Collocational bootstrapping: A hypothesis about the learning of subject-verb agreement in humans and neural networks
Pith reviewed 2026-05-21 06:46 UTC · model grok-4.3
The pith
Collocational patterns in child-directed speech provide enough signal for neural networks to learn subject-verb agreement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Neural networks learn English subject-verb agreement robustly from synthetic input whose subject-verb pairings exhibit moderate variability; child-directed speech contains comparable variability, making collocational bootstrapping a viable route to agreement acquisition.
What carries the argument
Collocational bootstrapping: the use of statistical regularities in word co-occurrence to infer syntactic dependencies.
If this is right
- Children could acquire subject-verb agreement from statistical patterns without additional syntactic knowledge.
- The same range of input variability supports generalization in both artificial and potentially human learners.
- Collocational cues may be sufficient for other local syntactic dependencies in early language acquisition.
Where Pith is reading between the lines
- The same mechanism might scale to agreement in languages with richer morphology or to other dependency relations such as noun-adjective concord.
- If the variability match holds, targeted experiments could test whether children show stronger agreement learning after exposure to input with matched statistical properties.
- Models that rely solely on collocational statistics could be compared against models that incorporate additional cues to isolate the contribution of co-occurrence alone.
Load-bearing premise
Neural-network performance on controlled synthetic datasets accurately reflects the mechanisms children use to extract agreement from natural language input.
What would settle it
A measurement showing that subject-verb pairing variability in child-directed corpora lies outside the range that permits robust agreement learning in the neural-network simulations.
Figures




read the original abstract
In what ways might statistical signals in linguistic input assist with the acquisition of syntax? Here we hypothesize a mechanism called collocational bootstrapping, in which regularities in word co-occurrence patterns can provide cues to syntactic dependencies. We investigate whether this mechanism can support the acquisition of English subject-verb agreement. First, we simulate language acquisition by training neural networks on synthetic datasets that vary in how predictable their subject-verb pairings are. We find that there is a range of variability levels at which these statistical learners robustly learn subject-verb agreement. We then analyze the variability of subject-verb pairings in child-directed language, and we find that the variability in such data falls within the range that supported robust generalization in our computational simulations. Taken together, these results suggest that collocational bootstrapping is a viable learning strategy for the type of input that children receive.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper hypothesizes 'collocational bootstrapping' as a mechanism in which word co-occurrence regularities provide cues to syntactic dependencies, specifically for acquiring English subject-verb agreement. It tests this via neural network simulations on synthetic datasets that systematically vary the predictability of subject-verb pairings, identifying a range of variability levels supporting robust generalization. A corpus analysis of child-directed language then shows that its subject-verb variability falls inside the same range, leading to the claim that collocational bootstrapping is a viable strategy for the input children receive.
Significance. If the central mapping from synthetic variability range to natural child-directed speech holds, the work supplies a concrete, testable computational account of how low-level statistical signals can support syntactic acquisition without requiring innate syntactic knowledge. The dual approach of controlled simulation plus direct corpus measurement is a strength, as is the focus on a falsifiable prediction about the variability sweet spot.
major comments (2)
- [§3] §3 (Synthetic experiments): the claim that the identified variability range supports robust agreement learning rests on networks trained only on controlled subject-verb predictability while other factors are held fixed; this construction does not reproduce the correlated cues (semantic number, noun/verb morphology, prosody, sentence position) present in natural input, so the observed range may not be a faithful proxy for the learning problem children face.
- [§4] §4 (Corpus analysis): matching only a single scalar variability statistic from CHILDES data to the synthetic range is insufficient to establish viability; the paper does not report training or evaluating the same networks on actual child-directed corpora to test whether the robustness and generalization behavior observed in the synthetic setting is preserved.
minor comments (2)
- [Abstract] Abstract and §2: the term 'collocational bootstrapping' is introduced without an explicit formal definition or operationalization before the simulations are described.
