AMAR: Lightweight Attention-Based Multi-User Activity Recognition from Wi-Fi CSI
Pith reviewed 2026-05-21 03:07 UTC · model grok-4.3
The pith
An attention-based framework treats multi-user Wi-Fi activity recognition as a set prediction problem to handle overlapping signals from concurrent activities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
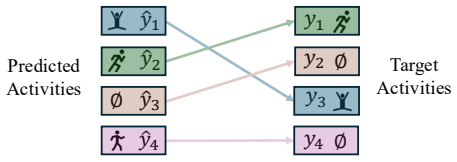
AMAR formulates HAR as a set prediction problem using a transformer-based architecture with learnable query embeddings as specialized activity detectors. This allows simultaneous identification of multiple activities from composite CSI representations. The edge-cloud architecture performs initial feature extraction with lightweight convolutional networks on edge devices, applies residual vector quantization for bandwidth reduction, and uses cloud-based attention for final set matching to handle varying occupancy levels.
What carries the argument
Learnable query embeddings in a transformer architecture that serve as specialized detectors for attention-based set matching on composite CSI representations.
If this is right
- Multi-user scenarios in classrooms and meeting rooms can achieve nearly double the rate of perfectly predicting all concurrent activities.
- The F1-score for activity recognition improves from 45.6% to 53.4% compared to best baselines.
- Occupancy estimation error is reduced by 74%.
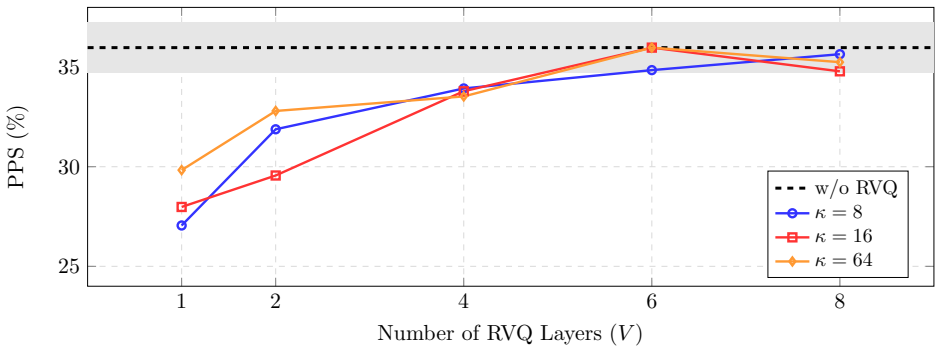
- Bandwidth is substantially minimized while maintaining performance through residual vector quantization.
- Systems can handle varying occupancy levels without fixed assumptions on number of users.
Where Pith is reading between the lines
- Similar attention-based set prediction could be applied to other contactless sensing like radar or acoustic signals for multi-user detection.
- Integration with privacy measures might be needed since Wi-Fi CSI can reveal detailed movement patterns.
- Further optimization of the quantization step could enable even lower bandwidth for IoT deployments.
Load-bearing premise
Residual vector quantization after edge-device feature extraction preserves sufficient activity-discriminative information from the composite CSI for accurate cloud-based set matching.
What would settle it
Experiments in new environments where the perfect prediction rate of all concurrent activities does not nearly double the best baseline or where F1-score falls below 53.4% would falsify the performance claims.
