Stochastic Attention: Connectome-Inspired Randomized Routing for Expressive Linear-Time Attention
Pith reviewed 2026-05-13 22:46 UTC · model grok-4.3
The pith
Random permutations turn sliding-window attention into stochastic global connections that reach full sequence coverage in logarithmic depth.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
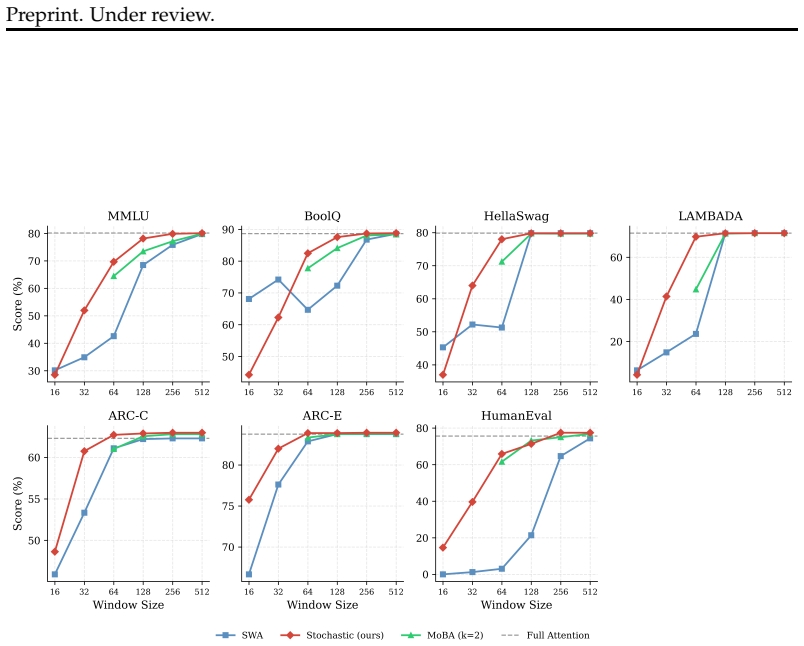
Independently sampled random permutations applied before each sliding-window attention step create stochastic shortcuts that expand receptive fields exponentially with depth. As a result, full sequence coverage is reached in O(log_w n) layers while retaining the O(n w) per-layer cost of sliding-window attention. The construction is motivated by the sparse, broadly distributed long-range connections observed in the fruit-fly connectome that serve as efficient global communication routes.
What carries the argument
Stochastic Attention: a random permutation of the token sequence applied before windowed attention, followed by restoration of the original order; it converts each fixed local window into a stochastic global window within unchanged compute.
If this is right
- Gated combination of Stochastic Attention and sliding-window attention yields the highest average zero-shot accuracy when training language models from scratch.
- At inference time on Qwen3-8B and Qwen3-30B-A3B, Stochastic Attention outperforms sliding-window attention and matches or exceeds Mixture of Block Attention at equal compute.
- Full-sequence receptive fields appear after O(log_w n) layers rather than the O(n/w) layers required by fixed windows.
- The approach functions as a complementary primitive that can be combined with other linear or sparse attention techniques.
Where Pith is reading between the lines
- The same permutation-based routing could be applied inside other sparse or linear attention families to enlarge their effective range without raising asymptotic cost.
- Because the permutations are sampled independently per layer, the mechanism may act as a lightweight form of stochastic regularization during training.
- Longer-context regimes would be the natural regime in which the logarithmic scaling advantage becomes most visible.
Load-bearing premise
Random permutations expand receptive fields without introducing coherence-destroying artifacts that would outweigh the coverage gains on downstream tasks.
What would settle it
Controlled pre-training runs that show no accuracy gain, or a consistent loss, when gated Stochastic Attention is added to sliding-window attention at matched token budget.
Figures







read the original abstract
The whole-brain connectome of a fruit fly comprises over 130K neurons connected with a probability of merely 0.02%, yet achieves an average shortest path of only 4.4 hops. Despite being highly structured at the circuit level, the network's long-range connections are broadly distributed across brain regions, functioning as stochastic shortcuts that enable efficient global communication. Inspired by this observation, we propose Stochastic Attention (SA), a drop-in enhancement for sliding-window attention (SWA) that applies a random permutation to the token sequence before windowed attention and restores the original order afterward. This transforms the fixed local window into a stochastic global one within the same $O(nw)$ per-layer budget. Through depth, independently sampled permutations yield exponentially growing receptive fields, achieving full sequence coverage in $O(\log_w n)$ layers versus $O(n/w)$ for SWA. We validate SA in two settings: pre-training language models from scratch, where a gated SA + SWA combination achieves the best average zero-shot accuracy, and training-free inference on Qwen3-8B and Qwen3-30B-A3B, where SA consistently outperforms SWA and matches or exceeds Mixture of Block Attention at comparable compute budgets. These results suggest that connectome-inspired stochastic routing is a practical primitive for improving the expressivity of efficient attention, complementary to existing linear and sparse approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Stochastic Attention (SA) as a drop-in enhancement to sliding-window attention (SWA). A random permutation is applied to the token sequence before windowed attention, after which the original order is restored; this converts fixed local windows into stochastic global connections at the same O(nw) per-layer cost. Stacking layers with independent permutations produces exponentially growing receptive fields, reaching full sequence coverage in O(log_w n) layers versus O(n/w) for plain SWA. The method is evaluated in two regimes: (i) pre-training language models from scratch, where a gated SA+SWA hybrid obtains the highest average zero-shot accuracy, and (ii) training-free inference on Qwen3-8B and Qwen3-30B-A3B, where SA consistently beats SWA and matches or exceeds Mixture of Block Attention at comparable budgets.
