Rethinking Training Targets, Architectures and Data Quality for Universal Speech Enhancement
Pith reviewed 2026-05-15 17:10 UTC · model grok-4.3
The pith
Time-shifted anechoic clean speech as training target and two-stage framework reach state-of-the-art universal speech enhancement
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
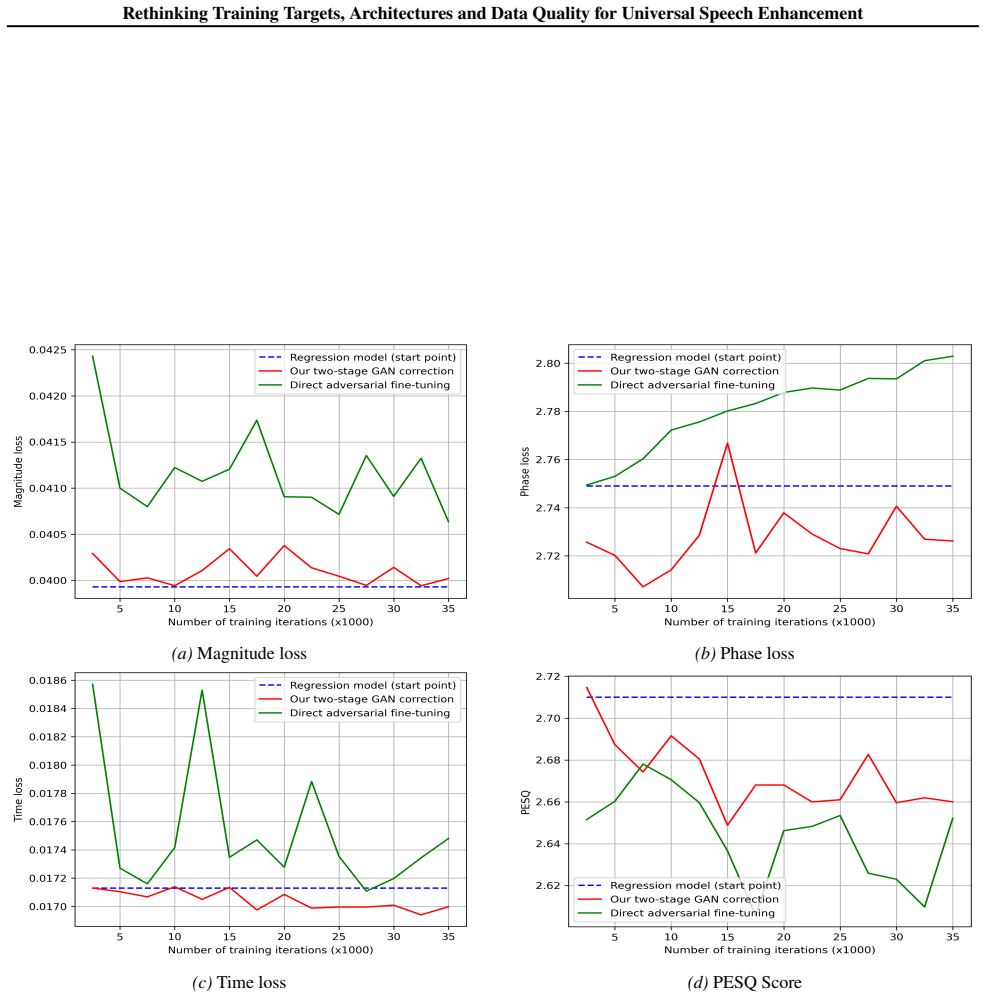
Time-shifted anechoic clean speech is a superior learning target to early-reflected speech for perceptual quality and ASR performance. Guided by distortion-perception tradeoff theory, a two-stage framework achieves minimal distortion at any chosen perceptual quality level. Large uncurated corpora impose a performance ceiling because models leave subtle artifacts intact. The approach sets new state-of-the-art results on the URGENT 2025 non-blind test set and shows strong language-agnostic generalization useful for improving TTS training data.
