The Harmonic Synthetic Control Method
Pith reviewed 2026-05-21 07:18 UTC · model grok-4.3
The pith
Harmonic Synthetic Control adapts to both common and idiosyncratic stochastic trends by tuning between donor matching and residual forecasting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
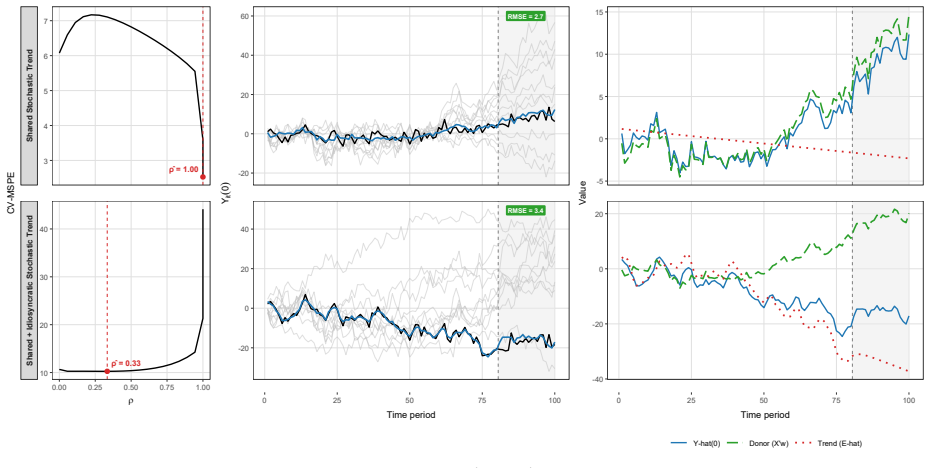
HSC replaces the binary choice of pre-filtering versus direct application with a soft allocation that jointly estimates donor weights and a unit-specific smooth residual, then forecasts the residual into post-treatment periods. A tuning parameter selected by cross-validation controls the division and produces a spectral downweighting of low-frequency residual components during matching. A prediction-error decomposition isolates weight-estimation distortion from forecasting error, and Monte Carlo exercises confirm good performance whether stochastic trends are predominantly common or idiosyncratic.
What carries the argument
The soft allocation mechanism, governed by a tuning parameter chosen via rolling-origin cross-validation, that divides estimation between donor-weight matching on an adjusted series and separate time-series forecasting of the treated-unit residual.
If this is right
- HSC performs well when stochastic trends are predominantly common across units.
- HSC performs well when stochastic trends are predominantly idiosyncratic to the treated unit.
- Estimators locked to a single regime fail in the opposite regime.
- The method continuously interpolates between synthetic control on differenced outcomes and synthetic control on raw outcomes with an intercept or trend.
- A prediction-error decomposition cleanly separates weight-estimation distortion from residual-forecasting error.
Where Pith is reading between the lines
- The soft-allocation idea could be ported to other panel-data estimators that currently force a hard choice between levels and differences.
- Real-world policy evaluations using trending macroeconomic series might become more robust once the tuning parameter is selected automatically.
- Replacing the current forecaster with alternatives that better capture higher-order dynamics would be a direct testable extension.
Load-bearing premise
The treated-unit-specific smooth residual can be reliably extrapolated into post-treatment periods by a time-series forecaster whose accuracy is governed by a tuning parameter chosen via rolling-origin cross-validation.
What would settle it
Monte Carlo trials or an empirical application in which HSC produces larger bias or higher mean-squared error than a regime-matched fixed estimator once the dominant type of stochastic trend is switched from common to idiosyncratic or vice versa.
