Same Target, Different Basins: Hard vs. Soft Labels for Annotator Distributions
Pith reviewed 2026-05-21 06:25 UTC · model grok-4.3
The pith
Hard-label delivery outperforms soft-label training when only a small number of annotations per example are available.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
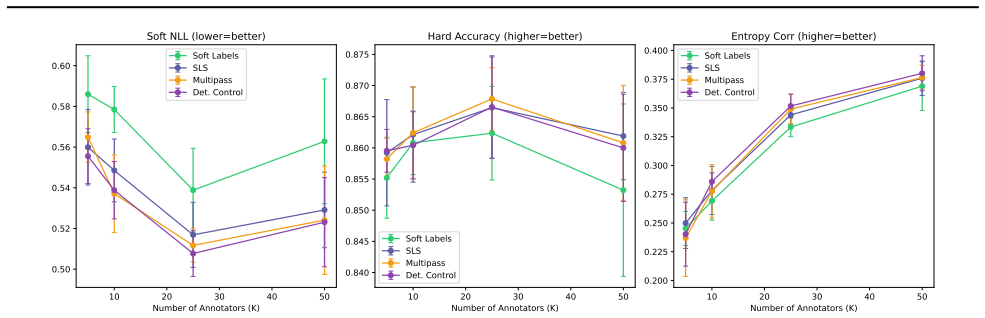
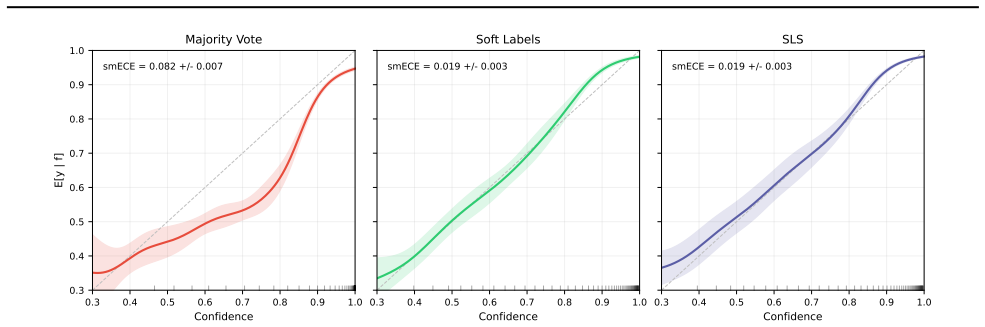
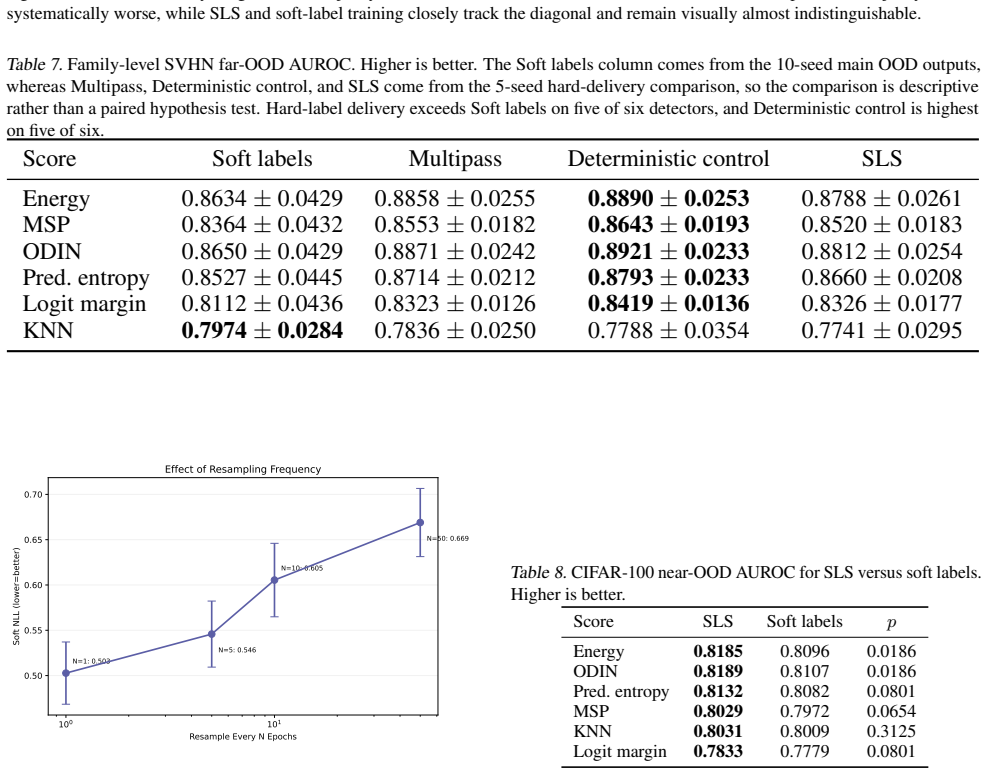
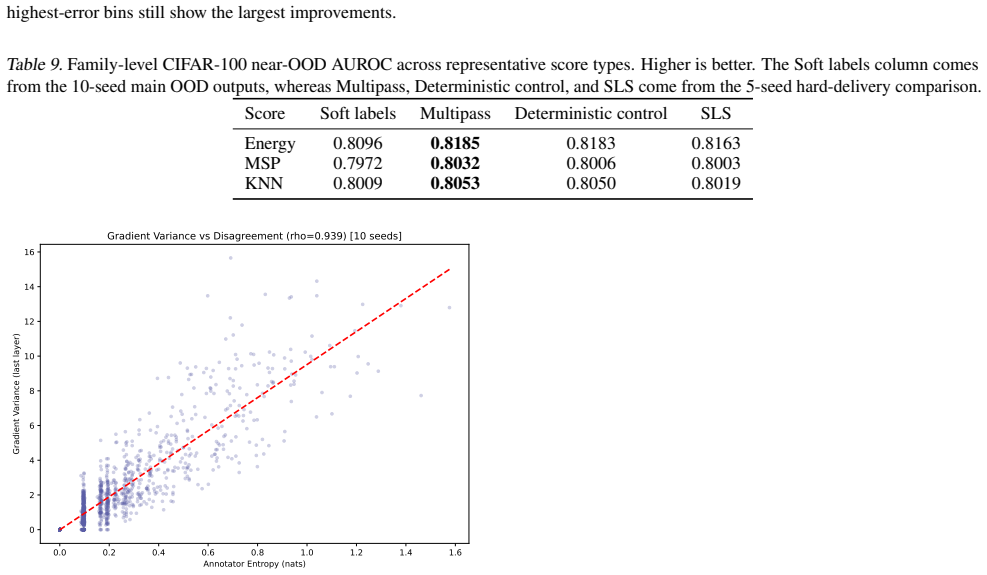
When the number of annotations per example is small, delivering hard labels either by cycling through observed votes in multipass training or by sampling one label per example at the start of each epoch improves performance over training directly on the empirical soft-label distribution, with the largest gains occurring where the sparse empirical target differs most from the full annotator distribution. When full distributions are available both hard-label methods match the performance of soft-label training. Hard-label delivery converges to flatter basins, with supporting descriptive evidence from OOD detection on SVHN and CIFAR-100.
What carries the argument
Hard-label delivery methods (multipass cycling through observed votes or stochastic label sampling) that preserve example-to-distribution correspondence, in contrast to direct training on empirical soft labels.
If this is right
- Multipass is a strong practical default when raw vote counts are available.
- SLS offers a lightweight alternative that remains competitive when only a few votes per example are available.
- SLS and soft-label cross-entropy optimize the same expected objective.
- Hard-label delivery converges to flatter basins, supported by OOD detection performance on SVHN and CIFAR-100.
Where Pith is reading between the lines
- Hard-label strategies may better capture epistemic uncertainty arising from annotator disagreement in low-annotation settings.
