Statistical Significance Revisited
Pith reviewed 2026-05-08 03:06 UTC · model grok-4.3
The pith
Reform proposals for statistical significance testing each carry identifiable strengths and shortcomings that warrant balanced review.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
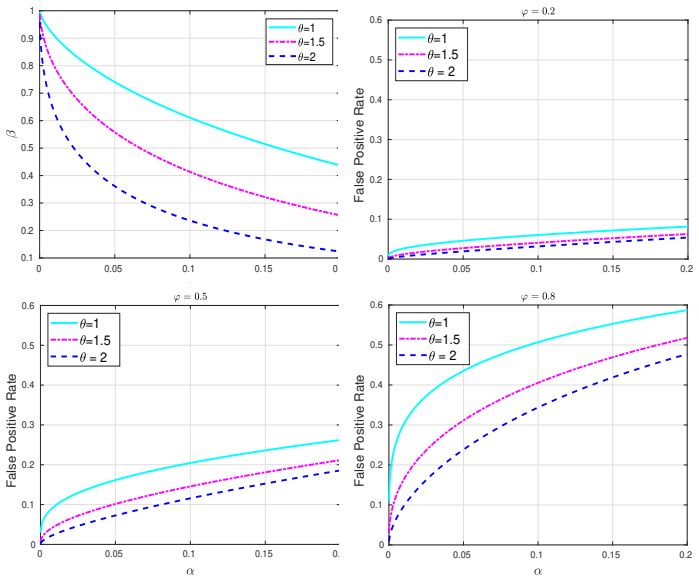
The paper claims that the four main reform proposals—moving away from a fixed 0.05 threshold, requiring prepublication studies, dropping the strict null-alternative dichotomy, and substituting confidence intervals or Bayesian methods—each possess strengths that address genuine concerns in current practice alongside shortcomings that could undermine reliability or introduce new difficulties, and that these can be identified by direct consideration of how sampling distributions and error probabilities function in each case.
What carries the argument
The qualitative weighing of strengths and shortcomings across the four listed reform proposals, anchored in the role of sampling distributions for computing error probabilities independent of thresholds.
If this is right
- Statistical practice would move away from automatic application of any single threshold toward context-sensitive decisions informed by the specific strengths and limits of each approach.
- Requirements for prepublication studies would be adopted only after weighing their benefit in reducing false positives against added time and resource costs.
- Researchers would interpret results with greater attention to the continuous nature of evidence rather than binary reject-or-accept decisions.
- Confidence intervals and Bayesian methods would be used where they supply additional information without discarding the error-probability framework that already works for many calculations.
Where Pith is reading between the lines
- The balanced review implies that training in statistics should present the four reform ideas alongside their documented limitations so that practitioners can combine useful elements rather than choose one wholesale replacement.
- This examination connects to the replication crisis by suggesting that some irreproducibility stems from over-reliance on any single rigid procedure, whether the old threshold or a proposed new one.
- Future methodological work could test the paper's qualitative assessment by developing simple metrics that quantify the trade-offs it identifies, such as changes in false-positive rates when thresholds are relaxed.
Load-bearing premise
The strengths and shortcomings of the reform proposals can be identified and weighed through examination of existing arguments and historical context without new data, formal models, or quantitative evaluation.
What would settle it
A side-by-side empirical or simulation study that measures actual error rates, reproducibility, or decision accuracy under each reform versus current practice and finds that the proposed changes produce no measurable differences in the claimed strengths or shortcomings.
