Fast Reconstruction of Exact Maxwell Dynamics from Sparse Data
Pith reviewed 2026-05-21 07:13 UTC · model grok-4.3
The pith
A neural network architecture for homogeneous electromagnetic fields embeds exact Maxwell solutions in each neuron to satisfy the equations by construction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
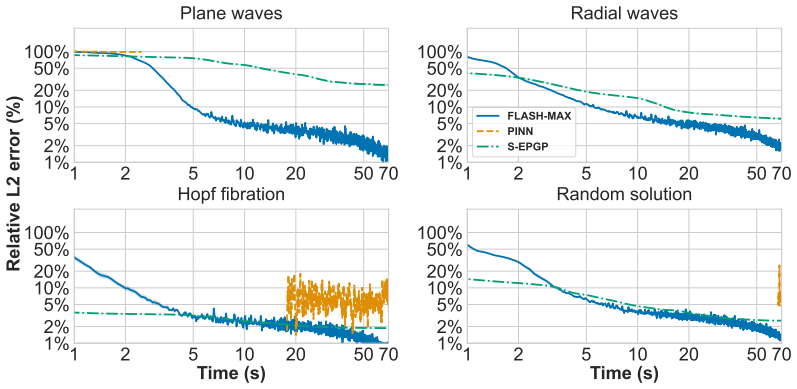
FLASH-MAX is a shallow exact-by-construction neural network for predicting homogeneous electromagnetic fields from sparse pointwise observations. Each hidden neuron represents a separate exact solution to Maxwell's equations, ensuring the network satisfies the governing equations symbolically by construction. A universal approximation result is proven, showing that this exact model class remains universal on arbitrary domains. The network reaches sub-1% relative validation error from about 1K sparse observations in seconds while maintaining a zero PDE residual, and keeps single-digit errors even for only 100 observations sampled from 3D space.
What carries the argument
The exact-by-construction hidden neurons, each representing an independent analytic solution to the homogeneous Maxwell equations, which enforce the physics directly in the network structure.
If this is right
- Training completes in seconds rather than requiring extensive optimization.
- The PDE residual remains exactly zero throughout and after training.
- Low error is achieved with as few as 100 sparse observations in three-dimensional space.
- The model class is universal, capable of approximating any homogeneous electromagnetic field on arbitrary domains.
- Sub-1 percent relative error is attainable with approximately one thousand pointwise observations.
Where Pith is reading between the lines
- Architectures of this type may be adapted for other systems of linear partial differential equations that admit known families of exact solutions.
- Real-time applications in electromagnetic sensing or imaging could benefit from the rapid training and exact compliance with the governing laws.
- The separation of the physical structure into the hypothesis class rather than the loss function offers a template for improving efficiency in other physics-constrained learning problems.
- Further work might explore how the number of neurons scales with the complexity of the field or the sparsity of the data.
Load-bearing premise
The fields being modeled must be homogeneous, without sources or material variations that would prevent the exact solutions from spanning the necessary function space.
What would settle it
Training the model on 100 random points sampled from a known homogeneous solution such as a plane wave and checking whether the output matches the true field to single-digit percent relative error while the computed curl, divergence, and other Maxwell residuals remain at machine zero.
