Towards Robust Argumentative Essay Understanding via TIDE: An Interactive Framework with Trial and Debate
Pith reviewed 2026-05-20 13:41 UTC · model grok-4.3
The pith
TIDE integrates a trial and debate process into prompt optimization to reduce the impact of noisy training data on argumentative essay tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
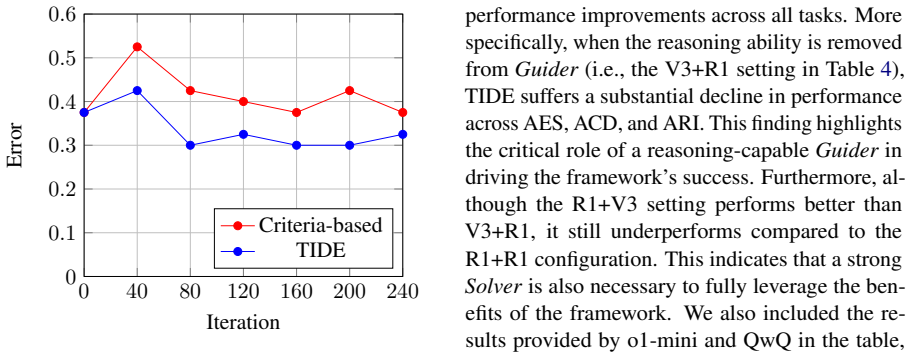
The authors present TIDE as a framework that incorporates a TrIal and DEbate mechanism into criteria-based prompt optimization for argument-related tasks. This integration is shown to mitigate the influence of noisy training data and enhance optimization stability, which produces measurable performance gains on automated essay scoring, argument component detection, and argument relation identification.
What carries the argument
TIDE, the interactive framework built around a TrIal and DEbate mechanism that refines prompts by iteratively testing and challenging criteria-based decisions to limit noise effects.
If this is right
- The framework produces higher accuracy on automated essay scoring compared with standard prompt optimization.
- Argument component detection improves because the debate step filters out misleading training signals.
- Argument relation identification gains from the added stability during prompt refinement.
- Overall results across the three tasks become less variable when noisy examples are present.
Where Pith is reading between the lines
- The same trial-and-debate structure could be tested on prompt optimization problems outside argument analysis where label noise is common.
- An interactive version might allow human judges to step into the debate phase for high-stakes essay evaluation.
- Further breakdowns could isolate whether the trial phase or the debate phase contributes most to noise reduction.
Load-bearing premise
Integrating the TrIal and DEbate mechanism will specifically reduce the effects of noisy training data and increase stability in criteria-based prompt optimization without adding new sources of instability.
What would settle it
A controlled experiment that applies TIDE and a baseline criteria-only optimizer to the same noisy dataset and measures whether TIDE shows no gain in stability or final task accuracy.
Figures







read the original abstract
Argumentative essays serve as a vital medium for assessing critical thinking and reasoning skills, yet there is limited works on accurately understanding and evaluating such texts via prompt. In this work, we propose TIDE, a novel framework designed to improve criteria-based prompt optimization for argument-related tasks by integrating TrIal and DEbate mechanism. Our method addresses key limitations of criteria-based prompt optimizing by mitigating the influence of noisy training data and enhancing optimization stability. We evaluate TIDE on three core tasks: Automated Essay Scoring, Argument Component Detection, and Argument Relation Identification. Results demonstrate that our framework improves performance across tasks. These findings underscore the potential of combining prompt-based methods for advanced argument understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TIDE, a novel interactive framework that augments criteria-based prompt optimization with a Trial and Debate mechanism for argument-related NLP tasks. It claims this integration mitigates the influence of noisy training data and improves optimization stability. The framework is evaluated on Automated Essay Scoring, Argument Component Detection, and Argument Relation Identification, with results reported to show performance improvements across these tasks.
Significance. If the central claim that the Trial and Debate mechanism specifically confers robustness to noisy data is substantiated with targeted experiments, the work could offer a practical advance in prompt-based methods for educational argument analysis, where data quality is often variable. The interactive framing is a potentially useful direction, though its incremental value over existing prompt optimization techniques remains to be quantified.
major comments (2)
- [Abstract] Abstract: The claim that TIDE 'mitigates the influence of noisy training data' is presented as a key contribution, yet the abstract supplies neither a mechanistic description of how the debate process filters or corrects noise nor any reference to ablations or controlled noise-injection experiments that would establish this causal link.