Figures




read the original abstract
Wi-Fi-based human activity recognition (HAR) has emerged as a promising approach for contactless sensing, leveraging channel state information (CSI) collected from wireless transceivers. While existing studies have primarily concentrated on single-user scenarios, real-world deployments often involve multi-user settings where concurrent users' movements induce overlapping CSI patterns that challenge conventional classification methods. To address this limitation, this paper introduces an attention-based multi-user activity recognition (AMAR) framework that formulates HAR as a set prediction problem. The transformer-based architecture in AMAR leverages learnable query embeddings acting as specialized activity detectors, enabling the simultaneous identification of multiple activities from composite CSI representations. Moreover, to address deployment constraints, AMAR is designed in an edge-cloud split architecture form where lightweight convolutional networks on edge devices perform initial feature extraction, followed by residual vector quantization that achieves substantial bandwidth reduction while preserving activity-discriminative information. The cloud component performs final activity prediction through attention-based set matching, enabling the system to handle varying occupancy levels. Across classroom, meeting-room, and empty-room environments, on average AMAR nearly doubles the rate of perfectly predicting all concurrent activities compared to the best baseline. Moreover, it achieves an $F_1$-score of 53.4% compared to 45.6% for the best benchmark, and reduces occupancy estimation error by 74%, while minimizing bandwidth substantially.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AMAR, an attention-based multi-user activity recognition framework from Wi-Fi CSI that formulates HAR as a set prediction problem. It uses a transformer with learnable query embeddings for simultaneous detection of concurrent activities from composite CSI, implemented via an edge-cloud split: lightweight convolutional networks extract features on edge devices, residual vector quantization compresses them for low-bandwidth transmission, and the cloud performs attention-based set matching. Empirical results across classroom, meeting-room, and empty-room settings claim that AMAR nearly doubles the perfect multi-activity prediction rate versus the best baseline, improves F1 from 45.6% to 53.4%, and cuts occupancy estimation error by 74% while substantially reducing bandwidth.
Significance. If the reported gains are robust, the work would advance practical multi-user Wi-Fi sensing by replacing single-activity classifiers with set prediction and enabling edge-cloud deployment through compression. The formulation as set matching with learnable queries is a clear conceptual step beyond standard multi-label classification for overlapping CSI signatures.
major comments (2)
- [§3.2] §3.2 (Residual Vector Quantization subsection): The central deployment claim rests on the assertion that residual VQ after edge convolutional feature extraction 'preserves activity-discriminative information,' yet no ablation on codebook size, no reconstruction error or mutual-information metrics, and no performance comparison with/without quantization are provided. This leaves the bandwidth-reduction component unisolated and the set-matching accuracy under compression unverified.
- [§4] §4 (Experiments): The headline metrics (perfect prediction rate doubling, F1 53.4% vs. 45.6%, 74% occupancy error reduction) are reported without dataset sizes, number of trials, statistical significance tests, or confidence intervals. Post-hoc environment-specific breakdowns further complicate assessment of whether the gains generalize beyond the tested overlap regimes.
minor comments (2)
- [§3.1] Notation for the learnable query embeddings and set-matching loss should be defined more explicitly in §3.1 to avoid ambiguity with standard transformer decoder queries.
- Figure captions for the edge-cloud architecture diagram and CSI spectrogram examples would benefit from additional detail on dimensions and preprocessing steps.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. Below we provide point-by-point responses to the major comments and describe the planned revisions to the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Residual Vector Quantization subsection): The central deployment claim rests on the assertion that residual VQ after edge convolutional feature extraction 'preserves activity-discriminative information,' yet no ablation on codebook size, no reconstruction error or mutual-information metrics, and no performance comparison with/without quantization are provided. This leaves the bandwidth-reduction component unisolated and the set-matching accuracy under compression unverified.
Authors: We acknowledge that the manuscript lacks explicit ablations for the residual vector quantization component. The claim that it preserves activity-discriminative information is inferred from the superior end-to-end performance of the full system. To address this, we will add ablations on codebook size, include reconstruction error and mutual information metrics where applicable, and provide performance comparisons with and without quantization in the revised manuscript. revision: yes
-
Referee: [§4] §4 (Experiments): The headline metrics (perfect prediction rate doubling, F1 53.4% vs. 45.6%, 74% occupancy error reduction) are reported without dataset sizes, number of trials, statistical significance tests, or confidence intervals. Post-hoc environment-specific breakdowns further complicate assessment of whether the gains generalize beyond the tested overlap regimes.
