People-Centred Medical Image Analysis
Pith reviewed 2026-05-07 16:30 UTC · model grok-4.3
The pith
PecMan uses a dynamic gating mechanism to jointly optimize fairness, accuracy, and clinician workload in medical image analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
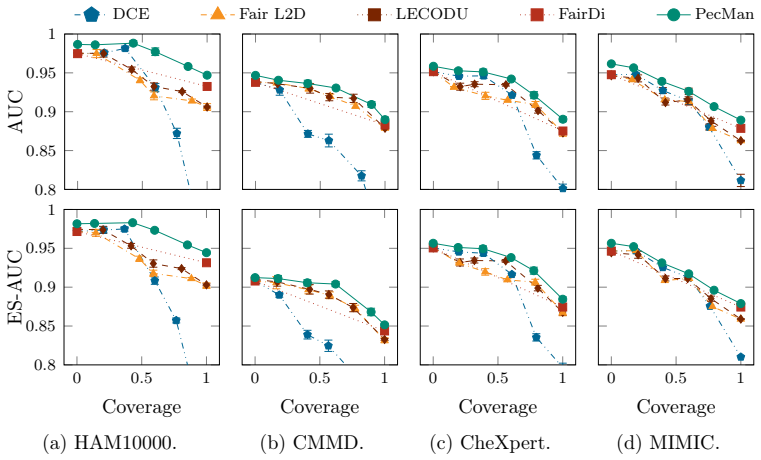
The central discovery is that a people-centred approach to medical image analysis, implemented via PecMan's dynamic gating that routes cases to AI, human clinicians, or joint review while respecting workload limits, achieves better combined performance on accuracy, fairness across diverse populations, and workflow integration than prior separate solutions.
What carries the argument
The dynamic gating mechanism within PecMan, which assigns each medical image case to AI alone, clinician alone, or both, subject to overall clinician availability constraints, while pursuing joint optimization of diagnostic accuracy and fairness.
If this is right
- Performance biases that hinder regulatory approval can be mitigated by explicit fairness optimization.
- Clinician adoption increases when AI does not disrupt established workflows or overload staff.
- Trade-offs between the three goals can be quantified and managed using the FairHAI benchmark.
- The framework demonstrates consistent gains over methods optimizing only subsets of these objectives.
Where Pith is reading between the lines
- Applying similar gating logic could help in other high-stakes domains with scarce expert time.
- Real-world deployment might require adapting the workload model to specific hospital schedules and team structures.
- The benchmark provides a template for testing other human-AI systems on fairness and integration metrics simultaneously.
Load-bearing premise
The assumption that clinician availability can be modeled as a simple dynamic constraint that captures real clinical settings without overlooking workflow disruptions or introducing new barriers.
What would settle it
If a study in an actual clinic finds that using PecMan results in lower overall diagnostic quality or higher clinician burnout than using separate fairness and deferral tools, the joint optimization benefit would be falsified.
Figures







read the original abstract
Recent advances in data-centric medical AI have produced highly accurate diagnostic systems, but the emphasis on data curation and performance metrics has not translated into widespread clinical adoption. We conjecture that this limited uptake stems from insufficient attention dedicated to the optimisation of fair performance across diverse patient populations and to workflow integration: performance biases can create regulatory barriers, and poorly integrated automation can disrupt clinical routines, degrade the quality of human-AI collaboration, and reduce clinicians' willingness to adopt AI tools. Prior work on workflow integration (e.g., Learning to Defer (L2D) and Learning to Complement (L2C)) and AI fairness has typically examined these challenges in isolation, overlooking their natural interdependence and the practical constraints of clinical environments, such as restricted clinician availability. We propose People-Centred Medical Image Analysis (PecMan), a human-AI framework that jointly optimises fairness, diagnostic accuracy, and workflow effectiveness through a dynamic gating mechanism that assigns cases to AI, clinicians, or both under clinician workload constraints. We also introduce the Fairness and Human-Centred AI (FairHAI) benchmark for evaluating trade-offs between accuracy, fairness, and clinician workload. Experiments using this benchmark show that PecMan consistently outperforms existing methods, paving the way for more trustworthy and clinically viable AI systems. Code will be available upon paper acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes People-Centred Medical Image Analysis (PecMan), a human-AI framework that jointly optimizes fairness, diagnostic accuracy, and workflow effectiveness through a dynamic gating mechanism that assigns cases to AI, clinicians, or both under clinician workload constraints. It introduces the FairHAI benchmark for evaluating trade-offs between accuracy, fairness, and clinician workload, and reports that experiments show PecMan consistently outperforms existing methods.
