, R., Gao, X., Xiang, T., et al. Towards artificial general intelligence via a multimodal foundation model. Nature Communications, 13 0 (1): 0 3094, 2022
work page 2022
-
[44]
Feng, T., Jin, C., Liu, J., Zhu, K., Tu, H., Cheng, Z., Lin, G., and You, J. How far are we from agi. arXiv preprint arXiv:2405.10313, 2024
-
[45]
Flores, L., Kim, S., and Young, S. D. Addressing bias in artificial intelligence for public health surveillance. Journal of Medical Ethics, 50 0 (3): 0 190--194, 2024
work page 2024
-
[46]
Mme-survey: A comprehensive survey on evaluation of multimodal llms
Fu, C., Zhang, Y.-F., Yin, S., Li, B., Fang, X., Zhao, S., Duan, H., Sun, X., Liu, Z., Wang, L., et al. Mme-survey: A comprehensive survey on evaluation of multimodal llms. arXiv preprint arXiv:2411.15296, 2024
-
[47]
Fu, J.-Y., Lin, L., Gao, X., Liu, P., Chen, Z., Yang, Z., Zhang, S., Zheng, X., Li, Y., Liu, Y., Ye, X., Liao, Y., Liao, C., Chen, B., Song, C., Wan, J., Lin, Z., Zhang, F., Wang, Z., Zhang, D., and Gai, K. Kwaiyiimath: Technical report. ArXiv, abs/2310.07488, 2023. URL https://api.semanticscholar.org/CorpusID:263834833
-
[48]
Gadre, S. Y., Ilharco, G., Fang, A., Hayase, J., Smyrnis, G., Nguyen, T., Marten, R., Wortsman, M., Ghosh, D., Zhang, J., et al. Datacomp: In search of the next generation of multimodal datasets. Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[49]
Large language models empowered agent-based modeling and simulation: A survey and perspectives
Gao, C., Lan, X., Li, N., Yuan, Y., Ding, J., Zhou, Z., Xu, F., and Li, Y. Large language models empowered agent-based modeling and simulation: A survey and perspectives. Humanities and Social Sciences Communications, 11 0 (1): 0 1--24, 2024 a
work page 2024
-
[50]
Physically grounded vision-language models for robotic manipulation
Gao, J., Sarkar, B., Xia, F., Xiao, T., Wu, J., Ichter, B., Majumdar, A., and Sadigh, D. Physically grounded vision-language models for robotic manipulation. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pp.\ 12462--12469. IEEE, 2024 b
work page 2024
-
[51]
Goodman, S. N. Aligning statistical and scientific reasoning. Science, 352 0 (6290): 0 1180--1181, 2016
work page 2016
-
[52]
Guan, S. and Wang, G. Drug discovery and development in the era of artificial intelligence: From machine learning to large language models. Artificial Intelligence Chemistry, 2 0 (1): 0 100070, 2024
work page 2024
-
[53]
Mitigating large language model hallucinations via autonomous knowledge graph-based retrofitting
Guan, X., Liu, Y., Lin, H., Lu, Y., He, B., Han, X., and Sun, L. Mitigating large language model hallucinations via autonomous knowledge graph-based retrofitting. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pp.\ 18126--18134, 2024
work page 2024
-
[54]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
Guo, D., Zhu, Q., Yang, D., Xie, Z., Dong, K., Zhang, W., Chen, G., Bi, X., Wu, Y., Li, Y., et al. Deepseek-coder: When the large language model meets programming--the rise of code intelligence. arXiv preprint arXiv:2401.14196, 2024 a
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
What can large language models do in chemistry? a comprehensive benchmark on eight tasks
Guo, T., Nan, B., Liang, Z., Guo, Z., Chawla, N., Wiest, O., Zhang, X., et al. What can large language models do in chemistry? a comprehensive benchmark on eight tasks. Advances in Neural Information Processing Systems, 36: 0 59662--59688, 2023
work page 2023
-
[56]
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Guo, T., Chen, X., Wang, Y., Chang, R., Pei, S., Chawla, N. V., Wiest, O., and Zhang, X. Large language model based multi-agents: A survey of progress and challenges. arXiv preprint arXiv:2402.01680, 2024 b
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
Reasoning with Language Model is Planning with World Model
Hao, S., Gu, Y., Ma, H., Hong, J. J., Wang, Z., Wang, D. Z., and Hu, Z. Reasoning with language model is planning with world model. arXiv preprint arXiv:2305.14992, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
Hao, X., Chen, W., Yan, Y., Zhong, S., Wang, K., Wen, Q., and Liang, Y. Urbanvlp: A multi-granularity vision-language pre-trained foundation model for urban indicator prediction. arXiv preprint arXiv:2403.16831, 2024
-
[59]
W., Li, L., Yang, Z., Wang, L., and Cheng, Y
Hao, Y., Gu, J., Wang, H. W., Li, L., Yang, Z., Wang, L., and Cheng, Y. Can mllms reason in multimodality? emma: An enhanced multimodal reasoning benchmark. arXiv preprint arXiv:2501.05444, 2025
-
[60]
He, C., Luo, R., Bai, Y., Hu, S., Thai, Z. L., Shen, J., Hu, J., Han, X., Huang, Y., Zhang, Y., et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. arXiv preprint arXiv:2402.14008, 2024 a
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[61]
Mmworld: Towards multi-discipline multi-faceted world model evaluation in videos
