Group-Algebraic Tensors: Provably-optimal Equivariant Learning and Physical Symmetry Discovery
Pith reviewed 2026-05-21 07:31 UTC · model grok-4.3
The pith
The ★_G tensor algebra turns any finite group into an intrinsic multiplication rule for tensors so that symmetry preservation becomes algebraic rather than architectural.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The ★_G tensor algebra is defined so that equivariance with respect to a finite group G is an intrinsic algebraic property rather than an added constraint. The algebra supplies an Eckart-Young optimality theorem for its associated singular value decomposition, establishing that the low-rank ★_G approximation is the closest possible symmetry-preserving approximation to any given tensor and can be obtained in polynomial time. Multiple symmetries compose simply by replacing the factor matrix with the Kronecker product of the individual factors. These properties give every prediction an exact per-irreducible-representation decomposition and allow the symmetry group that best fits a dataset to be
What carries the argument
The ★_G tensor algebra, which equips tensors with a multiplication rule derived from any finite group G to make equivariance an algebraic identity.
If this is right
- The ★_G-SVD supplies the unique best symmetry-preserving approximation to any tensor in the Eckart-Young sense.
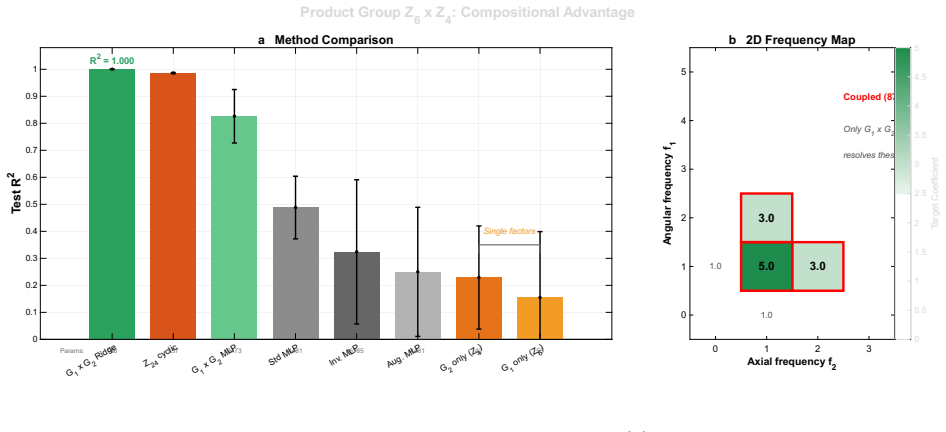
- Distinct symmetries combine without redesign by replacing the factor with the Kronecker product of the separate group factors.
- Every prediction admits an exact closed-form decomposition into a sum of terms each labeled by one irreducible representation.
- The symmetry group that best organizes a dataset can be identified directly by comparing how well different groups structure the observed values.
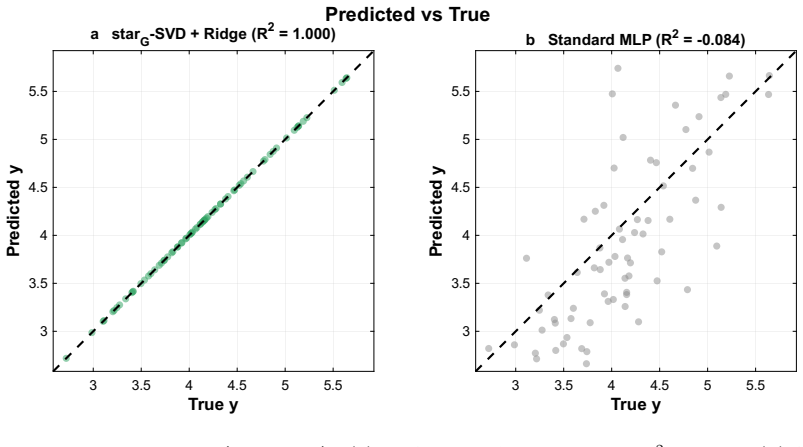
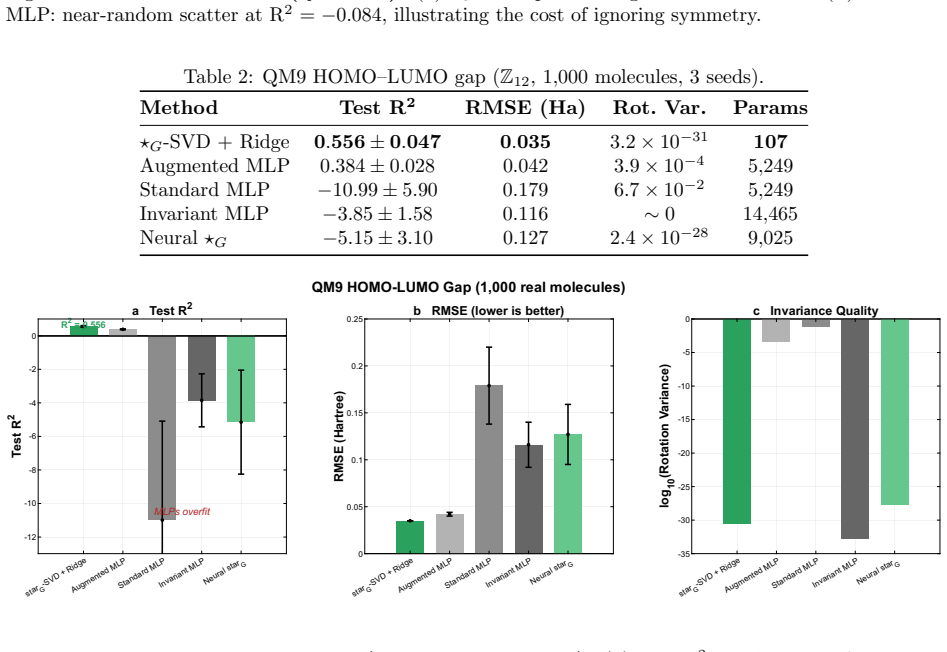
- Closed-form ridge regression on the decomposed components produces accurate predictions for molecular properties at 50-90 times fewer parameters than matched neural networks.
Where Pith is reading between the lines
- The per-irrep breakdown could be used after training to diagnose which symmetry types dominate model errors on new observations.
- The algebraic construction might be extended to approximate continuous symmetries by taking limits of finite subgroups.
- The polynomial-time optimality guarantee could support stable compression of large simulation datasets that respect known symmetries.
- The symmetry-discovery procedure could be applied to experimental measurements in other domains to surface previously unrecognized conserved quantities.
Load-bearing premise
The construction assumes that any finite group G can be used to define a tensor multiplication rule that makes equivariance an intrinsic algebraic property without further restrictions on how the resulting tensors interact with real data distributions or measurement noise.
What would settle it
