Latent Space Guided Scenario Sampling for Multimodal Segmentation Under Missing Modalities
Pith reviewed 2026-05-21 07:19 UTC · model grok-4.3
The pith
A distortion-based sampling method from pretrained latent space improves fine-tuning for multimodal segmentation with missing modalities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By quantifying the distortion induced by each modality-availability scenario in the pretrained shared latent representation, capturing scenario relations via a radial basis function kernel, and deriving refined scores through regularized kernel smoothing, the method converts these into a probability distribution for scenario sampling during fine-tuning, leading to superior performance under missing modalities.
What carries the argument
Latent-space-guided scenario sampling, which uses distortion magnitudes in the shared latent representation smoothed by an RBF kernel to prioritize informative modality scenarios for fine-tuning.
If this is right
- The method focuses training on more informative scenarios rather than uniform sampling.
- Performance gains are shown across multiple remote sensing datasets and backbone architectures.
- The pretrained latent space provides a reliable basis for guiding adaptation to missing data.
- Outperforms existing adaptation techniques like LoRA in this setting.
Where Pith is reading between the lines
- This approach may extend to other multimodal fusion tasks where data completeness varies.
- Future work could explore dynamic sampling during inference rather than only training.
- It suggests that latent space geometry can guide data efficiency in multimodal learning.
Load-bearing premise
The magnitude of distortion that each modality-availability scenario causes in the pretrained latent representation reliably indicates how informative that scenario will be for fine-tuning.
What would settle it
An experiment where the proposed distortion-based sampling is replaced with uniform random sampling and the resulting model shows equal or higher accuracy on missing-modality test cases would falsify the advantage of the method.
Figures



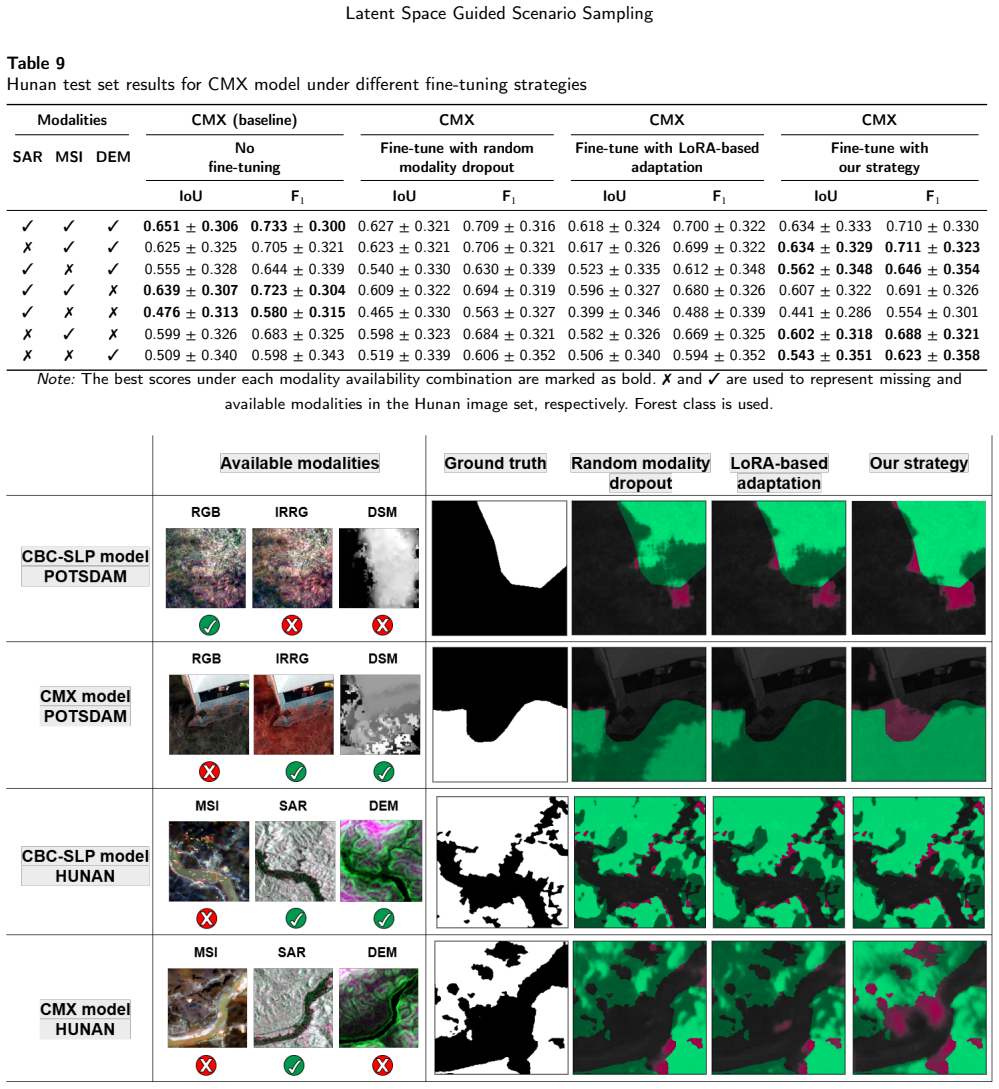
read the original abstract
Multimodal semantic segmentation benefits remote sensing analysis by combining complementary information from different sensor modalities. In real-world remote sensing applications, one or more modalities may be unavailable due to sensor failures, adverse atmospheric conditions, or data acquisition problems. Even with pretrained multimodal representations and existing fine-tuning or adaptation strategies, performance may remain limited because all modality availability scenarios are typically treated as equally informative during training. In this paper, we