Lighting-aware Unified Model for Instance Segmentation
Pith reviewed 2026-05-21 07:00 UTC · model grok-4.3
The pith
A contrast-map adapter makes instance segmentation robust to real-world lighting without retraining the backbone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
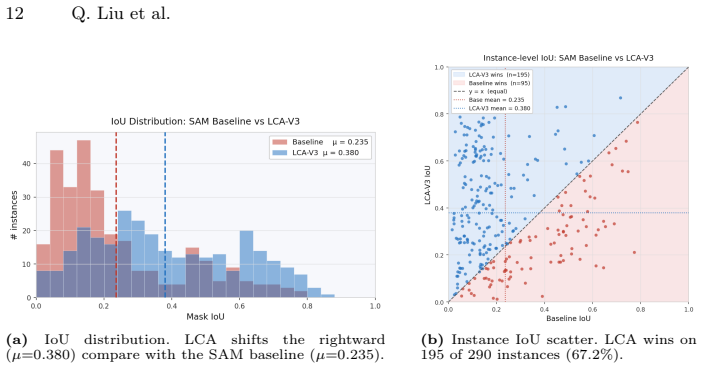
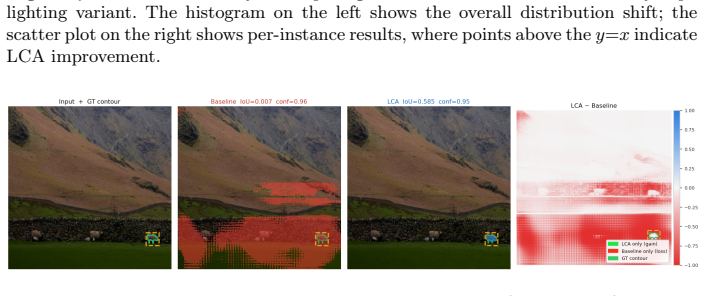
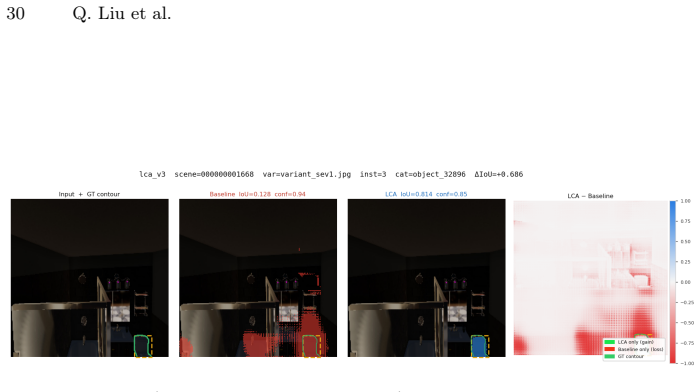
Lighting Convolutional-Attention (LCA) is an adapter module with a dual-branch architecture that processes RGB features alongside contrast maps. It is optimized through a pairwise training strategy that introduces a targeted loss term penalizing discrepancies between clean images and their illumination variants. A novel Unity-based synthetic dataset replicates complex real-world lighting conditions to support training and evaluation of the architecture.
