PlanRAG-Audio: Planning and Retrieval Augmented Generation for Long-form Audio Understanding
Pith reviewed 2026-05-21 06:51 UTC · model grok-4.3
The pith
PlanRAG-Audio plans required modalities and time spans then retrieves only relevant segments to improve accuracy on long audio.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
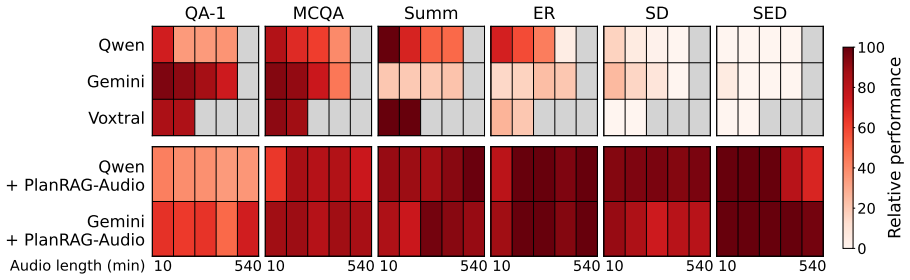
PlanRAG-Audio is a planning-based retrieval-augmented generation framework that explicitly plans which modalities and temporal spans are required for a given query and retrieves only query-relevant information from a structured text and audio database rather than processing entire recordings directly. This retrieval planning enables effective reasoning over complex, cross-domain audio queries while substantially reducing the input length passed to the large language models. Experiments show improved reasoning accuracy and stabilized performance as audio duration increases by decoupling inference cost from raw audio length.
What carries the argument
The explicit planning of modalities and temporal spans followed by targeted retrieval from a structured text and audio database.
Load-bearing premise
The structured database must contain every query-relevant acoustic cue and the planning step must correctly select the needed modalities and time spans without leaving out critical details.
What would settle it
A set of queries where the planner omits a time span containing a decisive sound event or emotion and the model then gives wrong answers that a full-audio baseline would have answered correctly.
Figures


read the original abstract
Long-form audio understanding poses significant challenges for large audio language models (LALMs) due to the extreme length of audio sequences and the need to reason over heterogeneous acoustic cues distributed over time, such as speech content, speaker identity, emotion, and sound events. To address these challenges, we propose \textbf{PlanRAG-Audio}, a planning-based retrieval-augmented generation framework for scalable long-form audio understanding. Rather than having audio LALMs process entire recordings directly, PlanRAG-Audio explicitly plans which modalities and temporal spans are required for a given query, and retrieves only query-relevant information from a structured text and audio database. This retrieval planning enables effective reasoning over complex, cross-domain audio queries while substantially reducing the input length passed to the large language models. Experiments across a wide range of speech/audio retrieval demonstrate that PlanRAG-Audio improves reasoning accuracy and stabilizes performance as audio duration increases by decoupling inference cost from raw audio length.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PlanRAG-Audio, a planning-based retrieval-augmented generation framework for long-form audio understanding. Instead of feeding entire recordings to large audio language models (LALMs), the method explicitly plans which modalities and temporal spans are needed for a query, retrieves only the relevant information from a structured text and audio database, and performs reasoning on the reduced context. The central claim is that this improves reasoning accuracy and stabilizes performance as audio duration grows by decoupling inference cost from raw audio length.
Significance. If the planning step reliably recovers all query-relevant acoustic cues (speech content, speaker identity, emotion, sound events) distributed over time, the framework would provide a practical route to scalable long-form audio reasoning without quadratic growth in context length. The approach is procedurally novel in its explicit modality-and-span planning layer, but its impact hinges on empirical verification of that layer.
major comments (2)
- [Abstract] Abstract: the claim that experiments 'demonstrate accuracy gains and stabilized performance' is unsupported by any reported baselines, datasets, metrics, controls, or statistical tests. Without these details it is impossible to determine whether the observed improvements are attributable to the planning-retrieval mechanism or to other factors.