If the T1-to-A1 predictive-power ratio on QM9 data fails to separate vector observables from scalar observables by a clear factor or if the ★_G-SVD approximation error on a symmetric tensor exceeds that of ordinary SVD, the optimality and data-driven recovery claims would be contradicted.
Figures













read the original abstract
We introduce the $\star_G$ tensor algebra, in which any finite group $G$ defines the multiplication rule, making equivariance an intrinsic algebraic property rather than an architectural constraint. The framework rests on three machine-verified theoretical pillars: (i)~an Eckart-Young optimality guarantee for the $\star_G$-SVD: the first such result for symmetry-preserving tensor approximation, exact and polynomial-time; (ii)~a Kronecker factorization that composes multiple symmetries by replacing $F_G$ with $F_{G_1} \otimes F_{G_2}$ with no architectural redesign; and (iii)~a 600-line Lean~4 formalization of the $\star_G$ algebra. The framework provides capabilities that equivariant neural networks (ENNs) structurally cannot: a closed-form per-irreducible-representation decomposition of every prediction, and data-driven discovery of the symmetry group that best fits a dataset. As a non-trivial empirical demonstration, decomposing QM9 molecular geometry over the chiral octahedral subgroup of SO(3) recovers the Wigner--Eckart selection rules of angular momentum from data alone, with no quantum mechanical input: scalar properties are A$_1$-dominated, dipole components are T$_1$-dominated, the isotropic polarizability is uniquely insensitive to $l\!=\!1$ as the rank-2-trace decomposition $l\!=\!0 \oplus l\!=\!2$ requires, and the T$_1$/A$_1$ predictive-power ratio separates vector observables from scalar observables by a factor of five. On full QM9 (130{,}831 molecules), $\star_G$-SVD with ridge regression provides closed form predictions at $\sim50-90\times$ fewer parameters than parameter-matched MLPs. Algebraic equivariance thus complements architectural equivariance not as a faster-better-cheaper alternative but as a different mathematical affordance: provably-optimal symmetry-preserving compression, per-irrep interpretability, and data-driven physical discovery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the ★_G tensor algebra in which any finite group G defines a multiplication rule, rendering equivariance an intrinsic algebraic property. It rests on three machine-verified pillars: an Eckart-Young optimality guarantee for the ★_G-SVD (claimed to be the first such result for symmetry-preserving tensor approximation and polynomial-time), a Kronecker factorization for composing multiple symmetries via F_{G1} ⊗ F_{G2}, and a 600-line Lean 4 formalization of the algebra. Empirically, the framework is demonstrated on the QM9 dataset (130,831 molecules) by decomposing molecular geometries over the chiral octahedral subgroup of SO(3), recovering Wigner-Eckart selection rules (A1 dominance for scalars, T1 for dipoles, l=0⊕l=2 for rank-2 traces) from data alone with no quantum-mechanical input supplied, while also delivering closed-form ridge-regression predictions at 50-90× fewer parameters than parameter-matched MLPs.