What carries the argument
Two-stage framework that first optimizes perceptual quality then refines for minimal distortion, using time-shifted anechoic clean speech as the learning target instead of early-reflected speech.
If this is right
- Higher perceptual quality and better ASR accuracy hold across diverse degradation conditions.
- The method directly improves quality of training data for text-to-speech systems.
- Language-agnostic generalization allows deployment without language-specific retraining.
- State-of-the-art results on the URGENT 2025 non-blind test set follow from the combined changes.
Where Pith is reading between the lines
- Curation of training data may matter more than raw volume for future speech enhancement systems.
- The same target-selection logic could be tested on music or environmental sound restoration.
- TTS pipelines could incorporate this enhancement step as a standard preprocessing stage to raise synthesis fidelity.
- The performance ceiling observed with uncurated data suggests systematic artifact audits before scaling datasets.
Load-bearing premise
Time-shifted anechoic clean speech is a universally superior learning target for perceptual quality and downstream ASR across all degradation conditions and datasets.
What would settle it
An experiment on the URGENT 2025 test set or another benchmark in which a model trained with early-reflected targets scores higher on perceptual metrics or lower ASR word error rate than the time-shifted anechoic version.
Figures








read the original abstract
Universal Speech Enhancement (USE) aims to restore speech quality under diverse degradation conditions while preserving signal fidelity. Despite recent progress, key challenges in training target selection, the distortion--perception tradeoff, and data curation remain unresolved. In this work, we systematically address these three overlooked problems. First, we revisit the conventional practice of using early-reflected speech as the dereverberation target and show that it can degrade perceptual quality and downstream ASR performance. We instead demonstrate that time-shifted anechoic clean speech provides a superior learning target. Second, guided by the distortion--perception tradeoff theory, we propose a simple two-stage framework that achieves minimal distortion under a given level of perceptual quality. Third, we analyze the trade-off between training data scale and quality for USE, revealing that training on large uncurated corpora imposes a performance ceiling, as models struggle to remove subtle artifacts. Our method achieves state-of-the-art performance on the URGENT 2025 non-blind test set and exhibits strong language-agnostic generalization, making it effective for improving TTS training data. Model weights are available for download at: https://huggingface.co/nvidia/RE-USE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper addresses challenges in universal speech enhancement by arguing that time-shifted anechoic clean speech is a superior training target compared to early-reflected speech, proposing a two-stage framework guided by distortion-perception tradeoff theory to minimize distortion at a given perceptual quality level, and analyzing trade-offs in training data scale versus quality. It claims state-of-the-art results on the URGENT 2025 non-blind test set, language-agnostic generalization, and utility for improving TTS training data, with model weights released publicly.
Significance. If the empirical results hold, the work could meaningfully advance universal speech enhancement by clarifying training target selection and data curation practices, with potential benefits for downstream ASR and TTS applications. The public release of model weights supports reproducibility and is a clear strength.
major comments (2)
- [Abstract] Abstract: the SOTA claim on the URGENT 2025 non-blind test set and the superiority of the time-shifted anechoic target are asserted without any quantitative metrics, delta scores, error bars, statistical significance tests, or baseline comparisons, which directly underpins the central claims about target selection and overall performance.
- [Abstract] Abstract and data-curation analysis: no cross-condition ablations or results on held-out languages/datasets are provided to support that the time-shifted anechoic target yields better perceptual quality and ASR performance across all listed degradations, leaving the language-agnostic generalization claim without load-bearing evidence.
minor comments (1)
- The manuscript would benefit from a dedicated results section or table presenting all quantitative evaluations, including ablations on the target choice, to allow readers to assess the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract requires quantitative support for the central claims and will revise it accordingly. We also address the generalization evidence below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the SOTA claim on the URGENT 2025 non-blind test set and the superiority of the time-shifted anechoic target are asserted without any quantitative metrics, delta scores, error bars, statistical significance tests, or baseline comparisons, which directly underpins the central claims about target selection and overall performance.