What carries the argument
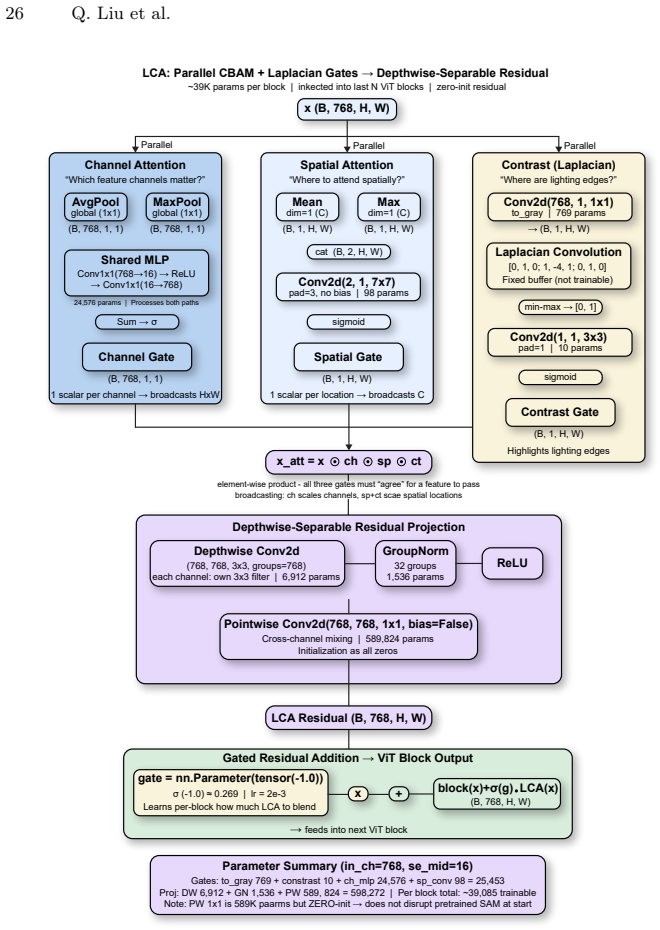
Lighting Convolutional-Attention (LCA) adapter, a dual-branch module that combines RGB features with contrast maps to produce lighting-invariant representations for the segmentation head.
If this is right
- The adapter delivers superior lighting-robust instance segmentation on multiple existing benchmarks.
- The method bridges the domain gap between synthetic lighting variants and real-world illumination conditions.
- Performance gains occur without any fine-tuning of the underlying heavy foundation-model backbone.
Where Pith is reading between the lines
- Contrast-map branches could be added to other vision tasks such as detection or depth estimation to gain similar lighting invariance.
- The pairwise training approach may reduce the volume of real-world annotated data needed when adapting models to new environments.
- Deployment in outdoor robotics or autonomous vehicles could become more reliable if the adapter proves stable across seasons and weather.
Load-bearing premise
The contrast maps enable physically motivated sensitivity to structural changes rather than illumination artifacts, allowing the dual-branch architecture to generalize from synthetic lighting variants to real-world conditions.
What would settle it
A clear drop in segmentation accuracy on real captured images whose lighting conditions fall outside the range simulated in the Unity dataset would show that the claimed generalization does not hold.
Figures




















read the original abstract
Foundation models like the Segment Anything Model (SAM) demonstrate impressive zero-shot generalization but frequently degrade under diverse real-world illumination, particularly for instance segmentation. In this work, we address this limitation by developing \textit{Lighting Convolutional-Attention (\lca{})}, an adapter module that enhances segmentation robustness without fine-tuning the heavy backbone. \lca{} employs a dual-branch architecture to process RGB features alongside contrast maps, enabling physically motivated sensitivity to structural changes rather than illumination artifacts. We optimize \lca{} through a pairwise training strategy, introducing a targeted loss term that explicitly penalizes discrepancies between clean images and their corresponding illumination variants. To evaluate and support this architecture, we conduct a comprehensive empirical study across multiple existing benchmarks and present a novel Unity-based synthetic dataset specifically designed to accurately replicate complex real-world lighting conditions. Extensive experimental results demonstrate that our approach successfully bridges the domain gap, delivering superior lighting-robust segmentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Lighting Convolutional-Attention (LCA) adapter module to improve the lighting robustness of foundation models such as SAM for instance segmentation. LCA uses a dual-branch architecture that processes RGB features together with contrast maps, is trained via a pairwise strategy with a loss that penalizes discrepancies between clean images and their illumination variants, and is evaluated on existing benchmarks plus a new Unity-generated synthetic dataset designed to replicate complex real-world lighting.
