HalluCXR: Benchmarking and Mitigating Hallucinations in Medical Vision-Language Models for Chest Radiograph Interpretation
Pith reviewed 2026-05-21 06:34 UTC · model grok-4.3
The pith
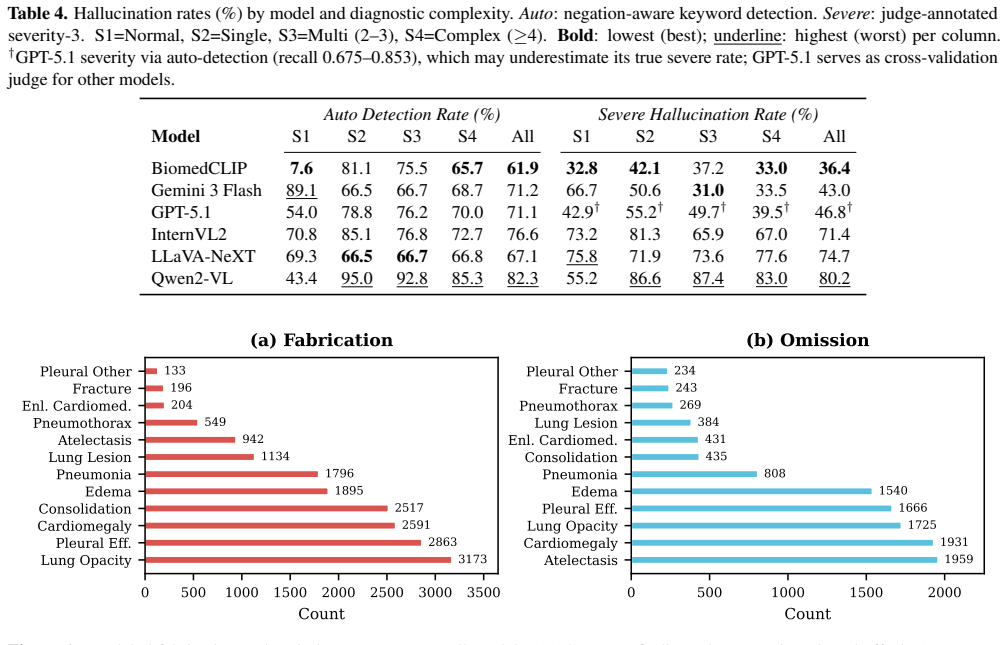
Vision-language models hallucinate in 62 to 82 percent of chest radiograph interpretations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
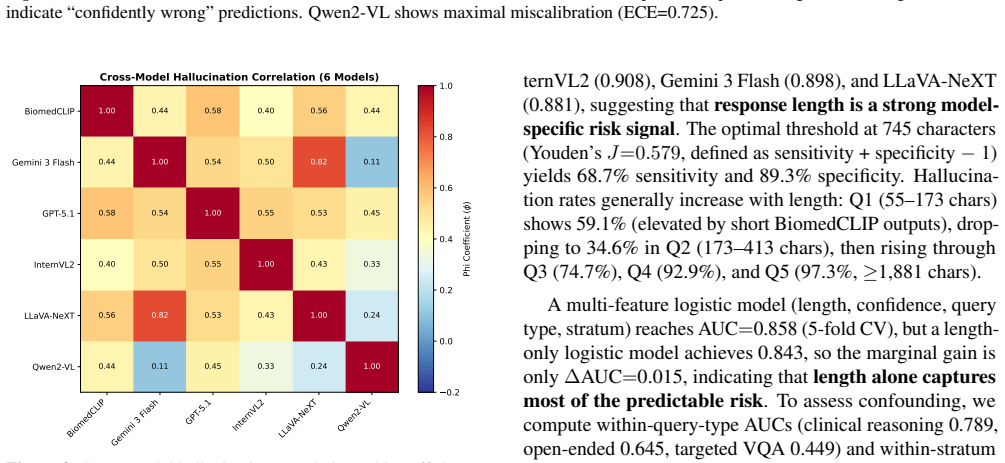
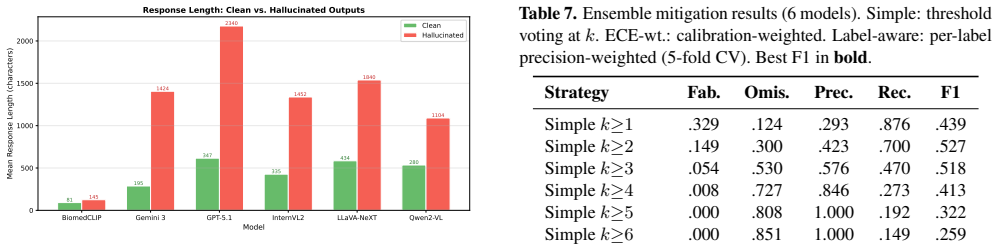
By evaluating six architecturally diverse vision-language models on 856 stratified MIMIC-CXR chest radiographs across three query types for 15,408 total outputs, the paper establishes that 61.9 to 82.3 percent of responses contain hallucinations and up to 80.2 percent include clinically dangerous errors. An eight-category taxonomy with severity ratings and a two-layer detection pipeline, validated on 250 human annotations, reveals three patterns: normal radiographs attract the most severe hallucinations, common findings are over-fabricated while rare ones are missed, and longer responses predict higher hallucination risk with AUC up to 0.908. Ensembles of models reduce fabrication by up to
What carries the argument
The HalluCXR benchmark with its eight-category hallucination taxonomy that includes clinical severity ratings and a two-layer detection pipeline validated against human annotations.
Load-bearing premise
The eight-category taxonomy and two-layer detection pipeline validated on 250 human annotations fully capture all clinically relevant hallucinations in the model outputs.
What would settle it
A larger-scale human review by radiologists on additional model outputs using a different or expanded error classification to check whether the 61.9-82.3 percent hallucination rates and severity distributions remain consistent.
Figures


read the original abstract