- The same hard-label approaches could be evaluated on additional datasets that exhibit annotator disagreement to test broader applicability.
- Reaching flatter basins via hard labels may yield improved generalization properties that extend beyond the OOD tasks examined.
Load-bearing premise
That the deterministic multipass and shuffled SLS controls successfully isolate the benefit of preserving the example-to-distribution correspondence rather than introducing confounding regularization or sampling artifacts.
What would settle it
No performance gain or a reversal of the reported gains when hard-label methods are compared to soft-label training on a dataset with few annotations per example where the sparse empirical targets are close to the full annotator distribution.
Figures








read the original abstract
When annotators disagree, that disagreement can reflect epistemic uncertainty rather than simple label noise. We study hard-label delivery as an alternative to the usual choices of collapsing votes to a single label or training directly on the empirical soft-label distribution. We focus on two primary hard-label methods: multipass, which cycles through observed votes while keeping the dataset size fixed, and stochastic label sampling (SLS), which samples one label per example at the start of each epoch. On CIFAR-10H, we find that when only a small number of annotations per example is available, hard-label delivery improves over soft-label training, with larger improvements where the sparse empirical target is farther from the full annotator distribution. When full annotator distributions are available, both hard-label methods match soft-label training. We use deterministic control as an ablation of multipass and shuffled SLS as a control that breaks the example-to-distribution match. We also show that SLS and soft-label cross-entropy optimize the same expected objective. Hard-label delivery also converges to flatter basins, with supporting descriptive evidence from OOD detection on SVHN and CIFAR-100. Overall, these results suggest that multipass is a strong practical default when raw vote counts are available, while SLS offers a lightweight alternative that remains competitive when only a few votes per example are available and matches soft-label training when full annotator distributions are available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that for annotator disagreement reflecting epistemic uncertainty, hard-label delivery via multipass (cycling through observed votes with fixed dataset size) or stochastic label sampling (SLS: one label per example per epoch) outperforms soft-label training on sparse empirical targets, with larger gains when the sparse distribution is farther from the full annotator distribution. On CIFAR-10H, both hard-label methods match soft-label performance when full distributions are available. Controls include deterministic multipass and shuffled SLS (to break per-example matching); SLS and soft-label cross-entropy are shown to optimize the same expected objective; hard labels converge to flatter basins, supported by OOD detection on SVHN and CIFAR-100. Multipass is recommended as a practical default when raw votes are available.
Significance. If the empirical results and controls hold, the work provides a practical alternative to soft-label training in low-annotation regimes and demonstrates that differences arise from optimization dynamics rather than the objective itself, since SLS and soft CE share the same expected loss. The explicit derivation of this equivalence and the focus on preserving example-to-distribution correspondence are strengths that could influence training practices for noisy or uncertain labels.
major comments (1)
- [Controls and Ablations] The central attribution of gains to preservation of example-to-distribution correspondence rests on the deterministic multipass and shuffled SLS controls. However, deterministic cycling may alter effective label exposure frequency and introduce implicit regularization distinct from random soft-label sampling, while shuffling SLS may independently modify per-epoch gradient statistics or label noise variance; these confounds are not ruled out and directly affect whether the performance differences can be credited to correspondence preservation rather than optimization artifacts. This is load-bearing for the main claim in the abstract and experimental sections.
minor comments (2)
- [Experimental Results] The abstract and results description report dataset-specific improvements without reference to error bars, standard deviations across runs, or statistical significance tests; adding these would make the empirical comparisons more robust.
- [Theoretical Analysis] Notation for the shared expected objective between SLS and soft-label cross-entropy should be clarified with an explicit equation reference to aid reproducibility.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's report. We address the major comment on controls and ablations below, providing clarifications and proposing revisions where appropriate.
read point-by-point responses
-
Referee: [Controls and Ablations] The central attribution of gains to preservation of example-to-distribution correspondence rests on the deterministic multipass and shuffled SLS controls. However, deterministic cycling may alter effective label exposure frequency and introduce implicit regularization distinct from random soft-label sampling, while shuffling SLS may independently modify per-epoch gradient statistics or label noise variance; these confounds are not ruled out and directly affect whether the performance differences can be credited to correspondence preservation rather than optimization artifacts. This is load-bearing for the main claim in the abstract and experimental sections.
