Platonic Representations in the Human Brain: Unsupervised Recovery of Universal Geometry
Pith reviewed 2026-05-21 06:04 UTC · model grok-4.3
The pith
fMRI embeddings learned separately per person can be aligned across brains using only unsupervised orthogonal rotations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
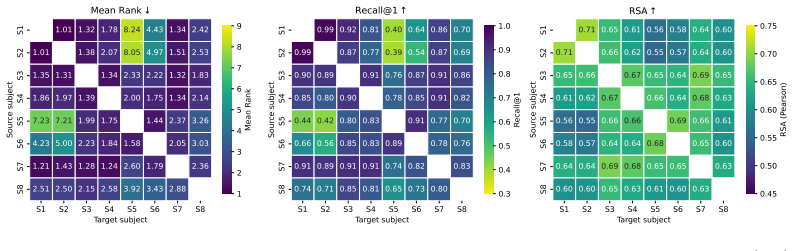
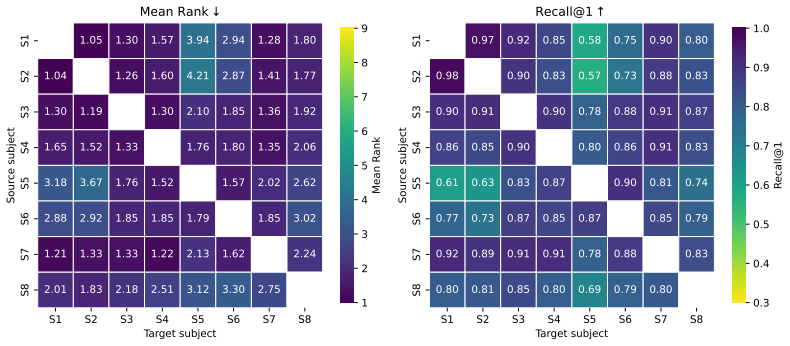
Independently learned subject-specific embeddings from fMRI can be translated across subjects using unsupervised orthogonal rotations, and synchronizing these rotations into a single shared latent space improves cross-subject retrieval, indicating that subject-specific fMRI representations are approximately isometric across individuals.
What carries the argument
Self-supervised encoder that learns subject-specific embeddings by exploiting repeated stimulus presentations within each individual.
If this is right
- Subject-specific spaces are mutually compatible with a single common coordinate system.
- Cross-subject retrieval performance rises once all pairwise rotations are synchronized to one shared space.
- Purely geometric transformations suffice to translate between brains without paired cross-subject samples or intermediate models.
- The results supply evidence that a shared neural geometry exists in human visual cortex.
Where Pith is reading between the lines
- If the geometry is approximately universal, a learned rotation matrix could in principle predict one person's brain responses to a new scene from another's responses alone.
- The same repeated-stimulus protocol could be applied to test whether comparable isometric structure appears in non-visual regions or during higher-level cognitive tasks.
- Alignment quality might degrade systematically for subjects with atypical perceptual experience, offering a potential geometric signature of individual differences.
Load-bearing premise
The self-supervised encoder recovers a faithful embedding of the stimulus geometry rather than noise or subject-specific artifacts.
What would settle it
Orthogonal rotations between subjects produce no improvement in cross-subject stimulus retrieval accuracy compared with random or identity alignments on held-out trials.
Figures

read the original abstract
The Strong Platonic Representation Hypothesis suggests that representational convergence in artificial neural networks can be harnessed constructively: embeddings can be translated across models through a universal latent space without paired data. We ask whether an analogous geometry can be recovered across human brains. Using fMRI data from the Natural Scenes Dataset, we propose a self-supervised encoder that learns subject-specific embeddings from brain data alone by exploiting repeated stimulus presentations. We show that these independently learned spaces can be translated across subjects using unsupervised orthogonal rotations, without paired cross-subject samples or intermediate model representations. Synchronizing pairwise rotations into a single shared latent space further improves cross-subject retrieval, indicating that subject-specific spaces are mutually compatible with a common coordinate system. These results provide evidence for a shared neural geometry in the human visual cortex: subject-specific fMRI representations are approximately isometric across individuals and can be translated through purely geometric transformations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a self-supervised encoder to recover subject-specific embeddings from repeated fMRI presentations in the Natural Scenes Dataset. These independently learned spaces are shown to be alignable across subjects via unsupervised orthogonal rotations without paired cross-subject data; synchronizing the pairwise rotations into a single shared latent space further improves cross-subject retrieval. The results are interpreted as evidence that subject-specific fMRI representations are approximately isometric and can be translated through purely geometric transformations, supporting an analogue of the Strong Platonic Representation Hypothesis in human visual cortex.
