Gaze into the Details: Locality-Sensitive Enhancement for OCTA Retinal Vessel Segmentation
Pith reviewed 2026-05-21 05:56 UTC · model grok-4.3
The pith
LSENet replaces U-Net skip connections with patch-wise attention to reduce vessel breaks and detail loss in OCTA retinal images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
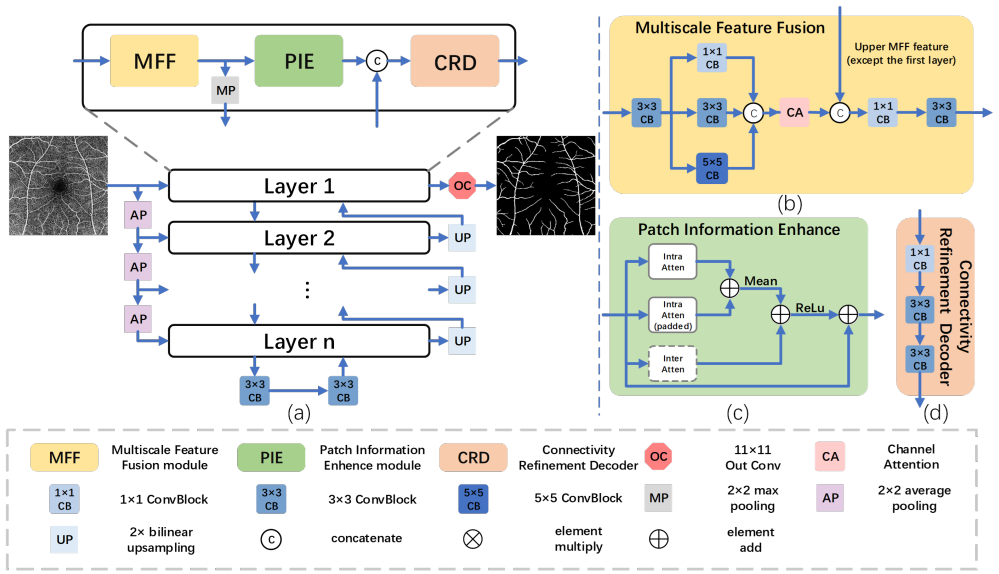
The central claim is that vessel discontinuities and detail loss in OCTA segmentation arise mainly from insufficient local processing in standard skip connections; replacing those connections with patch-wise attention inside the Patch Information Enhance module, while feeding it multi-scale features from the Multiscale Feature Fusion module and refining outputs in the Connectivity Refinement Decoder, directly restores continuity and fine structure without increasing model size.
What carries the argument
The Patch Information Enhance (PIE) module, which replaces standard skip connections with patch-wise attention to capture and reinforce local vessel information.
If this is right
- Vessel maps show fewer breaks in regions of low local contrast.
- Fine vessel details are retained through the supply of multi-scale inputs to the attention stage.
- Fragmentation at vessel endings is reduced by the large-kernel final layer.
- State-of-the-art accuracy is reached on OCTA-500, ROSE-1, and ROSSA while using fewer parameters than existing models.
Where Pith is reading between the lines
- The same patch-wise attention pattern could be dropped into other encoder-decoder networks that face low-contrast medical imaging tasks.
- Because the added modules keep the overall parameter count low, the design may support faster inference on standard clinical workstations.
- The emphasis on local patch statistics suggests a broader route for improving segmentation when global context alone is insufficient.
Load-bearing premise
The performance gains come chiefly from the patch-wise attention and multi-scale fusion rather than from dataset tuning or training schedule choices.
What would settle it
A controlled test that removes the PIE module, keeps every other change fixed, and measures whether vessel continuity scores on OCTA-500 drop to the level of the original U-Net would falsify the claim that patch-wise attention is the key fix.
Figures







read the original abstract
Existing deep learning frameworks for Optical Coherence Tomography Angiography (OCTA) vessel segmentation are largely derived from the U-Net architecture, which serves as the foundation for most current designs. However, most of these methods focus only on holistic representation, struggling to address the problem of low local contrast unique to OCTA, which leads to vessel discontinuities and loss of detail. To address these problems, we propose LSENet, which builds upon the U-Net architecture by introducing three core innovative modules: To address vessel discontinuities, we introduce the Patch Information Enhance module (PIE), which replaces standard skip connections to execute patch-wise attention. To mitigate detail loss, the Multiscale Feature Fusion module (MFF) is proposed to feed the PIE module rich, multi-scale information by extracting visually interpretable features from both the original input and preceding layers. Finally, the Connectivity Refinement Decoder (CRD) is designed to refine features from all levels and utilize a large kernel in the final convolutional layer to reduce fragmentation. Experiments on three public datasets (OCTA-500, ROSE-1, and ROSSA) demonstrate that our proposed LSENet achieves state-of-the-art performance while requiring fewer parameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LSENet, a U-Net variant for OCTA retinal vessel segmentation that introduces three modules to address low local contrast, vessel discontinuities, and detail loss: the Patch Information Enhance (PIE) module replaces skip connections with patch-wise attention; the Multiscale Feature Fusion (MFF) module supplies multi-scale features extracted from the original input and prior layers; and the Connectivity Refinement Decoder (CRD) refines multi-level features using a large-kernel final convolution. Experiments on OCTA-500, ROSE-1, and ROSSA are reported to achieve state-of-the-art segmentation performance with fewer parameters than prior methods.