Figures





read the original abstract
Synthetic control methods can produce misleading counterfactual predictions when outcome series contain unit-specific stochastic trends, a common feature of nonstationary macroeconomic data. Existing remedies, such as pre-filtering or differencing, reduce spurious matching but may discard shared nonstationary variation that helps estimate donor weights. We propose Harmonic Synthetic Control (HSC), which replaces this binary choice with a soft allocation mechanism. HSC jointly estimates donor weights and a treated-unit-specific smooth residual component, then extrapolates this component into post-treatment periods using a time-series forecaster. A tuning parameter, selected by rolling-origin cross-validation, governs the division between donor matching and forecasting. As it varies, HSC continuously interpolates between synthetic control applied to differenced outcomes and synthetic control applied to raw outcomes with an intercept or trend. We provide a spectral interpretation showing how HSC downweights low-frequency residual components in donor matching and assigns them to the forecasting branch. A prediction-error decomposition separates weight-estimation distortion from residual-forecasting error. Monte Carlo exercises show that HSC adapts across regimes, performing well when stochastic trends are predominantly common or idiosyncratic, while estimators fixed to one regime can fail in the other.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Harmonic Synthetic Control (HSC) method for synthetic control estimation with unit-specific stochastic trends in nonstationary data. HSC jointly estimates donor weights and a treated-unit-specific smooth residual component, extrapolates the residual via a time-series forecaster, and uses a single tuning parameter selected by rolling-origin cross-validation to interpolate between differenced and level-based synthetic control. It supplies a spectral interpretation of low-frequency component handling, a prediction-error decomposition separating weight-estimation distortion from forecasting error, and Monte Carlo evidence that HSC adapts across common versus idiosyncratic stochastic-trend regimes while fixed-regime estimators fail in mismatched cases.
Significance. If the Monte Carlo performance claims hold and the cross-validation procedure reliably selects regime-appropriate allocations, HSC would offer a useful flexible alternative to existing remedies like pre-filtering or differencing for macroeconomic applications. The manuscript earns credit for supplying a prediction-error decomposition and Monte Carlo exercises that directly test adaptation across regimes; these elements provide concrete, falsifiable evidence rather than purely theoretical claims.
major comments (2)
- [§3] §3 (HSC procedure and tuning parameter selection): The central claim that HSC adapts across regimes rests on rolling-origin cross-validation reliably identifying the appropriate split between donor matching and residual forecasting. However, when pre-treatment residuals contain unit-specific stochastic trends or breaks that differ from post-treatment behavior, the hold-out periods used in CV may not be representative of post-treatment extrapolation error. This concern is load-bearing for the adaptation result and requires either additional theoretical justification for CV consistency under nonstationarity or expanded Monte Carlo designs that explicitly vary the degree of pre- versus post-treatment nonstationarity mismatch.
- [§5] §5 (Monte Carlo exercises): The reported performance advantages for HSC over fixed-regime estimators are central to the paper's empirical contribution. To evaluate whether these advantages survive the CV selection issue raised above, the exercises should include explicit reporting of the selected tuning parameter values across replications, the frequency with which CV chooses the 'correct' regime, and sensitivity checks to the length of the rolling-origin hold-out window.
minor comments (2)
- [Abstract] Abstract: The description of the Monte Carlo exercises would be strengthened by including at least one quantitative performance metric (e.g., average RMSE or coverage rate) and a brief statement of the number of replications or error-bar information.
- [§2] Notation: The definition of the smooth residual component and its extrapolation step would benefit from an explicit equation linking the forecaster's tuning parameter to the overall HSC estimator, to make the interpolation property between differenced and raw SC fully transparent.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the manuscript. We address each major comment below and describe the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [§3] §3 (HSC procedure and tuning parameter selection): The central claim that HSC adapts across regimes rests on rolling-origin cross-validation reliably identifying the appropriate split between donor matching and residual forecasting. However, when pre-treatment residuals contain unit-specific stochastic trends or breaks that differ from post-treatment behavior, the hold-out periods used in CV may not be representative of post-treatment extrapolation error. This concern is load-bearing for the adaptation result and requires either additional theoretical justification for CV consistency under nonstationarity or expanded Monte Carlo designs that explicitly vary the degree of pre- versus post-treatment nonstationarity mismatch.
Authors: We agree that the reliability of rolling-origin cross-validation when pre- and post-treatment nonstationarity may differ is important for supporting the adaptation claim. The existing Monte Carlo design examines performance under common versus idiosyncratic stochastic trends but does not explicitly introduce mismatches such as breaks or trend changes at the treatment date. To address this directly, we will expand the Monte Carlo exercises to include designs that vary the degree of pre- versus post-treatment nonstationarity mismatch and report how the cross-validation procedure performs in those cases. revision: yes
-
Referee: [§5] §5 (Monte Carlo exercises): The reported performance advantages for HSC over fixed-regime estimators are central to the paper's empirical contribution. To evaluate whether these advantages survive the CV selection issue raised above, the exercises should include explicit reporting of the selected tuning parameter values across replications, the frequency with which CV chooses the 'correct' regime, and sensitivity checks to the length of the rolling-origin hold-out window.