Significance. If the reported gains hold under scrutiny, the work would provide a practical, lightweight adaptation strategy for making segmentation models more reliable under uncontrolled illumination without retraining the backbone. The new synthetic dataset could serve as a useful resource for the community studying domain gaps induced by lighting.
major comments (3)
- [§3.2] §3.2 (LCA architecture): The claim that contrast maps enable 'physically motivated sensitivity to structural changes rather than illumination artifacts' is central to the dual-branch design but is presented without a derivation, photometric justification, or explicit formula for how the contrast map is computed from the input; this leaves the physical motivation as an assumption rather than a demonstrated property.
- [§4] §4 (Experiments): While the abstract and introduction assert 'extensive experimental results' and 'superior lighting-robust segmentation' across benchmarks, the manuscript provides no quantitative metrics, error bars, statistical tests, or dataset statistics in the summary sections; without these, the magnitude and reliability of the claimed domain-gap bridging cannot be assessed.
- [§3.3] §3.3 (Pairwise training): The targeted loss term that penalizes discrepancies between clean and illumination-variant pairs is load-bearing for the training strategy, yet the manuscript does not specify its exact functional form, weighting relative to the segmentation loss, or ablation isolating its contribution versus the contrast-map branch alone.
minor comments (3)
- [§3] The notation for the LCA module and its components should be introduced with a clear diagram or pseudocode early in §3 to aid readability.
- [Figure 3] Figure captions for the synthetic dataset examples should explicitly state the range of lighting parameters varied (e.g., light source positions, intensities) so readers can judge how well they approximate real-world conditions.
- [§2] A few references to prior work on contrast-based illumination invariance (e.g., in photometric stereo or Retinex theory) appear to be missing from the related-work section.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, clarifying aspects of the manuscript and outlining the revisions we will make.
read point-by-point responses
-
Referee: [§3.2] §3.2 (LCA architecture): The claim that contrast maps enable 'physically motivated sensitivity to structural changes rather than illumination artifacts' is central to the dual-branch design but is presented without a derivation, photometric justification, or explicit formula for how the contrast map is computed from the input; this leaves the physical motivation as an assumption rather than a demonstrated property.
Authors: We agree that the physical motivation benefits from explicit support. The contrast map is intended to emphasize local structural variations by normalizing against local intensity statistics. In the revised manuscript we will add the precise computation formula for the contrast map, a short derivation drawing on photometric principles of local contrast, and an explanation of why this formulation reduces sensitivity to global illumination shifts while preserving edge and texture information. revision: yes
-
Referee: [§4] §4 (Experiments): While the abstract and introduction assert 'extensive experimental results' and 'superior lighting-robust segmentation' across benchmarks, the manuscript provides no quantitative metrics, error bars, statistical tests, or dataset statistics in the summary sections; without these, the magnitude and reliability of the claimed domain-gap bridging cannot be assessed.
Authors: We acknowledge that the abstract and introduction currently lack numerical summaries. The full experimental section and supplementary material already contain mAP / mIoU tables with standard deviations across multiple runs, statistical significance tests, and statistics for the Unity dataset (image count, lighting variation parameters). In the revision we will insert concise quantitative highlights and dataset descriptors into the abstract and introduction so that the claimed improvements are immediately quantifiable. revision: yes
-
Referee: [§3.3] §3.3 (Pairwise training): The targeted loss term that penalizes discrepancies between clean and illumination-variant pairs is load-bearing for the training strategy, yet the manuscript does not specify its exact functional form, weighting relative to the segmentation loss, or ablation isolating its contribution versus the contrast-map branch alone.