Figures

read the original abstract
Since its introduction by Fisher, the method of hypothesis testing that relies on computing error probabilities has witnessed several developments. Perhaps the most significant development was the seminal contributions of Neyman and Pearson who brought in the concept of the alternative hypothesis with its corresponding error of the second kind. Significance tests have played a major role in various scientific and technological developments, but not without controversies. Although originally cast as frequentist approaches, Bayesian ideas have been incorporated into significance tests, widening access to them. The quantities central to computations of error probabilities are the sampling distributions, which can be computed even without thresholds or alternative hypotheses. Even though Fisher used the significance threshold of 0.05 in his calculations, he cautioned against prescribing any specific threshold. Recently, there have been calls for reformation in practice with regard to the almost standard use of the significance threshold of 0.05, prepublication confirmatory studies, the dichotomous consideration of the null and alternative hypothesis and abandoning significance tests altogether in favour of other approaches such as confidence intervals and Bayesian decision theory. In this paper, we examine these calls for reform and unearth their strengths and short comings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper traces the historical development of hypothesis testing from Fisher's significance tests through Neyman and Pearson's introduction of the alternative hypothesis and type II error. It stresses the centrality of sampling distributions for error probability calculations (independent of thresholds or alternatives) and notes Fisher's caution against prescribing a fixed threshold such as 0.05. The main contribution is an interpretive examination of four classes of reform proposals—altering the conventional 0.05 threshold, requiring pre-publication confirmatory studies, abandoning dichotomous null/alternative decisions, and replacing significance tests with confidence intervals or Bayesian methods—by cataloguing their respective strengths and shortcomings.
Significance. If the review maintains balance and accurately represents the cited literature, it can serve as a useful synthesis for researchers seeking historical perspective on the ongoing debate over statistical practice. The paper's interpretive approach is appropriate for its scope and does not claim new empirical results or formal models; its value therefore rests on the fairness and depth with which it weighs the reform proposals against one another.
minor comments (3)
- [Abstract] Abstract: 'short comings' should be corrected to the single word 'shortcomings'.
- [Abstract] Abstract: The claim that the paper will 'unearth' strengths and shortcomings would be strengthened by an explicit statement of the evaluative criteria employed, even if only qualitative.
- The manuscript should supply specific citations (with section or page numbers where possible) for each reform proposal discussed so that readers can verify the attributed strengths and shortcomings.
Simulated Author's Rebuttal
We thank the referee for their positive summary of our manuscript and for recommending minor revision. The referee accurately captures the paper's focus on the historical development of hypothesis testing, the role of sampling distributions, Fisher's views on thresholds, and our balanced examination of four classes of reform proposals. We are pleased that the interpretive approach is viewed as appropriate for the scope and that the work is seen as a potentially useful synthesis, provided it maintains balance and fidelity to the literature—which we believe it does.
Circularity Check
No circularity in interpretive review of hypothesis testing reforms
full rationale