Significance. If the reported gains are shown to stem from the PIE/MFF/CRD modules under controlled conditions, the work would offer a lightweight, locality-sensitive improvement to U-Net-style segmentation for OCTA, where preserving fine vessel continuity is clinically relevant. The emphasis on patch-wise attention and multi-scale fusion aligns with known challenges in low-contrast angiography imaging.
major comments (3)
- [Experiments / Results] The central empirical claim (SOTA on three datasets with fewer parameters) rests on attribution to PIE, MFF, and CRD, yet the manuscript provides no ablation tables or controlled re-training of baselines (e.g., U-Net) under identical optimizer, learning-rate schedule, augmentation, loss weighting, and epoch settings. Without these, improvements cannot be isolated from training-protocol differences.
- [Results] No quantitative metrics, per-dataset tables, or error analysis (e.g., Dice, sensitivity, specificity, or vessel-continuity metrics) are referenced in sufficient detail to verify the SOTA claim or to compare parameter counts and FLOPs against the reproduced baselines.
- [Methods / PIE Module] The description of PIE as 'patch-wise attention' replacing skip connections lacks a precise formulation or complexity analysis; it is unclear whether the attention is computed within fixed patches or across the feature map and how this interacts with the multi-scale input from MFF.
minor comments (3)
- Define all acronyms (OCTA, PIE, MFF, CRD) at first use and ensure consistent notation for module names throughout.
- [Figure 1] Add a clear architectural diagram that annotates the differences from standard U-Net skip connections and highlights the large-kernel layer in CRD.
- [Discussion] Include a brief discussion of failure cases or qualitative examples where vessel discontinuities persist despite the proposed modules.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We appreciate the emphasis on strengthening empirical validation and methodological precision. Below we respond point-by-point to the major comments and outline the revisions we will make.
read point-by-point responses
-
Referee: [Experiments / Results] The central empirical claim (SOTA on three datasets with fewer parameters) rests on attribution to PIE, MFF, and CRD, yet the manuscript provides no ablation tables or controlled re-training of baselines (e.g., U-Net) under identical optimizer, learning-rate schedule, augmentation, loss weighting, and epoch settings. Without these, improvements cannot be isolated from training-protocol differences.
Authors: We agree that isolating the contribution of each module requires controlled ablations and identical training protocols. In the revised manuscript we will add comprehensive ablation tables that incrementally enable PIE, MFF, and CRD on the base U-Net. We will also re-train U-Net and all other baselines using exactly the same optimizer, learning-rate schedule, data augmentations, loss weighting, and epoch count as LSENet to ensure fair attribution of gains. revision: yes
-
Referee: [Results] No quantitative metrics, per-dataset tables, or error analysis (e.g., Dice, sensitivity, specificity, or vessel-continuity metrics) are referenced in sufficient detail to verify the SOTA claim or to compare parameter counts and FLOPs against the reproduced baselines.
Authors: We acknowledge that more granular reporting is needed. The revised version will include full per-dataset tables reporting Dice, sensitivity, specificity, and vessel-continuity metrics (e.g., connected-component count and average fragment length). Parameter counts and FLOPs will be listed for LSENet and every reproduced baseline under the controlled training protocol. revision: yes
-
Referee: [Methods / PIE Module] The description of PIE as 'patch-wise attention' replacing skip connections lacks a precise formulation or complexity analysis; it is unclear whether the attention is computed within fixed patches or across the feature map and how this interacts with the multi-scale input from MFF.