Authors: We thank the referee for highlighting potential confounds in the controls. The deterministic multipass is intended to isolate the benefit of cycling through observed votes while preserving example-to-distribution correspondence and fixed dataset size, serving as an ablation of the stochasticity in SLS. Although fixed ordering may affect exposure frequency, results show it remains competitive with soft-label training when full distributions are available, consistent with correspondence driving gains rather than randomization alone. The shuffled SLS control retains stochastic per-epoch sampling and label noise characteristics but breaks the specific example-to-distribution match; the observed performance drop relative to unshuffled SLS therefore isolates the correspondence effect. We acknowledge that shuffling could additionally influence per-epoch gradient statistics, yet the design keeps other factors as similar as possible to the main SLS condition. To strengthen the attribution, we will revise the experimental section and discussion to explicitly address these potential artifacts, including a clearer rationale for the controls and their relation to the expected-objective equivalence between SLS and soft-label cross-entropy. This will better support the claims in the abstract. revision: partial
Circularity Check
No significant circularity; claims rest on empirical comparisons and direct equivalence proof
full rationale
The paper's core results are empirical performance differences on CIFAR-10H between hard-label methods (multipass, SLS) and soft-label training, with ablations via deterministic multipass and shuffled SLS. The statement that SLS and soft-label cross-entropy optimize the same expected objective is presented as a direct mathematical derivation of equivalence, not a self-referential fit or prediction that reduces to its own inputs by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked to justify the central claims. The derivation chain remains self-contained, with experimental controls and OOD evidence providing independent support rather than tautological reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Cross-entropy is a suitable loss for both hard and soft targets in multi-class classification.
Reference graph
Works this paper leans on
-
[1]
Dawid, A. Philip and Skene, Allan M. , title =. Journal of the Royal Statistical Society: Series C (Applied Statistics) , volume =. 1979 , doi =
work page 1979
-
[2]
and Yu, Shipeng and Zhao, Linda H
Raykar, Vikas C. and Yu, Shipeng and Zhao, Linda H. and Valadez, Gerardo Hermosillo and Florin, Charles and Bogoni, Luca and Moy, Linda , title =. Journal of Machine Learning Research , volume =. 2010 , url =
work page 2010
- [3]
-
[4]
Computational Linguistics , volume =
Artstein, Ron and Poesio, Massimo , title =. Computational Linguistics , volume =. 2008 , doi =
work page 2008
-
[5]
Aroyo, Lora and Welty, Chris , title =. AI Magazine , volume =. 2015 , doi =
work page 2015
-
[6]
Peterson, Joshua C. and Battleday, Ruairidh M. and Griffiths, Thomas L. and Russakovsky, Olga , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages =. 2019 , doi =
work page 2019
-
[7]
Battleday, Ruairidh M. and Peterson, Joshua C. and Griffiths, Thomas L. , title =. Nature Communications , volume =. 2020 , doi =
work page 2020
-
[8]
Uma, Alexandra N. and Fornaciari, Tommaso and Hovy, Dirk and Paun, Silviu and Plank, Barbara and Poesio, Massimo , title =. Journal of Artificial Intelligence Research , volume =. 2021 , doi =
work page 2021
-
[9]
Plank, Barbara , title =. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =. 2022 , doi =
work page 2022
-
[10]
Dealing with Disagreements: Looking Beyond the Majority Vote in Subjective Annotations , journal =