Authors: We welcome the request for additional diagnostics on the cross-validation procedure. In the revised version we will report the distribution of selected tuning-parameter values across replications, the frequency with which the procedure selects the regime consistent with the data-generating process, and results from sensitivity checks that vary the length of the rolling-origin hold-out window. These additions will allow readers to assess the robustness of the reported performance advantages. revision: yes
Circularity Check
No circularity: HSC uses external CV tuning and independent Monte Carlo validation
full rationale
The derivation relies on a tuning parameter chosen by rolling-origin cross-validation applied to pre-treatment data, an external procedure whose objective is independent of the post-treatment counterfactuals being evaluated. The spectral interpretation and prediction-error decomposition are analytical separations of weight-estimation distortion from residual-forecasting error, derived from the method's own equations without reducing the target performance metric to a quantity defined in terms of itself. Monte Carlo exercises generate simulated data under controlled common versus idiosyncratic trend regimes and compare HSC against fixed-regime estimators, supplying falsifiable evidence outside the fitted values or self-citations. No load-bearing self-citation, self-definitional step, or fitted-input-renamed-as-prediction appears in the procedure or claims.
Axiom & Free-Parameter Ledger
free parameters (1)
- tuning parameter
axioms (1)
- domain assumption Outcome series contain unit-specific stochastic trends that are a common feature of nonstationary macroeconomic data
invented entities (1)
-
treated-unit-specific smooth residual component
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
The weight function w_q(μ;ρ) = μ / ((1-ρ) + ρ μ) ... identifies w_q(μ;ρ) as the weighted harmonic mean of μ and 1
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
HSC continuously interpolates between synthetic control applied to differenced outcomes and ... raw outcomes with an intercept or trend
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the Edinburgh Mathematical Society , volume=
On a New Method of Graduation , author=. Proceedings of the Edinburgh Mathematical Society , volume=
-
[2]
Transactions of the Actuarial Society of America , volume=
A New Method of Graduation , author=. Transactions of the Actuarial Society of America , volume=
-
[3]
Eilers, Paul H. C. and Marx, Brian D. , journal=. Flexible Smoothing with
-
[4]
Journal of Money, credit, and Banking , pages=
Postwar US business cycles: an empirical investigation , author=. Journal of Money, credit, and Banking , pages=. 1997 , publisher=
work page 1997
-
[5]
AEA Papers and Proceedings , volume=
Temporal aggregation for the synthetic control method , author=. AEA Papers and Proceedings , volume=. 2024 , organization=
work page 2024
-
[6]
American Journal of Political Science , volume=
Comparative politics and the synthetic control method , author=. American Journal of Political Science , volume=. 2015 , publisher=
work page 2015
-
[7]
Journal of econometrics , volume=
ArCo: An artificial counterfactual approach for high-dimensional panel time-series data , author=. Journal of econometrics , volume=. 2018 , publisher=
work page 2018
-
[8]
Journal of econometrics , volume=
Understanding spurious regressions in econometrics , author=. Journal of econometrics , volume=. 1986 , publisher=
work page 1986
-
[9]
Hamilton, James D , journal=. Why you should never use the. 2018 , publisher=
work page 2018
-
[10]
Balancing, regression, difference-in-differences and synthetic control methods: A synthesis , author=. 2016 , institution=
work page 2016
-
[11]
arXiv preprint arXiv:2508.21536 , year=
Triply Robust Panel Estimators , author=. arXiv preprint arXiv:2508.21536 , year=
-
[12]
Same Root Different Leaves: Time Series and Cross-Sectional Methods in Panel Data , author=. Econometrica , volume=. 2023 , publisher=
work page 2023
-
[13]
Journal of the American Statistical Association , volume=
The augmented synthetic control method , author=. Journal of the American Statistical Association , volume=. 2021 , publisher=
work page 2021
-
[14]
Journal of Applied Econometrics , volume=
Cointegration and control: Assessing the impact of events using time series data , author=. Journal of Applied Econometrics , volume=. 2021 , publisher=
work page 2021
-
[15]
Journal of the American statistical association , volume=