propose a novel training strategy that learns a scenario sampling distribution directly from the pretrained latent space. Instead of relying on uniform random modality dropout, the proposed method guides fine-tuning toward more informative modality availability scenarios. More specifically, we quantify the effect of each scenario independently based on the distortion it induces in the shared latent representation. We then capture scenario relations using a radial basis function kernel and derive refined scenario scores through a regularized kernel smoothing. These scores are then converted into a probability distribution during scenario sampling for fine-tuning. We evaluate this strategy on three remote sensing image sets, namely DSTL, Potsdam, and Hunan, using CBC-SLP, CBC, and CMX backbones. The experimental results with different image sets and backbones show that our method outperforms standard fine-tuning and LoRA-based adaptation. These findings suggest that the pretrained latent representation can serve as an effective basis for sampling during missing modality fine-tuning. Code is available at https://github.com/iremulku/Latent-Space-Guided-Scenario-Sampling
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a latent-space-guided scenario sampling strategy for fine-tuning multimodal semantic segmentation models under missing modalities. It quantifies the distortion each modality-availability scenario induces in a fixed pretrained shared latent representation, applies an RBF kernel with regularized smoothing to derive scenario scores and a sampling distribution, and reports that this outperforms uniform sampling in standard fine-tuning as well as LoRA adaptation on the DSTL, Potsdam, and Hunan datasets using CBC-SLP, CBC, and CMX backbones.
Significance. If the central result holds, the approach demonstrates that structure in a pretrained multimodal latent space can be leveraged to prioritize more informative training scenarios during adaptation, offering a potential efficiency gain for remote-sensing segmentation tasks where sensor modalities are intermittently unavailable. The public code release supports reproducibility and is a clear strength.
major comments (2)
- [Method (scenario scoring and sampling)] The outperformance claim rests on the assumption that distortion magnitude in the frozen pretrained latent space is a reliable proxy for how informative a scenario will be during subsequent fine-tuning. No experiment is reported that measures the actual per-scenario performance delta or gradient signal obtained when the model is allowed to adapt on high-distortion versus low-distortion scenarios in isolation; without this, it remains possible that any non-uniform sampling would produce similar gains.
