HDFlow: Hierarchical Diffusion-Flow Planning for Long-horizon Tasks
Pith reviewed 2026-05-20 23:33 UTC · model grok-4.3
The pith
HDFlow uses high-level diffusion for subgoals and low-level rectified flow for trajectories to plan long-horizon robot tasks more effectively.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
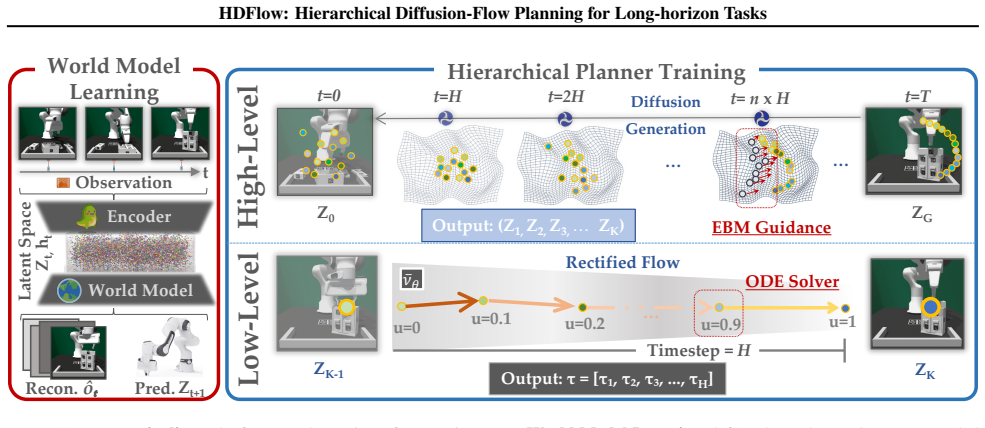
HDFlow is a novel hierarchical planning framework that employs a high-level diffusion planner to generate sequences of strategic subgoals in a learned latent space, capitalizing on diffusion's exploratory capabilities, and these subgoals then guide a low-level rectified flow planner that generates smooth and dense trajectories by exploiting the efficiency of ordinary differential equation-based trajectory generation.
What carries the argument
The two-level hierarchy in which high-level diffusion produces subgoal sequences in latent space to steer low-level rectified flow for dense trajectory generation.
If this is right
- The method achieves significant outperformance over state-of-the-art planners on four challenging furniture assembly tasks in both simulation and real-world settings.
- HDFlow generalizes to two long-horizon benchmarks that include diverse locomotion and manipulation tasks.
- Using ODE-based generation at the low level reduces the computational cost of iterative denoising and supports more real-time execution.
- The hierarchical decomposition supplies a principled way to handle sparse-reward long-horizon tasks that single-level generative planners struggle with.
Where Pith is reading between the lines
- Adding intermediate levels between the current high- and low-level planners could further extend the approach to tasks with even longer horizons.
- The learned latent space for subgoals may support transfer of plans across different robot embodiments or task distributions.
- Explicit mechanisms for detecting when a subgoal cannot be reached and replanning at the high level would strengthen robustness in noisy real-world settings.
Load-bearing premise
Subgoals generated by the high-level diffusion planner will reliably guide the low-level rectified flow planner to produce successful trajectories without any explicit translation mechanism or failure recovery.
What would settle it
If the low-level rectified flow planner routinely produces invalid or unsuccessful trajectories when conditioned on the high-level subgoals, or if HDFlow fails to outperform state-of-the-art methods on the furniture assembly tasks, the central claim would be falsified.