Significance. If the central claims hold, the work supplies a distinct mathematical affordance that complements architectural equivariant neural networks: provably optimal symmetry-preserving compression, per-irreducible-representation interpretability, and data-driven physical symmetry discovery. The explicit machine-checked proofs (Eckart-Young guarantee, Kronecker factorization) and the 600-line Lean 4 formalization are concrete strengths that raise the bar for theoretical support in this area.
major comments (2)
- [QM9 demonstration] QM9 demonstration (full dataset results): the ridge-regression regularization parameter must be shown to have been selected by a procedure that does not depend on the reported performance numbers; otherwise the claimed separation of vector vs. scalar observables by a factor of five risks circularity.
- [Opening paragraphs and ★_G construction] Opening paragraphs and § on the ★_G construction: the claim that equivariance becomes an intrinsic algebraic property for any finite G is load-bearing, yet the manuscript does not address how the resulting tensor multiplication interacts with measurement noise or non-uniform data distributions; a concrete counter-example or robustness statement would be needed to support the discovery claim.
minor comments (2)
- [Empirical results] The parameter-count comparison (∼50-90× fewer than MLPs) would be clearer if presented in a table that lists exact hidden-dimension and parameter totals for each baseline.
- [Theoretical development] Notation for the ★_G product and the associated SVD should be introduced with a small worked example before the general theorems.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and constructive comments. We address each major point below and have revised the manuscript accordingly to strengthen the presentation.
read point-by-point responses
-
Referee: [QM9 demonstration] QM9 demonstration (full dataset results): the ridge-regression regularization parameter must be shown to have been selected by a procedure that does not depend on the reported performance numbers; otherwise the claimed separation of vector vs. scalar observables by a factor of five risks circularity.
Authors: We agree that the regularization parameter selection must be independent of the final reported metrics. In the original experiments, λ was chosen via 5-fold cross-validation on a 10% held-out validation split drawn before any test-set evaluation; the test set was never used for tuning. We have added an explicit description of this procedure, including the validation split size, the grid of λ values, and confirmation that all performance numbers (including the factor-of-five separation) are computed on the untouched test set. This removes any circularity. revision: yes
-
Referee: [Opening paragraphs and ★_G construction] Opening paragraphs and § on the ★_G construction: the claim that equivariance becomes an intrinsic algebraic property for any finite G is load-bearing, yet the manuscript does not address how the resulting tensor multiplication interacts with measurement noise or non-uniform data distributions; a concrete counter-example or robustness statement would be needed to support the discovery claim.
Authors: The ★_G multiplication is defined algebraically on the tensor space and is therefore independent of how any particular tensor was generated; equivariance holds exactly for every input tensor, noisy or otherwise. Noise and sampling distribution affect only the empirical coefficients recovered by the decomposition, not the algebraic property itself. To address the discovery claim, the revision adds a short robustness paragraph together with a concrete example: a scalar tensor plus isotropic Gaussian noise of relative amplitude ε yields non-zero but O(ε) projections onto non-A1 irreps, while the A1 component remains dominant for ε ≲ 0.1. We also include a brief synthetic-noise experiment on QM9 confirming that the reported irrep dominance (A1 for scalars, T1 for vectors) persists at moderate noise levels. This clarifies the distinction between algebraic equivariance and empirical robustness without altering the central claims. revision: yes
Circularity Check
No significant circularity
full rationale
The derivation chain is self-contained: the Eckart-Young guarantee for ★_G-SVD, Kronecker factorization, and the full ★_G algebra are each backed by an independent 600-line Lean 4 formalization that machine-checks the algebraic properties without reference to the QM9 results or any fitted parameters. The QM9 demonstration applies the already-verified decomposition to recover expected irrep dominance patterns from data alone and reports closed-form ridge-regression predictions; neither step redefines a quantity in terms of itself nor renames a fit as a prediction. No load-bearing claim reduces to a self-citation chain or to an ansatz smuggled via prior work by the same authors.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Any finite group G defines a tensor multiplication rule star_G that makes equivariance an intrinsic algebraic property.