- [Methods] Methods: network architectures, exact agreement metrics, and statistical criteria for 'robust' learning are described at a high level; additional detail would improve replicability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below and have revised the paper where possible to clarify our methodology and acknowledge limitations.
read point-by-point responses
-
Referee: [§3] §3 (Synthetic experiments): the claim that the identified variability range supports robust agreement learning rests on networks trained only on controlled subject-verb predictability while other factors are held fixed; this construction does not reproduce the correlated cues (semantic number, noun/verb morphology, prosody, sentence position) present in natural input, so the observed range may not be a faithful proxy for the learning problem children face.
Authors: We agree that the synthetic experiments isolate subject-verb co-occurrence predictability while holding other factors fixed and therefore do not replicate the full set of correlated cues present in natural child-directed speech. This controlled design was chosen specifically to test the contribution of collocational statistics in isolation, thereby identifying the variability range at which such statistics alone can support robust generalization. We view the resulting range as a conservative estimate, since additional cues in natural input would be expected to make learning easier rather than harder. In the revised manuscript we have added a dedicated paragraph in the discussion section that explicitly addresses this point, clarifies the scope of the synthetic results, and notes that the identified range represents a lower bound under minimal-cue conditions. revision: partial
-
Referee: [§4] §4 (Corpus analysis): matching only a single scalar variability statistic from CHILDES data to the synthetic range is insufficient to establish viability; the paper does not report training or evaluating the same networks on actual child-directed corpora to test whether the robustness and generalization behavior observed in the synthetic setting is preserved.
Authors: We acknowledge that directly training and evaluating the networks on actual CHILDES corpora would constitute a stronger and more direct test of whether the generalization behavior transfers from the synthetic setting. Our corpus analysis was intentionally limited to measuring the subject-verb variability statistic in child-directed speech so that it could be compared against the range established in the controlled simulations; this matching was the central link between the two parts of the study. We recognize that the absence of end-to-end training on naturalistic data is a genuine limitation. In the revised manuscript we have expanded the discussion section to state this limitation explicitly, to explain why full retraining on CHILDES lies outside the current scope, and to outline how such experiments could be pursued in future work. revision: partial
Circularity Check
No significant circularity: independent simulations and corpus analysis
full rationale
The paper's derivation consists of two independent empirical components: (1) training neural networks on synthetic datasets that systematically vary subject-verb predictability to identify a viable range for robust agreement learning, and (2) measuring the actual variability of subject-verb pairings in child-directed language (CHILDES) and checking whether it falls inside that range. Neither step presupposes the outcome of the other; the synthetic experiments discover the range rather than fitting it to the target conclusion, and the corpus analysis is a separate measurement. No equations, self-definitions, fitted parameters renamed as predictions, or load-bearing self-citations are present in the provided abstract or described chain. The argument is therefore self-contained and externally benchmarked against real linguistic data.
Axiom & Free-Parameter Ledger
free parameters (1)
- variability levels of subject-verb pairings
axioms (1)
- domain assumption Neural network learning on controlled synthetic input can serve as a proxy for human statistical learning of syntax
invented entities (1)
-
collocational bootstrapping
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
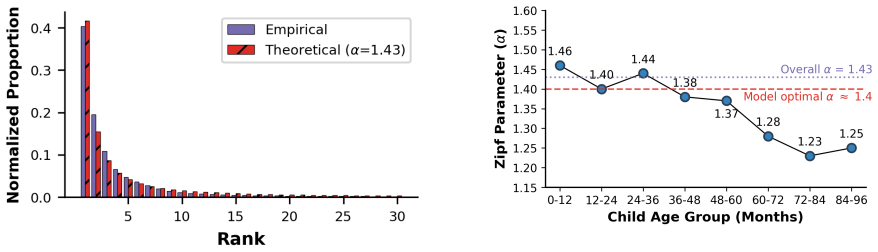
we varied the extent to which a subject could be predicted from its verb... f(r) = K / r^α ... α≈1.4 ... best-fitting value of α was α=1.43
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
collocational bootstrapping... neural networks... CHILDES
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Assessing BERT's Syntactic Abilities
The acquisition of anaphora by simple re- current networks.Language Acquisition, 20(3):181– 227. Yoav Goldberg. 2019. Assessing BERT’s syntactic abil- ities.arXiv preprint arXiv:1901.05287. Rebecca L. Gómez. 2002. Variability and detec- tion of invariant structure.Psychological Science, 13(5):431–436. Kristina Gulordava, Piotr Bojanowski, Edouard Grave, T...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[2]
Four decades of open language science: The CHILDES project.Language Teaching Research Quarterly, 44:15–30. Diederik Kingma and Jimmy Ba. 2015. Adam: A method for stochastic optimization. InInternational Conference on Learning Representations. Adhiguna Kuncoro, Chris Dyer, John Hale, Dani Yo- gatama, Stephen Clark, and Phil Blunsom. 2018. LSTMs can learn s...
