Distributional Autoencoders Know the Score
Pith reviewed 2026-05-23 03:14 UTC · model grok-4.3
The pith
A distributional autoencoder derives a closed-form link from its optimal level-set geometries to the data distribution's score and identifies intrinsic dimension from excess latent components.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
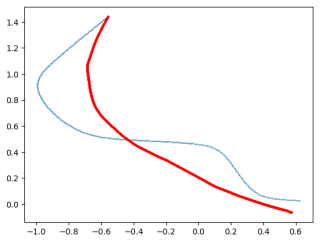
We derive a closed-form relation linking each optimal level-set geometry to the data-distribution score. This result explains DPA's empirical ability to disentangle factors of variation of the data, as well as allows the score to be recovered directly from samples. When the data follows the Boltzmann distribution, we demonstrate that this relation yields an approximation of the minimum free-energy path for the Mueller-Brown potential in a single fit. Second, we prove that if the data lies on a manifold that can be approximated by the encoder, latent components beyond the manifold dimension are conditionally independent of the data distribution - carrying no additional information - and thus
What carries the argument
The closed-form relation linking each optimal level-set geometry to the data-distribution score, which also underpins the proof of conditional independence for excess latent components.
If this is right
- The score of the data distribution can be recovered directly from samples via the closed-form relation.
- Disentanglement of factors of variation follows from the geometry-score link.
- For Boltzmann-distributed data, a single fit approximates the minimum free-energy path.
- A single model learns the data distribution and its intrinsic dimension simultaneously with exact guarantees.
Where Pith is reading between the lines
- The geometry-score relation could support direct use of the autoencoder for score-based generative sampling without a separate estimator.
- Testing on synthetic manifolds with known intrinsic dimension would check whether excess latents reliably flag that dimension.
- The Boltzmann-case result hints at possible extensions to other energy-based distributions for path approximations.
Load-bearing premise
The data distribution permits an optimal level-set geometry in the DPA objective and the encoder can approximate the manifold on which the data lies.
What would settle it
A direct comparison where the score recovered from the autoencoder's level-set geometry fails to match the score estimated independently from the same data samples.
Figures






read the original abstract
The Distributional Principal Autoencoder (DPA) combines distributionally correct reconstruction with principal-component-like interpretability of the encodings. In this work, we provide exact theoretical guarantees on both fronts. First, we derive a closed-form relation linking each optimal level-set geometry to the data-distribution score. This result explains DPA's empirical ability to disentangle factors of variation of the data, as well as allows the score to be recovered directly from samples. When the data follows the Boltzmann distribution, we demonstrate that this relation yields an approximation of the minimum free-energy path for the Mueller-Brown potential in a single fit. Second, we prove that if the data lies on a manifold that can be approximated by the encoder, latent components beyond the manifold dimension are conditionally independent of the data distribution - carrying no additional information - and thus reveal the intrinsic dimension. Together, these results show that a single model can learn the data distribution and its intrinsic dimension with exact guarantees simultaneously, unifying two longstanding goals of unsupervised learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Distributional Principal Autoencoder (DPA) and claims two main theoretical results with exact guarantees: (1) a closed-form relation between each optimal level-set geometry and the data-distribution score, which explains disentanglement, permits direct score recovery from samples, and (for Boltzmann data) yields an approximation to the minimum free-energy path of the Mueller-Brown potential in one fit; (2) a proof that, when data lies on a manifold approximable by the encoder, latent components beyond the manifold dimension are conditionally independent of the data distribution and thus reveal the intrinsic dimension. Together these unify distribution learning and dimension estimation.