- [Method / Experiments] Method and Experiments sections: the headline accuracy and stability improvements rest on the planner correctly identifying all query-relevant modalities and temporal spans. The manuscript provides no implementation details for the planning module, no error analysis of planner omissions, and no ablation that measures recall of ground-truth relevant segments. If even one critical cue (e.g., a brief overlapping sound event) is missed, the subsequent retrieval supplies incomplete context that the LALM reasoning step cannot recover.
minor comments (2)
- [Method] Clarify how the structured database is constructed and indexed, including the exact representation of acoustic cues and the retrieval mechanism (e.g., embedding model, similarity metric).
- [Experiments] Figure captions and experimental tables should explicitly state the audio durations tested and the number of queries per duration bin to allow readers to assess the 'stabilization with duration' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review of our manuscript on PlanRAG-Audio. We have carefully considered the major comments and provide point-by-point responses below. Where the comments identify areas needing clarification or additional analysis, we outline specific revisions that will be incorporated into the next version of the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that experiments 'demonstrate accuracy gains and stabilized performance' is unsupported by any reported baselines, datasets, metrics, controls, or statistical tests. Without these details it is impossible to determine whether the observed improvements are attributable to the planning-retrieval mechanism or to other factors.
Authors: We agree that the abstract, due to its length constraints, does not explicitly list the experimental details. In the revised manuscript we will update the abstract to briefly reference the evaluation datasets, the primary metrics (accuracy and stability measures), the baseline methods compared against, and note that improvements are statistically significant. The full experimental protocol, controls, and results remain in the Experiments section; the abstract revision will better anchor the high-level claim to the reported evidence. revision: yes
-
Referee: [Method / Experiments] Method and Experiments sections: the headline accuracy and stability improvements rest on the planner correctly identifying all query-relevant modalities and temporal spans. The manuscript provides no implementation details for the planning module, no error analysis of planner omissions, and no ablation that measures recall of ground-truth relevant segments. If even one critical cue (e.g., a brief overlapping sound event) is missed, the subsequent retrieval supplies incomplete context that the LALM reasoning step cannot recover.
Authors: This is a fair and important observation. The effectiveness of PlanRAG-Audio indeed depends on the planner's ability to surface all necessary cues. In the revised version we will expand the Method section with concrete implementation details of the planning module (including the prompting strategy and decision criteria for modality and span selection). We will also add a dedicated error analysis of planner omissions together with an ablation that reports recall of ground-truth relevant segments. These additions will directly quantify the planner's reliability and address the risk of missing critical acoustic cues. revision: yes
Circularity Check
No circularity: procedural framework with experimental claims
full rationale
The paper introduces PlanRAG-Audio as an explicit planning-plus-retrieval procedure that selects modalities and temporal spans before querying a structured database, then feeds the results to an LALM. No equations, fitted parameters, or self-referential definitions appear in the provided text. Performance improvements are asserted via experiments rather than derived from prior fits or self-citations. The central claim therefore remains independent of its own inputs and does not reduce by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A structured text and audio database exists that stores query-relevant information extractable without loss of critical cues.
invented entities (1)
-
PlanRAG-Audio planning module
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PlanRAG-Audio explicitly plans which modalities and temporal spans are required for a given query, and retrieves only query-relevant information from a structured text and audio database.