Figures





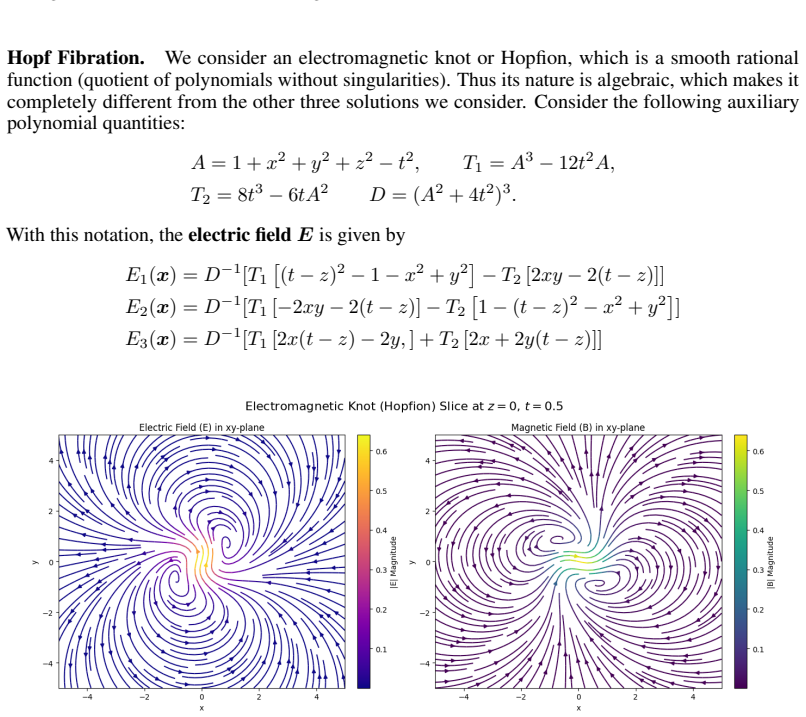


read the original abstract
We introduce FLASH-MAX, a shallow, exact-by-construction neural network architecture for predicting homogeneous electromagnetic fields from sparse pointwise observations. Each hidden neuron represents a separate exact solution to Maxwell's equations, so that the network satisfies the governing equations symbolically by construction and can be trained end-to-end from sparse data within seconds. We prove a universal approximation result showing that this exact model class remains universal on arbitrary domains. FLASH-MAX reaches sub-1% relative validation error from about 1K sparse pointwise observations in seconds, all while maintaining a zero PDE residual, and keeps single-digit errors even for only 100 observations sampled from 3D space. These results suggest that moving governing structure from the loss into the hypothesis class can dramatically improve the trade-off between precision and optimization speed in scientific machine learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FLASH-MAX, a shallow neural network architecture for reconstructing homogeneous electromagnetic fields from sparse pointwise observations. Each hidden neuron is constructed to represent an exact solution to the homogeneous Maxwell equations, so the network satisfies the governing PDEs symbolically by construction rather than through the loss. The authors report that the model can be trained end-to-end from roughly 1K sparse observations in seconds while maintaining zero PDE residual, achieves sub-1% relative validation error, and remains accurate even with only 100 observations. They also claim a universal approximation theorem establishing that this exact-by-construction model class is dense on arbitrary domains.
Significance. If the universal approximation result is rigorously established and the exactness property holds under training, the work would meaningfully advance physics-informed machine learning by moving governing equations from the loss into the hypothesis class. This could yield faster optimization and guaranteed physical consistency for sparse-data reconstruction tasks in electromagnetics. The reported performance metrics on limited observations are practically relevant, though the restriction to homogeneous source-free fields narrows the immediate applicability.
major comments (2)
- [Universal approximation theorem] Universal approximation theorem (abstract and corresponding proof section): The claim that the exact model class remains universal on arbitrary domains is load-bearing for the central contribution. For homogeneous Maxwell equations any linear combination of exact solutions is exact, yet density in the target space on a general bounded domain requires the parameterized family of solutions used in the hidden neurons to be complete with respect to the boundary conditions and topology. The manuscript must explicitly identify the solution family (e.g., plane waves, spherical harmonics, or eigenfunction expansions) and supply the completeness argument; without it the universality statement does not follow from the architectural design alone.
- [Results and experiments] Experimental validation (results section): The reported sub-1% relative error and zero residual are presented without baseline comparisons to standard PINNs or other exact-solution embeddings, without error bars across random seeds or observation samplings, and without ablation on the number of hidden neurons. These controls are necessary to substantiate that the speed and precision gains are attributable to the exact-by-construction property rather than to the specific test cases chosen.
minor comments (2)
- [Introduction and methods] Notation for the electromagnetic fields and the precise parameterization inside each hidden neuron should be introduced earlier and used consistently to aid readability.
- [Abstract] The abstract states 'sub-1% relative validation error' but does not specify the norm (L2, L-infinity, etc.) or the validation sampling strategy; this detail belongs in the main text as well.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have revised the manuscript to strengthen the presentation of the universal approximation result and the experimental validation.
read point-by-point responses
-
Referee: [Universal approximation theorem] Universal approximation theorem (abstract and corresponding proof section): The claim that the exact model class remains universal on arbitrary domains is load-bearing for the central contribution. For homogeneous Maxwell equations any linear combination of exact solutions is exact, yet density in the target space on a general bounded domain requires the parameterized family of solutions used in the hidden neurons to be complete with respect to the boundary conditions and topology. The manuscript must explicitly identify the solution family (e.g., plane waves, spherical harmonics, or eigenfunction expansions) and supply the completeness argument; without it the universality statement does not follow from the architectural design alone.