- [Experiments] Experiments section: No ablation isolating the Debate component, no baseline comparison against standard criteria-based optimization under controlled noise levels, and no quantitative results (e.g., accuracy deltas, error bars, or statistical significance) are described, leaving the reported performance gains unverified against the central robustness claim.
minor comments (1)
- [Abstract] The abstract would benefit from explicit mention of the datasets used, the number of runs, and at least one concrete performance metric to allow readers to gauge the scale of improvement.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and will revise the manuscript to strengthen the presentation of our robustness claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that TIDE 'mitigates the influence of noisy training data' is presented as a key contribution, yet the abstract supplies neither a mechanistic description of how the debate process filters or corrects noise nor any reference to ablations or controlled noise-injection experiments that would establish this causal link.
Authors: We agree that the abstract would benefit from a clearer mechanistic description and explicit references to supporting analyses. The full manuscript explains the Trial and Debate process in the Methods section, where iterative critique between trial instances helps surface and correct prompt elements distorted by noise. In the revision we will update the abstract to include a concise description of this filtering mechanism and add references to the relevant ablations and experiments. revision: yes
-
Referee: [Experiments] Experiments section: No ablation isolating the Debate component, no baseline comparison against standard criteria-based optimization under controlled noise levels, and no quantitative results (e.g., accuracy deltas, error bars, or statistical significance) are described, leaving the reported performance gains unverified against the central robustness claim.
Authors: The referee is correct that the current version lacks a dedicated ablation isolating the Debate component and does not report controlled noise-injection experiments or detailed quantitative statistics. We will add these elements in the revised manuscript: an ablation study with and without the Debate mechanism, comparisons against standard criteria-based optimization under controlled noise levels (e.g., 10-30% label noise), and full reporting of accuracy deltas, error bars, and statistical significance tests. These additions will directly substantiate the central robustness claim. revision: yes
Circularity Check
No significant circularity in TIDE framework proposal
full rationale
The paper introduces TIDE as a novel interactive framework that integrates a Trial and Debate mechanism into criteria-based prompt optimization for argument-related tasks. Claims about mitigating noisy training data and improving stability are presented as design motivations and empirical outcomes on Automated Essay Scoring, Argument Component Detection, and Argument Relation Identification, without any equations, derivations, fitted parameters, or mathematical reductions. No self-definitional loops, uniqueness theorems imported from prior self-work, or ansatz smuggling via citation appear in the provided text. The method is constructed as an original architecture rather than a re-derivation of its inputs, rendering the presentation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Criteria-based prompt optimization is limited by noisy training data and instability.
invented entities (1)
-
TIDE framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
integrating TrIal and DEbate mechanism... mitigating the influence of noisy training data
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Towards Comprehensive Argument Analysis in Education: Dataset, Tasks, and Method , author=. 2025 , eprint=
work page 2025
-
[3]
Publications Manual , year = "1983", publisher =
work page 1983
-
[4]
Large Language Models Are Human-Level Prompt Engineers , author=. 2022 , eprint=
work page 2022
- [7]
-
[9]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
- [10]
-
[11]
Dan Gusfield , title =. 1997
work page 1997
-
[12]
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
work page 2015
-
[13]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[14]
Conference on Empirical Methods in Natural Language Processing , year=
CEAMC: Corpus and Empirical Study of Argument Analysis in Education via LLMs , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[15]
Journal of Writing Research , year=
Argumentation features and essay quality: Exploring relationships and incidence counts , author=. Journal of Writing Research , year=
-
[16]
Reasoning on conflicting information: An empirical study of Formal Argumentation , author=. PLoS ONE , year=
-
[17]
ArguMentor: Augmenting User Experiences with Counter-Perspectives , author=. ArXiv , year=
-
[18]
Journal of Communication Pedagogy , year=
Argument Pedagogy for Everyday Life , author=. Journal of Communication Pedagogy , year=
-
[19]
Journal of English Education and Teaching , year=
Argumentative Essay Patterns Produced by University Students , author=. Journal of English Education and Teaching , year=
-
[20]
Journal of Writing Research , year=
Learning from comPA(I)Ring exemplars: Enhancing genre knowledge of argumentative texts , author=. Journal of Writing Research , year=