Figures















read the original abstract
Recent advances in generative models have shown promise in generating behavior plans for long-horizon, sparse reward tasks. While these approaches have achieved promising results, they often lack a principled framework for hierarchical decomposition and struggle with the computational demands of real-time execution, due to their iterative denoising process. In this work, we introduce Hierarchical Diffusion-Flow (HDFlow), a novel hierarchical planning framework that optimally leverages the strengths of diffusion and rectified flow models to overcome the limitations of single-paradigm generative planners. HDFlow employs a high-level diffusion planner to generate sequences of strategic subgoals in a learned latent space, capitalizing on diffusion's powerful exploratory capabilities. These subgoals then guide a low-level rectified flow planner that generates smooth and dense trajectories, exploiting the speed and efficiency of ordinary differential equation (ODE)-based trajectory generation. We evaluate HDFlow on four challenging furniture assembly tasks in both simulation and real-world, where it significantly outperforms state-of-the-art methods. Furthermore, we also showcase our method's generalizability on two long-horizon benchmarks comprising diverse locomotion and manipulation tasks. Project website: https://hdflow-page.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Hierarchical Diffusion-Flow (HDFlow), a hierarchical planning framework for long-horizon robotic tasks. A high-level diffusion model generates sequences of subgoals in a learned latent space to leverage exploratory capabilities, while a low-level rectified flow model uses ODE-based generation to produce smooth dense trajectories. The authors claim significant outperformance over state-of-the-art methods on four furniture assembly tasks in both simulation and real-world settings, plus generalizability on two long-horizon benchmarks involving locomotion and manipulation.
Significance. If the empirical results and hierarchical interface hold under scrutiny, HDFlow would demonstrate a practical way to combine diffusion's strength in subgoal exploration with rectified flow's efficiency for trajectory generation, addressing computational bottlenecks in real-time long-horizon planning. This could advance hierarchical generative planning in robotics by providing a principled decomposition rather than monolithic models.
major comments (2)
- [Abstract] Abstract: the central claim that HDFlow 'significantly outperforms state-of-the-art methods' on four furniture assembly tasks supplies no quantitative metrics, success rates, baseline comparisons, or statistical details. This absence directly undermines evaluation of the data-to-claim link for the primary empirical contribution.
- [Method section] Method section (hierarchical planner description): the mechanism by which latent-space subgoals from the high-level diffusion planner condition or are translated into inputs for the low-level rectified flow planner's ODE solver is not specified. No decoding step, conditioning variable, projection, or recovery policy is described, which is load-bearing for whether the hierarchical decomposition itself drives the reported successes rather than task-specific tuning.
minor comments (1)
- [Abstract] The abstract and introduction could more explicitly reference the project website for supplementary videos or code to aid reproducibility assessment.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment point by point below, indicating the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that HDFlow 'significantly outperforms state-of-the-art methods' on four furniture assembly tasks supplies no quantitative metrics, success rates, baseline comparisons, or statistical details. This absence directly undermines evaluation of the data-to-claim link for the primary empirical contribution.
Authors: We agree that the abstract would be strengthened by including specific quantitative metrics to support the performance claims. In the revised version, we will update the abstract to report key success rates (e.g., average success rate across the four tasks) along with direct comparisons to the strongest baselines and note the statistical significance of the improvements, while preserving the abstract's brevity. revision: yes
-
Referee: [Method section] Method section (hierarchical planner description): the mechanism by which latent-space subgoals from the high-level diffusion planner condition or are translated into inputs for the low-level rectified flow planner's ODE solver is not specified. No decoding step, conditioning variable, projection, or recovery policy is described, which is load-bearing for whether the hierarchical decomposition itself drives the reported successes rather than task-specific tuning.