Authors: We thank the referee for highlighting this lack of precision. In the revised Methods section we will supply the exact mathematical formulation of the patch-wise attention (computed inside fixed non-overlapping patches), include a complexity analysis (O(P·C·k²) where P is the number of patches), and add an explanatory diagram showing how MFF multi-scale features are concatenated before the patch attention operation. revision: yes
Circularity Check
No circularity: purely empirical architecture proposal
full rationale
The paper proposes LSENet as a U-Net variant with three modules (PIE replacing skip connections via patch-wise attention, MFF for multi-scale input, CRD with large-kernel refinement) to address low local contrast and vessel discontinuities in OCTA. All claims rest on experimental results across public datasets (OCTA-500, ROSE-1, ROSSA) showing SOTA performance with fewer parameters. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text; the evaluation is externally benchmarked and does not reduce to author-defined inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption U-Net serves as a suitable foundation for OCTA vessel segmentation tasks
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose LSENet, which builds upon the U-Net architecture by introducing three core innovative modules: Patch Information Enhance module (PIE) ... Multiscale Feature Fusion module (MFF) ... Connectivity Refinement Decoder (CRD)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experiments on three public datasets ... state-of-the-art performance while requiring fewer parameters
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Guogang Cao, Zeyu Peng, Zhilin Zhou, Yan Wu, Yunqing Zhang, and Rugang Yan. Multi-task octa image segmenta- tion with innovative dimension compression.Pattern Recog- nition, 159:111123, 2025. 2
work page 2025
-
[2]
Swin-unet: Unet-like pure transformer for medical image segmentation
Hu Cao, Yueyue Wang, Joy Chen, Dongsheng Jiang, Xi- aopeng Zhang, Qi Tian, and Manning Wang. Swin-unet: Unet-like pure transformer for medical image segmentation. InComputer Vision – ECCV 2022 Workshops, pages 205–
work page 2022
-
[3]
Springer Nature Switzerland, 2022. 2, 6
work page 2022
-
[4]
P. Carpineto, R. Mastropasqua, G. Marchini, L. Toto, M. Di Nicola, and L. Di Antonio. Reproducibility and repeata- bility of foveal avascular zone measurements in healthy sub- jects by optical coherence tomography angiography.Br J Ophthalmol, 100(5):671–6, 2016. 1, 2
work page 2016
-
[5]
Twins: revisiting the design of spatial attention in vision transformers.Nips ’21, 2021
Xiangxiang Chu, Zhi Tian, Yuqing Wang, Bo Zhang, Haib- ing Ren, Xiaolin Wei, Huaxia Xia, and Chunhua Shen. Twins: revisiting the design of spatial attention in vision transformers.Nips ’21, 2021. 2
work page 2021
-
[6]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In2021 International Conference on Learning Repre- sentations (ICLR), ...
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[7]
Deepvessel: Retinal vessel seg- mentation via deep learning and conditional random field
Huazhu Fu, Yanwu Xu, Stephen Lin, Damon Wing Kee Wong, and Jiang Liu. Deepvessel: Retinal vessel seg- mentation via deep learning and conditional random field. In Medical Image Computing and Computer-Assisted Interven- tion – MICCAI 2016, pages 132–139. Springer International Publishing, 2016. 2
work page 2016
-
[8]
Yunhe Gao, Mu Zhou, and Dimitris N. Metaxas. Utnet: A hybrid transformer architecture for medical image segmen- tation. InMedical Image Computing and Computer Assisted Intervention – MICCAI 2021, pages 61–71. Springer Inter- national Publishing, 2021. 6
work page 2021
-
[9]
Z. Gu, J. Cheng, H. Fu, K. Zhou, H. Hao, Y . Zhao, T. Zhang, S. Gao, and J. Liu. Ce-net: Context encoder network for 2d medical image segmentation.IEEE Transactions on Medical Imaging, 38(10):2281–2292, 2019. 2, 6
work page 2019
-
[10]
K. Hu, S. Jiang, Y . Zhang, X. Li, and X. Gao. Joint-seg: Treat foveal avascular zone and retinal vessel segmentation in octa images as a joint task.IEEE Transactions on Instrumentation and Measurement, 71:1–13, 2022. 2
work page 2022
-
[11]
Tao Jiang, Ying Li, Yifang Li, Wenyu Xing, Ming Yu, Feng Xie, and Dean Ta. A segmentation knowledge-based global- local attention network for tumor classification in breast ul- trasound images.Pattern Recognition, 171, 2026. 3
work page 2026
-
[12]
Pham, Qi Chen, Leyi Wei, and Ran Su