Significance. If the central claim holds after appropriate controls, the work would provide novel evidence for a shared, stimulus-independent neural geometry across individuals that can be recovered in a fully unsupervised manner. This would strengthen analogies between biological and artificial representations and could inform subject-general decoding methods. The unsupervised, paired-data-free alignment and the use of repeated-stimulus self-supervision are methodologically attractive features.
major comments (2)
- Abstract and Results: the reported improvement in cross-subject retrieval after rotation synchronization is presented without quantitative metrics, error bars, statistical tests, or baseline comparisons, making it impossible to evaluate the effect size or rule out that the gain is driven by trivial shared stimulus-evoked variance rather than intrinsic geometry.
- Methods (self-supervised encoder section): because every subject views the identical Natural Scenes Dataset images, any encoder that extracts stimulus-driven signals will produce alignable spaces; the manuscript contains no control (e.g., comparison against a supervised decoder, correlation with independently measured stimulus distances, or a null model using only low-level visual features) that would falsify the alternative explanation that alignment reflects common response patterns rather than a universal Platonic geometry.
minor comments (1)
- Abstract: the phrase 'Strong Platonic Representation Hypothesis' is introduced without a concise definition or citation to the original ANN literature, which may confuse readers unfamiliar with the analogy.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the presentation and controls.
read point-by-point responses
-
Referee: Abstract and Results: the reported improvement in cross-subject retrieval after rotation synchronization is presented without quantitative metrics, error bars, statistical tests, or baseline comparisons, making it impossible to evaluate the effect size or rule out that the gain is driven by trivial shared stimulus-evoked variance rather than intrinsic geometry.
Authors: We agree that the main-text description of the synchronization improvement would benefit from explicit quantification. In the revised manuscript we will expand the Results section to report mean cross-subject retrieval accuracies (with standard errors across subjects), paired statistical tests comparing synchronized versus unsynchronized rotations, and baseline comparisons including random orthogonal matrices and a stimulus-average null model. These additions will allow direct evaluation of effect size and help address whether gains exceed those attributable to shared stimulus-evoked responses. revision: yes
-
Referee: Methods (self-supervised encoder section): because every subject views the identical Natural Scenes Dataset images, any encoder that extracts stimulus-driven signals will produce alignable spaces; the manuscript contains no control (e.g., comparison against a supervised decoder, correlation with independently measured stimulus distances, or a null model using only low-level visual features) that would falsify the alternative explanation that alignment reflects common response patterns rather than a universal Platonic geometry.
Authors: This concern is well-taken and highlights a possible confound. While the self-supervised objective uses repeat consistency to encourage stable representations, we will add the requested controls in the revised Methods and Results: (i) direct comparison of alignment performance against a supervised decoder trained on stimulus labels, (ii) correlation analyses between the learned embeddings and distances computed from low-level visual features (e.g., Gabor or pixel-based metrics), and (iii) a null model that permutes repeat identities during training. These will be presented alongside the main alignment results to help distinguish geometric compatibility from purely stimulus-driven commonality. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The paper trains subject-specific self-supervised encoders independently on repeated stimulus presentations within each subject to produce embeddings, then applies post-hoc unsupervised orthogonal rotations to align those spaces and evaluates cross-subject retrieval. No equation or step reduces the claimed isometry or shared latent space to a definitional identity, fitted parameter renamed as prediction, or self-citation chain; the geometric alignment operates on independently derived representations without presupposing the target geometry in the training objective. The process is externally falsifiable via retrieval metrics and does not invoke load-bearing uniqueness theorems from the authors' prior work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Repeated presentations of the same stimulus produce consistent enough brain responses to allow self-supervised embedding learning per subject.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective / embed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We show that these independently learned spaces can be translated across subjects using unsupervised orthogonal rotations... synchronizing pairwise rotations into a single shared latent space
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
subject-specific fMRI representations are approximately isometric across individuals
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Linguistic regularities in continuous space word representations
Tomas Mikolov, Wen-tau Yih, and Geoffrey Zweig. Linguistic regularities in continuous space word representations. InProceedings of the 2013 Conference of the North American Chapter of the Associ- ation for Computational Linguistics: Human Language Technologies, pages 746–751. Association for Computational Linguistics, 2013
work page 2013
-
[2]
Maithra Raghu, Justin Gilmer, Jason Yosinski, and Jascha Sohl-Dickstein. Svcca: singular vector canonical correlation analysis for deep learning dynamics and interpretability. InProceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 6078–6087, Red Hook, NY , USA,
- [3]
-
[4]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InInternational Conference on Machine Learning (ICML), volume 97, pages 3519–3529, 2019
work page 2019
-
[5]
Love, Christopher J Cueva, Erin Grant, Iris Groen, Jascha Achterberg, Joshua B
Ilia Sucholutsky, Lukas Muttenthaler, Adrian Weller, Andi Peng, Andreea Bobu, Been Kim, Bradley C. Love, Christopher J Cueva, Erin Grant, Iris Groen, Jascha Achterberg, Joshua B. Tenenbaum, Kather- ine M. Collins, Katherine Hermann, Kerem Oktar, Klaus Greff, Martin N Hebart, Nathan Cloos, Nikolaus Kriegeskorte, Nori Jacoby, Qiuyi Zhang, Raja Marjieh, Robe...