Vision-language models (VLMs) are increasingly used for medical image interpretation, yet they frequently hallucinate, generating clinically plausible but factually incorrect findings that pose direct patient safety risks. We introduce HalluCXR, a benchmark evaluating six architecturally diverse VLMs across 856 stratified MIMIC-CXR chest radiographs and three query types, yielding 15,408 model evaluations. An eight-category hallucination taxonomy with clinical severity ratings and a two-layer detection pipeline are validated against 250 human annotations (auto-detection F1=0.959; LLM judge F1=0.907). We find that 61.9--82.3% of outputs contain hallucinations, with clinically dangerous errors in up to 80.2%. Three key patterns emerge: normal radiographs paradoxically attract the most severe hallucinations, common findings are systematically over-fabricated while rare findings go under-detected, and response length alone predicts hallucination risk (AUC up to 0.908). A six-model ensemble reduces fabrication by up to 84.8% at the cost of increased omission; a three-model subset retains comparable performance at half the cost. These results establish that hallucination auditing, verbosity-based risk monitoring, and ensemble-based safety layers are prerequisites for clinical deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HalluCXR, a benchmark for hallucinations in medical vision-language models interpreting chest radiographs. It evaluates six architecturally diverse VLMs on 856 stratified MIMIC-CXR images across three query types, producing 15,408 outputs. An eight-category hallucination taxonomy with severity ratings and a two-layer detection pipeline (automated + LLM judge) are introduced and validated on 250 human annotations (F1 scores 0.959 and 0.907). Key results include hallucination prevalence of 61.9–82.3% with clinically dangerous errors up to 80.2%, patterns such as more severe hallucinations on normal radiographs, over-fabrication of common findings, under-detection of rare ones, and response length as a predictor (AUC up to 0.908). Mitigation via a six-model ensemble reduces fabrication by up to 84.8%, with a three-model subset offering comparable performance at lower cost.