The paper is a qualitative historical review and critical commentary on the development of significance testing from Fisher and Neyman-Pearson onward, plus an evaluation of recent reform proposals (0.05 threshold, pre-registration, dichotomous decisions, confidence intervals, Bayesian approaches). It presents no mathematical derivations, no first-principles results, no fitted parameters, no quantitative predictions, and no equations that could reduce to inputs by construction. All assessments of strengths and shortcomings are interpretive and rest on external literature rather than any self-referential loop or unverified self-citation chain. The absence of any claimed derivation chain makes circularity impossible by definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Almassi, B. Trust in expert testimony: Eddington's 1919 Eclipse expedition and the British response to general relativity. Studies in History and Philosophy of Modern Physics. 2009
work page 1919
-
[2]
Amrhein, V. and Korner-Nievergelt, F. and Roth, T. The earth is flat ( p<0.05 ): significance thresholds and the crisis of unreplicable research. Peer J. 2017
work page 2017
-
[3]
Amrhein, V. and Greenland, S. and McShane, B. Retire statistical significance. Nature. 2019
work page 2019
-
[4]
Amrhein, V. and Greenland, S. and McShane, B. Inferential Statistics as Descriptive Statistics: There is no replication crisis if we do not expect one. The American Statistician. 2019
work page 2019
-
[5]
Anderson, A. A. Assessing Statistical Significance: Magnitude, precision and model uncertainty. The American Statistician. 2019
work page 2019
-
[6]
Benjamin, D. J. and Berger, J. O. and Johannesson, M. and et al. Redefine statistical significance. Nature Human Behaviour. 2017
work page 2017
-
[7]
Benjamin, D. and Berger, J. Three Recommendations for Improving the Use of p -values. The American Statistician. 2019
work page 2019
-
[8]
Bernardo, J. M. and Rueda, R. Bayesian Hypothesis Testing: A reference approach. International Statistical Review. 2002
work page 2002
-
[9]
Box, G. E. P. Science and statistics. Journal of the American Statistical Association. 1976
work page 1976
-
[10]
Brier, G. W. Verification of forecasts expressed in terms of probability. Monthly Weather Review. 1950
work page 1950
-
[11]
Brocker, J. and Smith, L. A. From Ensemble Forecasts to Predictive Distribution Functions. Tellus A. 2008
work page 2008
-
[12]
Brocker, J. and Smith, L. A. Scoring P robabilistic F orecasts: T he importance of being proper. Weather and Forecasting. 2007
work page 2007
-
[13]
Browner, W. S. and Newman, T. B. Are all p-values created equal? The anology between diagnostic tests and clinical research. Journal of the American Medical Association. 1987
work page 1987
-
[14]
Casella, G. and Berger, R. L. Reconciling Bayesian and Frequentist Evidence in the One-Sided Testing Problem. Journal of the American Statistical Association. 1987
work page 1987
-
[15]
Clemen, R. T. and Winkler, R. L. Combining P robability D istributions F rom E xperts in R isk A nalysis. Risk Analysis. 1999
work page 1999
-
[16]
Collins, H. and Pinch, T. The golem: what everyone should know about science. 1993
work page 1993
-
[17]
An investigation of the false discovery rate and the misinterpretation of p -values
Colquhoun, D. An investigation of the false discovery rate and the misinterpretation of p -values. Royal Society Open Science. 2014
work page 2014
-
[18]
The False Positive Risk: A proposal concerning what to do about P -values
Colquhoun, D. The False Positive Risk: A proposal concerning what to do about P -values. The American Statistician. 2019
work page 2019
-
[19]
Cox, D. R. The Role of Significance Tests. Scandanavian Journal of Statistics. 1977
work page 1977
-
[20]
Dawid, A. P. Present Position and Potential Developments: S ome P ersonal V iews: S tatistical T heory: T he P requencial A pproach. J. R. Statist. Soc. A. 1984
work page 1984
-
[21]
Diebold, F. X. and Gunther, T. A. and Tay, A. S. Evaluating density forecasts with application to Financial Risk Management. International Economic Review. 1998
work page 1998
-
[22]
Too good to be true? T he ( In )credibility of the UK inflation fan charts
Dowd, K. Too good to be true? T he ( In )credibility of the UK inflation fan charts. Journal of Macroeconomics. 2007
work page 2007
-
[23]
Earman, J. and Glymour, C. Relativity and Eclipses: The British eclipse expeditions of 1919 and their predecessors. Historical Studies in the Physical Sciences. 1980
work page 1919
-
[24]
Eddington, A. S. Space, Time and Gravitation: An outline of the general relativity theory. 1920
work page 1920
-
[25]