work page 2025
-
[6]
The platonic representation hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. The platonic representation hypothesis. InProceedings of the 41st International Conference on Machine Learning. JMLR.org, 2024
work page 2024
-
[7]
Harnessing the universal geometry of embeddings
Rishi Dev Jha, Collin Zhang, Vitaly Shmatikov, and John Xavier Morris. Harnessing the universal geometry of embeddings. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[8]
mini-vec2vec: Scaling universal geometry alignment with linear transformations, 2026
Guy Dar. mini-vec2vec: Scaling universal geometry alignment with linear transformations, 2026. URL https://arxiv.org/abs/2510.02348
-
[9]
Revisiting model stitching to compare neural repre- sentations
Yamini Bansal, Preetum Nakkiran, and Boaz Barak. Revisiting model stitching to compare neural repre- sentations. In A. Beygelzimer, Y . Dauphin, P. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, 2021. URLhttps://openreview.net/forum?id=ak06J5jNR4
work page 2021
-
[10]
Representation potentials of foundation models for multimodal alignment: A survey
Jianglin Lu, Hailing Wang, Yi Xu, Yizhou Wang, Kuo Yang, and Yun Fu. Representation potentials of foundation models for multimodal alignment: A survey. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 16669–16684. Association for Computational Linguistics, 2025. ISBN 979-8-89176-332-6. doi: 10.18653/v1/2025.e...
-
[11]
Uri Hasson, Yuval Nir, Ifat Levy, Galit Fuhrmann, and Rafael Malach. Intersubject synchronization of cortical activity during natural vision.Science, 303(5664):1634–1640, 2004. doi: 10.1126/science.1089506
-
[12]
Samuel A Nastase, Valeria Gazzola, Uri Hasson, and Christian Keysers. Measuring shared responses across subjects using intersubject correlation.Social Cognitive and Affective Neuroscience, 14(6):667–685,
-
[13]
doi: 10.1093/scan/nsz037
-
[14]
Representational similarity analysis - connecting the branches of systems neuroscience,
Nikolaus Kriegeskorte, Marieke Mur, and Peter A. Bandettini. Representational similarity analysis – connecting the branches of systems neuroscience.Frontiers in Systems Neuroscience, 2, 2008. doi: 10.3389/neuro.06.004.2008
-
[15]
Baihan Lin and Nikolaus Kriegeskorte. The topology and geometry of neural representations.Proceedings of the National Academy of Sciences, 121(42):e2317881121, 2024. doi: 10.1073/pnas.2317881121. URL https://www.pnas.org/doi/abs/10.1073/pnas.2317881121. 10
-
[16]
James V . Haxby, J. Swaroop Guntupalli, Andrew C. Connolly, Yaroslav O. Halchenko, Bryan R. Conroy, M. Ida Gobbini, Michael Hanke, and Peter J. Ramadge. A common, high-dimensional model of the representational space in human ventral temporal cortex.Neuron, 72(2):404–416, 2011. doi: 10.1016/j. neuron.2011.08.026
work page doi:10.1016/j 2011
-
[17]
Swaroop Guntupalli, Michael Hanke, Yaroslav O
J. Swaroop Guntupalli, Michael Hanke, Yaroslav O. Halchenko, Andrew C. Connolly, Peter J. Ramadge, and James V . Haxby. A model of representational spaces in human cortex.Cerebral Cortex, 26(6): 2919–2934, 2016. doi: 10.1093/cercor/bhw068
-
[18]
CLIP-MUSED: CLIP-guided multi- subject visual neural information semantic decoding
Qiongyi Zhou, Changde Du, Shengpei Wang, and Huiguang He. CLIP-MUSED: CLIP-guided multi- subject visual neural information semantic decoding. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=lKxL5zkssv
work page 2024
-
[19]
Functional brain-to-brain transformation without shared stimuli.NeuroImage, 327:121741, 2026
Navve Wasserman, Roman Beliy, Roy Urbach, and Michal Irani. Functional brain-to-brain transformation without shared stimuli.NeuroImage, 327:121741, 2026. doi: 10.1016/j.neuroimage.2026.121741
-
[20]
Allen, Ghislain St-Yves, Yihan Wu, Jesse L
Emily J. Allen, Ghislain St-Yves, Yihan Wu, Jesse L. Breedlove, Jacob S. Prince, Logan T. Dowdle, Matthias Nau, Brad Caron, Franco Pestilli, Ian Charest, J. Benjamin Hutchinson, Thomas Naselaris, and Kendrick Kay. A massive 7t fMRI dataset to bridge cognitive neuroscience and artificial intelligence. Nature Neuroscience, 25(1):116–126, 2022. doi: 10.1038/...