Significance. If the detection pipeline and taxonomy generalize beyond the validation set, the work provides a valuable large-scale empirical benchmark highlighting patient-safety risks in clinical VLM deployment. Strengths include the scale of evaluation (15,408 outputs), use of public MIMIC-CXR data, human annotation validation, and practical mitigation results (ensemble reductions). The identification of actionable patterns such as verbosity-based risk monitoring adds immediate utility for auditing systems.
major comments (1)
- [Methods / Results (validation subsection)] Validation of the detection pipeline (described in the methods and results sections): The eight-category taxonomy and two-layer detector are validated on only 250 human annotations out of 15,408 total outputs, with reported F1 scores of 0.959 (auto) and 0.907 (LLM judge). This small stratified sample provides limited evidence that the taxonomy captures all clinically relevant hallucination types or that the detector is free of systematic biases across models, query types, or radiograph findings (e.g., normal vs. abnormal films). If coverage or calibration does not generalize, the headline prevalence rates (61.9–82.3%) and severity claims (up to 80.2% dangerous) cannot be reliably extrapolated.
minor comments (2)
- [Dataset construction] The stratification details for the 856 radiographs (e.g., exact distribution of findings, normal vs. abnormal balance) are referenced but could be expanded with a supplementary table for full reproducibility.
- [Experimental setup] Clarify how the three query types were chosen and whether they cover the full range of clinical use cases for chest radiograph interpretation.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address the major comment point by point below, acknowledging limitations where appropriate and outlining specific revisions to strengthen the work.
read point-by-point responses
-
Referee: [Methods / Results (validation subsection)] Validation of the detection pipeline (described in the methods and results sections): The eight-category taxonomy and two-layer detector are validated on only 250 human annotations out of 15,408 total outputs, with reported F1 scores of 0.959 (auto) and 0.907 (LLM judge). This small stratified sample provides limited evidence that the taxonomy captures all clinically relevant hallucination types or that the detector is free of systematic biases across models, query types, or radiograph findings (e.g., normal vs. abnormal films). If coverage or calibration does not generalize, the headline prevalence rates (61.9–82.3%) and severity claims (up to 80.2% dangerous) cannot be reliably extrapolated.
Authors: We appreciate the referee's concern regarding the scale of the human validation. The 250 annotations were obtained via a stratified sampling strategy explicitly designed to cover all six models, the three query types, and a balanced distribution of normal versus abnormal radiographs, maximizing representativeness given the substantial cost and time required for expert medical annotation. The high F1 scores reflect strong agreement with human judgments on this sample. We nevertheless agree that the sample size constrains strong claims of full generalization across every possible subgroup and that undetected systematic biases remain possible. In the revised manuscript we will expand the human validation set to 750 annotations total, with targeted oversampling of rare findings and per-model breakdowns. We will add a new subsection reporting detector performance stratified by model, query type, and finding prevalence, and we will include an expanded limitations paragraph explicitly discussing the risk of extrapolation and the value of future community validation on the released annotations. revision: yes
Circularity Check
No circularity: empirical rates derived from external annotations and public data
full rationale
The paper is a standard empirical benchmark study. Hallucination prevalence (61.9–82.3 %) and severity claims are obtained by running the authors' eight-category taxonomy and two-layer detector over 15,408 model outputs on stratified MIMIC-CXR radiographs; the detector itself is validated on an independent set of 250 human annotations (F1 scores reported). No equations, fitted parameters, or self-citations are used to derive the headline statistics; the taxonomy is defined once and then applied, with coverage checked against external labels rather than by construction. The analysis therefore contains no self-definitional, fitted-input, or self-citation-load-bearing steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MIMIC-CXR provides reliable ground-truth findings for hallucination labeling
invented entities (1)
-
Eight-category hallucination taxonomy with severity ratings
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
An eight-category hallucination taxonomy with clinical severity ratings and a two-layer detection pipeline are validated against 250 human annotations (auto-detection F1=0.959; LLM judge F1=0.907).