Authors: We agree that the proof requires greater explicitness to be fully rigorous. The original manuscript states that the model class is universal but does not name the specific family or detail the completeness argument in the main text. In the revision we explicitly identify the hidden neurons as parameterized plane-wave solutions (with learnable wave vectors, frequencies, and polarizations) to the source-free homogeneous Maxwell equations. We have expanded Section 4 to include a self-contained completeness argument: these plane waves are dense in the space of smooth, divergence-free vector fields on bounded Lipschitz domains (invoking the known completeness of plane-wave expansions for the Helmholtz equation together with the divergence-free constraint). The revised proof now directly shows that finite linear combinations can approximate any target field in the appropriate Sobolev norm, thereby establishing universality on arbitrary domains. revision: yes
-
Referee: [Results and experiments] Experimental validation (results section): The reported sub-1% relative error and zero residual are presented without baseline comparisons to standard PINNs or other exact-solution embeddings, without error bars across random seeds or observation samplings, and without ablation on the number of hidden neurons. These controls are necessary to substantiate that the speed and precision gains are attributable to the exact-by-construction property rather than to the specific test cases chosen.
Authors: We concur that additional controls are needed to isolate the benefit of the exact-by-construction architecture. The revised manuscript now includes direct comparisons against a standard PINN baseline and a generic neural network without the Maxwell embedding, all trained on identical sparse observation sets. We report mean and standard deviation of relative error over 10 independent random seeds for both observation sampling and weight initialization. We have also added an ablation study that varies the number of hidden neurons from 20 to 400 while keeping all other factors fixed; the results confirm that zero residual is maintained for any neuron count and that validation error plateaus beyond approximately 80 neurons. These new experiments appear in an expanded Section 5 together with the corresponding tables and figures. revision: yes
Circularity Check
No significant circularity; exactness is architectural by design
full rationale
The paper's central claim is that the network satisfies Maxwell's equations exactly by construction because each hidden neuron is defined to be an exact solution, with the PDE residual therefore identically zero without any parameter fitting or loss term enforcing it. This is a direct architectural choice rather than a derived or fitted result, and the universal approximation statement is presented as a separate theorem for the resulting model class. No equations or steps in the provided abstract reduce a prediction or theorem back to its own inputs by definition, nor do they rely on self-citations whose content is unverified or load-bearing for the exactness property. The derivation chain is therefore self-contained against external benchmarks of PDE satisfaction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The electromagnetic fields are homogeneous and satisfy the source-free Maxwell equations.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
z₀ = ±√(z₁² + z₂² + z₃²) … every expression (FLASH-MAX) satisfies Maxwell’s equations (MAX), see Lemma 4 … Theorem 1 (Universal approximation for Maxwell’s equations)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We prove a universal approximation result showing that this exact model class remains universal on arbitrary domains.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Maziar Raissi, Paris Perdikaris, and George E. Karniadakis. Physics-Informed Neural Networks: A Deep Learning Framework for Solving Forward and Inverse Problems Involving Nonlinear Partial Differential Equations.Journal of Computational Physics, 378:686–707, 2019. doi: 10.1016/j.jcp.2018.10.045
-
[2]
Marc Härkönen, Markus Lange-Hegermann, and Bogdan Rai¸ t˘a. Gaussian Process Priors for Systems of Linear Partial Differential Equations with Constant Coefficients. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 12587–12615. PMLR, 2023. URLhttps://proceedings.mlr.press/v...