Significance. If the empirical gains prove robust, the work supplies a simple, parameter-free primitive that augments the expressivity of linear-time attention while preserving its complexity. The connectome-inspired stochastic-routing idea is complementary to existing sparse and linear mechanisms, requires no learned parameters, and rests on a transparent graph-theoretic neighborhood-expansion argument. These features make the contribution potentially easy to adopt and worth testing across additional architectures and tasks.
major comments (2)
- [§4.1] §4.1 (pre-training results): the statement that the gated SA+SWA combination achieves the best average zero-shot accuracy is presented without error bars, number of random seeds, or an explicit list of the exact baseline implementations and hyper-parameters used for each comparator; these omissions prevent verification that the reported margin is statistically reliable and attributable to the stochastic-routing mechanism.
- [§3.2] §3.2 (receptive-field argument): while the exponential growth follows from independent random w-regular connections per layer, the manuscript does not supply a concrete bound or Monte-Carlo estimate of the expected coverage fraction after l layers (or the probability of local-coherence degradation), leaving the O(log_w n) claim as an intuitive sketch rather than a quantified guarantee.
minor comments (2)
- [§3] The precise definition of the forward and inverse permutation steps (including how the window indices are mapped) should be stated once in pseudocode or as a short algorithm box for reproducibility.
- [Figure 2] Figure 2 (or the receptive-field visualization) would be clearer if it overlaid the theoretical coverage curve for several window sizes w alongside the empirical measurements.
Simulated Author's Rebuttal
We thank the referee for the positive recommendation of minor revision and for the constructive comments, which help strengthen the presentation of our results. We address each major comment below and will incorporate the requested clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [§4.1] §4.1 (pre-training results): the statement that the gated SA+SWA combination achieves the best average zero-shot accuracy is presented without error bars, number of random seeds, or an explicit list of the exact baseline implementations and hyper-parameters used for each comparator; these omissions prevent verification that the reported margin is statistically reliable and attributable to the stochastic-routing mechanism.
Authors: We agree that reporting error bars, seed counts, and explicit baseline details is necessary for verifying statistical reliability. In the revised manuscript we will add results averaged over three independent random seeds with standard deviations shown as error bars. We will also include a new appendix table that lists the precise hyper-parameters, model sizes, training steps, and implementation details for every baseline and comparator, ensuring full reproducibility of the reported margins. revision: yes
-
Referee: [§3.2] §3.2 (receptive-field argument): while the exponential growth follows from independent random w-regular connections per layer, the manuscript does not supply a concrete bound or Monte-Carlo estimate of the expected coverage fraction after l layers (or the probability of local-coherence degradation), leaving the O(log_w n) claim as an intuitive sketch rather than a quantified guarantee.
Authors: We acknowledge that the receptive-field analysis would benefit from quantitative support. In the revision we will add a new subsection containing Monte-Carlo simulations that estimate the expected coverage fraction after l layers for representative values of w and n. These simulations will also report the probability of achieving full coverage and any observed degradation in local token coherence, thereby converting the O(log_w n) claim into a quantified statement with empirical bounds. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines Stochastic Attention procedurally via random permutations applied to sliding-window attention, with the exponential receptive-field growth following directly from independent per-layer sampling and standard neighborhood expansion in random w-regular graphs. This is a self-contained combinatorial argument that does not reduce to fitted parameters, self-referential equations, or load-bearing self-citations. Performance claims rest on external pre-training and inference experiments rather than internal derivations that presuppose the result.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math A random permutation of the token sequence followed by windowed attention and inverse permutation can be computed in the same O(n w) time as standard sliding-window attention.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Through depth, independently sampled permutations yield exponentially growing receptive fields, achieving full sequence coverage in O(log_w n) layers versus O(n/w) for SWA.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The gated SA + SWA combination reproduces the connectome’s small-world regime: structured local clustering from SWA and distributed long-range shortcuts from SA.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
u rner, Tomke and Demarest, Damian and G \
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.