Oracle Supervision Transfers for Hyperparameter Prediction in Model-Based Image Denoising
Pith reviewed 2026-05-21 07:05 UTC · model grok-4.3
The pith
A single predictor transfers oracle hyperparameter labels from variational denoisers to diffusion models with only two new examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
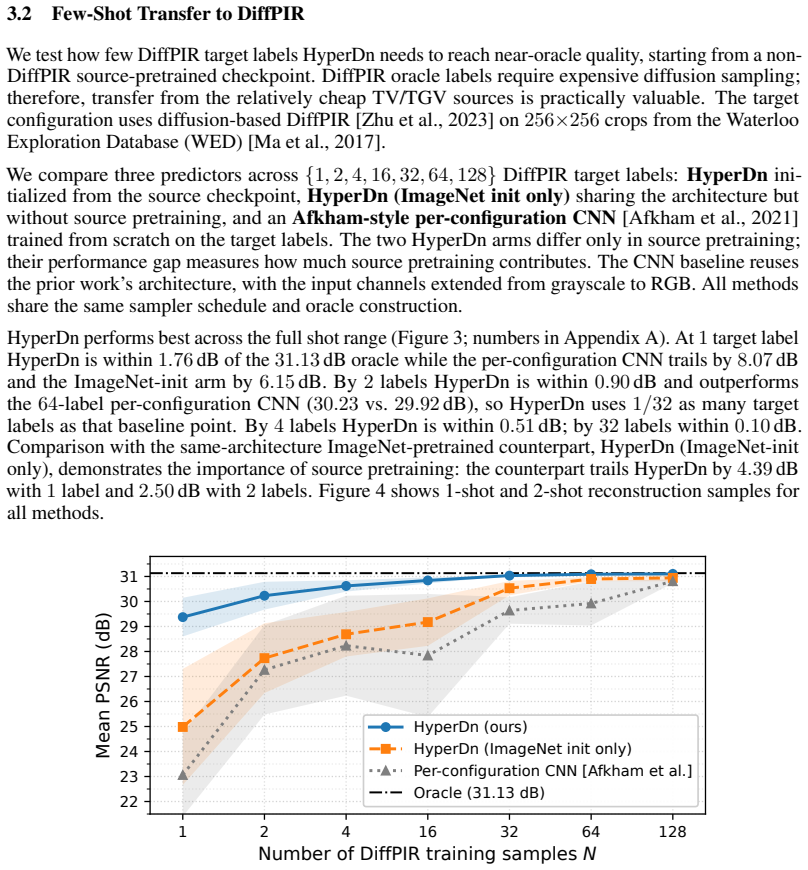
HyperDn is a single configuration-conditioned predictor that pools oracle supervision across source configurations and predicts heterogeneous hyperparameters for new denoiser-noise configurations. In cross-paradigm tests it transfers from TV/TGV variational sources to DiffPIR diffusion targets. With only two target oracle labels it reaches 30.23 dB PSNR, within 0.90 dB of the oracle, and outperforms a 64-label per-configuration predictor trained from scratch while using one thirty-second as many target labels.
What carries the argument
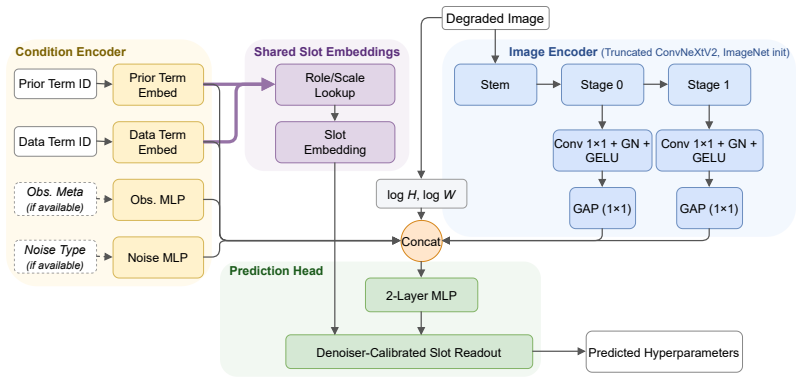
HyperDn, a configuration-conditioned predictor that pools oracle hyperparameter labels across multiple source denoiser setups to generalize to unseen target setups.
If this is right
- With two target oracle labels the method reaches performance within 0.90 dB of the full oracle on DiffPIR.
- It outperforms per-configuration predictors trained from scratch while using 1/32 as many target labels.
- Near-oracle results hold without any target labels for mixtures of seen noise types.
- Transfer works from 96 by 96 source images to 512 by 768 target images.