Significance. If the results hold and the modeled constraints align with real clinical environments, this work would be significant in advancing clinically viable medical AI by addressing the interdependence of fairness and workflow integration, areas previously studied in isolation. The FairHAI benchmark could serve as a useful tool for future research in human-centred AI.
major comments (1)
- The central claim that PecMan outperforms baselines on FairHAI depends on the dynamic gating jointly optimizing under a modeled clinician availability constraint. However, this treats availability as a clean resource allocation problem, while real clinical settings introduce unmodeled factors including communication costs, decision latency, EHR integration friction, and variable case complexity that could invert the trade-offs. Without validation that the synthetic constraint matches observed clinical logs, the outperformance does not establish clinical viability.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript. We address the major concern point by point below, acknowledging the limitations of our modeled constraints while clarifying the scope of our claims.
read point-by-point responses
-
Referee: The central claim that PecMan outperforms baselines on FairHAI depends on the dynamic gating jointly optimizing under a modeled clinician availability constraint. However, this treats availability as a clean resource allocation problem, while real clinical settings introduce unmodeled factors including communication costs, decision latency, EHR integration friction, and variable case complexity that could invert the trade-offs. Without validation that the synthetic constraint matches observed clinical logs, the outperformance does not establish clinical viability.
Authors: We agree that the clinician availability constraint in PecMan and FairHAI is modeled as a simplified resource allocation problem and does not incorporate additional real-world factors such as communication costs, decision latency, EHR integration friction, and variable case complexity. The FairHAI benchmark is a controlled, synthetic environment intended to isolate and evaluate the effects of joint optimization of fairness, accuracy, and workflow under workload constraints. Our central claim is limited to outperformance within this benchmark; we do not assert that the results establish clinical viability. In the revised manuscript, we will expand the limitations and discussion sections to explicitly address these unmodeled factors, analyze how they could alter the observed trade-offs, and propose directions for empirical validation against clinical logs and real workflow data. revision: yes
Circularity Check
No circularity in derivation chain; framework and benchmark are independently proposed
full rationale
The paper introduces PecMan as a joint optimization framework via dynamic gating under workload constraints and the FairHAI benchmark, with performance claims resting on experimental comparisons rather than any closed-form derivation, fitted parameter renamed as prediction, or self-referential definition. No equations, ansatzes, or uniqueness theorems are presented in the provided text that reduce to inputs by construction. Prior work on L2D/L2C is cited externally without self-citation load-bearing the central claim. The derivation chain is self-contained as a proposal validated by new experiments.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. Li, Y. Jiang, Y. Zhang, H. Zhu, Medical image analysis using deep learning algorithms, Frontiers in Public Health 11 (2023) 1273253
work page 2023
-
[2]