Authors: We thank the referee for noting this omission. The targeted loss is a pairwise discrepancy term between feature representations of clean and illumination-augmented images. In the revised §3.3 we will state its exact functional form as an equation, specify the relative weighting hyper-parameter with respect to the primary segmentation loss, and add an ablation experiment that isolates the pairwise loss contribution while holding the contrast-map branch fixed. revision: yes
Circularity Check
No significant circularity; empirical architecture and benchmarks are self-contained
full rationale
The paper proposes an LCA adapter with dual-branch processing of RGB and contrast maps, a pairwise loss penalizing illumination variants, and a new Unity synthetic dataset. These elements are trained and evaluated on existing benchmarks plus the new data, with performance gains reported directly from experiments. No equations, predictions, or uniqueness claims reduce by construction to fitted parameters or self-citations; the central claim rests on empirical validation rather than any self-referential derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Contrast maps capture structural changes independent of illumination artifacts
invented entities (1)
-
Lighting Convolutional-Attention (LCA) adapter module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2505.09274 (2025)
Bougourzi, F., Hadid, A.: Recent advances in medical imaging segmentation: A survey. arXiv preprint arXiv:2505.09274 (2025)
-
[2]
Diagnostics15(21), 2762 (2025)
Chankhachon,S.,Kansomkeat,S.,Bhurayanontachai,P.,Intajag,S.:Deeplearning network with illuminant augmentation for diabetic retinopathy segmentation using comprehensive anatomical context integration. Diagnostics15(21), 2762 (2025)
work page 2025
-
[3]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chaturvedi, S., Ren, M., Hold-Geoffroy, Y., Liu, J., Dorsey, J., Shu, Z.: Synthlight: Portrait relighting with diffusion model by learning to re-render synthetic faces. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 369–379 (2025)
work page 2025
-
[4]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Chen, T., Zhu, L., Deng, C., Cao, R., Wang, Y., Zhang, S., Li, Z., Sun, L., Zang, Y., Mao, P.: Sam-adapter: Adapting segment anything in underperformed scenes. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3367–3375 (2023)
work page 2023
-
[5]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., Schiele, B.: The cityscapes dataset for semantic urban scene understanding. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3213–3223 (2016)
work page 2016
-
[6]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Cubuk,E.D.,Zoph,B.,Mane,D.,Vasudevan,V.,Le,Q.V.:Autoaugment:Learning augmentation strategies from data. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 113–123 (2019)
work page 2019
-
[7]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops
Cubuk, E.D., Zoph, B., Shlens, J., Le, Q.V.: Randaugment: Practical automated data augmentation with a reduced search space. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops. pp. 702–703 (2020)
work page 2020
-
[8]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[9]
Everingham, M., Eslami, S.A., Van Gool, L., Williams, C.K., Winn, J., Zisserman, A.:Thepascalvisualobjectclasseschallenge:Aretrospective.Internationaljournal of computer vision111(1), 98–136 (2015)
work page 2015
-
[10]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
Hendrycks,D.,Dietterich,T.:Benchmarkingneuralnetworkrobustnesstocommon corruptions and perturbations. arXiv preprint arXiv:1903.12261 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[11]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hoyer, L., Dai, D., Van Gool, L.: Daformer: Improving network architectures and training strategies for domain-adaptive semantic segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9924– 9935 (2022)
work page 2022
-
[12]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 7132–7141 (2018)
work page 2018
-
[13]
In: Proceedings of the IEEE international conference on computer vision
Huang, X., Belongie, S.: Arbitrary style transfer in real-time with adaptive instance normalization. In: Proceedings of the IEEE international conference on computer vision. pp. 1501–1510 (2017)
work page 2017
-
[14]
Jin, S., Wang, L., Temming, B., Pokorny, F.T.: Physically-based lighting augmen- tation for robotic manipulation. arXiv e-prints pp. arXiv–2508 (2025)
