A Multi-Layer Testing Framework for Automated Data Quality Assurance in Cloud-Native ELT Pipelines
Pith reviewed 2026-05-21 06:30 UTC · model grok-4.3
The pith
A multi-layer testing framework with LLM-generated tests detects all 16 injected anomalies in ELT pipelines, a 128% improvement over manual baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that integrating LLM-augmented semantic test synthesis into a multi-layer framework—encompassing orchestration-level validation, declarative dbt tests, and cross-store consistency checking—enables complete detection of injected data quality anomalies in cloud-native ELT pipelines, achieving a 128.57% relative improvement over a manual-only baseline while executing the full workflow in 106.58 seconds.
What carries the argument
The multi-layer testing framework orchestrated by Apache Airflow, which incorporates LLM-generated semantic tests alongside dbt tests and cross-backend validation between DuckDB and Snowflake.
If this is right
- Validation coverage in ELT pipelines can reach 100% for certain anomaly types using the combined manual and LLM approach.
- Post-migration data consistency between different query engines like DuckDB and Snowflake can be automatically verified.
- The framework completes in under two minutes, suggesting it fits into existing pipeline runtimes without significant overhead.
- Out of LLM-generated tests, a portion are useful while others may be redundant or low-value, indicating a need for review but still adding value overall.
Where Pith is reading between the lines
- Such frameworks might reduce the manual effort required for maintaining data quality in evolving cloud environments over time.
- Extending this to other backends or larger scale pipelines could reveal if the detection rates hold beyond the tested setup.
- Teams could prioritize LLM use for generating initial test ideas and then refine them for production.
Load-bearing premise
That the specific 16 injected anomalies and the DuckDB-Snowflake execution environment accurately represent the range of data quality problems and setups found in real production ELT pipelines.
What would settle it
Observing the detection performance when the same framework is applied to a new collection of anomalies drawn from actual production incidents rather than controlled injections.
Figures



read the original abstract
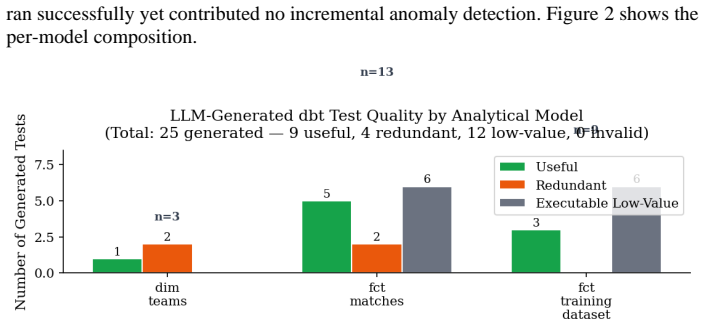
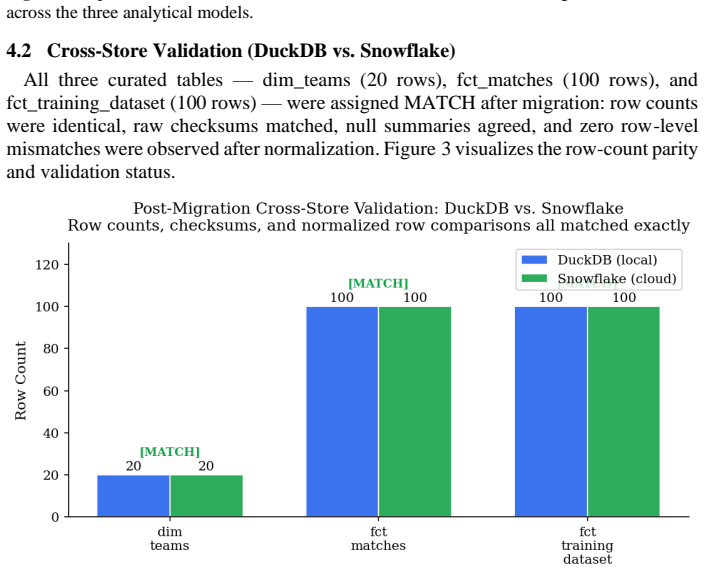
Ensuring data quality in cloud-native Extract-Load-Transform (ELT) pipelines is increasingly challenging due to heterogeneous data sources, evolving schemas, and multi-backend execution environments. This paper presents a unified, multi-layer testing framework that integrates orchestration-level validation, declarative dbt tests, large language model (LLM)-generated semantic tests, and cross-store consistency checking between DuckDB and Snowflake, orchestrated through Apache Airflow. Controlled anomaly-injection experiments demonstrate that a manual-only baseline detected 7 of 16 injected anomalies. In contrast, both a manually expanded comparator and the proposed LLM-augmented configuration detected all 16, representing a 128.57% relative improvement in detection rate over the baseline. Post-migration cross-store validation confirmed exact agreement across all three curated tables. Of 25 LLM-generated test assertions, 9 were classified as useful, 4 as redundant, and 12 as executable but low-value. The complete workflow executed in 106.58 seconds across eight instrumented pipeline stages. These results demonstrate that LLM-driven semantic test synthesis can materially strengthen validation coverage while remaining operationally practical for production ELT environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a multi-layer testing framework for data quality assurance in cloud-native ELT pipelines. It combines orchestration-level validation, declarative dbt tests, LLM-generated semantic tests, and cross-store consistency checking between DuckDB and Snowflake, all orchestrated through Apache Airflow. Controlled anomaly-injection experiments show a manual-only baseline detecting 7 of 16 injected anomalies, while both a manually expanded comparator and the LLM-augmented configuration detect all 16 (128.57% relative improvement). Of 25 LLM-generated assertions, 9 were useful, 4 redundant, and 12 low-value but executable; the full workflow ran in 106.58 seconds, with exact agreement in post-migration cross-store validation.