Mostafazadeh Davani, Aida and D. Dealing with Disagreements: Looking Beyond the Majority Vote in Subjective Annotations , journal =. 2022 , doi =
work page 2022
-
[11]
Language Resources and Evaluation , volume =
Frenda, Simona and Abercrombie, Gavin and Basile, Valerio and Pedrani, Alessandro and Panizzon, Raffaella and Cignarella, Alessandra Teresa and Marco, Cristina and Bernardi, Davide , title =. Language Resources and Evaluation , volume =. 2025 , doi =
work page 2025
-
[12]
arXiv preprint arXiv:2601.09065 , year =
Xu, Yinuo and Jurgens, David , title =. arXiv preprint arXiv:2601.09065 , year =
-
[13]
Nie, Yixin and Zhou, Xiang and Bansal, Mohit , title =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =. 2020 , doi =
work page 2020
-
[14]
Proceedings of the 17th International Workshop on Semantic Evaluation (SemEval-2023) , pages =
Leonardelli, Elisa and Abercrombie, Gavin and Almanea, Dina and Basile, Valerio and Fornaciari, Tommaso and Plank, Barbara and Rieser, Verena and Uma, Alexandra and Poesio, Massimo , title =. Proceedings of the 17th International Workshop on Semantic Evaluation (SemEval-2023) , pages =. 2023 , doi =
work page 2023
-
[15]
and Provost, Foster and Ipeirotis, Panagiotis G
Sheng, Victor S. and Provost, Foster and Ipeirotis, Panagiotis G. , title =. Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD) , pages =. 2008 , doi =
work page 2008
-
[16]
and Bhatt, Umang and Weller, Adrian , title =
Collins, Katherine M. and Bhatt, Umang and Weller, Adrian , title =. Proceedings of the AAAI Conference on Human Computation and Crowdsourcing (HCOMP) , volume =. 2022 , doi =
work page 2022
-
[17]
Distilling the Knowledge in a Neural Network
Hinton, Geoffrey and Vinyals, Oriol and Dean, Jeff , title =. arXiv preprint arXiv:1503.02531 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
Szegedy, Christian and Vanhoucke, Vincent and Ioffe, Sergey and Shlens, Jonathon and Wojna, Zbigniew , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =. 2016 , doi =
work page 2016
-
[19]
When Does Label Smoothing Help? , booktitle =
M. When Does Label Smoothing Help? , booktitle =. 2019 , url =
work page 2019
-
[20]
mixup: Beyond Empirical Risk Minimization , booktitle =
Zhang, Hongyi and Ciss. mixup: Beyond Empirical Risk Minimization , booktitle =. 2018 , url =
work page 2018
-
[21]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
Xie, Lingxi and Wang, Jingdong and Wei, Zhen and Wang, Meng and Tian, Qi , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =. 2016 , doi =
work page 2016
-
[22]
Regularizing Neural Networks by Penalizing Confident Output Distributions , booktitle =
Pereyra, Gabriel and Tucker, George and Chorowski, Jan and Kaiser,. Regularizing Neural Networks by Penalizing Confident Output Distributions , booktitle =. 2017 , url =
work page 2017
-
[23]
and Ravikumar, Pradeep and Tewari, Ambuj , title =
Natarajan, Nagarajan and Dhillon, Inderjit S. and Ravikumar, Pradeep and Tewari, Ambuj , title =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2013 , url =
work page 2013
-
[24]
Classification in the Presence of Label Noise: A Survey , journal =
Fr. Classification in the Presence of Label Noise: A Survey , journal =. 2014 , doi =
work page 2014
-
[25]
IEEE Transactions on Neural Networks and Learning Systems , volume =
Song, Hwanjun and Kim, Minseok and Park, Dongmin and Shin, Yooju and Lee, Jae-Gil , title =. IEEE Transactions on Neural Networks and Learning Systems , volume =. 2023 , doi =
work page 2023
- [26]
-
[27]
arXiv preprint arXiv:2408.02841 , year =
Ferrer, Luciana and Ramos, Daniel , title =. arXiv preprint arXiv:2408.02841 , year =
-
[28]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Lakshminarayanan, Balaji and Pritzel, Alexander and Blundell, Charles , title =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2017 , url =