work page 2023
-
[3]
Noetherian Operators in Macaulay2.Journal of Software for Algebra and Geometry, 12(1):33–41, 2022
Justin Chen, Yairon Cid-Ruiz, Marc Härkönen, Robert Krone, and Anton Leykin. Noetherian Operators in Macaulay2.Journal of Software for Algebra and Geometry, 12(1):33–41, 2022. doi: 10.2140/jsag.2022. 12.33
-
[4]
The Construction of Noetherian Operators.Journal of Algebra, 222(2):595–620, 1999
Ulrich Oberst. The Construction of Noetherian Operators.Journal of Algebra, 222(2):595–620, 1999. doi: 10.1006/jabr.1999.8035
-
[5]
Alberto Damiano, Irene Sabadini, and Daniele C. Struppa. Computational Methods for the Construction of a Class of Noetherian Operators.Experimental Mathematics, 16(1):41–53, 2007. doi: 10.1080/10586458. 2007.10128986
-
[6]
Katsusuke Nabeshima and Shinichi Tajima. Effective Algorithm for Computing Noetherian Operators of Zero-Dimensional Ideals.Applicable Algebra in Engineering, Communication and Computing, 33(6): 867–899, 2022. doi: 10.1007/s00200-022-00570-7
-
[7]
Daniel R. Grayson and Michael E. Stillman. Macaulay2, a Software System for Research in Algebraic Geometry, 2023. URLhttps://macaulay2.com
work page 2023
-
[8]
Linear PDE with Constant Coefficients
Rida Ait El Manssour, Marc Härkönen, and Bernd Sturmfels. Linear PDE with Constant Coefficients. Glasgow Mathematical Journal, 65(S1):S2–S27, 2023. doi: 10.1017/S0017089521000355
-
[9]
Yairon Cid-Ruiz and Bernd Sturmfels. Primary Decomposition with Differential Operators.International Mathematics Research Notices, 2023(14):12119–12147, 2023. doi: 10.1093/imrn/rnac178
-
[10]
Justin Chen and Yairon Cid-Ruiz. Primary Decomposition of Modules: A Computational Differential Approach.Journal of Pure and Applied Algebra, 226(10):107080, 2022
work page 2022
-
[11]
Primary Ideals and Their Differential Equations
Yairon Cid-Ruiz, Roser Homs, and Bernd Sturmfels. Primary Ideals and Their Differential Equations. Foundations of Computational Mathematics, 21(5):1363–1399, 2021. doi: 10.1007/s10208-020-09485-6
-
[12]
Noetherian operators and primary decomposition.Journal of Symbolic Computation, 110:1–23, 2022
Justin Chen, Marc Härkönen, Robert Krone, and Anton Leykin. Noetherian operators and primary decomposition.Journal of Symbolic Computation, 110:1–23, 2022. doi: 10.1016/j.jsc.2021.09.002
-
[13]
Yairon Cid-Ruiz. Noetherian operators, primary submodules and symbolic powers.Collectanea Mathe- matica, 72:175–202, 2021. doi: 10.1007/s13348-020-00285-3
-
[14]
Leon Ehrenpreis.Fourier analysis in several complex variables. Wiley, 1970
work page 1970
-
[15]
V . P. Palamodov.Linear differential operators with constant coefficients. Springer, 1970
work page 1970
-
[16]
North-Holland, 3 edition, 1990
Lars Hörmander.An Introduction to Complex Analysis in Several Variables, volume 7 ofNorth-Holland Mathematical Library. North-Holland, 3 edition, 1990
work page 1990
-
[17]
Björk.Rings of Differential Operators, volume 21 ofNorth-Holland Mathematical Library
J.-E. Björk.Rings of Differential Operators, volume 21 ofNorth-Holland Mathematical Library. North- Holland, 1979. ISBN 9780444852922
work page 1979
-
[18]
Vincent Sitzmann, Julien N. P. Martel, Alexander W. Bergman, David B. Lindell, and Gordon Wetzstein. Implicit neural representations with periodic activation functions. InAdvances in Neural Information Processing Systems, volume 33, 2020
work page 2020
-
[19]
Fourier features let networks learn high frequency functions in low dimensional domains
Matthew Tancik, Pratul Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan Barron, and Ren Ng. Fourier features let networks learn high frequency functions in low dimensional domains. InAdvances in Neural Information Processing Systems, volume 33, 2020
work page 2020
-
[20]
Random features for large-scale kernel machines
Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines. InAdvances in Neural Information Processing Systems, volume 20, 2007. 11
