How You Move Tells What You'll Do: Trajectory-Conditioned Egocentric Prediction
Pith reviewed 2026-05-21 07:10 UTC · model grok-4.3
The pith
Future camera trajectories encode operator intent to predict actions more accurately than language in egocentric video.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
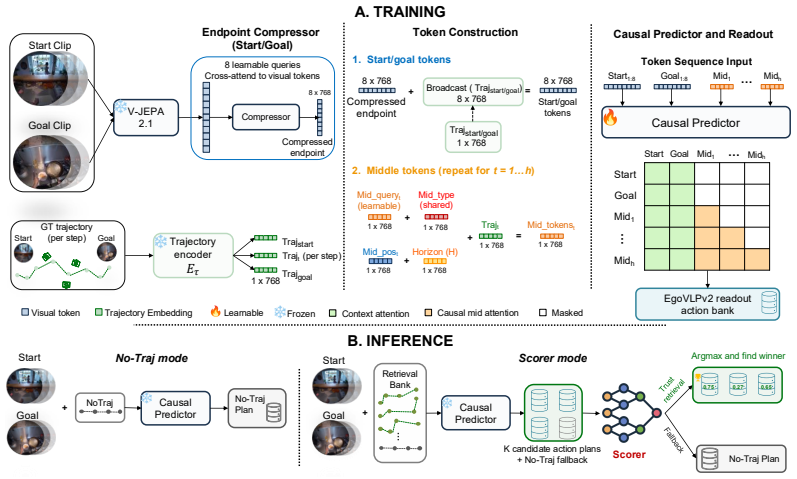
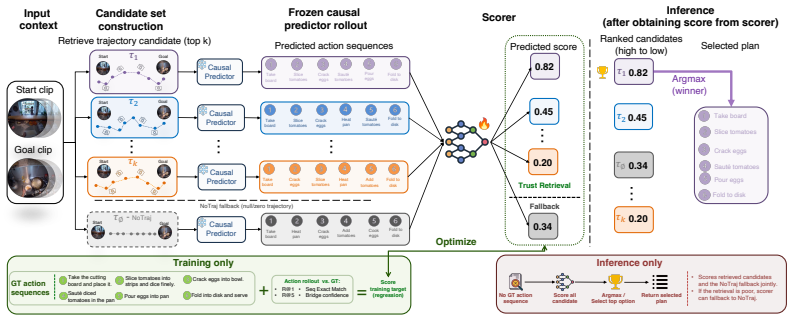
The future camera trajectory carries the operator's intent in a form fine enough to determine how an action will unfold, substantially outperforming language as a conditioning signal. This same intent makes the trajectory itself partially predictable from the context, so TrajPilot predicts candidate future trajectories from egocentric context and uses them to pilot action prediction in an action-aligned embedding space where language shapes the structure but is never used as a conditioning input.
What carries the argument
TrajPilot, which predicts candidate future trajectories from egocentric context and conditions action prediction on them within an action-aligned embedding space.
If this is right
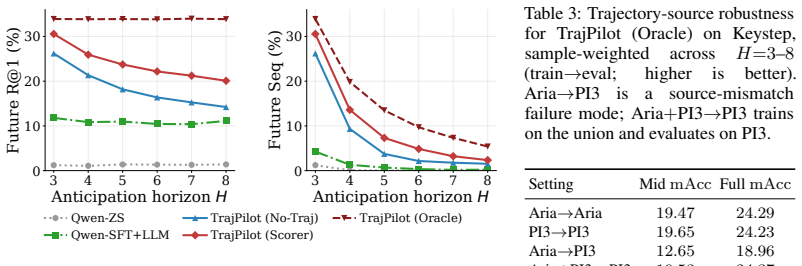
- Beats VLM and structured-planner baselines on procedural planning tasks across multiple egocentric datasets including Ego-Exo4D and Ego4D.
- The performance advantage over baselines increases as the prediction horizon lengthens.
- Maintains gains even when using RGB-only estimated camera poses instead of ground-truth trajectories.
- Enables goal-free anticipation that outperforms VLM baselines on Ego-Exo4D atomic tasks.
- Extends successfully to datasets like EPIC-Kitchens-100 and basketball shot-outcome prediction.
Where Pith is reading between the lines
- If head trajectories reliably signal intent, this could be used to anticipate user actions in augmented reality or assistive robotics without explicit commands.
- Trajectory conditioning might generalize to other video domains where motion paths disambiguate future events better than text descriptions.