Where Pith is reading between the lines
- The same pooling strategy could reduce label costs for hyperparameter tuning in other inverse imaging problems that use model-based solvers.
- Joint training across configurations may reveal shared structure in optimal hyperparameter landscapes that is currently hidden by isolated per-setup training.
- The label reduction could make adaptive model-based denoisers more practical when clean reference images are limited or expensive to obtain.
Load-bearing premise
Oracle supervision gathered on variational denoisers shares enough structure with diffusion-based ones to support effective transfer after seeing only a couple of new target labels.
What would settle it
A new diffusion configuration where the two-label transferred predictor performs worse than a from-scratch predictor trained on dozens of its own oracle labels.
Figures




read the original abstract
Hyperparameter prediction is a critical practical bottleneck for model-based image denoisers, ranging from classical TV/TGV variational solvers to modern diffusion-based models such as DiffPIR. While existing learned predictors can achieve near-oracle performance, this approach scales poorly: each new configuration conventionally requires its own oracle-labeled training set, and each label requires a hierarchical grid search evaluated against clean ground truth. We therefore ask whether oracle supervision collected on source configurations can transfer to target configurations with few or no target oracle labels. We propose HyperDn, a single configuration-conditioned predictor that pools oracle supervision across source configurations and predicts heterogeneous hyperparameters for new denoiser--noise configurations. In a cross-paradigm experiment, HyperDn transfers from relatively cheap TV/TGV variational sources to more expensive diffusion-based DiffPIR. With only $2$ target oracle labels, it reaches $30.23$\,dB, within $0.90$\,dB of the oracle, and outperforms the $64$-label per-configuration predictor trained from scratch, using $1/32$ as many target labels as that baseline point. Without any target oracle labels, HyperDn also reaches near-oracle PSNR on two unseen mixtures of seen noise types and on transfer from relatively cheap $96\times 96$ source images to $512\times 768$ targets. Together, these results show that expensive oracle supervision for hyperparameter prediction can be transferred from source to new target configurations, reducing the need to rebuild oracle labels for each new denoising configuration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HyperDn, a configuration-conditioned predictor that pools oracle supervision from source configurations (TV/TGV variational denoisers) to predict hyperparameters for target configurations (DiffPIR diffusion models). It reports that with only 2 target oracle labels, HyperDn achieves 30.23 dB PSNR (within 0.90 dB of the oracle) and outperforms a 64-label per-configuration predictor trained from scratch, while also showing near-oracle performance on unseen noise mixtures and image-size transfers with zero target labels.
Significance. If the transfer mechanism holds, the work provides a concrete route to amortize the high cost of oracle hyperparameter labeling (hierarchical grid search against ground truth) across denoising paradigms, which could meaningfully lower the barrier to deploying new model-based denoisers.
major comments (2)
- Abstract: The headline claim that source TV/TGV oracle labels enable the reported 30.23 dB result with only 2 target labels (outperforming the 64-label scratch baseline) is not yet supported by an ablation that isolates the contribution of the pooled source supervision. Training the identical architecture on the same 2 DiffPIR labels alone (without source pooling or conditioning) is required to rule out the possibility that performance is explained by model capacity plus the 2 target labels rather than cross-paradigm transfer.
- Abstract: The concrete PSNR numbers and direct comparison to the 64-label baseline are welcome, but the absence of error bars, explicit dataset details (image sets, noise levels, selection of the 2 target labels), and description of the configuration-conditioning mechanism leaves the reliability of the 0.90 dB gap and the 1/32 label-efficiency claim difficult to assess.
minor comments (2)
- Abstract: The phrases 'relatively cheap TV/TGV' and 'more expensive diffusion-based DiffPIR' would benefit from a brief quantitative comparison of oracle-collection wall-clock time or FLOPs to make the practical motivation sharper.
- Abstract: Consider adding a compact table that lists label counts, PSNR, and gap-to-oracle for the oracle, the 64-label baseline, the 2-label HyperDn, and any zero-label transfer cases.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: Abstract: The headline claim that source TV/TGV oracle labels enable the reported 30.23 dB result with only 2 target labels (outperforming the 64-label scratch baseline) is not yet supported by an ablation that isolates the contribution of the pooled source supervision. Training the identical architecture on the same 2 DiffPIR labels alone (without source pooling or conditioning) is required to rule out the possibility that performance is explained by model capacity plus the 2 target labels rather than cross-paradigm transfer.