- [Method (regularized kernel smoothing)] The regularization parameter in the kernel smoothing step is treated as a free hyper-parameter, yet the manuscript provides no sensitivity analysis or cross-validation procedure showing that the reported gains are stable across reasonable choices of this parameter or that the final sampling distribution does not collapse to a near-uniform distribution for the chosen value.
minor comments (2)
- [Abstract] The abstract asserts quantitative outperformance but does not include any numerical metrics, error bars, or dataset-specific improvement magnitudes; adding one or two representative numbers would improve the summary.
- [Method] Notation for the distortion measure and the RBF kernel bandwidth should be introduced with explicit equations rather than descriptive text only, to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with clarifications on our methodological choices and empirical support. Where appropriate, we outline revisions to strengthen the presentation and validation of the latent-space-guided sampling approach.
read point-by-point responses
-
Referee: [Method (scenario scoring and sampling)] The outperformance claim rests on the assumption that distortion magnitude in the frozen pretrained latent space is a reliable proxy for how informative a scenario will be during subsequent fine-tuning. No experiment is reported that measures the actual per-scenario performance delta or gradient signal obtained when the model is allowed to adapt on high-distortion versus low-distortion scenarios in isolation; without this, it remains possible that any non-uniform sampling would produce similar gains.
Authors: We appreciate this observation on the proxy assumption. The distortion metric is derived from a fixed pretrained multimodal latent space, where larger deviations quantify greater departure from complete modality information; this provides a structured, data-driven basis for prioritization rather than arbitrary non-uniformity. The reported gains are consistent across DSTL, Potsdam, and Hunan with CBC-SLP, CBC, and CMX backbones, exceeding both uniform dropout and LoRA baselines. To directly address whether arbitrary non-uniform sampling could suffice, we will add a controlled comparison against random non-uniform scenario sampling in the revised experiments. revision: yes
-
Referee: [Method (regularized kernel smoothing)] The regularization parameter in the kernel smoothing step is treated as a free hyper-parameter, yet the manuscript provides no sensitivity analysis or cross-validation procedure showing that the reported gains are stable across reasonable choices of this parameter or that the final sampling distribution does not collapse to a near-uniform distribution for the chosen value.
Authors: We agree that explicit sensitivity analysis would better demonstrate robustness. The regularization parameter was chosen via preliminary tuning to preserve scenario differentiation while avoiding over-smoothing. In the revision we will include a sensitivity study across a range of regularization values, reporting the resulting scenario score distributions, effective support size, and downstream segmentation performance to confirm stability and that the sampling distribution remains distinctly non-uniform for the selected operating point. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines a scenario sampling distribution by first measuring distortion each modality-availability scenario induces in a fixed pretrained shared latent representation, then applying RBF kernel smoothing and regularization to obtain scores that are converted to sampling probabilities. This construction is independent of the subsequent fine-tuning performance; the distortion computation occurs on the frozen encoder prior to adaptation, and the method is evaluated empirically on DSTL, Potsdam, and Hunan datasets with multiple backbones. No step reduces by construction to a fitted parameter from the target task, no self-citation is load-bearing for the core premise, and the central claim rests on observed outperformance rather than tautological equivalence to inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- regularization parameter in kernel smoothing
axioms (1)
- domain assumption Distortion induced in the shared latent representation by a modality availability scenario quantifies the informativeness of that scenario for fine-tuning.