Elvidge, S. and Themens, D. R. and Brown, M. K. and Donegan-Lawley, E. What to do when F_ 10.7 Goes Out. Space Weather. 2023
work page 2023
-
[26]
Emmert, J. T. Altitude and solar activity dependence of 1967-2005 thermospheric density trends derived from orbital drag. Journal of Geophysical Research: Space Physics. 2015
work page 1967
-
[27]
Emmert, J. T. and Mannucci, A. J. and McDonald, S. E. and Vergados, P. Attribution of interminimum changes in global and hemispheric total electron content. Journal of Geophysical Research: Space Physics. 2017
work page 2017
-
[28]
Fisher, R. A. Statistical methods for research workers. 1925
work page 1925
-
[29]
Fisher, R. A. Uncertain Inference. Proceedings of the American Academy of Arts and Sciences. 1936
work page 1936
-
[30]
Fisher, R. A. The Design of Experiments. 1971
work page 1971
-
[31]
Fisher, R. A. Statistical methods for scientific induction. Journal of the Royal Statistical Society, Series B. 1955
work page 1955
-
[32]
Gannon, M. and Pereira, C. and Polpo, A. Blending Bayesian and Classical Tools to Define Optimal-Size-Dependent Significance Levels. The American Statistician. 2019
work page 2019
-
[33]
Gelman, A. and Loken, E. The Statisical Crisis in Science. American Scientist. 2014
work page 2014
-
[34]
Gibson, E. W. The role of p -values in judging the strength of evidence and realistic replication expectations. Statistics in Biopharmacitical Research. 2021
work page 2021
-
[35]
Gilmore, G. and Tausch-Peboy, G. The 1919 eclipse results that verified general relativity and their later destractors: A story retold. Notes and Records: the Royal Society Journal of the History of Science. 2022
work page 1919
-
[36]
Ginoux, J. M. Albert Einstein and Doubling of the Deflection of Light. Foundations of Science. 2022
work page 2022
-
[37]
Ghosh, J. K. and Delampady, M. and Samanta, T. An Introduction to Bayesian Analysis: Theory and Methods. 2006
work page 2006
-
[38]
Good, I. J. Rational Decisions. Journal of the Royal Statistical Society. Series B (Methodological). 1952
work page 1952
-
[39]
Gneiting, T. and Balabdaoui, F. and Raftery, A. E. Probabilistic Forecasts, Calibration and Sharpness. J. R. Statist. Soc. B. 2007
work page 2007
-
[40]
Gneiting, T. and Raftery, A. E. Strictly Proper Scoring Rules, Prediction and Estimation. J. Amer. Math. Soc. 2007
work page 2007
-
[41]
Goodman, S. N. A comment on replication, p -values and evidence. Statistics in Medicine. 1992
work page 1992
-
[42]
Goodman, S. N. Toward Evidence-Based Medical Statistics. 1: The p -Value Fallacy. Annals of Internal Medicine. 1999
work page 1999
-
[43]
Goodman, S. N. Towards Evidence-Based Medical Statistics. 2: The Bayes Factor. Annals of Internal Medicine. 1999
work page 1999
-
[44]
Greenland, S. Valid p -Values Behave Exactly as They Should: Some misleading criticisms of p -values and their resolution. The American Statistician. 2019
work page 2019
-
[45]
Hagedorn, R. and Smith, L. A. Communicating the value of probabilistic forecasts with weather roulette. Meteorological Applications. 2009
work page 2009
-
[46]
Henney, C. J. and Toussaint, W. A. and White, S. M. and Arge, C. N. Forecasting F_ 10.7 with solar magnetic flux transport modeling. Space Weather. 2012
work page 2012
-
[47]
Henney, C. J. and Hock, R. A. and Scholey, A. K. Toussaint, W. A. and White, S. M. and Arge, C. N. Forecasting solar extreme and far ultraviolet irradiance. Space Weather. 2015
work page 2015
-
[48]
Hoestra, R. and Finch, S. and Kiers, H. A. L. and Johnson, A. Probability as certainty: Dichotomous thinking and the misuse of p -values. Psychonomic Bulletin and Review. 2006
work page 2006
-
[49]
Hsu, C. -T. and N. M. Pedatella. Effects of Forcing Uncertainties on the Thermospheric and Ionospheric States During Geomagnetic Storm and Quiet Periods. Space Weather. 2023
work page 2023
-
[50]
Will ASA's efforts to improve statistical practice be successful? Some evidence to the contrary
Hubbard, R. Will ASA's efforts to improve statistical practice be successful? Some evidence to the contrary. The American Statistician. 2019
work page 2019
-
[51]
Hung, H. M. J. and O'Neill, R. T. and Kohne, K. The behaviour of the p -value when the alternative hypothesis is true. Biometrics. 1997
work page 1997
-
[52]