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the system first plans which modalities (e.g., spoken content, speaker information, emotional cues, and non-verbal acoustic events), temporal spans, and constraints are required
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
- [2]
- [3]
-
[4]
SpeechVerse: A Large-scale Generalizable Audio Framework , author =. arXiv preprint arXiv:2405.08295 , year =
-
[5]
Qwen2-Audio Technical Report , author =. arXiv preprint arXiv:2407.10759 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
Audio Flamingo: A Novel Audio Language Model with Few-Shot Learning and Dialogue Abilities , author =. Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
-
[7]
Moshi: a speech‐text foundation model for real‐time dialogue , author =. 2024 , eprint=
work page 2024
-
[8]
SALMONN-omni: A Standalone Speech LLM without Codec Injection for Full-duplex Conversation , author =. 2025 , eprint=
work page 2025
-
[9]
Jinchuan Tian and William Chen and Yifan Peng and Jiatong Shi and Siddhant Arora and Shikhar Bharadwaj and Takashi Maekaku and Yusuke Shinohara and Keita Goto and Xiang Yue and Huck Yang and Shinji Watanabe , year =
- [10]
-
[11]
M eeting QA : Extractive Question-Answering on Meeting Transcripts
Prasad, Archiki and Bui, Trung and Yoon, Seunghyun and Deilamsalehy, Hanieh and Dernoncourt, Franck and Bansal, Mohit. M eeting QA : Extractive Question-Answering on Meeting Transcripts. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023
work page 2023
-
[12]
Shankar, Natarajan Balaji and Johnson, Alexander and Chance, Christina and Veeramani, Hariram and Alwan, Abeer , booktitle=. CORAAL QA: A Dataset and Framework for Open Domain Spontaneous Speech Question Answering from Long Audio Files , year=
-
[13]
W av RAG : Audio-Integrated Retrieval Augmented Generation for Spoken Dialogue Models
Chen, Yifu and Ji, Shengpeng and Wang, Haoxiao and Wang, Ziqing and Chen, Siyu and He, Jinzheng and Xu, Jin and Zhao, Zhou. W av RAG : Audio-Integrated Retrieval Augmented Generation for Spoken Dialogue Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025
work page 2025
-
[14]
Alexander Johnson and Peter Plantinga and Pheobe Sun and Swaroop Gadiyaram and Abenezer Girma and Ahmad Emami , year =
-
[15]
Cacophony: An Improved Contrastive Audio-Text Model , year=
Zhu, Ge and Darefsky, Jordan and Duan, Zhiyao , journal=. Cacophony: An Improved Contrastive Audio-Text Model , year=
-
[16]
NAAQA: A Neural Architecture for Acoustic Question Answering , year=
Abdelnour, Jérôme and Rouat, Jean and Salvi, Giampiero , journal=. NAAQA: A Neural Architecture for Acoustic Question Answering , year=
-
[17]
DUAL: Discrete Spoken Unit Adaptive Learning for Textless Spoken Question Answering , author =. 2022 , booktitle =
work page 2022
-
[18]
31st European Signal Processing Conference (EUSIPCO) , year =
Parthasaarathy Sudarsanam and Tuomas Virtanen , title =. 31st European Signal Processing Conference (EUSIPCO) , year =
-
[19]
Peng, Yifan and Sudo, Yui and Shakeel, Muhammad and Watanabe, Shinji. OWSM - CTC : An Open Encoder-Only Speech Foundation Model for Speech Recognition, Translation, and Language Identification. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024
work page 2024
-
[20]
Yifan Peng and Muhammad Shakeel and Yui Sudo and William Chen and Jinchuan Tian and Chyi-Jiunn Lin and Shinji Watanabe , year =
-
[21]
HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units , year=
Hsu, Wei-Ning and Bolte, Benjamin and Tsai, Yao-Hung Hubert and Lakhotia, Kushal and Salakhutdinov, Ruslan and Mohamed, Abdelrahman , journal=. HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units , year=
-
[22]
WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing , year=
Chen, Sanyuan and Wang, Chengyi and Chen, Zhengyang and Wu, Yu and Liu, Shujie and Chen, Zhuo and Li, Jinyu and Kanda, Naoyuki and Yoshioka, Takuya and Xiao, Xiong and Wu, Jian and Zhou, Long and Ren, Shuo and Qian, Yanmin and Qian, Yao and Wu, Jian and Zeng, Michael and Yu, Xiangzhan and Wei, Furu , journal=. WavLM: Large-Scale Self-Supervised Pre-Traini...