-
[21]
Thomas T. Liu. Noise contributions to the fmri signal: An overview.NeuroImage, 143:141–151, 2016. doi: 10.1016/j.neuroimage.2016.09.008
-
[22]
Improving the accuracy of single-trial fmri response estimates using glmsingle.eLife, 11:e77599, nov
Jacob S Prince, Ian Charest, Jan W Kurzawski, John A Pyles, Michael J Tarr, and Kendrick N Kay. Improving the accuracy of single-trial fmri response estimates using glmsingle.eLife, 11:e77599, nov
-
[24]
Furkan Ozcelik and Rufin VanRullen. Natural scene reconstruction from fmri signals using generative latent diffusion.Scientific Reports, 13(1):15666, Sep 2023. doi: 10.1038/s41598-023-42891-8
-
[25]
Reconstructing the mind’s eye: fMRI-to-image with contrastive learning and diffusion priors
Paul Steven Scotti, Atmadeep Banerjee, Jimmie Goode, Stepan Shabalin, Alex Nguyen, Cohen Ethan, Aidan James Dempster, Nathalie Verlinde, Elad Yundler, David Weisberg, Kenneth Norman, and Tan- ishq Mathew Abraham. Reconstructing the mind’s eye: fMRI-to-image with contrastive learning and diffusion priors. InThirty-seventh Conference on Neural Information P...
work page 2023
-
[26]
J. R. KETTENRING. Canonical analysis of several sets of variables.Biometrika, 58(3):433–451, 1971. doi: 10.1093/biomet/58.3.433
-
[27]
Regularized generalized canonical correlation analysis.Psy- chometrika, 76(2):257–284, 2011
Arthur Tenenhaus and Michel Tenenhaus. Regularized generalized canonical correlation analysis.Psy- chometrika, 76(2):257–284, 2011
work page 2011
-
[28]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding, 2019. URLhttps://arxiv.org/abs/1807.03748
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[29]
Paul J. Besl and Neil D. McKay. A method for registration of 3-d shapes.IEEE Trans. Pattern Anal. Mach. Intell., 14(2), 1992. doi: 10.1109/34.121791
-
[30]
A. Singer. Angular synchronization by eigenvectors and semidefinite programming.Applied and Compu- tational Harmonic Analysis, 30(1):20–36, 2011. doi: 10.1016/j.acha.2010.02.001
-
[31]
Lanhui Wang and Amit Singer. Exact and stable recovery of rotations for robust synchronization.Informa- tion and Inference: A Journal of the IMA, 2:145–193, 10 2013. doi: 10.1093/imaiai/iat005
-
[32]
Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C
Tsung-Yi Lin, Michael Maire, Serge J. Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. Microsoft COCO: Common objects in context. InEuropean Conference on Computer Vision (ECCV), pages 740–755, 2014
work page 2014
-
[33]
Jacob S. Prince, Ian Charest, Jan W. Kurzawski, John A. Pyles, Michael J. Tarr, and Kendrick N. Kay. Improving the accuracy of single-trial fMRI response estimates using GLMsingle.eLife, 11, 2022. doi: 10.7554/eLife.77599
-
[34]
On deep multi-view representation learning
Weiran Wang, Raman Arora, Karen Livescu, and Jeff Bilmes. On deep multi-view representation learning. InProceedings of the 32nd International Conference on Machine Learning, volume 37, pages 1083–1092,
-
[35]
URLhttps://proceedings.mlr.press/v37/wangb15.html
-
[36]
Deep canonical correlation analysis
Galen Andrew, Raman Arora, Jeff Bilmes, and Karen Livescu. Deep canonical correlation analysis. In Proceedings of the 30th International Conference on Machine Learning, volume 28, pages 1247–1255,
-
[37]
URLhttps://proceedings.mlr.press/v28/andrew13.html. 11
-
[38]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patrick L...