T. R. C. of Radiologists, Clinical radiology workforce census 2023, Tech. rep., The Royal College of Radiologists (2023). 21
work page 2023
-
[3]
E. J. Topol, High-performance medicine: The convergence of human and artificial intelligence, Nature medicine 25 (1) (2019) 44–56
work page 2019
-
[4]
M. M. Abuzaid, W. Elshami, H. Tekin, B. Issa, Assessment of the will- ingness of radiologists and radiographers to accept the integration of artificial intelligence into radiology practice, Academic Radiology 29 (1) (2022) 87–94
work page 2022
-
[5]
A. Derevianko, S. F. M. Pizzoli, F. Pesapane, A. Rotili, D. Monzani, R. Grasso, E. Cassano, G. Pravettoni, The use of artificial intelligence (ai) in the radiology field: What is the state of doctor–patient commu- nication in cancer diagnosis?, Cancers 15 (2) (2023) 470
work page 2023
- [6]
- [7]
-
[8]
E. Kumah, Artificial intelligence in healthcare and its implications for patient centered care, Discover Public Health 22 (1) (2025) 524
work page 2025
-
[9]
S. S. Jain, S. Goto, J. L. Hall, S. S. Khan, C. A. MacRae, C. Ofori, C. Pegus, M. Pencina, E. D. Peterson, L. H. Schwamm, et al., Pragmatic approaches to the evaluation and monitoring of artificial intelligence in health care: A science advisory from the american heart association, Circulation 152 (23) (2025) e433–e442
work page 2025
-
[10]
E. U. Alum, O. P.-C. Ugwu, Artificial intelligence in personalized medicine: transforming diagnosis and treatment, Discover Applied Sci- ences 7 (3) (2025) 193
work page 2025
-
[11]
L. A. Celi, J. Cellini, M.-L. Charpignon, E. C. Dee, F. Dernoncourt, R. Eber, W. G. Mitchell, L. Moukheiber, J. Schirmer, J. Situ, et al., Sources of bias in artificial intelligence that perpetuate healthcare dis- parities - a global review, PLOS Digital Health 1 (3) (2022) e0000022. 22
work page 2022
-
[12]
L. Oakden-Rayner, J. Dunnmon, G. Carneiro, C. Ré, Hidden stratifica- tion causes clinically meaningful failures in machine learning for medical imaging, in: ACM CHIL, 2020, pp. 151–159
work page 2020
-
[13]
M. A. Ricci Lara, R. Echeveste, E. Ferrante, Addressing fairness in artificialintelligenceformedicalimaging, NatureCommunications13(1) (2022) 4581
work page 2022
- [14]
- [15]
-
[16]
Y. Zong, Y. Yang, T. Hospedales, MEDFAIR: Benchmarking fairness for medical imaging, in: ICLR, 2023
work page 2023
-
[17]
T. Iqbal, M. Masud, B. Amin, C. Feely, M. Faherty, T. Jones, M. Tier- ney, A. Shahzad, P. Vazquez, Towards integration of artificial intelli- gence into medical devices as a real-time recommender system for per- sonalised healthcare: State-of-the-art and future prospects, Health Sci- ences Review (2024)
work page 2024
-
[18]
N. Quadrianto, V. Sharmanska, O. Thomas, Discovering fair represen- tations in the data domain, in: CVPR, 2019, pp. 8227–8236
work page 2019
- [19]
-
[20]
V. V. Ramaswamy, S. S. Kim, O. Russakovsky, Fair attribute classifica- tion through latent space de-biasing, in: CVPR, 2021, pp. 9301–9310
work page 2021
-
[21]
S. Park, J. Lee, P. Lee, S. Hwang, D. Kim, H. Byun, Fair contrastive learning for facial attribute classification, in: CVPR, 2022, pp. 10389– 10398
work page 2022
-
[22]
Y. Roh, K. Lee, S. Whang, C. Suh, Fr-train: A mutual information- based approach to fair and robust training, in: ICML, PMLR, 2020, pp. 8147–8157. 23
work page 2020
-
[23]
M. B. Zafar, I. Valera, M. G. Rogriguez, K. P. Gummadi, Fairness con- straints: Mechanisms for fair classification, in: AISTATS, PMLR, 2017, pp. 962–970
work page 2017
-
[24]
B. H. Zhang, B. Lemoine, M. Mitchell, Mitigating unwanted biases with adversarial learning, in: AIES, 2018, pp. 335–340
work page 2018
-
[25]