-
[23]
Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya , title =. 2023 , publisher =
work page 2023
-
[24]
Chen, Sanyuan and Wu, Yu and Wang, Chengyi and Liu, Shujie and Tompkins, Daniel and Chen, Zhuo and Che, Wanxiang and Yu, Xiangzhan and Wei, Furu , booktitle =. 2023 , series =
work page 2023
-
[25]
Clap learning audio concepts from natural language supervision , author=. ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , year=
work page 2023
-
[26]
Lawrence and Girshick, Ross , booktitle=
Johnson, Justin and Hariharan, Bharath and van der Maaten, Laurens and Fei-Fei, Li and Zitnick, C. Lawrence and Girshick, Ross , booktitle=. CLEVR: A Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning , year=
-
[27]
CLEAR: A Dataset for Compositional Language and Elementary Acoustic Reasoning , year =
Jerome Abdelnour and Giampiero Salvi and Jean Rouat , publisher =. CLEAR: A Dataset for Compositional Language and Elementary Acoustic Reasoning , year =
-
[28]
Clotho-AQA: A Crowdsourced Dataset for Audio Question Answering , year=
Lipping, Samuel and Sudarsanam, Parthasaarathy and Drossos, Konstantinos and Virtanen, Tuomas , booktitle=. Clotho-AQA: A Crowdsourced Dataset for Audio Question Answering , year=
-
[29]
Audiopedia: Audio QA with Knowledge , year=
Penamakuri, Abhirama Subramanyam and Chhatre, Kiran and Jain, Akshat , booktitle=. Audiopedia: Audio QA with Knowledge , year=
-
[30]
AudioBERT: Audio Knowledge Augmented Language Model , year=
Ok, Hyunjong and Yoo, Suho and Lee, Jaeho , booktitle=. AudioBERT: Audio Knowledge Augmented Language Model , year=
-
[31]
Sanabria, Ramon and Caglayan, Ozan and Palaskar, Shruti and Elliott, Desmond and Barrault, Lo\"ic and Specia, Lucia and Metze, Florian , booktitle =. 2018 , organization=
work page 2018
-
[32]
MeetingQA: Extractive Question-Answering on Meeting Transcripts , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[33]
Garofolo, John S. and Auzanne, Cedric G. P. and Voorhees, Ellen M. , title =. 2000 , booktitle =
work page 2000
-
[34]
Stream RAG: Instant and Accurate Spoken Dialogue Systems with Streaming Tool Usage , author=. 2025 , eprint=
work page 2025
-
[35]
Kong, Qiuqiang and Cao, Yin and Iqbal, Turab and Wang, Yuxuan and Wang, Wenwu and Plumbley, Mark D. , journal=. PANNs: Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition , year=
-
[36]
SpeechDPR: End-To-End Spoken Passage Retrieval For Open-Domain Spoken Question Answering , year=
Lin, Chyi-Jiunn and Lin, Guan-Ting and Chuang, Yung-Sung and Wu, Wei-Lun and Li, Shang-Wen and Mohamed, Abdelrahman and Lee, Hung-Yi and Lee, Lin-Shan , booktitle=. SpeechDPR: End-To-End Spoken Passage Retrieval For Open-Domain Spoken Question Answering , year=
-
[37]
Speech Retrieval-Augmented Generation without Automatic Speech Recognition , year=
Min, Do June and Mundnich, Karel and Lapastora, Andy and Soltanmohammadi, Erfan and Ronanki, Srikanth and Han, Kyu , booktitle=. Speech Retrieval-Augmented Generation without Automatic Speech Recognition , year=
-
[38]
AURA: Agent for Understanding, Reasoning, and Automated Tool Use in Voice-Driven Tasks , author=. 2025 , eprint=
work page 2025
-
[39]
Semnani, Sina and Yao, Violet and Zhang, Heidi and Lam, Monica. W iki C hat: Stopping the Hallucination of Large Language Model Chatbots by Few-Shot Grounding on W ikipedia. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023
work page 2023
-
[40]
Akari Asai and Zeqiu Wu and Yizhong Wang and Avirup Sil and Hannaneh Hajishirzi , booktitle=. Self-
-
[41]
RA - ISF : Learning to Answer and Understand from Retrieval Augmentation via Iterative Self-Feedback
Liu, Yanming and Peng, Xinyue and Zhang, Xuhong and Liu, Weihao and Yin, Jianwei and Cao, Jiannan and Du, Tianyu. RA - ISF : Learning to Answer and Understand from Retrieval Augmentation via Iterative Self-Feedback. Findings of the Association for Computational Linguistics: ACL 2024. 2024