work page 2024
-
[39]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning (ICML), pages 8748–8763, 2021
work page 2021
-
[40]
Andreas Peter Steiner, Alexander Kolesnikov, Xiaohua Zhai, Ross Wightman, Jakob Uszkoreit, and Lucas Beyer. How to train your ViT? data, augmentation, and regularization in vision transformers.Transactions on Machine Learning Research, 2022. URLhttps://openreview.net/forum?id=4nPswr1KcP
work page 2022
-
[41]
Sentence-BERT: Sentence embeddings using Siamese BERT-networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using Siamese BERT-networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992,
work page 2019
-
[42]
doi: 10.18653/v1/D19-1410
-
[43]
Yixuan Li, Jason Yosinski, Jeff Clune, Hod Lipson, and John Hopcroft. Convergent learning: Do different neural networks learn the same representations? InProceedings of the 1st International Workshop on Feature Extraction: Modern Questions and Challenges at NIPS 2015, volume 44 ofProceedings of Machine Learning Research, pages 196–212. PMLR, 2015
work page 2015
-
[44]
Gromov-Wasserstein alignment of word embedding spaces
David Alvarez-Melis and Tommi Jaakkola. Gromov-Wasserstein alignment of word embedding spaces. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1881–1890. Association for Computational Linguistics, 2018. doi: 10.18653/v1/D18-1214
-
[45]
Unsupervised alignment of embeddings with wasserstein procrustes
Edouard Grave, Armand Joulin, and Quentin Berthet. Unsupervised alignment of embeddings with wasserstein procrustes. InProceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics, volume 89 ofProceedings of Machine Learning Research, pages 1880–1890, 2019
work page 2019
-
[46]
Relative representations enable zero-shot latent space communication
Luca Moschella, Valentino Maiorca, Marco Fumero, Antonio Norelli, Francesco Locatello, and Emanuele Rodolà. Relative representations enable zero-shot latent space communication. InThe Eleventh Interna- tional Conference on Learning Representations, 2023. URL https://openreview.net/forum?id= SrC-nwieGJ
work page 2023
-
[47]
Word translation without parallel data
Guillaume Lample, Alexis Conneau, Marc’Aurelio Ranzato, Ludovic Denoyer, and Hervé Jégou. Word translation without parallel data. InInternational Conference on Learning Representations, 2018. URL https://openreview.net/forum?id=H196sainb
work page 2018
-
[48]
Pablo Marcos-Manchón and Lluís Fuentemilla. Shared representations in brains and models reveal a two-route cortical organization during scene perception.Communications Biology, May 2026. doi: 10.1038/s42003-026-10169-0
-
[49]
Janice Chen, Yuan Chang Leong, Christopher J. Honey, Chung H. Yong, Kenneth A. Norman, and Uri Hasson. Shared memories reveal shared structure in neural activity across individuals.Nature Neuroscience, 20(1):115–125, 2017. doi: 10.1038/nn.4450
-
[50]
Jörn Diedrichsen and Nikolaus Kriegeskorte. Representational models: A common framework for understanding encoding, pattern-component, and representational-similarity analysis.PLOS Computational Biology, 13(4):1–33, 2017. doi: 10.1371/journal.pcbi.1005508
-
[51]
Daiki Nakamura, Shizuo Kaji, Ryota Kanai, and Ryusuke Hayashi. Unsupervised method for representation transfer from one brain to another.Frontiers in Neuroinformatics, V olume 18 - 2024, 2024. doi: 10.3389/ fninf.2024.1470845
-
[52]
T. Bazeille, H. Richard, H. Janati, and B. Thirion. Local optimal transport for functional brain template estimation. In Albert C. S. Chung, James C. Gee, Paul A. Yushkevich, and Siqi Bao, editors,Information Processing in Medical Imaging, pages 237–248. Springer International Publishing, 2019
work page 2019
-
[53]