Authors: We agree that the abstract should be self-contained with key quantitative results. In the revision we will insert specific metrics (e.g., PESQ, DNSMOS, and ASR WER deltas versus the strongest baselines on the URGENT 2025 non-blind set), including error bars from repeated runs and statistical significance indicators. These numbers are already reported with full tables and ablations in Sections 4 and 5; the abstract will now reference them directly. revision: yes
-
Referee: [Abstract] Abstract and data-curation analysis: no cross-condition ablations or results on held-out languages/datasets are provided to support that the time-shifted anechoic target yields better perceptual quality and ASR performance across all listed degradations, leaving the language-agnostic generalization claim without load-bearing evidence.
Authors: The full manuscript already contains multi-dataset results spanning several languages and degradation conditions that demonstrate consistent gains from the time-shifted anechoic target. To make this evidence more explicit for the language-agnostic claim, we will add a dedicated cross-condition ablation table and results on two additional held-out languages in the revised version. If the page limit permits, we will also include a short discussion of how the target choice interacts with each degradation type. revision: partial
Circularity Check
No circularity: empirical target choice and framework rest on external benchmarks
full rationale
The paper's core contributions are empirical: an experimental comparison showing time-shifted anechoic speech outperforms early-reflected speech as a training target, a two-stage architecture guided by an external distortion-perception tradeoff theory, and an analysis of data scale versus quality. No equations, fitted parameters, or predictions are presented that reduce by construction to the inputs (e.g., no self-definitional targets or fitted quantities renamed as predictions). The SOTA result on the URGENT 2025 non-blind set and language-agnostic claims are evaluated against held-out external data rather than derived from self-citations or internal fits. The work is therefore self-contained against benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Distortion-perception tradeoff theory governs the achievable operating points for enhancement models
Reference graph
Works this paper leans on
-
[1]
Nanocodec: Towards high-quality ultra fast speech llm inference
Casanova, E., Neekhara, P., Langman, R., Hussain, S., Ghosh, S., Yang, X., Jukic, A., Li, J., and Ginsburg, B. Nanocodec: Towards high-quality ultra fast speech llm inference. InProc. Interspeech 2025, pp. 5028–5032,
work page 2025
-
[2]
ICASSP 2023 deep noise suppression challenge
Dubey, H., Aazami, A., Gopal, V ., Naderi, B., Braun, S., Cutler, R., Ju, A., Zohourian, M., Tang, M., Golestaneh, M., et al. ICASSP 2023 deep noise suppression challenge. IEEE Open Journal of Signal Processing, 5:725–737,
work page 2023
-
[3]
Goswami, N. and Harada, T. FUSE: Universal speech en- hancement using multi-stage fusion of sparse compres- sion and token generation models for the urgent 2025 challenge. InProc. Interspeech,
work page 2025
-
[4]
Emilia: A large-scale, extensive, multilin- gual, and diverse dataset for speech generation,
He, H., Shang, Z., Wang, C., Li, X., Gu, Y ., Hua, H., Liu, L., Yang, C., Li, J., Shi, P., et al. Emilia: A large-scale, extensive, multilingual, and diverse dataset for speech generation.arXiv preprint arXiv:2501.15907,
-
[5]
Huang, J., Yan, Z., Jiang, W., and Wen, F. A two-stage training framework for joint speech compression and en- hancement.arXiv preprint arXiv:2309.04132,
-
[6]
S., Neekhara, P., Yang, X., Casanova, E., Ghosh, S., Fejgin, R., Desta, M
9 Rethinking Training Targets, Architectures and Data Quality for Universal Speech Enhancement Hussain, S. S., Neekhara, P., Yang, X., Casanova, E., Ghosh, S., Fejgin, R., Desta, M. T., Valle, R., and Li, J. Koel-tts: Enhancing llm based speech generation with preference alignment and classifier free guidance. InProceedings of the 2025 Conference on Empir...