work page 2024
-
[42]
Myeonghwa Lee and Seonho An and Kim, \ Min Soo\. PlanRAG: A Plan-then-Retrieval Augmented Generation for Generative Large Language Models as Decision Makers. 2024
work page 2024
-
[43]
Prakhar Verma and Sukruta Prakash Midigeshi and Gaurav Sinha and Arno Solin and Nagarajan Natarajan and Amit Sharma , booktitle=. Plan\
-
[44]
Liu, Heng and Jiang, Siru and Duan, Fangyun and Lyu, Yongzhe and Wang, Xiusong and Ge, Hanlin and Liang, Chao , booktitle=. CadenceRAG: Context-Aware and Dependency-Enhanced Retrieval Augmented Generation for Holistic Video Understanding , year=
-
[45]
Librispeech: An ASR corpus based on public domain audio books , year=
Panayotov, Vassil and Chen, Guoguo and Povey, Daniel and Khudanpur, Sanjeev , booktitle=. Librispeech: An ASR corpus based on public domain audio books , year=
-
[46]
Zhao, Zihan and Jiang, Yiyang and Liu, Heyang and Wang, Yu and Wang, Yanfeng , journal=. LibriSQA: A Novel Dataset and Framework for Spoken Question Answering with Large Language Models , year=
- [47]
-
[48]
Wang, Changhan and Riviere, Morgane and Lee, Ann and Wu, Anne and Talnikar, Chaitanya and Haziza, Daniel and Williamson, Mary and Pino, Juan and Dupoux, Emmanuel. V ox P opuli: A Large-Scale Multilingual Speech Corpus for Representation Learning, Semi-Supervised Learning and Interpretation. Proceedings of the 59th Annual Meeting of the Association for Com...
work page 2021
-
[49]
Gemmeke, Jort F. and Ellis, Daniel P. W. and Freedman, Dylan and Jansen, Aren and Lawrence, Wade and Moore, R. Channing and Plakal, Manoj and Ritter, Marvin , booktitle=. Audio Set: An ontology and human-labeled dataset for audio events , year=
-
[50]
Retrieval-augmented generation for knowledge-intensive NLP tasks , year =
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K\". Retrieval-augmented generation for knowledge-intensive NLP tasks , year =. Proceedings of the 34th International Conference on Neural Information Processing Systems , series =
-
[51]
I. McCowan and J. Carletta and W. Kraaij and S. Ashby and S. Bourban and M. Flynn and M. Guillemot and T. Hain and J. Kadlec and V. Karaiskos and M. Kronenthal and G. Lathoud and M. Lincoln and A. Lisowska and W. Post and Dennis Reidsma and P. Wellner. The AMI meeting corpus. Proceedings of Measuring Behavior 2005, 5th International Conference on Methods ...
work page 2005
-
[52]
Odyssey 2024 - Speech Emotion Recognition Challenge: Dataset, Baseline Framework, and Results , author =. 2024 , booktitle =
work page 2024
-
[53]
Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya , title =
- [54]
-
[55]
Text Embeddings by Weakly-Supervised Contrastive Pre-training , author=. 2024 , eprint=
work page 2024
-
[56]
E mo2 V ec: Learning Generalized Emotion Representation by Multi-task Training
Xu, Peng and Madotto, Andrea and Wu, Chien-Sheng and Park, Ji Ho and Fung, Pascale. E mo2 V ec: Learning Generalized Emotion Representation by Multi-task Training. Proceedings of the 9th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis. 2018
work page 2018
-
[57]
Metrics for Polyphonic Sound Event Detection
Mesaros, Annamaria and Heittola, Toni and Virtanen, Tuomas. Metrics for Polyphonic Sound Event Detection. Applied Sciences. 2016
work page 2016
-
[58]
Alexis Plaquet and Hervé Bredin , title=
-
[59]
OpenBEATs: A Fully Open-Source General-Purpose Audio Encoder , year=
Bharadwaj, Shikhar and Cornell, Samuele and Choi, Kwanghee and Fukayama, Satoru and Shim, Hye-Jin and Deshmukh, Soham and Watanabe, Shinji , booktitle=. OpenBEATs: A Fully Open-Source General-Purpose Audio Encoder , year=
-
[60]
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author=. 2025 , eprint=
work page 2025
- [61]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.