Authors: We agree that an explicit ablation isolating the pooled source supervision would provide stronger evidence for the transfer mechanism. In the revised manuscript we will add results from training the identical architecture on the same 2 DiffPIR labels alone, without source pooling or configuration conditioning. This will allow direct comparison and help confirm that the observed performance is attributable to cross-paradigm transfer rather than model capacity and the two target labels. revision: yes
-
Referee: Abstract: The concrete PSNR numbers and direct comparison to the 64-label baseline are welcome, but the absence of error bars, explicit dataset details (image sets, noise levels, selection of the 2 target labels), and description of the configuration-conditioning mechanism leaves the reliability of the 0.90 dB gap and the 1/32 label-efficiency claim difficult to assess.
Authors: We appreciate this observation. The revised version will include error bars computed over multiple runs, explicit details on the image sets and noise levels used, the procedure for selecting the two target labels, and an expanded description of the configuration-conditioning mechanism. These additions will be placed in the abstract and a new reproducibility subsection to make the reported gaps and label-efficiency claims easier to evaluate. revision: yes
Circularity Check
No circularity: empirical transfer validated on external oracles and baselines
full rationale
The paper trains a configuration-conditioned predictor on pooled external oracle labels (obtained via grid search against clean ground truth on source TV/TGV configurations) and evaluates PSNR on independent target images for DiffPIR. Performance claims (e.g., 30.23 dB with 2 target labels) are measured against held-out oracles and scratch-trained baselines, not derived by redefining fitted quantities as predictions. No equations reduce results to inputs by construction, and no self-citation chain supports the central transfer claim. The setup is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Stephen Boyd, Neal Parikh, Eric Chu, Borja Peleato, and Jonathan Eckstein
doi: 10.1088/1361-6420/ac245d. Stephen Boyd, Neal Parikh, Eric Chu, Borja Peleato, and Jonathan Eckstein. Distributed optimization and statistical learning via the alternating direction method of multipliers.Foundations and Trends in Machine Learning, 3(1):1–122,
-
[2]
doi: 10.1561/2200000016. URL https://doi.org/10. 1561/2200000016. Kristian Bredies, Karl Kunisch, and Thomas Pock. Total generalized variation.SIAM Journal on Imaging Sciences, 3(3):492–526,
-
[3]
Total generalized variation.SIAM J
doi: 10.1137/090769521. Yutian Chen, Xingyou Song, Chansoo Lee, Zi Wang, Qiuyi Zhang, David Dohan, Kazuya Kawakami, Greg Kochanski, Arnaud Doucet, Marc’Aurelio Ranzato, Sagi Perel, and Nando de Freitas. Towards learning universal hyperparameter optimiz- ers with transformers. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[4]
URL https://proceedings.neurips.cc/paper_files/paper/2022/ hash/cf6501108fced72ee5c47e2151c4e153-Abstract-Conference.html. Adam Coates, Andrew Y . Ng, and Honglak Lee. An analysis of single-layer networks in unsupervised feature learning. InProceedings of the Fourteenth International Conference on Artificial Intelli- gence and Statistics, volume 15 ofProc...
work page 2022
-
[5]
doi: 10.1109/CVPR.2009.5206848. Eastman Kodak Company. Kodak Lossless True Color Image Suite (PhotoCD PCD0992). http: //r0k.us/graphics/kodak/,
-
[6]
Chelsea Finn, Pieter Abbeel, and Sergey Levine
URLhttps://arxiv.org/abs/1802.02219. Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. InProceedings of the International Conference on Machine Learning (ICML), volume 70 ofProceedings of Machine Learning Research, pages 1126–1135. PMLR,
-
[7]
doi: 10.1137/080725891. Gene H. Golub, Michael Heath, and Grace Wahba. Generalized cross-validation as a method for choosing a good ridge parameter.Technometrics, 21(2):215–223,
-
[8]
doi: 10.1080/00401706. 1979.10489751. URLhttps://doi.org/10.1080/00401706.1979.10489751. David Ha, Andrew Dai, and Quoc V . Le. Hypernetworks. InInternational Conference on Learning Representations (ICLR),
-
[9]
URLhttps://doi.org/10.1137/1034115
doi: 10.1137/1034115. URLhttps://doi.org/10.1137/1034115. Jeremy Howard and Sebastian Ruder. Universal language model fine-tuning for text classification. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 328–339,
-
[10]
doi: 10.18653/v1/P18-1031. URL https: //aclanthology.org/P18-1031/. Jia-Bin Huang, Abhishek Singh, and Narendra Ahuja. Single image super-resolution from transformed self-exemplars. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 5197–5206,