work page 2025
-
[7]
Jensen, J. and Taal, C. H. An algorithm for predicting the intelligibility of speech masked by modulated noise maskers.IEEE/ACM Transactions on Audio, Speech, and Language Process., 24(11):2009–2022,
work page 2009
-
[8]
Miipher-2: A universal speech restoration model for million-hour scale data restoration
Karita, S., Koizumi, Y ., Zen, H., Ishikawa, H., Scheibler, R., and Bacchiani, M. Miipher-2: A universal speech restoration model for million-hour scale data restoration. arXiv preprint arXiv:2505.04457,
-
[9]
Less is more: Data curation matters in scaling speech enhance- ment.arXiv preprint arXiv:2506.23859,
Li, C., Zhang, W., Wang, W., Scheibler, R., Saijo, K., Cor- nell, S., Fu, Y ., Sach, M., Ni, Z., Kumar, A., et al. Less is more: Data curation matters in scaling speech enhance- ment.arXiv preprint arXiv:2506.23859,
-
[10]
V oicefixer: Toward general speech restoration with neural vocoder.arXiv:2109.13731,
Liu, H., Kong, Q., Tian, Q., Zhao, Y ., Wang, D., Huang, C., and Wang, Y . V oiceFixer: Toward general speech restoration with neural vocoder.arXiv preprint arXiv:2109.13731,
-
[11]
MLS: A Large-Scale Multilingual Dataset for Speech Research
Pratap, V ., Xu, Q., Sriram, A., Synnaeve, G., and Collobert, R. MLS: A large-scale multilingual dataset for speech research.arXiv preprint arXiv:2012.03411,
work page internal anchor Pith review arXiv 2012
-
[12]
Rong, X., Wang, D., Hu, Q., Wang, Y ., Hu, Y ., and Lu, J. TS-URGENet: A three-stage universal robust and gen- eralizable speech enhancement network.arXiv preprint arXiv:2505.18533,
-
[13]
Utmos: Utokyo-sarulab system for voicemos challenge 2022
Saeki, T., Xin, D., Nakata, W., Koriyama, T., Takamichi, S., and Saruwatari, H. UTMOS: Utokyo-sarulab sys- tem for V oiceMOS challenge 2022.arXiv preprint arXiv:2204.02152,
-
[14]
Interspeech 2025 URGENT speech enhancement challenge
Saijo, K., Zhang, W., Cornell, S., Scheibler, R., Li, C., Ni, Z., Kumar, A., Sach, M., Fu, Y ., Wang, W., et al. Interspeech 2025 URGENT speech enhancement challenge. InProc. Interspeech, pp. 858–862,
work page 2025
-
[15]
Universal speech enhancement with score-based diffusion.arXiv preprint arXiv:2206.03065,
Serr`a, J., Pascual, S., Pons, J., Araz, R. O., and Scaini, D. Universal speech enhancement with score-based diffu- sion.arXiv preprint arXiv:2206.03065,
-
[16]
Valin, J.-M., Giri, R., Venkataramani, S., Isik, U., and Kr- ishnaswamy, A. To dereverb or not to dereverb? Percep- tual studies on real-time dereverberation targets.arXiv preprint arXiv:2206.07917,
-
[17]
Anyenhance: A unified generative model with prompt-guidance and self-critic for voice enhancement,
Zhang, J., Yang, J., Fang, Z., Wang, Y ., Zhang, Z., Wang, Z., Fan, F., and Wu, Z. AnyEnhance: A unified generative model with prompt-guidance and self-critic for voice enhancement.arXiv preprint arXiv:2501.15417, 2025a. Zhang, W., Saijo, K., Wang, Z.-Q., Watanabe, S., and Qian, Y . Toward universal speech enhancement for diverse input conditions. InIEEE ...