Significance. If the closed-form derivations and the manifold-independence result hold with the stated generality, the work would be significant: it supplies a single model with exact (non-asymptotic) guarantees for both score estimation and intrinsic-dimension recovery, directly addressing two core unsupervised-learning objectives. The parameter-free character of the level-set/score link and the unification claim would be notable strengths.
major comments (2)
- [abstract / manifold theorem] The manifold result (abstract, paragraph beginning 'Second, we prove that if the data lies on a manifold...'): the stated conclusion that extra latent components are conditionally independent of the data distribution under mere 'approximability' by the encoder is load-bearing for the intrinsic-dimension claim. Conditional independence of the extra latents from the data (and hence from the score) holds exactly only when the encoder range coincides with the manifold or reconstruction error is identically zero on the support; the derivation must therefore either (a) state the precise error tolerance under which independence is recovered or (b) show that the approximation error vanishes in the relevant measure. Without this clarification the unification result rests on an implicit exact-capture assumption.
- [closed-form derivation] § on the closed-form level-set/score relation (the derivation linking optimal level-set geometry to the data-distribution score): the abstract asserts an exact, closed-form relation that 'allows the score to be recovered directly from samples,' yet the provided text supplies neither the explicit functional form nor the steps establishing that the relation is free of post-hoc fitting choices. If the relation reduces to a fitted quantity by construction, the 'exact guarantee' and 'parameter-free' claims are undermined.
minor comments (2)
- [abstract] Abstract: the claim of 'exact theoretical guarantees' and 'closed-form relation' is stated without any displayed equation or theorem label, making it impossible for a reader to verify the scope of the result from the abstract alone.
- [Boltzmann / Mueller-Brown paragraph] The Mueller-Brown experiment is presented as a single-fit demonstration; a brief statement of the numerical tolerance used to declare 'approximation' of the minimum free-energy path would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major point below, with revisions planned where the manuscript requires clarification.
read point-by-point responses
-
Referee: [abstract / manifold theorem] The manifold result (abstract, paragraph beginning 'Second, we prove that if the data lies on a manifold...'): the stated conclusion that extra latent components are conditionally independent of the data distribution under mere 'approximability' by the encoder is load-bearing for the intrinsic-dimension claim. Conditional independence of the extra latents from the data (and hence from the score) holds exactly only when the encoder range coincides with the manifold or reconstruction error is identically zero on the support; the derivation must therefore either (a) state the precise error tolerance under which independence is recovered or (b) show that the approximation error vanishes in the relevant measure. Without this clarification the unification result rests on an implicit exact-capture assumption.
Authors: We agree that the abstract's phrasing with 'approximable' is imprecise and requires explicit conditions. The full proof establishes conditional independence exactly when the encoder range coincides with the manifold (i.e., reconstruction error is zero on the data support). In revision we will update the abstract and theorem statement to state this precise condition and note that the result holds under exact capture, thereby removing any implicit assumption. revision: yes
-
Referee: [closed-form derivation] § on the closed-form level-set/score relation (the derivation linking optimal level-set geometry to the data-distribution score): the abstract asserts an exact, closed-form relation that 'allows the score to be recovered directly from samples,' yet the provided text supplies neither the explicit functional form nor the steps establishing that the relation is free of post-hoc fitting choices. If the relation reduces to a fitted quantity by construction, the 'exact guarantee' and 'parameter-free' claims are undermined.