- Models could be trained to jointly optimize trajectory prediction and action forecasting for better overall performance on long sequences.
Load-bearing premise
The future trajectory can be predicted sufficiently well from the current egocentric context that the model does not need the actual future trajectory provided at test time to achieve most of its improvement.
What would settle it
Training a variant of the model that uses randomly sampled or mean trajectories instead of predicted ones and finding no significant drop in action prediction accuracy would falsify the claim that predicted trajectories provide useful conditioning.
Figures






read the original abstract
Predicting how a person's first-person view will evolve (what action will follow, what plan completes a task, whether an in-progress shot will score) is fundamentally under-specified: the same context admits many plausible futures, and a model trained to minimize prediction error is forced to hedge or average across them, getting it wrong either way. Two findings shape our approach. First, the future camera trajectory, the path the head carves through space, lets the model commit to one of those futures: it carries the operator's intent in a form fine enough to determine how an action will unfold, substantially outperforming language as a conditioning signal. Second, this same intent makes the trajectory itself partially predictable from the context at hand, enough that trajectory need not be observed at test time to recover most of the gain. We instantiate these findings as TrajPilot, a model that predicts candidate future trajectories from egocentric context and uses them to pilot action prediction in an action-aligned embedding space where language shapes the structure but is never used as a conditioning input. TrajPilot beats VLM and structured-planner baselines on procedural planning across Ego-Exo4D atomic, Ego-Exo4D Keystep, Ego4D GoalStep, and EgoPER, with the trajectory advantage widening with horizon (exactly where prior planners collapse) and holding under RGB-only camera-pose estimation. With the goal masked at inference, the same model performs goal-free anticipation, beating VLM baselines on Ego-Exo4D atomic and extending to EPIC-Kitchens-100 and basketball shot-outcome prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TrajPilot, a model that predicts candidate future camera trajectories from egocentric video context and conditions downstream action prediction and procedural planning on those trajectories inside an action-aligned embedding space. It claims that trajectories encode operator intent more finely than language, yielding consistent gains over VLM and structured-planner baselines on Ego-Exo4D atomic, Ego-Exo4D Keystep, Ego4D GoalStep, and EgoPER; that the trajectory advantage widens with horizon; that the gains persist under RGB-only pose estimation; and that the same model supports goal-free anticipation on Ego-Exo4D, EPIC-Kitchens-100, and basketball shot-outcome prediction.
Significance. If the central claims are substantiated, the work would be significant for egocentric vision and action anticipation: it supplies a conditioning signal that demonstrably outperforms language for long-horizon procedural tasks where current planners degrade. The multi-dataset evaluation and the reported robustness to RGB-only pose estimation are concrete strengths. No machine-checked proofs or open reproducible code are mentioned, so the assessment rests entirely on the empirical results.
major comments (1)
- [Experiments / Results] The manuscript asserts that predicted trajectories recover most of the performance gain without test-time observation of the trajectory. However, no explicit ablation is presented that directly compares action-prediction accuracy when conditioning on ground-truth trajectories versus on the model's own predicted trajectories. This comparison is load-bearing for the second finding, especially because the reported advantage widens with horizon (where prediction error is expected to grow).
minor comments (1)
- [Method] The description of the action-aligned embedding space and how language shapes its structure without being used at inference could be expanded with a diagram or explicit equations in §3.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's significance and for the constructive feedback on the experimental design. We address the major comment below.
read point-by-point responses
-
Referee: The manuscript asserts that predicted trajectories recover most of the performance gain without test-time observation of the trajectory. However, no explicit ablation is presented that directly compares action-prediction accuracy when conditioning on ground-truth trajectories versus on the model's own predicted trajectories. This comparison is load-bearing for the second finding, especially because the reported advantage widens with horizon (where prediction error is expected to grow).