Authors: The referee is correct that additional experimental details are needed. We will update the experiments section to report dataset sizes, the number of trials, statistical significance tests, and confidence intervals. We will also discuss the generalization of the gains across the different environments and overlap regimes in more detail. revision: yes
Circularity Check
No circularity: empirical architecture and benchmark comparisons
full rationale
The paper describes an edge-cloud split architecture (lightweight conv feature extraction + residual VQ + transformer set prediction) and reports empirical metrics (F1 53.4% vs 45.6%, 74% occupancy error reduction, doubled perfect multi-activity rate) against external baselines across environments. No derivation chain, equations, or first-principles claims exist that reduce by construction to fitted inputs, self-definitions, or self-citation load-bearing steps. Performance assertions are falsifiable experimental outcomes, not tautological renamings or predictions forced by the model's own parameters.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable query embeddings
axioms (1)
- domain assumption Composite CSI from concurrent activities can be disentangled into individual activity predictions via attention-based set matching
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
transformer-based architecture ... learnable query embeddings acting as specialized activity detectors ... residual vector quantization ... edge-cloud split
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Jcost and RVQ loss (Eq. 5) for codebook learning
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
MU-SHOT-Fi: Self-Supervised Multi-User Wi-Fi Sensing with Source-free Unsupervised Domain Adaptation
MU-SHOT-Fi recovers multi-user activity classification accuracy under domain shifts in WiFi CSI sensing using source-free adaptation with Hungarian matching, occupancy-weighted entropy regularization, and rotation pre...
-
MU-SHOT-Fi: Self-Supervised Multi-User Wi-Fi Sensing with Source-free Unsupervised Domain Adaptation
MU-SHOT-Fi is a source-free UDA framework for multi-user WiFi HAR using permutation-invariant set prediction, occupancy-weighted information maximization, and binary rotation prediction to handle domain shifts.
Reference graph
Works this paper leans on
-
[1]
Harvesting ambient rf for presence detection through deep learning,
Y. Liu, T. Wang, Y. Jiang, and B. Chen, “Harvesting ambient rf for presence detection through deep learning,”IEEE Trans. on Neural Networks and Learning Sys., vol. 33, no. 4, pp. 1571– 1583, April 2022
work page 2022
-
[2]
Device-free occupancy detection and crowd counting in smart buildings with WiFi-enabled IoT,
H. Zou, Y. Zhou, J. Yang, and C. J. Spanos, “Device-free occupancy detection and crowd counting in smart buildings with WiFi-enabled IoT,”Energy and Buildings, vol. 174, pp. 309– 322, 2018
work page 2018
-
[3]
Spotfi: Decimeter level localization using wifi,
M. Kotaru, K. Joshi, D. Bharadia, and S. Katti, “Spotfi: Decimeter level localization using wifi,” inProc. of the 2015 ACM Conf. on Special Interest Group on Data Commun., 2015, pp. 269–282
work page 2015
-
[4]
Commodity WiFi sensing in ten years: Status, challenges, and opportunities,
S. Tan, Y. Ren, J. Yang, and Y. Chen, “Commodity WiFi sensing in ten years: Status, challenges, and opportunities,”IEEE Internet of Things Jrnl., vol. 9, no. 18, pp. 17 832–17 843, 2022
work page 2022
-
[5]
WiFi sensing with channel state information: A survey,
Y. Ma, G. Zhou, and S. Wang, “WiFi sensing with channel state information: A survey,”ACM Comput. Surv., vol. 52, no. 3, Jun. 2019. [Online]. Available: https://doi.org/10.1145/3310194
-
[6]
A survey on behavior recognition using WiFi channel state information,
S. Yousefi, H. Narui, S. Dayal, S. Ermon, and S. Valaee, “A survey on behavior recognition using WiFi channel state information,”IEEE Commun. Magazine, vol. 55, no. 10, pp. 98–104, 2017
work page 2017