-
[18]
ClearerV oice-Studio: Bridg- ing advanced speech processing research and practical deployment
Zhao, S., Pan, Z., and Ma, B. ClearerV oice-Studio: Bridg- ing advanced speech processing research and practical deployment. InProc. Interspeech 2025, pp. 2980–2984,
work page 2025
-
[19]
perceptual quality, the degree to which the distribution of ˜sis close to that of s. To alleviate the hallucination problem in generative models, our goal is toachieve minimal distortion under a given level of perceptual quality P . Mathematically, we are dealing with the distortion-perception (DP) function (Freirich et al., 2021), D(P) = min p˜s|y {E[d(s...
work page 2021
-
[20]
and (Freirich et al., 2021). 13 Rethinking Training Targets, Architectures and Data Quality for Universal Speech Enhancement Figure 4.An example of a room impulse response, highlighting the time shiftn 0 introduced by the direct path. Table 5.Dataset Composition for URGENT 2025 Challenge Type Corpus Condition Sampling (kHz) Duration (h) Speech LibriV ox (...
work page 2021
-
[21]
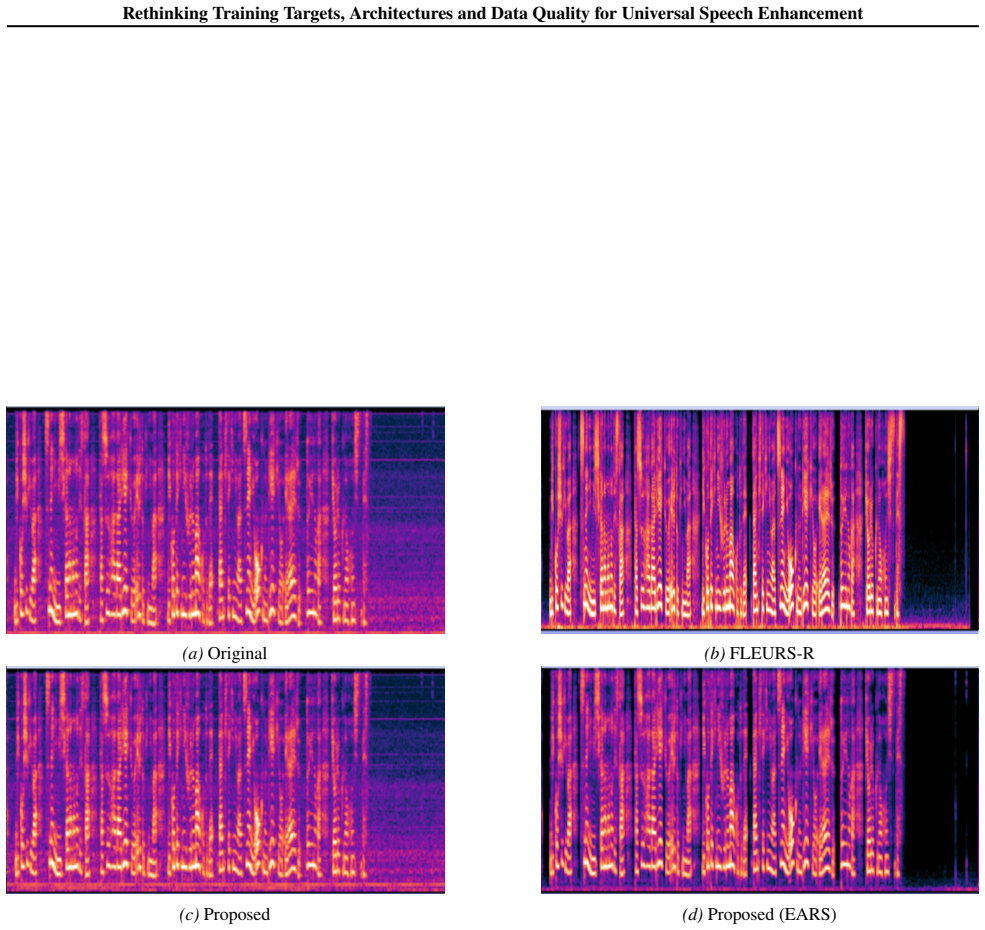
The median of each data source is indicated by a dashed vertical line. 16 Rethinking Training Targets, Architectures and Data Quality for Universal Speech Enhancement (a)Anechoic 1 (b)Early reflected 1 (c)Anechoic 2 (d)Early reflected 2 Figure 8.Enhanced spectrogram comparison between using time-shifted anechoic clean speech and early-reflected speech as ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.