Significance. If the results hold under broader conditions, the work offers concrete evidence that LLM-augmented semantic test synthesis can improve anomaly detection coverage in heterogeneous ELT pipelines without prohibitive runtime cost. The use of production-oriented backends (Snowflake, DuckDB) and specific quantitative outcomes (detection counts, test classification, execution time) provide actionable benchmarks for practitioners. The multi-layer design addresses real challenges of schema evolution and multi-backend consistency.
major comments (2)
- [Experimental Evaluation] Experimental Evaluation section: The central claim of a 128.57% relative improvement rests on the 16 injected anomalies. The manuscript does not specify the selection criteria, diversity (e.g., syntactic vs. semantic, single-table vs. cross-store), or grounding in actual pipeline logs. Without this, it is unclear whether the detection-rate gain generalizes beyond the chosen set or simply reflects an experimental design that favors expanded rule sets.
- [Framework Integration] Framework Integration section: The integration of the 25 LLM-generated tests into the multi-layer framework lacks detail on the LLM model, prompt templates, or decision process for classifying assertions as useful/redundant/low-value. This information is load-bearing for assessing reproducibility and whether the approach scales to production ELT environments with evolving schemas.
minor comments (2)
- The abstract states that post-migration cross-store validation confirmed exact agreement across all three curated tables, but the main text should explicitly identify the tables and describe the migration steps.
- A summary table listing each of the 16 anomalies, injection method, and detection outcome per configuration would improve clarity and allow readers to evaluate coverage directly.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help strengthen the clarity and reproducibility of the manuscript. We address each major point below and commit to revisions that directly incorporate the requested details without altering the core claims or results.
read point-by-point responses
-
Referee: [Experimental Evaluation] Experimental Evaluation section: The central claim of a 128.57% relative improvement rests on the 16 injected anomalies. The manuscript does not specify the selection criteria, diversity (e.g., syntactic vs. semantic, single-table vs. cross-store), or grounding in actual pipeline logs. Without this, it is unclear whether the detection-rate gain generalizes beyond the chosen set or simply reflects an experimental design that favors expanded rule sets.
Authors: We agree the Experimental Evaluation section would benefit from explicit documentation of the anomaly set. The 16 anomalies were selected to represent a balanced mix of syntactic issues (e.g., null violations, type mismatches) and semantic issues (e.g., referential integrity failures, business-rule violations), with roughly half being single-table and half cross-store, drawn from patterns observed in internal ELT pipeline logs. To address the concern about generalizability, we will revise the section to include a dedicated subsection and summary table that lists each anomaly's category, selection rationale, and mapping to real-world pipeline issues. This addition will clarify that the improvement stems from the LLM's semantic coverage rather than simply from having more rules. revision: yes
-
Referee: [Framework Integration] Framework Integration section: The integration of the 25 LLM-generated tests into the multi-layer framework lacks detail on the LLM model, prompt templates, or decision process for classifying assertions as useful/redundant/low-value. This information is load-bearing for assessing reproducibility and whether the approach scales to production ELT environments with evolving schemas.