Authors: The explicit functional form and derivation steps appear in the dedicated section on the level-set/score relation, obtained directly from the optimality conditions of the DPA objective with no post-hoc parameters. To address the referee's concern we will insert a direct pointer from the abstract to this section and restate the parameter-free character of the relation. revision: partial
Circularity Check
No circularity; derivations stated as independent results
full rationale
The abstract states two theoretical results—a closed-form relation linking optimal level-set geometry to the data-distribution score, and a proof that latent components beyond manifold dimension are conditionally independent under encoder approximation—without providing any equations, derivation steps, or self-citations. No load-bearing reductions to fitted inputs, self-definitions, or author-imported uniqueness theorems are visible in the given text. The claims are presented as derived and proved from the DPA objective and manifold assumptions, with no evidence that any prediction reduces to its inputs by construction. The derivation chain is therefore self-contained on inspection.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Data lies on a manifold approximable by the encoder
- domain assumption Data follows Boltzmann distribution when demonstrating minimum free-energy path approximation
Reference graph
Works this paper leans on
-
[1]
G. Alain and Y . Bengio. What Regularized Auto-Encoders Learn from the Data-Generating Distribution.Journal of Machine Learning Research, 15(110):3743–3773, 2014. ISSN 1533-
work page 2014
-
[2]
URLhttp://jmlr.org/papers/v15/alain14a.html
- [3]
-
[4]
Implicit Density Estimation by Local Moment Matching to Sample from Auto-Encoders
Y . Bengio, G. Alain, and S. Rifai. Implicit Density Estimation by Local Moment Match- ing to Sample from Auto-Encoders, 2012. URL http://arxiv.org/abs/1207.0057. arXiv:1207.0057 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[5]
L. Bonati, E. Trizio, A. Rizzi, and M. Parrinello. A unified framework for machine learning collective variables for enhanced sampling simulations: mlcolvar.The Journal of Chemical Physics, 159(1):014801, July 2023. ISSN 0021-9606, 1089-7690. doi: 10.1063/5.0156343. URLhttps://doi.org/10.1063/5.0156343
-
[6]
J. Braunsmann, M. Rajkovi´c, M. Rumpf, and B. Wirth. Convergent autoencoder approximation of low bending and low distortion manifold embeddings.ESAIM: Mathematical Modelling and Numerical Analysis, 58(1):335–361, Jan. 2024. ISSN 2822-7840, 2804-7214. doi: 10/ g9hp7w. URL https://www.esaim-m2an.org/articles/m2an/abs/2024/01/ m2an220261/m2an220261.html. Num...
work page 2024
-
[7]
R. T. Q. Chen, X. Li, R. Grosse, and D. Duvenaud. Isolating Sources of Disentangle- ment in Variational Autoencoders, 2018. URL http://arxiv.org/abs/1802.04942. arXiv:1802.04942 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
W. Chen and A. L. Ferguson. Molecular enhanced sampling with autoencoders: On-the- fly collective variable discovery and accelerated free energy landscape exploration.Journal of Computational Chemistry, 39(25):2079–2102, Sept. 2018. ISSN 0192-8651, 1096-987X. doi: 10.1002/jcc.25520. URL https://onlinelibrary.wiley.com/doi/abs/10. 1002/jcc.25520. _eprint: ...
-
[9]
W. E, W. Ren, and E. Vanden-Eijnden. String method for the study of rare events.Phys. Rev. B, 66:052301, Aug 2002. doi: 10.1103/PhysRevB.66.052301. URL https://link.aps. org/doi/10.1103/PhysRevB.66.052301
-
[10]
M. Giaquinta and S. Hildebrandt.Calculus of Variations I, volume 310 ofGrundlehren der mathematischen Wissenschaften. Springer Berlin Heidelberg, Berlin, Heidelberg, 2004. ISBN 978-3-642-08074-6 978-3-662-03278-7. doi: 10.1007/978-3-662-03278-7. URL http: //link.springer.com/10.1007/978-3-662-03278-7
-
[11]
T. Gneiting and A. E. Raftery. Strictly Proper Scoring Rules, Prediction, and Estimation.Journal of the American Statistical Association, 102(477):359–378, Mar. 2007. ISSN 0162-1459, 1537- 274X. doi: 10/c6758w. URL http://www.tandfonline.com/doi/abs/10.1198/ 016214506000001437