Authors: We acknowledge that the interface between the high-level diffusion planner and the low-level rectified flow planner requires a more explicit and self-contained description. We will add a dedicated paragraph and accompanying equations in the Method section that detail the decoding of latent subgoals into state-space targets, the exact conditioning variables passed to the ODE solver, and the projection step used to initialize the trajectory generation. This revision will make clear how the hierarchical structure contributes to the overall performance. revision: yes
Circularity Check
No circularity; empirical claims rest on external task evaluations
full rationale
The paper presents HDFlow as a hierarchical planner that uses a high-level diffusion model to produce latent subgoals which then condition a low-level rectified-flow ODE solver. All performance claims are grounded in reported results on four furniture-assembly tasks (sim and real) plus two long-horizon locomotion/manipulation benchmarks. No equations, fitted parameters, or first-principles derivations appear in the supplied text; the central argument is therefore an empirical comparison rather than a self-referential reduction of outputs to inputs. The subgoal-to-trajectory interface is described at a high level but is not asserted as a mathematical identity or prediction derived from the same data used to train the models. Consequently the derivation chain does not collapse by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
HDFlow employs a high-level diffusion planner to generate sequences of strategic subgoals in a learned latent space... low-level rectified flow planner that generates smooth and dense trajectories, exploiting the speed and efficiency of ordinary differential equation (ODE)-based trajectory generation.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce an Energy-Based Model (EBM) to provide explicit guidance... manifold-aware process
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ankile, L., Simeonov, A., Shenfeld, I., and Agrawal, P
URL https://openreview.net/forum?id= li7qeBbCR1t. Ankile, L., Simeonov, A., Shenfeld, I., and Agrawal, P. Juicer: Data-efficient imitation learning for robotic as- sembly. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 5096–5103. IEEE, 2024a. Ankile, L., Simeonov, A., Shenfeld, I., Torne, M., and Agrawal, P. From im...
-
[2]
URL https://api.semanticscholar.org/ CorpusID:270440444. Grathwohl, W., Wang, K.-C., Jacobsen, J.-H., Duvenaud, D., and Zemel, R. Learning the stein discrepancy for training and evaluating energy-based models without sampling. InInternational Conference on Machine Learning, pp. 3732–3747. PMLR, 2020. Gupta, A., Yu, L., Sohn, K., Gu, X., Hahn, M., Li, F.- ...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[3]
Mastering Diverse Domains through World Models
URL https://openreview.net/forum?id= S1lOTC4tDS. Hafner, D., Lee, K.-H., Fischer, I., and Abbeel, P. Deep hierarchical planning from pixels. In Oh, A. H., Agarwal, A., Belgrave, D., and Cho, K. (eds.),Advances in Neural Information Processing Systems, 2022. URL https: //openreview.net/forum?id=wZk69kjy9_d. Hafner, D., Pasukonis, J., Ba, J., and Lillicrap,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Hao, C., Xiao, A., Xue, Z., and Soh, H
URL https://openreview.net/forum?id= IrM64DGB21. Hao, C., Xiao, A., Xue, Z., and Soh, H. Chd: Coupled hier- archical diffusion for long-horizon tasks.arXiv preprint arXiv:2505.07261, 2025. He, K., Chen, X., Xie, S., Li, Y ., Dollár, P., and Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF conference on computer...
-
[5]
Janner, M., Du, Y ., Tenenbaum, J., and Levine, S
doi: 10.1109/LRA.2020.2974707. Janner, M., Du, Y ., Tenenbaum, J., and Levine, S. Planning with diffusion for flexible behavior synthesis. InInterna- tional Conference on Machine Learning, pp. 9902–9915. PMLR, 2022. Kaelbling, L. P. and Lozano-Pérez, T. Hierarchical task and motion planning in the now. In2011 IEEE international conference on robotics and ...
-
[6]
Flow Matching for Generative Modeling
URL https://openreview.net/forum?id= EHG5Iv1mmb. Lee, Y ., Hu, E. S., and Lim, J. J. Ikea furniture assembly en- vironment for long-horizon complex manipulation tasks. In2021 ieee international conference on robotics and au- tomation (icra), pp. 6343–6349. IEEE, 2021. Li, W., Wang, X., Jin, B., and Zha, H. Hierarchical diffusion for offline decision makin...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/cvpr46437.2021 2021
-
[7]
URL https://openreview.net/forum?id= XMOaOigOQo. 12 HDFlow: Hierarchical Diffusion-Flow Planning for Long-horizon Tasks Shridhar, M., Manuelli, L., and Fox, D. Perceiver-actor: A multi-task transformer for robotic manipulation. In Liu, K., Kulic, D., and Ichnowski, J. (eds.),Proceedings of The 6th Conference on Robot Learning, volume 205 of Proceedings of...