Z. Wang, X. Dong, H. Xue, Z. Zhang, W. Chiu, T. Wei, K. Ren, Fairness-aware adversarial perturbation towards bias mitigation for de- ployed deep models, in: CVPR, 2022, pp. 10379–10388
work page 2022
-
[26]
M. P. Kim, A. Ghorbani, J. Zou, Multiaccuracy: Black-box post- processing for fairness in classification, in: AIES, 2019, pp. 247–254
work page 2019
-
[27]
J. Herington, M. D. McCradden, K. Creel, R. Boellaard, E. C. Jones, A. K. Jha, A. Rahmim, P. J. Scott, J. J. Sunderland, R. L. Wahl, et al., Ethical considerations for artificial intelligence in medical imaging: de- ployment and governance, Journal of Nuclear Medicine 64 (10) (2023) 1509–1515
work page 2023
-
[28]
Z. Obermeyer, B. Powers, C. Vogeli, S. Mullainathan, Dissecting racial bias in an algorithm used to manage the health of populations, Science 366 (6464) (2019)
work page 2019
-
[29]
A. J. Larrazabal, N. Nieto, V. Peterson, D. H. Milone, E. Ferrante, Gen- der imbalance in medical imaging datasets produces biased classifiers for computer-aided diagnosis, National Academy of Sciences 117 (23) (2020) 12592–12594
work page 2020
-
[30]
V. C. Nitesh, SMOTE: Synthetic minority over-sampling technique, Journal of Artificial Intelligence Research 16 (1) (2002) 321
work page 2002
- [31]
-
[32]
B. Kim, H. Kim, K. Kim, S. Kim, J. Kim, Learning not to learn: Train- ing deep neural networks with biased data, in: CVPR, 2019, pp. 9012– 9020
work page 2019
- [33]
- [34]
- [35]
-
[36]
J. Cha, S. Chun, K. Lee, H.-C. Cho, S. Park, Y. Lee, S. Park, Swad: Domain generalization by seeking flat minima, in: NeurIPS, Vol. 34, 2021, pp. 22405–22418
work page 2021
-
[37]
E. Tartaglione, C. A. Barbano, M. Grangetto, End: Entangling and disentangling deep representations for bias correction, in: CVPR, 2021, pp. 13508–13517
work page 2021
-
[38]
M. H. Sarhan, N. Navab, A. Eslami, S. Albarqouni, Fairness by learning orthogonal disentangled representations, in: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXIX 16, Springer, 2020, pp. 746–761
work page 2020
-
[39]
Y. Tian, M. Shi, Y. Luo, A. Kouhana, T. Elze, M. Wang, Fairseg: A large-scale medical image segmentation dataset for fairness learning us- ing segment anything model with fair error-bound scaling, in: ICLR, 2024
work page 2024
-
[40]
Y. Luo, M. Shi, M. O. Khan, M. M. Afzal, H. Huang, S. Yuan, Y. Tian, L. Song, A. Kouhana, T. Elze, et al., FairCLIP: Harnessing fairness in vision-language learning, in: CVPR, 2024, pp. 12289–12301
work page 2024
-
[42]
A. Rosenfeld, M. D. Solbach, J. K. Tsotsos, Totally looks like-how hu- mans compare, compared to machines, in: IEEE Conf. Comput. Vis. Pattern Recog. Worksh., 2018, pp. 1961–1964
work page 2018
-
[43]
T. Serre, Deep learning: the good, the bad, and the ugly, Annual Review of Vision Science 5 (2019) 399–426. 25
work page 2019
- [44]
-
[45]
E. K. Chiou, J. D. Lee, Trusting automation: Designing for responsivity and resilience, Human Factors 65 (1) (2023) 137–165
work page 2023
-
[46]
Z. Lu, M. Yin, Human reliance on machine learning models when per- formance feedback is limited: Heuristics and risks, in: CHI Conference on Human Factors in Computing Systems, 2021, pp. 1–16
work page 2021
-
[47]
M. Yin, J. Wortman Vaughan, H. Wallach, Understanding the effect of accuracy on trust in machine learning models, in: CHI Conference on Human Factors in Computing Systems, 2019, pp. 1–12
work page 2019
-
[48]
D. Shin, The effects of explainability and causability on perception, trust, and acceptance: Implications for explainable AI, International Journal of Human-Computer Studies 146 (2021) 102551
work page 2021
-
[49]
K. Weitz, D. Schiller, R. Schlagowski, T. Huber, E. André, "do you trust me?" increasing user-trust by integrating virtual agents in explainable ai interaction design, in: ACM International Conference on Intelligent Virtual Agents, 2019, pp. 7–9