work page 2015
-
[3]
A systematic framework for generating novel experimental hypotheses from language models
Assessing the ability of LSTMs to learn syntax- sensitive dependencies.Transactions of the Associa- tion for Computational Linguistics, 4:521–535. Ilya Loshchilov and Frank Hutter. 2019. Decoupled weight decay regularization. InInternational Confer- ence on Learning Representations. Brian MacWhinney. 2000.The CHILDES Project: Tools for Analyzing Talk. Law...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[4]
Data drives unstable hierarchical generaliza- tion in LMs. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Process- ing, pages 11722–11740, Suzhou, China. Association for Computational Linguistics. Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multi...
work page 2025
-
[5]
Frequency effects on syntactic rule learning in transformers. InProceedings of the 2021 Con- ference on Empirical Methods in Natural Language Processing, pages 932–948. Kenneth Wexler and Peter W. Culicover. 1980.F ormal Principles of Language Acquisition. MIT Press. Ethan Gotlieb Wilcox, Richard Futrell, and Roger Levy
work page 2021
-
[6]
Using computational models to test syntactic learnability.Linguistic Inquiry, 55(4):805–848. Elizabeth Wonnacott, Elissa L. Newport, and Michael K. Tanenhaus. 2008. Acquiring and processing verb ar- gument structure: Distributional learning in a minia- ture language.Cognitive Psychology, 56(3):165– 209. Charles Yang. 2016.The Price of Linguistic Produc- t...
- [7]
- [8]
-
[9]
oh be be very gentle with baby right
“oh be be very gentle with baby right” Age 12-24 months (α= 1.40)
- [10]
-
[11]
you don’t like MacDonald’s and I don’t like MacDonald’s
“you don’t like MacDonald’s and I don’t like MacDonald’s” Age 24-36 months (α= 1.44)
- [12]
-
[13]
let’s sit here on mama’s mama’s knee
“let’s sit here on mama’s mama’s knee” Age 36-48 months (α= 1.38)
- [14]
- [15]
- [16]
- [17]
-
[18]
there’s something wrong with her teeth aren’t there
“there’s something wrong with her teeth aren’t there” Age 60-72 months (α= 1.28)
-
[19]
well I know but you know what I think this chair is
“well I know but you know what I think this chair is”
-
[20]
so you want listen come here I’m going to tell you
“so you want listen come here I’m going to tell you”
-
[21]
I don’t think I would like those
“I don’t think I would like those” Age 70-84 months (α= 1.23)
- [22]
- [23]
-
[24]
“there’s how many bears on one wheel’ Age 84-96 months (α= 1.25)
- [25]
-
[26]
alright well if you don’t put it on then the letter’s no good
“alright well if you don’t put it on then the letter’s no good”
-
[27]
“uh what about a movie though” D Training loss See Figure 6 for the loss trajectories of the models we trained. E Data Cleaning We downloaded 5,147,586 utterances from partic- ipants categorized as English-language speakers, restricted to 25 target speaker roles: Adult, Care- taker, Father, Friend, Grandfather, Grandmother, Investigator, Mother, Narrator,...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.