Authors: We agree that an explicit side-by-side comparison of action-prediction performance under ground-truth versus predicted trajectory conditioning is important to substantiate the claim that predicted trajectories recover most of the gain. The manuscript reports strong results with predicted trajectories and shows that the advantage over baselines grows with horizon, but does not include the direct GT-versus-predicted ablation requested. In the revised manuscript we will add this ablation, reporting action-prediction accuracy for both conditioning regimes across horizons on Ego-Exo4D and Ego4D GoalStep. This will quantify how much performance is retained when the model must rely on its own trajectory predictions. revision: yes
Circularity Check
No circularity: learned predictors and empirical ablations remain independent of inputs
full rationale
The paper trains TrajPilot to predict future trajectories from egocentric context and then conditions action prediction on those outputs in an embedding space shaped by language but without using language as conditioning. Both the trajectory predictor and the downstream action model are trained end-to-end on data; no equation defines the output as a direct function of the input by construction, no parameter is fitted on a subset and then renamed a prediction, and no load-bearing claim rests on a self-citation whose content is unverified. Experiments compare against VLM and planner baselines across multiple datasets and horizons, with the advantage claimed to persist under predicted (not ground-truth) trajectories. This structure is self-contained and externally falsifiable.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
future camera trajectory... carries the operator's intent in a form fine enough to determine how an action will unfold, substantially outperforming language as a conditioning signal
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TrajPilot... predicts candidate future trajectories from egocentric context and uses them to pilot action prediction in an action-aligned embedding space
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Self-supervised learning from images with a joint- embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint- embedding predictive architecture. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
work page 2023
-
[2]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mahmoud Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Mojtaba Komeili, et al. V-JEPA 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Anurag Bagchi, Zhipeng Bao, Homanga Bharadhwaj, Yu-Xiong Wang, Pavel Tokmakov, and Martial Hebert. Walk through paintings: Ego-centric world models from internet priors.arXiv preprint arXiv:2601.15284, 2026
-
[4]
Whole- body conditioned egocentric video prediction
Yutong Bai, Danny Tran, Amir Bar, Yann LeCun, Trevor Darrell, and Jitendra Malik. Whole- body conditioned egocentric video prediction. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. arXiv:2506.21552
-
[5]
Amir Bar, Gaoyue Zhou, Danny Tran, Trevor Darrell, and Yann LeCun. Navigation world mod- els. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15791–15801, 2025
work page 2025
-
[6]
Revisiting Feature Prediction for Learning Visual Representations from Video
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual repre- sentations from video.arXiv preprint arXiv:2404.08471, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Procedure planning in instructional videos
Chien-Yi Chang, De-An Huang, Danfei Xu, Ehsan Adeli, Li Fei-Fei, and Juan Carlos Niebles. Procedure planning in instructional videos. InEuropean Conference on Computer Vision (ECCV), 2020
work page 2020
-
[8]
Planning with reasoning using vision language world model.arXiv preprint arXiv:2509.02722, 2025
Delong Chen, Théo Moutakanni, Willy Chung, Yejin Bang, Ziwei Ji, Allen Bolourchi, and Pascale Fung. Planning with reasoning using vision language world model.arXiv preprint arXiv:2509.02722, 2025
-
[9]
arXiv preprint arXiv:2512.10942 (2025)
Delong Chen, Mustafa Shukor, Theo Moutakanni, Willy Chung, Jade Yu, Tejaswi Kasarla, Allen Bolourchi, Yann LeCun, and Pascale Fung. VL-JEPA: Joint embedding predictive architecture for vision-language.arXiv preprint arXiv:2512.10942, 2025
-
[10]
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, et al. Rescaling egocentric vision: Collection, pipeline and challenges for EPIC-Kitchens-100.International Journal of Computer Vision, 130:33–55, 2022
work page 2022
-
[11]
Anticipative video transformer
Rohit Girdhar and Kristen Grauman. Anticipative video transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 13505–13515, 2021
work page 2021
-
[12]
Ego-Exo4D: Understanding skilled human activity from first- and third-person perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, et al. Ego-Exo4D: Understanding skilled human activity from first- and third-person perspectives. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[13]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Mariam Hassan, Sebastian Stapf, Ahmad Rahimi, Pedro M B Rezende, Yasaman Haghighi, David Brüggemann, Isinsu Katircioglu, Lin Zhang, Xiaoran Chen, Suman Saha, Marco Cannici, et al. GEM: A generalizable ego-vision multimodal world model for fine-grained ego-motion, object dynamics, and scene composition control.arXiv preprint arXiv:2412.11198, 2024