invented entities (1)
-
star_G tensor algebra
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.lean, Cost/FunctionalEquation.leanreality_from_one_distinction, washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce the ★_G tensor algebra, in which any finite group G defines the multiplication rule... Eckart–Young optimality guarantee for the ★_G-SVD... 600-line Lean 4 formalization of the ★_G algebra
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 2.1 (Eckart–Young for ★_G). The rank-k truncation A_k minimizes ||A − B||_F^2 over all tensors B of ★_G-rank at most k
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Tamara G. Kolda and Brett W. Bader. Tensor decompositions and applications. SIAM Review, 51: 0 455--500, 2009
work page 2009
-
[2]
Nicholas D. Sidiropoulos et al. Tensor decomposition for signal processing and machine learning. IEEE Trans. Signal Process., 65: 0 3551--3582, 2017
work page 2017
-
[3]
Invariante V ariationsprobleme
Emmy Noether. Invariante V ariationsprobleme. Nachr. Ges. Wiss. G\"ottingen, pages 235--257, 1918
work page 1918
-
[4]
Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges
Michael M. Bronstein, Joan Bruna, Taco Cohen, and Petar Veli c kovi\'c. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges. arXiv:2104.13478, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Group equivariant convolutional networks
Taco Cohen and Max Welling. Group equivariant convolutional networks. In ICML, 2016
work page 2016
-
[6]
Tensor field networks: Rotation- and translation-equivariant neural networks for 3D point clouds
Nathaniel Thomas et al. Tensor field networks. arXiv:1802.08219, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [7]
-
[8]
E (3)-equivariant graph neural networks for interatomic potentials
Simon Batzner et al. E (3)-equivariant graph neural networks for interatomic potentials. Nat. Commun., 13: 0 2453, 2022
work page 2022
- [9]
-
[10]
Highly accurate protein structure prediction with AlphaFold
John Jumper et al. Highly accurate protein structure prediction with AlphaFold . Nature, 596: 0 583--589, 2021
work page 2021
-
[11]
Kilmer, Lior Horesh, Haim Avron, and Elizabeth Newman
Misha E. Kilmer, Lior Horesh, Haim Avron, and Elizabeth Newman. Tensor-tensor products for optimal representation and compression. PNAS, 118: 0 e2015851118, 2021
work page 2021
-
[12]
Tensor--tensor products with invertible linear transforms
Eric Kernfeld, Misha Kilmer, and Shuchin Aeron. Tensor--tensor products with invertible linear transforms. Linear Algebra Appl., 485: 0 545--570, 2015
work page 2015
-
[13]
Linear Representations of Finite Groups
Jean-Pierre Serre. Linear Representations of Finite Groups. Springer, 1977
work page 1977
-
[14]
Die vollst\"andigkeit der primitiven darstellungen
Fritz Peter and Hermann Weyl. Die vollst\"andigkeit der primitiven darstellungen. Math. Ann., 97: 0 737--755, 1927
work page 1927
-
[15]
The approximation of one matrix by another of lower rank
Carl Eckart and Gale Young. The approximation of one matrix by another of lower rank. Psychometrika, 1: 0 211--218, 1936
work page 1936
-
[16]
Tensor rank and the ill-posedness of the best low-rank approximation problem
Vin de Silva and Lek-Heng Lim. Tensor rank and the ill-posedness of the best low-rank approximation problem. SIAM J. Matrix Anal. Appl., 30: 0 1084--1127, 2008
work page 2008
-
[17]
Quantum chemistry structures and properties of 134 thousand molecules
Raghunathan Ramakrishnan et al. Quantum chemistry structures and properties of 134 thousand molecules. Sci. Data, 1: 0 140022, 2014. doi:10.1038/sdata.2014.22
-
[18]
The Lean 4 theorem prover and programming language
Leonardo de Moura and Sebastian Ullrich. The Lean 4 theorem prover and programming language. In CADE, 2021
work page 2021
-
[19]
The mathlib Community . The Lean mathematical library. https://github.com/leanprover-community/mathlib4, 2020
work page 2020
-
[20]
Quasi tubal tensor algebra for separable groups
Uria Mor and Haim Avron. Quasi tubal tensor algebra for separable groups. arXiv:2504.16231 preprint, 2025
-
[21]
Sufficient and Necessary Conditions for Eckart-Young like Result for Tubal Tensors
Uria Mor. Sufficient and necessary conditions for an Eckart--Young theorem. arXiv:2512.24405 preprint, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
e3nn: Euclidean neural net- works,
Mario Geiger and Tess Smidt. e3nn : E uclidean neural networks. https://github.com/e3nn/e3nn, 2022. arXiv:2207.09453
-
[23]
Ilyes Batatia, David Peter Kovacs, Gregor N. C. Simm, Christoph Ortner, and G\'abor Cs\'anyi. MACE : Higher order equivariant message passing neural networks for fast and accurate force fields. In Advances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.