-
[11]
doi: 10.1109/cvpr.2015.7299156. URL https://doi.org/10.1109/cvpr. 2015.7299156. 10 Xu Jia, Bert De Brabandere, Tinne Tuytelaars, and Luc Van Gool. Dynamic fil- ter networks. InAdvances in Neural Information Processing Systems (NeurIPS), pages 667–675,
-
[12]
Alex Kendall, Yarin Gal, and Roberto Cipolla
URL https://papers.nips.cc/paper/2016/hash/ 8bf1211fd4b7b94528899de0a43b9fb3-Abstract.html. Alex Kendall, Yarin Gal, and Roberto Cipolla. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7482–7491,
work page 2016
-
[13]
doi: 10.1109/CVPR.2018.00781. J. C. De los Reyes, Carola-Bibiane Schönlieb, and Tuomo Valkonen. Bilevel parameter learning for higher-order total variation regularisation models.Journal of Mathematical Imaging and Vision, 57(1):1–25,
-
[14]
Ilya Loshchilov and Frank Hutter
doi: 10.1007/s10851-016-0662-8. Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Confer- ence on Learning Representations (ICLR),
-
[15]
doi: 10.1109/TIP.2016.2631888. David R. Martin, Charless C. Fowlkes, Doron Tal, and Jitendra Malik. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. InProceedings of the IEEE International Conference on Computer Vision (ICCV), volume 2, pages 416–423,
-
[16]
Stereo matching with transparency and matting,
doi: 10.1109/ICCV .2001.937655. URL https://doi. org/10.1109/ICCV.2001.937655. Alex Nichol, Joshua Achiam, and John Schulman. On first-order meta-learning algorithms,
-
[17]
URLhttps://arxiv.org/abs/1803.02999. S. Ramani, T. Blu, and M. Unser. Monte-Carlo SURE: A black-box optimization of regularization parameters for general denoising algorithms.IEEE Transactions on Image Processing, 17(9): 1540–1554,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
doi: 10.1109/TIP.2008.2001404. Leonid I. Rudin, Stanley Osher, and Emad Fatemi. Nonlinear total variation based noise removal algo- rithms.Physica D: Nonlinear Phenomena, 60(1–4):259–268,
-
[19]
URLhttps://doi.org/10.1016/0167-2789(92)90242-f
doi: 10.1016/0167-2789(92) 90242-f. URLhttps://doi.org/10.1016/0167-2789(92)90242-f. Thanh Trung Vu, Andreas Kofler, and Kostas Papafitsoros. Deep unrolling for learning optimal spa- tially varying regularisation parameters for total generalised variation. InLecture Notes in Computer Science, pages 282–294. Springer Nature Switzerland,
-
[20]
URLhttps://arxiv.org/abs/2502.16532
doi: 10.1007/978-3-031-92366-1_22. URLhttps://arxiv.org/abs/2502.16532. Alan Q. Wang, Adrian V . Dalca, and Mert R. Sabuncu. Computing multiple image reconstructions with a single hypernetwork.Machine Learning for Biomedical Imaging, 1(June 2022 issue):1–25,
-
[21]
URLhttps://melba-journal.org/2022:017
doi: 10.59275/j.melba.2022-e5ec. URLhttps://melba-journal.org/2022:017. Kaixuan Wei, Angelica I. Aviles-Rivero, Jingwei Liang, Ying Fu, Carola-Bibiane Schönlieb, and Hua Huang. Tuning-free plug-and-play proximal algorithm for inverse imaging prob- lems. InProceedings of the International Conference on Machine Learning (ICML), volume 119 ofProceedings of M...
-
[22]
In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp
doi: 10.1109/cvpr52729.2023.01548. URL https://doi.org/10. 1109/cvpr52729.2023.01548. 11 Yuanzhi Zhu, Kai Zhang, Jingyun Liang, Jiezhang Cao, Bihan Wen, Radu Timofte, and Luc Van Gool. Denoising diffusion models for plug-and-play image restoration. InIEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 1219–1229,
-
[23]
1109/cvprw59228.2023.00129. URL https://doi.org/10.1109/cvprw59228.2023.00129. 12 The appendix is organized to support the claims made in the main paper. Section A records the experimental details, loss weighting, and additional DiffPIR numbers behind the transfer experiments. Section B reports the two architecture-validation ablations referenced in the m...
-
[24]
The details below cover the oracle construction, loss weighting, and precise numbers behind the DiffPIR few-shot figure. Oracle construction and loss weighting.All experiments use oracle labels produced by hierar- chical grid searches, with the target hyperparameter vector defined as the PSNR-maximizing setting for each image–configuration pair. All three...
work page 2018
-
[25]
as the classical per-image tuning rule for λ under additive Gaussian noise with known or estimable variance. The comparison answers two narrow questions: whether per-image adaptation matters on this classical axis, and whether HyperDn can match or exceed SURE’s quality while being far cheaper per image. For this reason, we do not use SURE for the other se...
work page 2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.