Reference graph
Works this paper leans on
-
[1]
Towards robust incomplete multi- modalopen-setdomaingeneralizationwithuncertainmissingmodal- ities
Chen, X., Tao, H., Li, B., 2026. Towards robust incomplete multi- modalopen-setdomaingeneralizationwithuncertainmissingmodal- ities. Knowledge-Based Systems 341, 115777
work page 2026
-
[2]
A novel approach to incompletemultimodallearningforremotesensingdatafusion
Chen, Y., Zhao, M., Bruzzone, L., 2024. A novel approach to incompletemultimodallearningforremotesensingdatafusion. IEEE Transactions on Geoscience and Remote Sensing 62, 1–14
work page 2024
-
[3]
A deep-learning-based forecasting ensemble to predict missing data for remote sensing analysis
Das, M., Ghosh, S.K., 2017. A deep-learning-based forecasting ensemble to predict missing data for remote sensing analysis. IEEE JournalofSelectedTopicsinAppliedEarthObservationsandRemote Sensing 10, 5228–5236
work page 2017
-
[4]
DSTL Satellite Imagery Feature Detection
Detection, D.S.I.F., 2016. DSTL Satellite Imagery Feature Detection. Kaggle competition. [Online]. Available: https://www.kaggle.com/c/dstl-satellite-imagery-feature-detection. Accessed: Jan. 29, 2026
work page 2016
-
[5]
Therepresentertheoremforhilbert spaces: a necessary and sufficient condition
Dinuzzo,F.,Schölkopf,B.,2012. Therepresentertheoremforhilbert spaces: a necessary and sufficient condition. Advances in neural information processing systems 25
work page 2012
-
[6]
Do,M.K.,Han,K.,Lai,P.,Phan,K.T.,Xiang,W.,2025. Robsense:A robust multi-modal foundation model for remote sensing with static, temporal, and incomplete data adaptability, in: Proceedings of the Computer Vision and Pattern Recognition Conference, pp. 7427– 7436
work page 2025
-
[7]
Dong, H., Liu, M., Zhou, K., Chatzi, E., Kannala, J., Stachniss, C., Fink, O., 2026. Advances in multimodal adaptation and general- ization: From traditional approaches to foundation models. IEEE TransactionsonPatternAnalysisandMachineIntelligence48,5672– 5691
work page 2026
-
[8]
Gong, A., Choi, K., Dwivedi, R., 2024. Supervised kernel thinning. Advances in Neural Information Processing Systems 37, 6267–6322
work page 2024
-
[9]
Han,W.,Geng,J.,Xu,Z.,Jiang,W.,2025. Multimodalheterogeneous hypergraph learning for incomplete multimodal semantic segmenta- tionofremotesensingimages. IEEETransactionsonGeoscienceand Remote Sensing 63, 1–15
work page 2025
-
[10]
Lora: Low-rank adaptation of large language models
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al., 2022. Lora: Low-rank adaptation of large language models. Iclr 1, 3
work page 2022
-
[11]
2D Semantic Labeling Contest: Potsdam
ISPRS, 2014. 2D Semantic Labeling Contest: Potsdam. ISPRS Benchmark Datasets (UrbanSemLab). [Online]. Available: https://www.isprs.org/resources/datasets/benchmarks/UrbanSemLab. Accessed: Jan. 30, 2026
work page 2014
-
[12]
Li, J., Wang, Z., Xu, N., You, Z., 2025. Semantic segmentation with scale alignment and contextual information fusion for multimodal remote sensing images. Information Fusion , 103671
work page 2025
-
[13]
Li,X.,Wen,X.,Xu,H.,Wang,X.,2026. Structfuse-net:Astructure- awaremultimodalfusionnetworkforgeometry-consistentoptical–sar image segmentation. IEEE Transactions on Geoscience and Remote Sensing 64, 1–20
work page 2026
-
[14]
Li, Y., Zhou, Y., Zhang, Y., Zhong, L., Wang, J., Chen, J., 2022. Dkdfn:Domainknowledge-guideddeepcollaborativefusionnetwork for multimodal unitemporal remote sensing land cover classification. ISPRS Journal of Photogrammetry and Remote Sensing 186, 170– 189