-
[21]
English Language and Literature Studies , year=
Infusing Critical Thinking Skills into Argumentative Writing: A Study of Chinese College College Learners , author=. English Language and Literature Studies , year=
-
[22]
Leveraging Small LLMs for Argument Mining in Education: Argument Component Identification, Classification, and Assessment , author=. ArXiv , year=
-
[24]
QwQ-32B: Embracing the Power of Reinforcement Learning , url =
Qwen Team , month =. QwQ-32B: Embracing the Power of Reinforcement Learning , url =
- [25]
-
[26]
Assessing Open-Source Large Language Models on Argumentation Mining Subtasks , author=. ArXiv , year=
-
[27]
International Conference on Computational Linguistics , year=
Argumentation Mining on Essays at Multi Scales , author=. International Conference on Computational Linguistics , year=
-
[28]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. ArXiv , year=
-
[29]
Monologic and Dialogic Styles of Argumentation: A Bakhtinian Analysis of Academic Debates between Mainland China and Taiwan , author=. Argumentation , year=
-
[30]
Can Large Language Models perform Relation-based Argument Mining? , author=. ArXiv , year=
-
[31]
Annual Meeting of the Association for Computational Linguistics , year=
Decomposing Argumentative Essay Generation via Dialectical Planning of Complex Reasoning , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[32]
Training Language Models to Win Debates with Self-Play Improves Judge Accuracy , author=. ArXiv , year=
-
[33]
Annual Meeting of the Association for Computational Linguistics , year=
Debatrix: Multi-dimensional Debate Judge with Iterative Chronological Analysis Based on LLM , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[34]
LLM-Based Empathetic Response Through Psychologist-Agent Debate , author=. APWeb/WAIM , year=
-
[36]
IEEE Transactions on Knowledge and Data Engineering , year=
A Survey on Context Learning , author=. IEEE Transactions on Knowledge and Data Engineering , year=
-
[37]
Chain of Thought Prompting Elicits Reasoning in Large Language Models , author=. ArXiv , year=
-
[38]
Can LLM s Reason with Rules? Logic Scaffolding for Stress-Testing and Improving LLM s
Wang, Siyuan and Wei, Zhongyu and Choi, Yejin and Ren, Xiang. Can LLM s Reason with Rules? Logic Scaffolding for Stress-Testing and Improving LLM s. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.406
-
[39]
Behavioral and Brain Sciences , volume=
Everyday reasoning and logical inference , author=. Behavioral and Brain Sciences , volume=. 1993 , publisher=
work page 1993
-
[40]
International Conference on Language Resources and Evaluation , year=
Calibrating LLM-Based Evaluator , author=. International Conference on Language Resources and Evaluation , year=
- [41]
-
[42]
Portuguese Conference on Artificial Intelligence , year=
Assessing Good, Bad and Ugly Arguments Generated by ChatGPT: a New Dataset, its Methodology and Associated Tasks , author=. Portuguese Conference on Artificial Intelligence , year=
-
[43]
Towards Widening The Distillation Bottleneck for Reasoning Models , author=. ArXiv , year=
-
[44]
Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning , author=. ArXiv , year=
-
[45]
Large Language Models Are Human-Level Prompt Engineers , author=. ArXiv , year=
-
[46]
North American Chapter of the Association for Computational Linguistics , year=
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding , author=. North American Chapter of the Association for Computational Linguistics , year=
-
[47]
Conference on Empirical Methods in Natural Language Processing , year=
Argument Pair Extraction from Peer Review and Rebuttal via Multi-task Learning , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[48]
Workshop on Argument Mining , year=
A Unified Representation and a Decoupled Deep Learning Architecture for Argumentation Mining of Students’ Persuasive Essays , author=. Workshop on Argument Mining , year=
- [49]
- [50]
-
[51]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools , author=. ArXiv , year=
- [52]
-
[53]
RoBERTa: A Robustly Optimized BERT Pretraining Approach , author=. ArXiv , year=
- [54]
-
[55]
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate , author=. ArXiv , year=
-
[56]
Debating with More Persuasive LLMs Leads to More Truthful Answers , author=. ArXiv , year=
-
[57]
Noise reduction in speech processing , pages=
Pearson correlation coefficient , author=. Noise reduction in speech processing , pages=. 2009 , publisher=
work page 2009
- [58]
-
[59]
Exploring LLM Prompting Strategies for Joint Essay Scoring and Feedback Generation , author=. ArXiv , year=
-
[60]
Improving Factuality and Reasoning in Language Models through Multiagent Debate , author=. ArXiv , year=
- [61]
-
[62]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenhang Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, K. Lu, and 31 others. 2023. https://api.semanticscholar.org/CorpusID:263134555 Qwen technical report . ArXiv, abs/2309.16609
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[63]
Jon Barwise. 1993. Everyday reasoning and logical inference. Behavioral and Brain Sciences, 16(2):337--338
work page 1993
-
[64]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E. Peters, and Arman Cohan. 2020. https://api.semanticscholar.org/CorpusID:215737171 Longformer: The long-document transformer . ArXiv, abs/2004.05150
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[65]