Ioannidis, J. P. A. Why most published research findings are false. PubMed. 2005
work page 2005
-
[53]
Ioannidis, J. P. A. What have we (not) learnt from millions of scientific papers with p -values?. The American Statistician. 2019
work page 2019
-
[54]
Kahneman, D. and Tversky, A. Prospect Theory: An Analysis of Decision Under Risk. Econometrica. 1979
work page 1979
-
[55]
Kelly, J. L. A new interpretation of information rate. The Bell Systems Technical Journal. 1956
work page 1956
-
[56]
Lambert, D. and Hall, W. J. Asymptotic Lognormality of p -Values. Annals of Statistics. 1982
work page 1982
-
[57]
Leutbecher, M and Palmer, T. N. Ensemble F orecasting. Journal of Computational Physics. 2008
work page 2008
-
[58]
Lindley, D. V. The Philosophy of Statistics. Journal of the Royal Statistical Society. Series D. 2000
work page 2000
-
[59]
Luo, J. and Zhu, L. and Zhang, K. and Zhao, C. and Liu, Z. Forecasting the 10.7 cm Solar Radio Flux Using Deep CNN-LSTM Neural Networks. Processes. 2022
work page 2022
-
[60]
Machete, R. L. and Dintwe, K. Cyclic trends of wildfires over sub-Saharan Africa. Fire. 2023
work page 2023
-
[61]
Machete, R. L. and Moroz, I. M. Initial Distribution Spread: A density forecasting approach. Physica D: Nonlinear Phenomena. 2012
work page 2012
-
[62]
Machete, R. L. Early warning with calibrated and sharper probabilistic forecasts. Journal of Forecasting. 2013
work page 2013
-
[63]
Machete, R. L. Contrasting Probabilistic Scoring Rules. Journal of Statistical Planning and Inference. 2013
work page 2013
-
[64]
Manski, C. F. Treatment Choice with Trial Data: Statistical Decision theory should supplant hypothesis testing. The American Statistician. 2019
work page 2019
-
[65]
Mayo, D. G. Statistical Inference as Severe Testing. 2018
work page 2018
-
[66]
Mayo, D. G. and Hand, D. Statistical significance and its critics: practicing damaging science, or damaging scientific practice?. Synthese. 2022
work page 2022
-
[67]
McShane, B.B. and Gal, D. and Gelman, A. and Robert, C. and Tacket, J.L. Abandon, Statistical Significance. The American Statistician. 2019
work page 2019
-
[68]
Neyman, J. and Pearson, E. S. On the Use and Interpretation of Certain Test Criteria for Purposes of Inference: Part I. Biometrika. 1928
work page 1928
-
[69]
Neyman, J. and Pearson, E. S. On the Use and Interpretation of Certain Test Criteria for Purposes of Inference: Part II. Biometrika. 1928
work page 1928
-
[70]
Neyman, J. and Pearson, E. S. On the Problem of the Most Efficient Tests of Statistical Hypotheses. Philosophical Transactions of the Royal Society. Series A. 1933
work page 1933
-
[71]
Note on an article by Sir Ronald Fisher
Neyman, J. Note on an article by Sir Ronald Fisher. Journal of the Royal Statistical Society. Series B. 1955
work page 1955
-
[72]
Nosek, B. A. and Spies, J. R. and Motyl, M. Scientific Utopia: Restructuring Incentives and Practices to Promote Truth Over Publishability. Perspectives on Psychological Sciences. 2012
work page 2012
-
[73]
Beyond the confidence interval
Poole, C. Beyond the confidence interval. American Journal of Public Health. 1987
work page 1987
-
[74]
Solar activity prediction: Timing predictors and cycle 24
Schatten, K. Solar activity prediction: Timing predictors and cycle 24. Journal of Geophysical Research. 2002
work page 2002
-
[75]
Letter to the Editor: Comment on replication, p -values and evidence by S
Senn, S. Letter to the Editor: Comment on replication, p -values and evidence by S. N. Goodman. Statistics in Medicine. 2002
work page 2002
-
[76]
Smith, L. A. What might we learn from climate forecasts?. Proceedings of the National Academy of Sciences of the UNited States of America. 2002
work page 2002
-
[77]
Smith, L. A. Identification and prediction of low dimensional dynamics. Physica D. 1992
work page 1992
-
[78]
Smith, L. A. Maintenance of Uncertainty. Proc International School of Physics ''Enrico Fermi. 1997
work page 1997
-
[79]
Roulston, M. S. and Smith, L. A. Evaluating P robabilistic F orecasts U sing I nformation T heory. Monthly W eather R eview. 2002
work page 2002
-
[80]
Stevenson, E. and Rodriguez-Fernandez, V. and Minisci, E. and Camacho, D. A deep learning approach to solar radio flux forecasting. Acta Astronautica. 2022
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.