work page 2022
-
[15]
Liang, G., Zhou, Q., Wang, Z., Chen, J., Gu, L., Yao, C., Wu, S., Huang,B.,Chen,K.,2025. Semantic-guidedmaskedmutuallearning for multi-modal brain tumor segmentation with arbitrary missing modalities, in: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 5137–5145
work page 2025
-
[16]
Linial, O., Leifman, G., Blau, Y., Sherman, N., Gigi, Y., Sirko, W., Beryozkin, G., 2025. Enhancing remote sensing representations throughmixed-modalitymaskedautoencoding,in:Proceedingsofthe Winter Conference on Applications of Computer Vision, pp. 507– 516
work page 2025
-
[17]
Ma,X.,Zhang,X.,Pun,M.O.,Huang,B.,2025a.Aunifiedframework with multimodal fine-tuning for remote sensing semantic segmenta- tion.IEEETransactionsonGeoscienceandRemoteSensing63,1–15
-
[18]
Sasam:Scale- aware segmentation anything model for multimodal remote sensing Ulku et al
Ma,Y.,Tong,H.,Chai,L.,Mao,S.,Zhang,Y.,2025b. Sasam:Scale- aware segmentation anything model for multimodal remote sensing Ulku et al. Page 13 of 14 Latent Space Guided Scenario Sampling images. Information Fusion 129, 104054
-
[19]
Momeni,S.,Mazumder,S.,Liu,B.,2025. Continuallearningusinga kernel-based method over foundation models, in: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 19528–19536
work page 2025
-
[20]
Mmmvit: Multiscale multimodal vision transformer for brain tumor segmentationwithmissingmodalities
Qiu,C.,Song,Y.,Liu,Y.,Zhu,Y.,Han,K.,Sheng,V.S.,Liu,Z.,2024. Mmmvit: Multiscale multimodal vision transformer for brain tumor segmentationwithmissingmodalities. BiomedicalSignalProcessing and Control 90, 105827
work page 2024
-
[21]
Robust multi- modal learning with missing modalities via parameter-efficient adap- tation
Reza, M.K., Prater-Bennette, A., Asif, M.S., 2024. Robust multi- modal learning with missing modalities via parameter-efficient adap- tation. IEEEtransactionsonpatternanalysisandmachineintelligence 47, 742–754
work page 2024
-
[22]
Kernel partial least squares regression in reproducing kernel hilbert space
Rosipal, R., Trejo, L.J., 2001. Kernel partial least squares regression in reproducing kernel hilbert space. Journal of machine learning research 2, 97–123
work page 2001
-
[23]
Comparing support vector machines with gaussiankernelstoradialbasisfunctionclassifiers
Scholkopf,B.,Sung,K.K.,Burges,C.J.,Girosi,F.,Niyogi,P.,Poggio, T., Vapnik, V., 1997. Comparing support vector machines with gaussiankernelstoradialbasisfunctionclassifiers. IEEEtransactions on Signal Processing 45, 2758–2765
work page 1997
-
[24]
Shi, J., Sun, Z., Yu, L., Yang, X., Yan, Z., 2026. Addressing imbal- anced modal incompleteness in realistic multi-modal medical image segmentationviahierarchicalgradientalignment. IEEETransactions on Medical Imaging
work page 2026
-
[25]
Journal of Machine Learning Research 18, 1–38
Trouillon, T., Dance, C.R., Gaussier, É., Welbl, J., Riedel, S., Bouchard,G.,2017.Knowledgegraphcompletionviacomplextensor factorization. Journal of Machine Learning Research 18, 1–38
work page 2017
-
[26]
Sample based explana- tions via generalized representers
Tsai, C.P., Yeh, C.K., Ravikumar, P., 2023. Sample based explana- tions via generalized representers. Advances in Neural Information Processing Systems 36, 23485–23498
work page 2023
-
[27]