-
[15]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Error detection in egocentric procedural task videos
Shih-Po Lee, Zijia Lu, and Kristen Grauman. Error detection in egocentric procedural task videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2024. 10
work page 2024
-
[17]
VEDiT: Latent prediction architecture for procedural video representation learning
Han Lin, Tushar Nagarajan, Nicolas Ballas, Mahmoud Assran, Mojtaba Komeili, Mohit Bansal, and Koustuv Sinha. VEDiT: Latent prediction architecture for procedural video representation learning. InInternational Conference on Learning Representations (ICLR), 2025
work page 2025
-
[18]
Himangi Mittal, Nakul Agarwal, Shao-Yuan Lo, and Kwonjoon Lee. Can’t make an omelette without breaking some eggs: Plausible action anticipation using large video-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[19]
Lorenzo Mur-Labadia, Matthew Muckley, Amir Bar, Mahmoud Assran, Koustuv Sinha, Michael Rabbat, Yann LeCun, Nicolas Ballas, and Adrien Bardes. V-JEPA 2.1: Unlocking dense features in video self-supervised learning.arXiv preprint arXiv:2603.14482, 2026
-
[20]
Yulei Niu, Wenliang Guo, Long Chen, Xudong Lin, and Shih-Fu Chang. SCHEMA: State CHangEs MAtter for procedure planning in instructional videos. InInternational Conference on Learning Representations (ICLR), 2024. arXiv:2403.01599
-
[21]
Cosmos World Foundation Model Platform for Physical AI
NVIDIA. Cosmos world foundation model technical report.arXiv preprint arXiv:2501.03575, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
EgoVLPv2: Egocentric video-language pre- training with fusion in the backbone
Shraman Pramanick, Yale Song, Sayan Nag, Kevin Qinghong Lin, Hardik Shah, Mike Zheng Shou, Rama Chellappa, and Pengchuan Zhang. EgoVLPv2: Egocentric video-language pre- training with fusion in the backbone. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
work page 2023
-
[23]
Interaction region visual trans- former for egocentric action anticipation
Debaditya Roy, Ramanathan Rajendiran, and Basura Fernando. Interaction region visual trans- former for egocentric action anticipation. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2024
work page 2024
-
[24]
Luigi Seminara, Davide Moltisanti, and Antonino Furnari. ViterbiPlanNet: Injecting procedural knowledge via differentiable Viterbi for planning in instructional videos, 2026
work page 2026
-
[25]
Ego4D Goal-Step: Toward hierarchical understanding of procedural activities
Yale Song, Eugene Byrne, Tushar Nagarajan, Huiyu Wang, Roberto Martín-Martín, and Lorenzo Torresani. Ego4D Goal-Step: Toward hierarchical understanding of procedural activities. In Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2023
work page 2023
-
[26]
EgoDistill: Egocentric head motion distillation for efficient video understanding
Shuhan Tan, Tushar Nagarajan, and Kristen Grauman. EgoDistill: Egocentric head motion distillation for efficient video understanding. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[27]
COIN: A large-scale dataset for comprehensive instructional video analysis
Yansong Tang, Dajun Ding, Yongming Rao, Yu Zheng, Danyang Zhang, Lili Zhao, Jiwen Lu, and Jie Zhou. COIN: A large-scale dataset for comprehensive instructional video analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019
work page 2019
-
[28]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Informa- tion Processing Systems (NeurIPS), volume 30, 2017
work page 2017
-
[29]
PDPP: Projected diffusion for procedure planning in instructional videos
Hanlin Wang, Yilu Wu, Sheng Guo, and Limin Wang. PDPP: Projected diffusion for procedure planning in instructional videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14836–14845, 2023
work page 2023
-
[30]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, and Tong He. Scalable permutation-equivariant visual geometry learning.arXiv preprint arXiv:2507.13347, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Seeing without pixels: Perception from camera trajectories.arXiv preprint arXiv:2511.21681, 2025
Zihui Xue, Kristen Grauman, Dima Damen, Andrew Zisserman, and Tengda Han. Seeing without pixels: Perception from camera trajectories.arXiv preprint arXiv:2511.21681, 2025
-
[32]
Video-LLaMA: An instruction-tuned audio-visual language model for video understanding
Hang Zhang, Xin Li, and Lidong Bing. Video-LLaMA: An instruction-tuned audio-visual language model for video understanding. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 2023. 11
work page 2023
-
[33]
GeoWorld: Geometric World Models
Zeyu Zhang, Danning Li, Ian Reid, and Richard Hartley. GeoWorld: Geometric world models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026. arXiv:2602.23058
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Dimitri Zhukov, Jean-Baptiste Alayrac, Ramazan Gokberk Cinbis, David Fouhey, Ivan Laptev, and Josef Sivic. Cross-task weakly supervised learning from instructional videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019. 12 A Implementation details A.1 Datasets Ego-Exo4D atomic.We use the open-vocabulary Eg...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.