work page 2007
-
[12]
I. Higgins, L. Matthey, A. Pal, C. P. Burgess, X. Glorot, M. Botvinick, S. Mohamed, and A. Ler- chner. beta-V AE: Learning Basic Visual Concepts with a Constrained Variational Framework. Nov. 2016. URL https://www.semanticscholar.org/paper/beta-VAE% 3A-Learning-Basic-Visual-Concepts-with-a-Higgins-Matthey/ a90226c41b79f8b06007609f39f82757073641e2
work page 2016
-
[13]
H. Kim and A. Mnih. Disentangling by Factorising, 2018. URL http://arxiv.org/abs/ 1802.05983. arXiv:1802.05983 [cs, stat]. 11
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
J. M. Lee.Introduction to Smooth Manifolds, volume 218 ofGraduate Texts in Mathematics. Springer New York, New York, NY , 2012. ISBN 978-1-4419-9981-8 978-1-4419-9982-5. doi: 10.1007/978-1-4419-9982-5. URL https://link.springer.com/10.1007/ 978-1-4419-9982-5
- [15]
-
[16]
A. Mardt, L. Pasquali, H. Wu, and F. Noé. V AMPnets for deep learning of molecular kinetics.Na- ture Communications, 9(1):5, Jan. 2018. ISSN 2041-1723. doi: 10.1038/s41467-017-02388-1. URL https://www.nature.com/articles/s41467-017-02388-1 . Publisher: Nature Publishing Group
-
[17]
K. Müller and L. D. Brown. Location of saddle points and minimum energy paths by a constrained simplex optimization procedure.Theoretica Chimica Acta, 53(1):75–93, 1979. ISSN 0040-5744, 1432-2234. doi: 10/bkwf52. URL https://doi.org/10.1007/ BF00547608
work page 1979
-
[18]
S. Schonsheck, J. Chen, and R. Lai. Chart Auto-Encoders for Manifold Structured Data, 2019. URLhttp://arxiv.org/abs/1912.10094. arXiv:1912.10094 [cs]
-
[19]
Distributional Principal Autoencoders
X. Shen and N. Meinshausen. Distributional Principal Autoencoders, Apr. 2024. URL http: //arxiv.org/abs/2404.13649. arXiv:2404.13649 [cs, stat]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
X. Shen and N. Meinshausen. Engression: extrapolation through the lens of distributional regression.Journal of the Royal Statistical Society Series B: Statistical Methodology, page qkae108, Nov. 2024. ISSN 1369-7412, 1467-9868. doi: 10/g9hp74. URL https://doi. org/10.1093/jrsssb/qkae108
- [21]
-
[22]
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-Based Generative Modeling through Stochastic Differential Equations, 2020. URL http://arxiv. org/abs/2011.13456. arXiv:2011.13456 [cs, stat]
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[23]
P. Vincent. A Connection Between Score Matching and Denoising Autoencoders.Neural Computation, 23(7):1661–1674, July 2011. ISSN 0899-7667, 1530-888X. doi: 10/d7h7bn. URLhttps://doi.org/10.1162/NECO_a_00142
-
[24]
Y . Zheng, T. He, Y . Qiu, and D. Wipf. Learning Manifold Dimensions with Conditional Varia- tional Autoencoders. Oct. 2022. URL https://openreview.net/forum?id=Lvlxq_ H96lI#:~:text=as%20is%20likely%20the%20case,world%20datasets. 12 NeurIPS Paper Checklist 1)Claims Question: Do the main claims made in the abstract and introduction accurately reflect the p...
work page 2022
-
[25]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
-
[26]
We will argue that the second, divergence terms become negligible in the first-order station- arity conditions (Eq. 22)
-
[27]
At this order(i.e., at order ε), we will show that theintegrandsof the first terms must coincidealmost surely. From matching the second terms (with the perturbation inside the divergence), one might expect that on the level sets, we would have f1(y) a.e. ≡f 2(y), which would lead to spherical level sets: ∥y−c(X)∥ 2 = V(X) Z(X) , which cannot be justified....
-
[28]
If Le(X) were to extend to infinity (the “times the measure” part), thePdata factor in f1,2 would kill this contribution, as Pdata vanishes quickly enough for the level set variance V(X)to be finite (by assumption). Thus the (flux) integral is at mostO ε2 . This means, that when considering the first-order optimality condition 22, for which we have obtain...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.