Ulku, I., Akagündüz, E., Ömer Özgür Tanrıöver, 2026. Robust multispectralsemanticsegmentationundermissingorfullmodalities via structured latent projection. URL:https://arxiv.org/abs/2604. 15856,arXiv:2604.15856
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Cross-band correlation-aware interactive fusion for multispectral images
Ulku, I., Ozgur Tanriover, O., Akagündüz, E., 2025. Cross-band correlation-aware interactive fusion for multispectral images. IEEE Geoscience and Remote Sensing Letters 22, 1–5
work page 2025
-
[29]
Wei, S., Luo, C., Luo, Y., 2023. Mmanet: Margin-aware distillation and modality-aware regularization for incomplete multimodal learn- ing,in:ProceedingsoftheIEEE/CVFconferenceoncomputervision and pattern recognition, pp. 20039–20049
work page 2023
-
[30]
Wen, L., Xiao, J., Liao, L., Chen, J., Wang, M., 2026. Charm: Collaborativeharmonizationacrossarbitrarymodalitiesformodality- agnosticsemanticsegmentation,in:ProceedingsoftheAAAIConfer- ence on Artificial Intelligence, pp. 10603–10611
work page 2026
-
[31]
Mad-mix: Multi-modal data mixturesvialatentspacecouplingforvision-languagemodeltraining
Xie, W., Tonin, F., Cevher, V., 2026. Mad-mix: Multi-modal data mixturesvialatentspacecouplingforvision-languagemodeltraining. arXiv preprint arXiv:2602.07790
-
[32]
IEEETransactionsonintelligenttransportationsystems 24, 14679–14694
Zhang, J., Liu, H., Yang, K., Hu, X., Liu, R., Stiefelhagen, R., 2023.Cmx:Cross-modalfusionforrgb-xsemanticsegmentationwith transformers. IEEETransactionsonintelligenttransportationsystems 24, 14679–14694
work page 2023
-
[33]
Zhang, Y., He, N., Yang, J., Li, Y., Wei, D., Huang, Y., Zhang, Y., He,Z.,Zheng,Y.,2022. mmformer:Multimodalmedicaltransformer for incomplete multimodal learning of brain tumor segmentation, in: Internationalconferenceonmedicalimagecomputingandcomputer- assisted intervention, Springer. pp. 107–117
work page 2022
-
[34]
Zhang, Z., Shu, D., Liao, C., Liu, C., Zhao, Y., Wang, R., Huang, X., Zhang, M., Gong, J., 2025. Flexisam: A flexible sam-based semanticsegmentationmodelforlandcoverclassificationusinghigh- resolution multimodal remote sensing imagery. ISPRS Journal of Photogrammetry and Remote Sensing 227, 594–612
work page 2025
-
[35]
Zhang, Z., Zhou, Y.J., Hu, Y., Ma, X., Yuan, Z., Wang, Z., Zhang, H., Xu, M., 2026. Disentangling for transfer: Boosting limited modalities via information-theoretic regularization and cross-modal reconstruction,in:ProceedingsoftheAAAIConferenceonArtificial Intelligence, pp. 13052–13060
work page 2026
-
[36]
Zheng,X.,Lyu,Y.,Jiang,L.,Paudel,D.P.,VanGool,L.,Hu,X.,2025. Reducing unimodal bias in multi-modal semantic segmentation with multi-scale functional entropy regularization, in: Proceedings of the IEEE/CVFInternationalConferenceonComputerVision,pp.21166– 21176
work page 2025
-
[37]
Zhou, Y., Ma, A., Wang, J., Chen, Z., Zhong, Y., 2026. Remote sensing meta modal representation for missing modality land cover mapping:Fromearthmissdatasettometarsmethod. RemoteSensing of Environment 333, 115132
work page 2026
-
[38]
Zhou, Y., Wang, Y., Su, J., Wen, Z., Zhang, P., Zhang, W., 2025. Emsnet: Efficient multimodal symmetric network for semantic seg- mentation of urban scene from remote sensing imagery. IEEE JournalofSelectedTopicsinAppliedEarthObservationsandRemote Sensing 18, 5878–5892. Irem Ulku received B.Sc. degrees in both Elec- tronics and Communication Engineering a...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.