work page 2007
-
[21]
Yoh-Han Pao, Gwang Hoon Park, and Dejan J. Sobajic. Learning and generalization characteristics of the random vector functional-link net.Neurocomputing, 6(2):163–180, 1994. doi: 10.1016/0925-2312(94) 90053-1
-
[22]
Extreme learning machine: Theory and applica- tions.Neurocomputing, 70(1–3):489–501, 2006
Guang-Bin Huang, Qin-Yu Zhu, and Chee-Kheong Siew. Extreme learning machine: Theory and applica- tions.Neurocomputing, 70(1–3):489–501, 2006. doi: 10.1016/j.neucom.2005.12.126
-
[23]
On the spectral bias of neural networks
Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred Hamprecht, Yoshua Bengio, and Aaron Courville. On the spectral bias of neural networks. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 5301–5310. PMLR, 2019
work page 2019
-
[24]
Sifan Wang, Yujun Teng, and Paris Perdikaris. Understanding and Mitigating Gradient Flow Pathologies in Physics-Informed Neural Networks.SIAM Journal on Scientific Computing, 43(5):A3055–A3081, 2021. doi: 10.1137/20M1318043
-
[25]
Krishnapriyan, Amir Gholami, Shandian Zhe, Robert M
Aditi S. Krishnapriyan, Amir Gholami, Shandian Zhe, Robert M. Kirby, and Michael W. Mahoney. Characterizing Possible Failure Modes in Physics-Informed Neural Networks. InAdvances in Neural Information Processing Systems, volume 34, pages 26548–26560, 2021. URL https://proceedings. neurips.cc/paper/2021/hash/df438e5206f31600e6ae4af72f2725f1-Abstract.html
work page 2021
-
[26]
Pan Zhang, Yanyan Hu, Yuchen Jin, Shaogui Deng, Xuqing Wu, and Jiefu Chen. A Maxwell’s Equations Based Deep Learning Method for Time Domain Electromagnetic Simulations.IEEE Journal on Multiscale and Multiphysics Computational Techniques, 6:35–40, 2021
work page 2021
-
[27]
Pratanu Roy and Stephen T. Castonguay. Exact Enforcement of Temporal Continuity in Sequential Physics- Informed Neural Networks.Computer Methods in Applied Mechanics and Engineering, 430:117197, 2024. doi: 10.1016/j.cma.2024.117197
-
[28]
Shiyuan Piao, Hong Gu, Aina Wang, and Pan Qin. A Domain-Adaptive Physics-Informed Neural Network for Inverse Problems of Maxwell’s Equations in Heterogeneous Media.IEEE Antennas and Wireless Propagation Letters, 23(10):2905–2909, 2024. doi: 10.1109/LAWP.2024.3413851
-
[29]
Jia Guo, Haifeng Wang, Shilin Gu, and Chenping Hou. TCAS-PINN: Physics-Informed Neural Networks with a Novel Temporal Causality-Based Adaptive Sampling Method.Chinese Physics B, 33(5):050701,
-
[30]
doi: 10.1088/1674-1056/ad21f3
-
[31]
Yuan Zhang, Renxian Li, Huan Tang, Zhuoyuan Shi, Bing Wei, Shuhong Gong, Lixia Yang, and Bing Yan. Electromagnetic Scattering from a Three-Dimensional Object Using Physics-Informed Neural Network.Applied Computational Electromagnetics Society Journal, 40(2):103–111, feb 2025. doi: 10.13052/2025.ACES.J.400203
-
[32]
Journal of Mathematical Physics64(9), 091902 (2023) https://doi.org/10.1063/5
Yuyao Chen and Luca Dal Negro. Physics-Informed Neural Networks for Imaging and Parameter Retrieval of Photonic Nanostructures from Near-Field Data.APL Photonics, 7(1):010802, 2022. doi: 10.1063/5. 0072969
work page doi:10.1063/5 2022
-
[33]
Y . Deng, K. Fan, B. Jin, J. Malof, and W. J. Padilla. Physics-Informed Learning in Artificial Electromagnetic Materials.Applied Physics Reviews, 12(1):011331, 2025. doi: 10.1063/5.0232675
-
[34]
Michel Nohra and Steven Dufour. Physics-Informed Neural Networks for the Numerical Modeling of Steady-State and Transient Electromagnetic Problems with Discontinuous Media.arXiv preprint arXiv:2406.04380, 2024
-
[35]
Michel Nohra and Steven Dufour. Approximating Electromagnetic Fields in Discontinuous Media Using a Single Physics-Informed Neural Network.arXiv preprint arXiv:2407.20833, 2024
-
[36]
Shaviner, Hemanth Chandravamsi, Shimon Pisnoy, Ziv Chen, and Steven H
Gal G. Shaviner, Hemanth Chandravamsi, Shimon Pisnoy, Ziv Chen, and Steven H. Frankel. PINNs for Solving Unsteady Maxwell’s Equations: Convergence Issues and Comparative Assessment with Compact Schemes.Neural Computing and Applications, 37(29):24103–24122, 2025. doi: 10.1007/ s00521-025-11554-2