work page 2025
-
[15]
Advances in Neural Information Processing Systems36, 29914–29934 (2023) 16 Q
Ke, L., Ye, M., Danelljan, M., Tai, Y.W., Tang, C.K., Yu, F., et al.: Segment anything in high quality. Advances in Neural Information Processing Systems36, 29914–29934 (2023) 16 Q. Liu et al
work page 2023
-
[16]
In: Proceedings of the IEEE/CVF international conference on computer vision
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4015–4026 (2023)
work page 2023
-
[17]
Advances in neural information processing systems29(2016)
Kondor, R., Pan, H.: The multiscale laplacian graph kernel. Advances in neural information processing systems29(2016)
work page 2016
-
[18]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
work page 2014
-
[19]
In: Proceedings of the european conference on computer vision (ECCV)
Pan, X., Luo, P., Shi, J., Tang, X.: Two at once: Enhancing learning and gen- eralization capacities via ibn-net. In: Proceedings of the european conference on computer vision (ECCV). pp. 464–479 (2018)
work page 2018
-
[20]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al.: Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
In: Pro- ceedings of the IEEE/CVF international conference on computer vision
Sakaridis, C., Dai, D., Gool, L.V.: Guided curriculum model adaptation and uncertainty-aware evaluation for semantic nighttime image segmentation. In: Pro- ceedings of the IEEE/CVF international conference on computer vision. pp. 7374– 7383 (2019)
work page 2019
-
[22]
In: Proceedings of the IEEE/CVF international conference on computer vision
Sakaridis, C., Dai, D., Van Gool, L.: Acdc: The adverse conditions dataset with correspondences for semantic driving scene understanding. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 10765–10775 (2021)
work page 2021
-
[23]
Engineering, Technology & Applied Science Research15(6), 30119–30129 (2025)
Sermwuthisarn, P., Phumeechanya, S.: Integration of u-net and fastsam for accu- rate leaf image segmentation in complex backgrounds. Engineering, Technology & Applied Science Research15(6), 30119–30129 (2025)
work page 2025
-
[24]
Journal of big data6(1), 1–48 (2019)
Shorten, C., Khoshgoftaar, T.M.: A survey on image data augmentation for deep learning. Journal of big data6(1), 1–48 (2019)
work page 2019
-
[25]
Advances in neural information processing systems34, 237–250 (2021)
Wang, H., Xiao, C., Kossaifi, J., Yu, Z., Anandkumar, A., Wang, Z.: Augmax: Adversarial composition of random augmentations for robust training. Advances in neural information processing systems34, 237–250 (2021)
work page 2021
-
[26]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, J., Liu, J., Sun, X., Singh, K.K., Shu, Z., Zhang, H., Yang, J., Zhao, N., Wang, T.Y., Chen, S.S., et al.: Comprehensive relighting: Generalizable and con- sistent monocular human relighting and harmonization. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 380–390 (2025)
work page 2025
-
[27]
Neurocomputing 312, 135–153 (2018)
Wang, M., Deng, W.: Deep visual domain adaptation: A survey. Neurocomputing 312, 135–153 (2018)
work page 2018
-
[28]
In: Proceedings of the European conference on computer vision (ECCV)
Woo, S., Park, J., Lee, J.Y., Kweon, I.S.: Cbam: Convolutional block attention module. In: Proceedings of the European conference on computer vision (ECCV). pp. 3–19 (2018)
work page 2018
-
[29]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wu, X., Wu, Z., Guo, H., Ju, L., Wang, S.: Dannet: A one-stage domain adaptation network for unsupervised nighttime semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 15769– 15778 (2021)
work page 2021
-
[30]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xiong, Y., Varadarajan, B., Wu, L., Xiang, X., Xiao, F., Zhu, C., Dai, X., Wang, D., Sun, F., Iandola, F., et al.: Efficientsam: Leveraged masked image pretraining for efficient segment anything. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16111–16121 (2024)
work page 2024
-
[31]
Personalize segment anything model with one shot
Zhang, R., Jiang, Z., Guo, Z., Yan, S., Pan, J., Ma, X., Dong, H., Gao, P., Li, H.: Personalize segment anything model with one shot. arXiv preprint arXiv:2305.03048 (2023) Abbreviated paper title 17 A Supplementary Materials A.1 Additional Related Work Attention Mechanisms for Visual Robustness.Attention mechanisms have been widely adopted to enhance vis...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.