Thomas Bazeille, Elizabeth DuPre, Hugo Richard, Jean-Baptiste Poline, and Bertrand Thirion. An empirical evaluation of functional alignment using inter-subject decoding.NeuroImage, 245:118683, 2021. doi: 10.1016/j.neuroimage.2021.118683. 12
-
[54]
Daniel L. K. Yamins, Ha Hong, Charles F. Cadieu, Ethan A. Solomon, Darren Seibert, and James J. DiCarlo. Performance-optimized hierarchical models predict neural responses in higher visual cortex.Proceedings of the National Academy of Sciences, 111(23):8619–8624, 2014. doi: 10.1073/pnas.1403112111
-
[55]
Seyed-Mahdi Khaligh-Razavi and Nikolaus Kriegeskorte. Deep supervised, but not unsupervised, models may explain IT cortical representation.PLOS Computational Biology, 10(11):1–29, 2014. doi: 10.1371/ journal.pcbi.1003915
work page 2014
-
[56]
Radoslaw Martin Cichy, Aditya Khosla, Dimitrios Pantazis, Antonio Torralba, and Aude Oliva. Comparison of deep neural networks to spatio-temporal cortical dynamics of human visual object recognition reveals hierarchical correspondence.Scientific Reports, 6(1):27755, 2016. doi: 10.1038/srep27755
-
[57]
Martin Schrimpf, Jonas Kubilius, Michael J. Lee, N. Apurva Ratan Murty, Robert Ajemian, and James J. DiCarlo. Integrative benchmarking to advance neurally mechanistic models of human intelligence.Neuron, 108(3):413–423, 2020. doi: 10.1016/j.neuron.2020.07.040
-
[58]
Charlotte Caucheteux and Jean-Rémi King. Brains and algorithms partially converge in natural language processing.Communications Biology, 5(1):134, 2022. doi: 10.1038/s42003-022-03036-1
-
[59]
Talia Konkle and George A. Alvarez. A self-supervised domain-general learning framework for human ven- tral stream representation.Nature Communications, 13(1):491, 2022. doi: 10.1038/s41467-022-28091-4
-
[60]
Wang, Kendrick Kay, Thomas Naselaris, Michael J
Aria Y . Wang, Kendrick Kay, Thomas Naselaris, Michael J. Tarr, and Leila Wehbe. Better models of human high-level visual cortex emerge from natural language supervision with a large and diverse dataset. Nature Machine Intelligence, 5(12):1415–1426, 2023. doi: 10.1038/s42256-023-00753-y
-
[61]
Kietzmann, Emily Allen, Yihan Wu, Thomas Naselaris, Kendrick Kay, and Ian Charest
Adrien Doerig, Tim C. Kietzmann, Emily Allen, Yihan Wu, Thomas Naselaris, Kendrick Kay, and Ian Charest. High-level visual representations in the human brain are aligned with large language models. Nature Machine Intelligence, pages 1220–1234, 2025. doi: 10.1038/s42256-025-01072-0
-
[62]
Colin Conwell, Jacob S. Prince, Kendrick N. Kay, George A. Alvarez, and Talia Konkle. A large-scale examination of inductive biases shaping high-level visual representation in brains and machines.Nature Communications, 15(1):9383, 2024. doi: 10.1038/s41467-024-53147-y
-
[63]
Zirui Chen and Michael F. Bonner. Universal dimensions of visual representation.Science Advances, 11 (27):eadw7697, 2025. doi: 10.1126/sciadv.adw7697
-
[64]
Matthew F. Glasser, Timothy S. Coalson, Emma C. Robinson, Carl D. Hacker, John Harwell, Essa Yacoub, Kamil Ugurbil, Jesper Andersson, Christian F. Beckmann, Mark Jenkinson, Stephen M. Smith, and David C. Van Essen. A multi-modal parcellation of human cerebral cortex.Nature, 536(7615):171–178, 2016. doi: 10.1038/nature18933
-
[65]
Liang Wang, Ryan E.B. Mruczek, Michael J. Arcaro, and Sabine Kastner. Probabilistic maps of visual topography in human cortex.Cerebral Cortex, 25(10):3911–3931, 2015. doi: 10.1093/cercor/bhu277
- [66]
-
[67]
Neural rays for occlusion-aware image-based rendering,
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15979–15988, 2022. doi: 10.1109/CVPR52688.2022.01553. 13 Appendix A fMRI preprocessing details For all main analyses, we use the Natural Scenes D...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.