work page 2017
- [29]
-
[30]
Nixon, Jeremy and Dusenberry, Michael W. and Jerfel, Ghassen and Nguyen, Timothy and Liu, Jeremiah and Zhang, Linchuan and Tran, Dustin , title =. CVPR Workshops , year =
-
[31]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Kumar, Ananya and Liang, Percy and Ma, Tengyu , title =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2019 , url =
work page 2019
-
[32]
arXiv preprint arXiv:2308.01222 (2023)
Wang, Cheng , title =. arXiv preprint arXiv:2308.01222 , year =
-
[33]
B. Smooth. International Conference on Learning Representations (ICLR) , year =
-
[34]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Minderer, Matthias and Djolonga, Josip and Romijnders, Rob and Hubis, Frances and Zhai, Xiaohua and Houlsby, Neil and Tran, Dustin and Lucic, Mario , title =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2021 , url =
work page 2021
-
[35]
Hochreiter, Sepp and Schmidhuber, J. Flat Minima , journal =. 1997 , doi =
work page 1997
-
[36]
International Conference on Learning Representations (ICLR) , year =
Keskar, Nitish Shirish and Mudigere, Dheevatsa and Nocedal, Jorge and Smelyanskiy, Mikhail and Tang, Ping Tak Peter , title =. International Conference on Learning Representations (ICLR) , year =
-
[37]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Li, Hao and Xu, Zheng and Taylor, Gavin and Studer, Christoph and Goldstein, Tom , title =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2018 , url =
work page 2018
-
[38]
Three Factors Influencing Minima in SGD
Jastrz. Three Factors Influencing Minima in. arXiv preprint arXiv:1711.04623 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
and Dherin, Benoit and Barrett, David G
Smith, Samuel L. and Dherin, Benoit and Barrett, David G. T. and De, Soham , title =. International Conference on Learning Representations (ICLR) , year =
- [40]
-
[41]
and Wei, Colin and Lee, Jason D
HaoChen, Jeff Z. and Wei, Colin and Lee, Jason D. and Ma, Tengyu , title =. Conference on Learning Theory (COLT) , year =
- [42]
-
[43]
Proceedings of the 34th International Conference on Machine Learning (ICML) , series =
Dinh, Laurent and Pascanu, Razvan and Bengio, Samy and Bengio, Yoshua , title =. Proceedings of the 34th International Conference on Machine Learning (ICML) , series =. 2017 , url =
work page 2017
- [44]
-
[45]
and Wilson, Andrew Gordon , title =
Stanton, Samuel and Izmailov, Pavel and Kirichenko, Polina and Alemi, Alexander A. and Wilson, Andrew Gordon , title =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2021 , url =
work page 2021
-
[46]
and Kim, Seungyeon and Kumar, Sanjiv , title =
Menon, Aditya Krishna and Rawat, Ankit Singh and Reddi, Sashank J. and Kim, Seungyeon and Kumar, Sanjiv , title =. Proceedings of the 38th International Conference on Machine Learning (ICML) , series =. 2021 , url =
work page 2021
-
[47]
International Conference on Learning Representations (ICLR) , year =
Foret, Pierre and Kleiner, Ariel and Mobahi, Hossein and Neyshabur, Behnam , title =. International Conference on Learning Representations (ICLR) , year =
-
[48]
Conference on Uncertainty in Artificial Intelligence (UAI) , year =
Izmailov, Pavel and Podoprikhin, Dmitrii and Garipov, Timur and Vetrov, Dmitry and Wilson, Andrew Gordon , title =. Conference on Uncertainty in Artificial Intelligence (UAI) , year =
-
[49]
International Conference on Learning Representations , year =
Nitish Shirish Keskar and Dheevatsa Mudigere and Jorge Nocedal and Mikhail Smelyanskiy and Ping Tak Peter Tang , title =. International Conference on Learning Representations , year =
-
[50]
Filipe Rodrigues and Francisco C. Pereira , title =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.