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Response length alone predicts hallucination risk (AUC up to 0.908).
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Google DeepMind, “Gemini 3 flash model card,” tech. rep., Google, 2025. 1, 2
work page 2025
-
[2]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge,et al., “Qwen2-VL: Enhancing vision- language model’s perception of the world at any resolution,” arXiv preprint arXiv:2409.12191, 2024. 1, 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Z. Chen, W. Wang, Y . Cao, Y . Liu, Z. Gao, E. Cui, J. Zhu, S. Ye, H. Tian, Z. Liu,et al., “Expanding performance bound- aries of open-source multimodal models with model, data, and test-time scaling,”arXiv preprint arXiv:2412.05271, 2024. 1, 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
LLaV A-NeXT: Improved reasoning, OCR, and world knowledge
H. Liu, C. Li, Y . Li, B. Li, Y . Zhang, S. Shen, and Y . J. Lee, “LLaV A-NeXT: Improved reasoning, OCR, and world knowledge.” https://llava-vl.github.io/ blog/2024-01-30-llava-next/, 2024. 1, 3
work page 2024
-
[5]
LLaV A-Med: Training a large language-and-vision assistant for biomedicine in one day,
C. Li, C. Wong, S. Zhang, N. Usuyama, H. Liu, J. Yang, T. Naumann, H. Poon, and J. Gao, “LLaV A-Med: Training a large language-and-vision assistant for biomedicine in one day,” inProceedings of NeurIPS, 2023. 1, 2
work page 2023
-
[6]
Z. Chen, M. Varma, J. Xu, M. Paschali, D. Van Veen, A. John- ston, A. Youssef, L. Blankemeier, J.-B. Delbrouck, J. P. Cohen,et al., “A vision-language foundation model to en- hance efficiency of chest X-ray interpretation,”arXiv preprint arXiv:2401.12208, 2024. 1, 2
-
[7]
Med- Flamingo: A multimodal medical few-shot learner,
M. Moor, Q. Huang, S. Wu, M. Yasunaga, Y . Dalmia, J. Leskovec, C. Zakka, E. P. Reis, and P. Rajpurkar, “Med- Flamingo: A multimodal medical few-shot learner,”Proceed- ings of Machine Learning Research (PMLR), vol. 225, 2023. 1, 2
work page 2023
-
[8]
The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision)
Z. Yang, L. Li, K. Lin, J. Wang, C.-C. Lin, Z. Liu, and L. Wang, “The dawn of LMMs: Preliminary explorations with GPT-4V(ision),”arXiv preprint arXiv:2309.17421, 2024. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Med-Halt: Medical domain hallucination test for large language models,
A. Pal, L. K. Umapathi, and M. Sankarasubbu, “Med-Halt: Medical domain hallucination test for large language models,” inProceedings of EMNLP, 2023. 1, 2
work page 2023
-
[10]
Z. Gu, C. Yin, F. Liu, and P. Zhang, “MedVH: To- wards systematic evaluation of hallucination for large vi- sion language models in the medical context,”arXiv preprint arXiv:2407.02730, 2024. 1, 2
-
[11]
Object hallucination in image captioning,
A. Rohrbach, L. A. Hendricks, K. Burns, T. Darrell, and K. Saenko, “Object hallucination in image captioning,” in Proceedings of EMNLP, 2018. 1, 2
work page 2018
-
[12]
Evaluating object hallucination in large vision-language mod- els,
Y . Li, Y . Du, K. Zhou, J. Wang, W. X. Zhao, and J.-R. Wen, “Evaluating object hallucination in large vision-language mod- els,” inProceedings of EMNLP, 2023. 2
work page 2023
-
[13]
FaithScore: Fine-grained evaluations of hallucinations in large vision-language models,