-
[7]
Context-aware predictive coding: A representation learning framework for WiFi sensing,
B. Barahimi, H. Tabassum, M. Omer, and O. Waqar, “Context-aware predictive coding: A representation learning framework for WiFi sensing,”IEEE Open J. Commun. Soc., vol. 5, pp. 6119–6134, 2024. [Online]. Available: https://doi.org/10.1109/OJCOMS.2024.3465216
-
[8]
Multitrack: Multi-user tracking and activity recog- nition using commodity WiFi,
S. Tan, L. Zhang, Z. Wang, and J. Yang, “Multitrack: Multi-user tracking and activity recog- nition using commodity WiFi,”Proc. of the 2019 CHI Conf. on Human Factors in Computing Sys., pp. 1–12, 2019
work page 2019
-
[9]
Wisdom: Wi-fi-based contactless multiuser activity recognition,
P. Duan, C. Li, J. Li, X. Chen, C. Wang, and E. Wang, “Wisdom: Wi-fi-based contactless multiuser activity recognition,”IEEE Internet of Things Jrnl., vol. 10, no. 2, pp. 1876–1886, 2023
work page 2023
-
[10]
Tensorbeat: Tensor decomposition for monitoring multiperson breathing beats with commodity WiFi,
X. Wang, C. Yang, and S. Mao, “Tensorbeat: Tensor decomposition for monitoring multiperson breathing beats with commodity WiFi,”ACM Trans. Intell. Syst. Technol., vol. 9, no. 1, Sep. 2017. [Online]. Available: https://doi.org/10.1145/3078855
-
[11]
Imar: Multi-user continuous action recognition with WiFi signals,
J. He and W. Yang, “Imar: Multi-user continuous action recognition with WiFi signals,” Proc. ACM Interact. Mob. Wearable Ubiquitous Technol., vol. 6, no. 3, Sep. 2022. [Online]. Available: https://doi.org/10.1145/3550311
-
[12]
H. Rizk, A. Elmogy, M. Rihan, and H. Yamaguchi, “Multisensex: A sustainable solution for multi-human activity recognition and localization in smart environments,”AI, vol. 6, no. 1,
-
[13]
Available: https://www.mdpi.com/2673-2688/6/1/6 23
[Online]. Available: https://www.mdpi.com/2673-2688/6/1/6 23
-
[14]
Wimans: A benchmark dataset for WiFi-based multi-user activity sensing,
S. Huang, K. Li, D. You, Y. Chen, A. Lin, S. Liu, X. Li, and J. A. McCann, “Wimans: A benchmark dataset for WiFi-based multi-user activity sensing,” 2024. [Online]. Available: https://arxiv.org/abs/2402.09430
-
[15]
Lightweight csi-based human activity recognition for multi-task IoT applications,
C. Liu, F. Miao, Y. Chen, J. Wu, H. Wan, T. Tang, T. Ohtsuki, G. Gui, and H. Sari, “Lightweight csi-based human activity recognition for multi-task IoT applications,”IEEE In- ternet of Things Jrnl., pp. 1–1, 2025
work page 2025
-
[16]
Efficientfi: Toward large-scale lightweight WiFi sensing via csi compression,
J. Yang, X. Chen, H. Zou, D. Wang, Q. Xu, and L. Xie, “Efficientfi: Toward large-scale lightweight WiFi sensing via csi compression,”IEEE Internet of Things Jrnl., vol. 9, no. 15, pp. 13 086–13 095, 2022
work page 2022
-
[17]
Wi-multi: A three-phase system for multiple human activity recognition with commercial WiFi devices,
C. Feng, S. Arshad, S. Zhou, D. Cao, and Y. Liu, “Wi-multi: A three-phase system for multiple human activity recognition with commercial WiFi devices,”IEEE Internet of Things Jrnl., vol. 6, no. 4, pp. 7293–7304, Aug 2019
work page 2019
-
[18]
Multisense: Enabling multi-person respiration sensing with commodity WiFi,
Y. Zeng, D. Wu, J. Xiong, J. Liu, Z. Liu, and D. Zhang, “Multisense: Enabling multi-person respiration sensing with commodity WiFi,”Proc. of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, vol. 4, 09 2020
work page 2020
-
[19]
Wi-run: Device-free step estimation system with commodity wi-fi,
M. Liu, L. Zhang, P. Yang, L. Lu, and L. Gong, “Wi-run: Device-free step estimation system with commodity wi-fi,”Jrnl. of Network and Computer Applications, vol. 143, pp. 77–88, 2019. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S108480451930164X
work page 2019
-
[20]
Multiple people identification through walls using off-the- shelf WiFi,
B. Korany, H. Cai, and Y. Mostofi, “Multiple people identification through walls using off-the- shelf WiFi,”IEEE Internet of Things Jrnl., vol. 8, no. 8, pp. 6963–6974, April 2021