Combining matching and synthetic control to tradeoff biases from extrapolation and interpolation , author=. Journal of the American statistical association , volume=. 2021 , publisher=
work page 2021
-
[16]
Abadie, A. and Gardeazabal, J. , title =. The American Economic Review , year =
-
[17]
Journal of the American statistical Association , volume=
Synthetic control methods for comparative case studies: Estimating the effect of California’s tobacco control program , author=. Journal of the American statistical Association , volume=. 2010 , publisher=
work page 2010
-
[18]
Journal of economic literature , volume=
Using synthetic controls: Feasibility, data requirements, and methodological aspects , author=. Journal of economic literature , volume=. 2021 , publisher=
work page 2021
-
[19]
American Economic Review , volume=
Synthetic difference-in-differences , author=. American Economic Review , volume=. 2021 , publisher=
work page 2021
-
[20]
Quantitative Economics , volume=
Synthetic controls with imperfect pretreatment fit , author=. Quantitative Economics , volume=. 2021 , publisher=
work page 2021
-
[21]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Synthetic controls with staggered adoption , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2022 , publisher=
work page 2022
-
[22]
Journal of Statistical Software , volume=
scpi: Uncertainty quantification for synthetic control methods , author=. Journal of Statistical Software , volume=
-
[23]
Journal of the American Statistical Association , volume=
Prediction intervals for synthetic control methods , author=. Journal of the American Statistical Association , volume=. 2021 , publisher=
work page 2021
-
[24]
Journal of Causal Inference , volume=
Synthetic control method: Inference, sensitivity analysis and confidence sets , author=. Journal of Causal Inference , volume=. 2018 , publisher=
work page 2018
-
[25]
Review of Economics and Statistics , pages=
Uncertainty quantification in synthetic controls with staggered treatment adoption , author=. Review of Economics and Statistics , pages=. 2025 , publisher=
work page 2025
-
[26]
arXiv preprint arXiv:2505.22388 , year=
A Synthetic Business Cycle Approach to Counterfactual Analysis with Nonstationary Macroeconomic Data , author=. arXiv preprint arXiv:2505.22388 , year=
-
[27]
Journal of Business & Economic Statistics , volume=
A design-based perspective on synthetic control methods , author=. Journal of Business & Economic Statistics , volume=. 2024 , publisher=
work page 2024
-
[28]
Journal of the American Statistical Association , volume=
An exact and robust conformal inference method for counterfactual and synthetic controls , author=. Journal of the American Statistical Association , volume=. 2021 , publisher=
work page 2021
-
[29]
Journal of Business & Economic Statistics , volume=
Counterfactual analysis and inference with nonstationary data , author=. Journal of Business & Economic Statistics , volume=. 2022 , publisher=
work page 2022
-
[30]
Journal of the American Statistical Association , volume=
Counterfactual analysis with artificial controls: Inference, high dimensions, and nonstationarity , author=. Journal of the American Statistical Association , volume=. 2021 , publisher=
work page 2021
-
[31]
arXiv preprint arXiv:2504.19841 , year=
Inference with few treated units , author=. arXiv preprint arXiv:2504.19841 , year=
work page internal anchor Pith review arXiv
-
[32]
The Econometrics Journal , volume=
Causal models for longitudinal and panel data: A survey , author=. The Econometrics Journal , volume=. 2024 , publisher=
work page 2024
-
[33]
Journal of the American Statistical Association , volume=
A penalized synthetic control estimator for disaggregated data , author=. Journal of the American Statistical Association , volume=. 2021 , publisher=
work page 2021
-
[34]
Synthetic control and inference , author=. Econometrics , volume=. 2017 , publisher=
work page 2017
-
[35]
Distributional synthetic controls , author=. Econometrica , volume=. 2023 , publisher=
work page 2023
-
[36]
A simple, positive semi-definite, heteroskedasticity and autocorrelation consistent covariance matrix , author=. Econometrica , volume=. 1987 , publisher=
work page 1987
-
[37]
Heteroskedasticity and autocorrelation consistent covariance matrix estimation , author=. Econometrica , volume=. 1991 , publisher=
work page 1991
- [38]
-
[39]
Hsiao, Cheng and Ching, H Steve and Wan, Shui Ki , journal=. A panel data approach for program evaluation: measuring the benefits of political and economic integration of. 2012 , publisher=
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.