He, X., Feng, W., Zheng, K., Lu, Y., Zhu, W., Li, J., Fan, Y., Wang, J., Li, L., Yang, Z., et al. Mmworld: Towards multi-discipline multi-faceted world model evaluation in videos. arXiv preprint arXiv:2406.08407, 2024 b
-
[62]
Cmmu: A benchmark for chinese multi-modal multi-type question understanding and reasoning
He, Z., Wu, X., Zhou, P., Xuan, R., Liu, G., Yang, X., Zhu, Q., and Huang, H. Cmmu: A benchmark for chinese multi-modal multi-type question understanding and reasoning. arXiv preprint arXiv:2401.14011, 2024 c
-
[63]
Measuring Massive Multitask Language Understanding
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[64]
Hocky, G. M. Connecting molecular properties with plain language. Nature Machine Intelligence, 6 0 (3): 0 249--250, 2024
work page 2024
-
[65]
SCITUNE: Aligning Large Language Models with Human-Curated Scientific Multimodal Instructions
Horawalavithana, S., Munikoti, S., Stewart, I., and Kvinge, H. Scitune: Aligning large language models with scientific multimodal instructions. arXiv preprint arXiv:2307.01139, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[66]
Hu, B., Zheng, L., Zhu, J., Ding, L., Wang, Y., and Gu, X. Teaching plan generation and evaluation with gpt-4: Unleashing the potential of llm in instructional design. IEEE Transactions on Learning Technologies, 2024
work page 2024
- [67]
-
[68]
Towards Reasoning in Large Language Models: A Survey
Huang, J. and Chang, K. C.-C. Towards reasoning in large language models: A survey. arXiv preprint arXiv:2212.10403, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[69]
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X., Qin, B., et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Transactions on Information Systems, 2023
work page 2023
-
[70]
Huang, Y., Gao, T., Zhang, J., Liu, X., and Wang, G. Adapting large language models for biomedicine though retrieval-augmented generation with documents scoring. In 2024 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), pp.\ 5770--5775. IEEE, 2024 a
work page 2024
-
[71]
Huang, Z., Wang, Z., Xia, S., and Liu, P. Olympicarena medal ranks: Who is the most intelligent ai so far? arXiv preprint arXiv:2406.16772, 2024 b
-
[72]
Hui, B., Yang, J., Cui, Z., Yang, J., Liu, D., Zhang, L., Liu, T., Zhang, J., Yu, B., Lu, K., et al. Qwen2. 5-coder technical report. arXiv preprint arXiv:2409.12186, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[73]
Mmneuron: Discovering neuron-level domain-specific interpretation in multimodal large language model
Huo, J., Yan, Y., Hu, B., Yue, Y., and Hu, X. Mmneuron: Discovering neuron-level domain-specific interpretation in multimodal large language model. arXiv preprint arXiv:2406.11193, 2024
-
[74]
Ishmam, M. F., Shovon, M. S. H., Mridha, M. F., and Dey, N. From image to language: A critical analysis of visual question answering (vqa) approaches, challenges, and opportunities. Information Fusion, pp.\ 102270, 2024
work page 2024
-
[75]
Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., Low, A., Helyar, A., Madry, A., Beutel, A., Carney, A., et al. Openai o1 system card. arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[76]
P., Anand, A., Dharmadhikari, A., Marathe, A., and Shah, R
Jaiswal, R., Jain, D., Popat, H. P., Anand, A., Dharmadhikari, A., Marathe, A., and Shah, R. R. Improving physics reasoning in large language models using mixture of refinement agents. arXiv preprint arXiv:2412.00821, 2024
-
[77]
A survey on large language model hallucination via a creativity perspective
Jiang, X., Tian, Y., Hua, F., Xu, C., Wang, Y., and Guo, J. A survey on large language model hallucination via a creativity perspective. arXiv preprint arXiv:2402.06647, 2024
-
[78]
Reasoning grasping via multimodal large language model
Jin, S., Xu, J., Lei, Y., and Zhang, L. Reasoning grasping via multimodal large language model. arXiv preprint arXiv:2402.06798, 2024 a
-
[79]
Cladder: A benchmark to assess causal reasoning capabilities of language models
Jin, Z., Chen, Y., Leeb, F., Gresele, L., Kamal, O., Lyu, Z., Blin, K., Gonzalez Adauto, F., Kleiman-Weiner, M., Sachan, M., et al. Cladder: A benchmark to assess causal reasoning capabilities of language models. Advances in Neural Information Processing Systems, 36, 2024 b
work page 2024
-
[80]
C., De Sousa Ribeiro, F., Oktay, O., McCradden, M., and Glocker, B
Jones, C., Castro, D. C., De Sousa Ribeiro, F., Oktay, O., McCradden, M., and Glocker, B. A causal perspective on dataset bias in machine learning for medical imaging. Nature Machine Intelligence, 6 0 (2): 0 138--146, 2024
work page 2024
-
[81]
Highly accurate protein structure prediction with alphafold
Jumper, J., Evans, R., Pritzel, A., Green, T., Figurnov, M., Ronneberger, O., Tunyasuvunakool, K., Bates, R., Z \' dek, A., Potapenko, A., et al. Highly accurate protein structure prediction with alphafold. nature, 596 0 (7873): 0 583--589, 2021
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.