work page 2021
-
[21]
Multi-user gesture recognition using WiFi,
R. H. Venkatnarayan, G. Page, and M. Shahzad, “Multi-user gesture recognition using WiFi,” inProc. of the 16th Annual Intl. Conf. on Mobile Sys., Applications, and Services, ser. MobiSys ’18. New York, NY, USA: Association for Computing Machinery, 2018, p. 401–413. [Online]. Available: https://doi.org/10.1145/3210240.3210335
-
[22]
Muse-fi: Contactless muti-person sensing exploiting near-field wi-fi channel variation,
J. Hu, T. Zheng, Z. Chen, H. Wang, and J. Luo, “Muse-fi: Contactless muti-person sensing exploiting near-field wi-fi channel variation,” inProc. of the 29th Annual Intl. Conf. on Mobile Computing and Networking, ser. ACM MobiCom ’23. New York, NY, USA: Association for Computing Machinery, 2023. [Online]. Available: https://doi.org/10.1145/3570361.3613290
-
[23]
Rscnet: Dynamic csi compression for cloud-based WiFi sensing,
B. Barahimi, H. Singh, H. Tabassum, O. Waqar, and M. Omer, “Rscnet: Dynamic csi compression for cloud-based WiFi sensing,” inICC 2024 - IEEE Intl. Conf. on Commun. IEEE, Jun. 2024, p. 4179–4184. [Online]. Available: http://dx.doi.org/10.1109/ICC51166. 2024.10622623
-
[24]
24 Attention Learning is Needed to Efficiently Learn Parity Function Amit Daniely and Eran Malach
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” 2020. [Online]. Available: https: //arxiv.org/abs/2005.12872
-
[25]
The hungarian method for the assignment problem,
H. W. Kuhn, “The hungarian method for the assignment problem,”Naval Research Logistics Quarterly, vol. 2, no. 1-2, pp. 83–97, 1955
work page 1955
-
[26]
Xception: Deep learning with depthwise separable convolutions,
F. Chollet, “Xception: Deep learning with depthwise separable convolutions,” inProc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 1251–1258. 24
work page 2017
-
[27]
Multi-scale context aggregation by dilated convolutions,
F. Yu and V. Koltun, “Multi-scale context aggregation by dilated convolutions,” inIntl. Conf. on Learning Representations (ICLR), 2016
work page 2016
-
[28]
Two-stream convolution aug- mented transformer for human activity recognition,
B. Li, W. Cui, W. Wang, L. Zhang, Z. Chen, and M. Wu, “Two-stream convolution aug- mented transformer for human activity recognition,” inProc. of the AAAI Conf. on artificial intelligence, vol. 35, no. 1, 2021, pp. 286–293
work page 2021
-
[29]
Soundstream: An end-to-end neural audio codec, 2021
N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasacchi, “Soundstream: An end-to-end neural audio codec,” 2021. [Online]. Available: https://arxiv.org/abs/2107.03312
-
[30]
Momask: Generative masked modeling of 3d human motions
C. Guo, Y. Mu, M. G. Javed, S. Wang, and L. Cheng, “Momask: Generative masked modeling of 3d human motions,” 2023. [Online]. Available: https://arxiv.org/abs/2312.00063
-
[31]
Evaluation: from precision, recall and F-measure to ROC, informedness, markedness and correlation,
D. M. W. Powers, “Evaluation: from precision, recall and f-measure to roc, informedness, markedness and correlation,” 2020. [Online]. Available: https://arxiv.org/abs/2010.16061
-
[32]
WiFi-based human activity recognition using attention-based BiLSTM,
A. Elkelany, R. Ross, and S. McKeever, “WiFi-based human activity recognition using attention-based BiLSTM,” inArtificial Intelligence and Cognitive Science: 30th Irish Conf., AICS 2022, Munster, Ireland, December 8–9, 2022, Revised Selected Papers. Springer, 2023, pp. 126–137
work page 2022
-
[33]
R. Girshick, “Fast r-cnn,” 2015. [Online]. Available: https://arxiv.org/abs/1504.08083
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[34]
Deep convolutional and LSTM recurrent neural networks for multimodal wearable activity recognition,
F. J. Ord´ o˜ nez and D. Roggen, “Deep convolutional and LSTM recurrent neural networks for multimodal wearable activity recognition,”Sensors, vol. 16, no. 1, p. 115, 2016. 25
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.