work page 2023
-
[8]
URL https://openreview.net/forum?id= PxTIG12RRHS. Suárez-Ruiz, F. and Pham, Q.-C. A framework for fine robotic assembly. In2016 IEEE international conference on robotics and automation (ICRA), pp. 421–426. IEEE, 2016. Wang, F. and Liu, H. Understanding the behaviour of con- trastive loss. InProceedings of the IEEE/CVF conference on computer vision and pat...
work page 2016
-
[9]
Forward Process and Conditional Score.The forward diffusion process defines how a clean latent state z0 is noised toz ℓ at timestepℓ: zℓ = √¯αℓz0 + √ 1−¯αℓϵ, ϵ∼ N(0,I) From this, the conditional distribution q(z0|zℓ) can be expressed as a Gaussian with mean µ(zℓ, ℓ) = 1√¯αℓ (zℓ −√1−¯αℓϵ) and variance Σ(ℓ) = (1−¯αℓ)I. The gradient of the log-probability of...
-
[10]
True Optimal Energy Guidance.The true optimal energy guidance, ∇zℓ Etrue(zℓ|c), aims to steer the diffusion process towards regions of low energy (high success probability) in the z0 space. This gradient is given by the expectation of the score of q(z0|zℓ) weighted by the exponential of the negative energy function, effectively performing importance sampl...
-
[11]
Learned EBM Guidance.Our learned EBM guidance, ∇zℓ Eϕ(zℓ|c), typically approximates the gradient of the energy function at zℓ. In many practical implementations, this effectively corresponds to a linear weighting of the score of q(z0|zℓ)by the energy function itself, rather than its exponential: ∇zℓ Eϕ(zℓ|c)≈E q(z0|zℓ)[E(z0|c)∇zℓ logq(z 0|zℓ)] =− 1√1−¯αℓ ...
-
[12]
Analysis of the Guidance Gap.The EBM guidance gap is defined as ∆EBM(zℓ) =∥∇ zℓ Etrue(zℓ|c)− ∇ zℓ Eϕ(zℓ|c)∥2. Substituting the expressions, we get: ∆EBM(zℓ) = − 1√1−¯αℓ Eq(z0|zℓ)[ϵ|e−E(z0|c)]−E q(z0|zℓ)[E(z0|c)ϵ] 2 14 HDFlow: Hierarchical Diffusion-Flow Planning for Long-horizon Tasks Let δ(z0) = e−E(z0 |c) Eq(z0 |zℓ )[e−E(z0 |c)] −E(z 0|c) represent the ...
-
[13]
The guided sampling step samples from p(y= 1|z, c)p(z|c) , implementing the unconstrained Bayesian posterior. This is achieved by combining classifier-free guidance for the conditional termp(z|c) and EBM guidance for the success termp(y= 1|z, c), as detailed in Proof A.3
-
[14]
The projection step enforces the manifold constraint z∈ M by mapping to the closest point on the approximated manifold. By the principle of alternating projections and the contraction property of projection operators, this two-step process converges to a point that balances optimality (high success probability) with feasibility (remaining on the manifold)...
work page 2025
-
[15]
Lack of Temporal Dynamics: DINOv2, while excellent for static visual representation, does not inherently capture temporal dynamics. The RSSM is crucial for learning a recurrent state that summarizes the history of observations and predicts future states, which is vital for long-horizon planning
-
[16]
Unstructured Latent Space:While DINOv2 provides semantically rich visual features, its latent space is not explicitly structured for planning in terms of task progress or action relevance. The RSSM, especially with the contrastive and IDM objectives, is specifically designed to create a latent space that is optimized for downstream planning
-
[17]
Dimensionality and Noise:Raw DINOv2 features might be higher dimensional or contain more irrelevant noise for planning compared to the compressed and refined latent states learned by the RSSM. The RSSM acts as a bottleneck and a learning mechanism to extract the most pertinent information for control. In conclusion, while DINOv2 serves as an excellent vis...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.