Liying Cheng, Lidong Bing, Qian Yu, Wei Lu, and Luo Si. 2020. https://api.semanticscholar.org/CorpusID:227035335 Argument pair extraction from peer review and rebuttal via multi-task learning . In Conference on Empirical Methods in Natural Language Processing
work page 2020
-
[67]
2025, Astronomy and Computing, 52, 100954, doi: 10.1016/j.ascom.2025.100954
Scott A. Crossley, Perpetual Baffour, L. Burleigh, and Jules King. 2025. https://doi.org/10.1016/j.asw.2025.100954 A large-scale corpus for assessing source-based writing quality: Asap 2.0 . Assessing Writing, 65:100954
-
[68]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Jun-Mei Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiaoling Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, and 179 others. 2025. https://api.semanticscholar.org/CorpusID:275789950 Deepseek-r1: Incentivizing reasoning capability in llms...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bing-Li Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dong-Li Ji, Erhang Li, Fangyun Lin, Fucong Dai, and 179 others. 2024. https://api.semanticscholar.org/CorpusID:275118643 Deepseek-v3 technical report . ArXiv, abs/2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[70]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. https://api.semanticscholar.org/CorpusID:52967399 Bert: Pre-training of deep bidirectional transformers for language understanding . In North American Chapter of the Association for Computational Linguistics
work page 2019
-
[71]
Jeffrey P. Mehltretter Drury, Nicholas S. Paliewicz, and Sara A. Mehltretter Drury. 2019. https://api.semanticscholar.org/CorpusID:146011477 Argument pedagogy for everyday life . Journal of Communication Pedagogy
work page 2019
-
[72]
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. 2023. https://api.semanticscholar.org/CorpusID:258841118 Improving factuality and reasoning in language models through multiagent debate . ArXiv, abs/2305.14325
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[73]
Ahmed El-Kishky. 2024. https://api.semanticscholar.org/CorpusID:272648256 Openai o1 system card . ArXiv, abs/2412.16720
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[74]
Lucile Favero, Juan Antonio P'erez-Ortiz, Tanja K \"a ser, and Nuria Oliver. 2025. https://api.semanticscholar.org/CorpusID:276482778 Leveraging small llms for argument mining in education: Argument component identification, classification, and assessment . ArXiv, abs/2502.14389
- [75]
-
[76]
Yuhang He, Jianzhu Bao, Yang Sun, Bin Liang, Min Yang, Bing Qin, and Ruifeng Xu. 2024. https://api.semanticscholar.org/CorpusID:271860879 Decomposing argumentative essay generation via dialectical planning of complex reasoning . In Annual Meeting of the Association for Computational Linguistics
work page 2024
-
[77]
Geoffrey Irving, Paul Francis Christiano, and Dario Amodei. 2018. https://api.semanticscholar.org/CorpusID:22050710 Ai safety via debate . ArXiv, abs/1805.00899
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[78]
R., Rocktäschel, T., and Perez, E
Akbir Khan, John Hughes, Dan Valentine, Laura Ruis, Kshitij Sachan, Ansh Radhakrishnan, Edward Grefenstette, Samuel R. Bowman, Tim Rocktaschel, and Ethan Perez. 2024. https://api.semanticscholar.org/CorpusID:267627652 Debating with more persuasive llms leads to more truthful answers . ArXiv, abs/2402.06782
-
[79]
Jingcong Liang, Rong Ye, Meng Han, Ruofei Lai, Xinyu Zhang, Xuanjing Huang, and Zhongyu Wei. 2024. https://api.semanticscholar.org/CorpusID:268379278 Debatrix: Multi-dimensional debate judge with iterative chronological analysis based on llm . In Annual Meeting of the Association for Computational Linguistics
work page 2024
-
[80]
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Zhaopeng Tu, and Shuming Shi. 2023. https://api.semanticscholar.org/CorpusID:258967540 Encouraging divergent thinking in large language models through multi-agent debate . ArXiv, abs/2305.19118
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[81]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. https://api.semanticscholar.org/CorpusID:198953378 Roberta: A robustly optimized bert pretraining approach . ArXiv, abs/1907.11692
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[82]
Yuxuan Liu, Tianchi Yang, Shaohan Huang, Zihan Zhang, Haizhen Huang, Furu Wei, Weiwei Deng, Feng Sun, and Qi Zhang. 2023. https://api.semanticscholar.org/CorpusID:262464745 Calibrating llm-based evaluator . In International Conference on Language Resources and Evaluation
work page 2023
-
[83]
Chunxia Lu. 2021. https://api.semanticscholar.org/CorpusID:239046459 Infusing critical thinking skills into argumentative writing: A study of chinese college college learners . English Language and Literature Studies
work page 2021
- [84]
-
[85]
Tine Mombaers, Roos Van Gasse, and Sven De Maeyer. 2024. https://api.semanticscholar.org/CorpusID:270467114 Learning from compa(i)ring exemplars: Enhancing genre knowledge of argumentative texts . Journal of Writing Research
work page 2024
-
[86]
Elena Musi, Nadin Kokciyan, Khalid Al-Khatib, Davide Ceolin, Emmanuelle Dietz, Klara Gutekunst, Annette Hautli-Janisz, Cristian Manuel Santiba \ n ez Ya \ n ez, Jodi Schneider, Jonas Scholz, and 1 others. 2025. Toward reasonable parrots: Why large language models should argue with us by design. arXiv preprint arXiv:2505.05298
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.