work page 2025
-
[37]
Ziv Chen, Gal G. Shaviner, Hemanth Chandravamsi, Shimon Pisnoy, Steven H. Frankel, and Uzi Pereg. Quantum Physics-Informed Neural Networks for Maxwell’s Equations: Circuit Design, “Black Hole” Barren Plateaus Mitigation, and GPU Acceleration.Quantum Machine Intelligence, 8(1):21, 2026. doi: 10.1007/s42484-026-00365-w
-
[38]
Evolutionary Optimization of Physics-Informed Neural Networks: Evo-PINN Frontiers and Opportunities
Jian Cheng Wong, Abhishek Gupta, Chin Chun Ooi, Pao-Hsiung Chiu, Jiao Liu, and Yew-Soon Ong. Evolutionary Optimization of Physics-Informed Neural Networks: Evo-PINN Frontiers and Opportunities. IEEE Computational Intelligence Magazine, 21(1):16–36, 2026. doi: 10.1109/MCI.2025.3607749. 12
-
[39]
Mixed Finite Elements inR 3.Numerische Mathematik, 35(3):315–341, 1980
Jean-Claude Nédélec. Mixed Finite Elements inR 3.Numerische Mathematik, 35(3):315–341, 1980
work page 1980
-
[40]
Ngoc Cuong Nguyen, Jaime Peraire, and Bernardo Cockburn. Hybridizable Discontinuous Galerkin Methods for the Time-Harmonic Maxwell Equations.Journal of Computational Physics, 230(19):7151– 7175, 2011
work page 2011
-
[41]
Douglas N. Arnold, Richard S. Falk, and Ragnar Winther. Finite Element Exterior Calculus, Homological Techniques, and Applications.Acta Numerica, 15:1–155, 2006
work page 2006
-
[42]
Björn Engquist and Lexing Ying. Sweeping Preconditioner for the Helmholtz Equation: Hierarchical Matrix Representation.Communications on Pure and Applied Mathematics, 64(5):697–735, 2011. doi: 10.1002/cpa.20358
-
[43]
Wolfgang Bangerth and Rolf Rannacher.Adaptive Finite Element Methods for Differential Equations. Birkhäuser Basel, Basel, 2003
work page 2003
-
[44]
Anders Logg, Kent-Andre Mardal, and Garth Wells, editors.Automated Solution of Differential Equa- tions by the Finite Element Method: The FEniCS Book, volume 84 ofLecture Notes in Computa- tional Science and Engineering. Springer Berlin, Heidelberg, 2012. ISBN 978-3-642-23099-8. doi: 10.1007/978-3-642-23099-8
-
[45]
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators.Nature Machine Intelligence, 3(3):218–229, 2021. doi: 10.1038/s42256-021-00302-5
-
[46]
Zongyi Li, Nikola Borislavov Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew M. Stuart, and Anima Anandkumar. Fourier Neural Operator for Parametric Partial Differential Equations. InInternational Conference on Learning Representations (ICLR), 2021. URL https:// openreview.net/forum?id=c8P9NQVtmnO
work page 2021
-
[47]
Zongyi Li, Hongkai Zheng, Nikola Kovachki, David Jin, Haoxuan Chen, Burigede Liu, Kamyar Aziz- zadenesheli, and Anima Anandkumar. Physics-Informed Neural Operator for Learning Partial Differential Equations.ACM/IMS Journal of Data Science, 1(3):1–27, 2024. doi: 10.1145/3648506
-
[48]
Kamyar Azizzadenesheli, Nikola Kovachki, Zongyi Li, Miguel Liu-Schiaffini, Jean Kossaifi, and Anima Anandkumar. Neural Operators for Accelerating Scientific Simulations and Design.Nature Reviews Physics, 6:320–328, 2024. doi: 10.1038/s42254-024-00712-5
-
[49]
Chen, Duane Boning, and David Z
Jiaqi Gu, Zhengqi Gao, Chenghao Feng, Hanqing Zhu, Ray T. Chen, Duane Boning, and David Z. Pan. NeurOLight: A Physics-Agnostic Neural Operator Enabling Parametric Pho- tonic Device Simulation. InAdvances in Neural Information Processing Systems, vol- ume 35, 2022. URL https://proceedings.neurips.cc/paper_files/paper/2022/hash/ 5ddfb189c022a317ff1c72e66390...
work page 2022
-
[50]
Hanqing Zhu, Wenyan Cong, Guojin Chen, Shupeng Ning, Ray T. Chen, Jiaqi Gu, and David Z. Pan. PACE: Pacing Operator Learning to Accurate Optical Field Simulation for Complicated Photonic Devices. InAdvances in Neural Information Processing Sys- tems, volume 37, 2024. URL https://papers.nips.cc/paper_files/paper/2024/hash/ 7cc16e8635e6f27c295355bd214ef8d8-...