L. Jing, R. Li, Y . Chen, and X. Du, “FaithScore: Fine-grained evaluations of hallucinations in large vision-language models,” inFindings of the Association for Computational Linguistics: EMNLP 2024, pp. 5042–5063, Association for Computational Linguistics, 2024. 1, 2
work page 2024
-
[14]
S. Zhang, Y . Xu, N. Usuyama, J. Bagga, R. Tinn, S. Preston, R. Rao, M. Wei, N. Valluri, C. Wong,et al., “BiomedCLIP: A multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs,”arXiv preprint arXiv:2303.00915, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
PubMedCLIP: How much does CLIP benefit visual question answering in the medical domain?,
S. Eslami, G. de Melo, and C. Meinel, “PubMedCLIP: How much does CLIP benefit visual question answering in the medical domain?,”Findings of EACL, 2023. 2
work page 2023
-
[16]
To- wards generalist foundation model for radiology by lever- aging web-scale 2D&3D medical data,
C. Wu, X. Zhang, Y . Zhang, Y . Wang, and W. Xie, “To- wards generalist foundation model for radiology by lever- aging web-scale 2D&3D medical data,”arXiv preprint arXiv:2308.02463, 2023. 2
-
[17]
Detecting and Evaluating Medical Hallucinations in Large Vision Language Models
J. Chen, D. Yang, T. Wu, Y . Jiang, X. Hou, M. Li, S. Wang, D. Xiao, K. Li, and L. Zhang, “Med-HallMark: Detecting and evaluating medical hallucinations in large vision language models,”arXiv preprint arXiv:2406.10185, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
FactCheXcker: Mitigating measurement hallucinations in chest X-ray report generation models,
A. Heiman, X. Zhang, E. Chen, S. E. Kim, and P. Rajpurkar, “FactCheXcker: Mitigating measurement hallucinations in chest X-ray report generation models,” inProceedings of CVPR, 2025. 2
work page 2025
-
[19]
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qin, and T. Liu, “A survey on hallucination in large language models: Principles, taxon- omy, challenges, and open questions,”ACM Transactions on Information Systems, 2025. 2
work page 2025
-
[20]
Judg- ing LLM-as-a-judge with MT-Bench and Chatbot Arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. P. Xing,et al., “Judg- ing LLM-as-a-judge with MT-Bench and Chatbot Arena,” in Proceedings of NeurIPS, 2023. 2
work page 2023
-
[21]
Chatbot arena: An open platform for evaluating LLMs by human preference,
W.-L. Chiang, L. Zheng, Y . Sheng, A. N. Angelopoulos, T. Li, D. Li, H. Zhang, B. Zhu, M. Jordan, J. E. Gonzalez, and I. Stoica, “Chatbot arena: An open platform for evaluating LLMs by human preference,” inProceedings of ICML, 2024. 2
work page 2024
-
[22]
MIMIC-CXR-JPG, a large publicly available database of labeled chest radiographs,
A. E. W. Johnson, T. J. Pollard, N. R. Greenbaum, M. P. Lun- gren, C.-y. Deng, Y . Peng, Z. Lu, R. G. Mark, S. J. Berkowitz, and S. Horng, “MIMIC-CXR-JPG, a large publicly available database of labeled chest radiographs,”Scientific Data, vol. 6, no. 1, p. 317, 2019. 2, 8
work page 2019
-
[23]
CheXpert: A large chest radiograph dataset with uncertainty labels and expert comparison,
J. Irvin, P. Rajpurkar, M. Ko, Y . Yu, S. Ciurea-Ilcus, C. Chute, H. Marklund, B. Haghgoo, R. Ball, K. Shpanskaya,et al., “CheXpert: A large chest radiograph dataset with uncertainty labels and expert comparison,” inProceedings of the AAAI Conference on Artificial Intelligence, 2019. 2
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.