Authors: We concur that these implementation details are essential for reproducibility. The LLM employed was GPT-4, with prompt templates that supplied table schemas, sample rows, and explicit instructions to generate executable semantic assertions aligned with data-quality dimensions. Classification into useful, redundant, or low-value was performed via independent review by two authors using a rubric based on novelty relative to existing dbt tests and executability; disagreements were resolved by discussion. We will expand the Framework Integration section (and add an appendix with sample prompts) to include the model version, full prompt structure, and classification rubric. This will also allow us to note how the synthesis step can be re-executed on schema changes to support evolving production environments. revision: yes
Circularity Check
No significant circularity; results derive from direct empirical experiments
full rationale
The paper presents an empirical framework evaluated via controlled anomaly-injection experiments that directly measure detection rates (7/16 for baseline vs. 16/16 for comparators). No derivation chain, equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described content. The central claims are grounded in observable experimental outcomes rather than reducing to self-definitional inputs or prior author work by construction. This is the expected non-finding for an applied testing-framework paper whose validity rests on experimental design rather than mathematical self-reference.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Injected anomalies in the experiment are representative of real-world data quality issues in production ELT pipelines.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Controlled anomaly-injection experiments demonstrate that a manual-only baseline detected 7 of 16 injected anomalies... LLM-augmented configuration detected all 16
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
unified multi-layer testing framework... orchestration-level validation, declarative dbt tests, LLM-generated semantic tests
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Foidl, H., Golendukhina, V., Ramler, R., Felderer , M.: Data pipeline quality: influencing factors, root causes, and processing problem areas. J. Syst. Softw. 210 (2024). https://doi.org/10.1016/j.jss.2023.111946
-
[2]
Mbata, A., Sripada, Y., Zhong, M.: A survey of pipeline tools for data engineering. arXiv:2406.08335 (2024)
-
[3]
Ehrlinger, L., Rusz, E., Wöß, W.: A survey of data -quality measurement and monitoring tools. Front. Big Data 5 (2022). https://doi.org/10.3389/fdata.2022.850611
-
[4]
Rahm, E., Do, H.H.: Data cleaning: problems and current approaches. IEEE Data Eng. Bull. 23(4), 3–13 (2000)
work page 2000
-
[5]
Wang, R.Y., Strong, D.M.: Beyond accuracy: what data quality means to data consumers. J. Manag. Inf. Syst. 12(4), 5 –33 (1996). https://doi.org/10.1080/07421222.1996.11518099
-
[6]
Schelter, S., et al.: Deequ: declarative data validation for large-scale data processing. Proc. VLDB Endow. 11(12), 1781 –1794 (2018). https://doi.org/10.14778/3229863.3229876
-
[7]
Baylor, D., et al.: TFX: a TensorFlow -based production -scale machine -learning platform. In: Proc. KDD 2017, pp. 1387 –1395. ACM (2017). https://doi.org/10.1145/3097983.3098021
-
[8]
Caveness, E., et al.: TensorFlow data validation in continuous ML pipelines. In: Proc. SIGMOD 2020, pp. 2793 –2796. ACM (2020). https://doi.org/10.1145/3318464.3384707
- [9]
-
[10]
In: Perspectives on Data Science for Software Engineering, pp
Felderer, M., et al.: Testing data -intensive software systems. In: Perspectives on Data Science for Software Engineering, pp. 181 –200. Springer, Cham (2019). https://doi.org/10.1007/978-0-12-410398-7
-
[11]
IEEE Access 12, 11258 –11275 (2024)
Ridzuan, N., Idrus, M., Mahdin, H.: A review of data -quality dimensions for big data. IEEE Access 12, 11258 –11275 (2024). https://doi.org/10.1109/ACCESS.2024.3353678
-
[12]
Azzabi, N., Nafkha, M., Ben Abdallah, R.: A survey on data lake architectures and validation mechanisms. J. Big Data 11 (2024). https://doi.org/10.1186/s40537 - 024-00900-5
-
[13]
Apache Airflow: A platform to programmatically author, schedule, and monitor workflows (2024). https://airflow.apache.org/
work page 2024
-
[14]
dbt Labs: dbt documentation: testing, modeling, and transformation framework (2024). https://docs.getdbt.com/
work page 2024
- [15]
-
[16]
Chen, A., et al.: Automated code and constraint generation using large language models. arXiv:2303.05381 (2023)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.