work page 2024
-
[51]
Yannick Augenstein, Taavi Repän, and Carsten Rockstuhl. Neural Operator-Based Surrogate Solver for Free-Form Electromagnetic Inverse Design.ACS Photonics, 10(5):1547–1557, 2023. doi: 10.1021/ acsphotonics.3c00156
work page 2023
-
[52]
Sooyoung Oh, EungKyu Lee, and Sun K. Hong. Physics-Informed Deep Operator Networks for Modeling 2D Time-Domain Electromagnetic Wave Propagation in Various Media.iScience, 29(3):115076, 2026. doi: 10.1016/j.isci.2026.115076
-
[53]
Zaifan Wu, Yue You, Xian Zhou, and Fang Zhang. Accelerated Time-Domain Simulation of Complex Photonic Structures with a Data-Aware Fourier Neural Operator.Optics Communications, 604:132838,
-
[54]
doi: 10.1016/j.optcom.2025.132838
-
[55]
Christopher Leon and Alexander Scheinker. Physics-Constrained Machine Learning for Electrodynamics Without Gauge Ambiguity Based on Fourier Transformed Maxwell’s Equations.Scientific Reports, 14: 14809, 2024. doi: 10.1038/s41598-024-65650-9
-
[56]
Wilson, Yuheng Chen, Alexander V
Vaishnavi Iyer, Blake A. Wilson, Yuheng Chen, Alexander V . Kildishev, Vladimir M. Shalaev, and Alexandra Boltasseva. Deep learning in photonic device development: nuances and opportunities.npj Nanophotonics, 3:5, 2026. doi: 10.1038/s44310-025-00097-y. 13
-
[57]
Mauricio Álvarez, David Luengo, and Neil D. Lawrence. Latent Force Models. InProceedings of the Twelfth International Conference on Artificial Intelligence and Statistics, volume 5 ofProceedings of Machine Learning Research, pages 9–16. PMLR, 2009. URL https://proceedings.mlr.press/v5/ alvarez09a.html
work page 2009
-
[58]
Learning Divergence-Free and Curl-Free Vector Fields with Matrix-Valued Kernels
Ives Macêdo and Rener Castro. Learning Divergence-Free and Curl-Free Vector Fields with Matrix-Valued Kernels. Technical report, Instituto de Matemática Pura e Aplicada (IMPA), 2010
work page 2010
-
[59]
Arno Solin, Manon Kok, Niklas Wahlström, Thomas B. Schön, and Simo Särkkä. Modeling and Inter- polation of the Ambient Magnetic Field by Gaussian Processes.IEEE Transactions on Robotics, 34(4): 1112–1127, 2018. doi: 10.1109/TRO.2018.2830323
-
[60]
Carl Jidling, Niklas Wahlström, Adrian Wills, and Thomas B. Schön. Linearly Con- strained Gaussian Processes. InAdvances in Neural Information Processing Systems 30, pages 1215–1224, 2017. URL https://proceedings.neurips.cc/paper/2017/hash/ 71ad16ad2c4d81f348082ff6c4b20768-Abstract.html
work page 2017
-
[61]
Algorithmic Linearly Constrained Gaussian Processes
Markus Lange-Hegermann. Algorithmic Linearly Constrained Gaussian Processes. InAdvances in Neural Information Processing Systems 31, pages 2141–2152, 2018. URL https://proceedings.neurips. cc/paper/2018/hash/68b1fbe7f16e4ae3024973f12f3cb313-Abstract.html
work page 2018
-
[62]
Constraining Gaussian Processes to Systems of Linear Ordinary Differential Equations
Andreas Besginow and Markus Lange-Hegermann. Constraining Gaussian Processes to Systems of Linear Ordinary Differential Equations. In Sanmi Koyejo, Shakir Mohamed, Anima Agarwal, Danielle Belgrave, Kyunghyun Cho, and Alice Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 29386–29399. Curran Associates, Inc., 2022. URL https:...