work page 2019
- [50]
-
[51]
N. Agarwal, A. Moehring, P. Rajpurkar, T. Salz, Combining human ex- pertise with artificial intelligence: experimental evidence from radiology, Tech. rep., National Bureau of Economic Research (2023)
work page 2023
-
[52]
K. Vodrahalli, R. Daneshjou, T. Gerstenberg, J. Zou, Do humans trust advice more if it comes from ai? an analysis of human-AI interactions, in: AIES, 2022, pp. 763–777
work page 2022
-
[53]
X. Wu, L. Xiao, Y. Sun, J. Zhang, T. Ma, L. He, A survey of human- in-the-loop for machine learning, Future Generation Computer Systems 135 (C) (2022) 364–381.doi:10.1016/j.future.2022.05.014. URLhttps://doi.org/10.1016/j.future.2022.05.014 26
-
[54]
V. Keswani, M. Lease, K. Kenthapadi, Towards unbiased and accurate deferral to multiple experts, in: AIES, 2021, pp. 154–165
work page 2021
-
[55]
H. Narasimhan, W. Jitkrittum, A. K. Menon, A. Rawat, S. Kumar, Post-hoc estimators for learning to defer to an expert, in: NeurIPS, Vol. 35, 2022
work page 2022
-
[56]
A. Mao, C. Mohri, M. Mohri, Y. Zhong, Two-stage learning to defer with multiple experts, in: NeurIPS, 2023
work page 2023
- [57]
- [58]
-
[59]
N. Charoenphakdee, Z. Cui, Y. Zhang, M. Sugiyama, Classification with rejection based on cost-sensitive classification, in: ICML, PMLR, 2021, pp. 1507–1517
work page 2021
- [60]
- [61]
-
[62]
H. Mozannar, D. Sontag, Consistent estimators for learning to defer to an expert, in: ICML, PMLR, 2020, pp. 7076–7087
work page 2020
- [63]
-
[64]
H. Mozannar, H. Lang, D. Wei, P. Sattigeri, S. Das, D. Sontag, Who should predict? Exact algorithms for learning to defer to humans, in: AISTATS, PMLR, 2023, pp. 10520–10545
work page 2023
-
[65]
M.-A. Charusaie, H. Mozannar, D. Sontag, S. Samadi, Sample efficient learningofpredictorsthatcomplementhumans, in: ICML,PMLR,2022, pp. 2972–3005. 27
work page 2022
-
[66]
Y. Cao, H. Mozannar, L. Feng, H. Wei, B. An, In defense of soft- max parametrization for calibrated and consistent learning to defer, in: NeurIPS, Vol. 36, 2024
work page 2024
-
[67]
E. Straitouri, L. Wang, N. Okati, M. G. Rodriguez, Improving expert predictions with conformal prediction, in: ICML, PMLR, 2023, pp. 32633–32653
work page 2023
-
[68]
S. Liu, Y. Cao, Q. Zhang, L. Feng, B. An, Mitigating underfitting in learning to defer with consistent losses, in: AISTATS, 2024
work page 2024
-
[69]
H. Mozannar, A. Satyanarayan, D. Sontag, Teaching humans when to defer to a classifier via exemplars, in: AAAI Conference on Artificial Intelligence, Vol. 36, 2022, pp. 5323–5331
work page 2022
- [70]
- [71]
- [72]
-
[73]
A. Mao, M. Mohri, Y. Zhong, Principled approaches for learning to defer with multiple experts, in: International Symposium on Artificial Intelligence and Mathematics, 2024
work page 2024
- [74]
- [75]
- [76]
-
[77]
M. Steyvers, H. Tejeda, G. Kerrigan, P. Smyth, Bayesian modeling of human–AI complementarity, National Academy of Sciences 119 (11) (2022) e2111547119
work page 2022
-
[78]
G. Kerrigan, P. Smyth, M. Steyvers, Combining human predictions with model probabilities via confusion matrices and calibration, in: NeurIPS, Vol. 34, 2021, pp. 4421–4434
work page 2021
- [79]
-
[80]
P. Hemmer, S. Schellhammer, M. Vössing, J. Jakubik, G. Satzger, Forming effective human-AI teams: Building machine learning models that complement the capabilities of multiple experts, in: L. D. Raedt (Ed.), International Joint Conference on Artificial Intelligence, Interna- tional Joint Conferences on Artificial Intelligence Organization, 2022, pp. 2478–...
- [81]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.