work page 2022
-
[63]
Linearly Constrained Gaussian Processes with Boundary Conditions
Markus Lange-Hegermann. Linearly Constrained Gaussian Processes with Boundary Conditions. In Proceedings of The 24th International Conference on Artificial Intelligence and Statistics, volume 130 ofProceedings of Machine Learning Research, pages 1090–1098. PMLR, 2021. URL https: //proceedings.mlr.press/v130/lange-hegermann21a.html
work page 2021
-
[64]
On Boundary Conditions Parametrized by Analytic Functions
Markus Lange-Hegermann and Daniel Robertz. On Boundary Conditions Parametrized by Analytic Functions. In François Boulier, Matthew England, Timur M. Sadykov, and Evgenii V . V orozhtsov, editors, Computer Algebra in Scientific Computing, volume 13366 ofLecture Notes in Computer Science, pages 225–245. Springer, Cham, 2022. doi: 10.1007/978-3-031-14788-3_13
-
[65]
David Dalton, Alan Lazarus, Hao Gao, and Dirk Husmeier. Boundary constrained Gaussian processes for robust physics-informed machine learning of linear partial differential equations.Journal of Machine Learning Research, 25(272):1–61, 2024. URLhttp://jmlr.org/papers/v25/23-1508.html
work page 2024
- [67]
-
[68]
Xin Li, Markus Lange-Hegermann, and Bogdan Rai¸ t˘a. Gaussian Process Regression for Inverse Problems in Linear PDEs.IFAC-PapersOnLine, 59(12):196–201, 2025
work page 2025
-
[69]
Lagaris, Aristidis Likas, and Dimitrios I
Isaac E. Lagaris, Aristidis Likas, and Dimitrios I. Fotiadis. Artificial Neural Networks for Solving Ordinary and Partial Differential Equations.IEEE Transactions on Neural Networks, 9(5):987–1000, 1998. doi: 10.1109/72.712178
-
[70]
Towards understanding the effect of leak in Spiking Neural Networks,
Enrico Schiassi, Roberto Furfaro, Carl Leake, Mario De Florio, Hunter Johnston, and Daniele Mortari. Extreme Theory of Functional Connections: A Fast Physics-Informed Neural Network Method for Solving Ordinary and Partial Differential Equations.Neurocomputing, 457:334–356, 2021. doi: 10.1016/j.neucom. 2021.06.015
-
[71]
N. Sukumar and Ankit Srivastava. Exact Imposition of Boundary Conditions with Distance Functions in Physics-Informed Deep Neural Networks.Computer Methods in Applied Mechanics and Engineering, 389:114333, 2022. doi: 10.1016/j.cma.2021.114333
-
[72]
Ein Gegenstück zum Ritzschen Verfahren
Erich Trefftz. Ein Gegenstück zum Ritzschen Verfahren. InProceedings of the 2nd International Congress of Applied Mechanics, pages 131–137, Zürich, 1926
work page 1926
-
[73]
Tomi Huttunen, Petri Malinen, and Peter Monk. Solving Maxwell’s Equations Using the Ultra Weak Variational Formulation.Journal of Computational Physics, 223(2):731–758, 2007. doi: 10.1016/j.jcp. 2006.10.016. 14
-
[74]
A Survey of Trefftz Methods for the Helmholtz Equation
Ralf Hiptmair, Andrea Moiola, and Ilaria Perugia. A Survey of Trefftz Methods for the Helmholtz Equation. In Gabriel R. Barrenechea, Franco Brezzi, Andrea Cangiani, and Emmanuil H. Georgoulis, editors,Building Bridges: Connections and Challenges in Modern Approaches to Numerical Partial Differential Equations, volume 114 ofLecture Notes in Computational S...
-
[75]
Alexander Scheinker and Reeju Pokharel. Physics-Constrained 3D Convolutional Neural Networks for Electrodynamics.APL Machine Learning, 1(2):026109, 2023. doi: 10.1063/5.0132433
-
[76]
Lax.Hyperbolic Partial Differential Equations, volume 14 ofCourant Lecture Notes in Math- ematics
Peter D. Lax.Hyperbolic Partial Differential Equations, volume 14 ofCourant Lecture Notes in Math- ematics. Courant Institute of Mathematical Sciences and American Mathematical Society, 2006. ISBN 9780821835760. doi: 10.1090/cln/014
-
[77]
Rüdiger Verfürth.A Posteriori Error Estimation Techniques for Finite Element Methods. Oxford University Press, 2013
work page 2013
-
[78]
Joachim Schöberl. A posteriori error estimates for maxwell equations.Mathematics of Computation, 77 (262):633–649, 2008. doi: 10.1090/S0025-5718-07-02030-3
-
[79]
Chenkai Mao and Jonathan A. Fan. Accurate and scalable deep maxwell solvers.Proceedings of the National Academy of Sciences, 123(18):e2530330123, 2026. doi: 10.1073/pnas.2530330123. URL https://www.pnas.org/doi/abs/10.1073/pnas.2530330123
-
[80]
Tosio Kato, Marius Mitrea, Gustavo Ponce, and Michael Taylor. Extension and representation of divergence- free vector fields on bounded domains.Mathematical Research Letters, 7(5–6):643–650, 2000
work page 2000
-
[81]
Kurt Hornik, Maxwell Stinchcombe, and Halbert White. Universal Approximation of an Unknown Mapping and Its Derivatives Using Multilayer Feedforward Networks.Neural Networks, 3(5):551–560, 1990. 15 A Additional experiments A.1 Sensitivity Analysis and Ablations We evaluateFLASH-MAXwith different network widths and activation functions in Table 3. The resul...
work page 1990
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.