Qiangguo Jin, Zhaopeng Meng, Tuan D. Pham, Qi Chen, Leyi Wei, and Ran Su. Dunet: A deformable network for retinal vessel segmentation.Knowledge-Based Systems, 178: 149–162, 2019. 2
work page 2019
-
[13]
Amir H. Kashani, Chieh-Li Chen, Jin K. Gahm, Fang Zheng, Grace M. Richter, Philip J. Rosenfeld, Yonggang Shi, and Ruikang K. Wang. Optical coherence tomography angiogra- phy: A comprehensive review of current methods and clini- cal applications.Progress in Retinal and Eye Research, 60: 66–100, 2017. 1, 2
work page 2017
-
[14]
L. Kreitner, J. C. Paetzold, N. Rauch, C. Chen, A. M. Hagag, A. E. Fayed, S. Sivaprasad, S. Rausch, J. Weich- sel, B. H. Menze, M. Harders, B. Knier, D. Rueckert, and M. J. Menten. Synthetic optical coherence tomography an- giographs for detailed retinal vessel segmentation without human annotations.IEEE Transactions on Medical Imaging, 43(6):2061–2073, 2024. 2
work page 2061
-
[15]
Chetan L Srinidhi, P. Aparna, and Jeny Rajan. Recent ad- vancements in retinal vessel segmentation.Journal of Medi- cal Systems, 41(4):70, 2017. 1
work page 2017
-
[16]
Wang, Ying Cui, Raviv Katz, Filippos Vingopoulos, Giovanni Staurenghi, Demetrios G
In ˆes La ´ıns, Jay C. Wang, Ying Cui, Raviv Katz, Filippos Vingopoulos, Giovanni Staurenghi, Demetrios G. Vavvas, Joan W. Miller, and John B. Miller. Retinal applications of swept source optical coherence tomography (oct) and opti- cal coherence tomography angiography (octa).Progress in Retinal and Eye Research, 84:100951, 2021. 1
work page 2021
-
[17]
M. Li, Y . Chen, Z. Ji, K. Xie, S. Yuan, Q. Chen, and S. Li. Image projection network: 3d to 2d image segmentation in octa images.IEEE Transactions on Medical Imaging, 39 (11):3343–3354, 2020. 2
work page 2020
-
[18]
Mingchao Li, Kun Huang, Qiuzhuo Xu, Jiadong Yang, Yuhan Zhang, Zexuan Ji, Keren Xie, Songtao Yuan, Qinghuai Liu, and Qiang Chen. Octa-500: A retinal dataset for optical coherence tomography angiography study.Medi- cal Image Analysis, 93:103092, 2024. 2, 5
work page 2024
-
[19]
Zhenli Li, Xinpeng Zhang, Meng Zhao, Fan Shi, and Wei Zhou. Direction-guided network for retinal vessel segmenta- tion in octa images.Biomedical Signal Processing and Con- trol, 103:107455, 2025. 1, 2, 6
work page 2025
-
[20]
Chang Liu, Kaoru Hirota, and Yaping Dai. Patch attention convolutional vision transformer for facial expression recog- nition with occlusion.Information Sciences, 619:781–794,
-
[21]
Jianhua Liu, Dongxin Zhao, Juncai Shen, Peng Geng, Ying Zhang, Jiaxin Yang, and Ziqian Zhang. Hrd-net: High reso- lution segmentation network with adaptive learning ability of retinal vessel features.Computers in Biology and Medicine, 173:108295, 2024. 2
work page 2024
-
[22]
Xiaoming Liu, Di Zhang, Junping Yao, and Jinshan Tang. Transformer and convolutional based dual branch network for retinal vessel segmentation in octa images.Biomedical Signal Processing and Control, 83:104604, 2023. 1, 2
work page 2023
-
[23]
Xinyi Liu, Hailan Shen, Wenyan Zhong, Wanqing Xiong, and Zailiang Chen. Dsdc-net: Semi-supervised superficial octa vessel segmentation for false positive reduction.Pattern Recognition, 165:111592, 2025. 1, 2
work page 2025
-
[24]
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 9992–10002,
-
[25]
Y . Ma, H. Hao, J. Xie, H. Fu, J. Zhang, J. Yang, Z. Wang, J. Liu, Y . Zheng, and Y . Zhao. Rose: A retinal oct-angiography vessel segmentation dataset and new model.IEEE Transac- tions on Medical Imaging, 40(3):928–939, 2021. 2, 5
work page 2021
-
[26]
Lieve Moons and Lies De Groef. Multimodal retinal imag- ing to detect and understand alzheimer’s and parkinson’s dis- ease.Current Opinion in Neurobiology, 72:1–7, 2022. 1
work page 2022
-
[27]
Frangi, Masahiro Akiba, and Jiang Liu
Lei Mou, Yitian Zhao, Huazhu Fu, Yonghuai Liu, Jun Cheng, Yalin Zheng, Pan Su, Jianlong Yang, Li Chen, Alejandro F. Frangi, Masahiro Akiba, and Jiang Liu. Cs2-net: Deep learn- ing segmentation of curvilinear structures in medical imag- ing.Medical Image Analysis, 67:101874, 2021. 2, 4, 6
work page 2021
-
[28]
H. Ning, C. Wang, X. Chen, and S. Li. An accurate and effi- cient neural network for octa vessel segmentation and a new dataset. InICASSP 2024 - 2024 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP), pages 1966–1970, 2024. 1, 2, 5, 6
work page 2024
-
[29]
R. Peng, H. He, Y . Wei, Y . Wen, and D. Hu. Patch matters: Training-free fine-grained image caption enhancement via local perception. In2025 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 3963– 3973, 2025. 2
work page 2025
-
[30]
Amar Pujari, Karthika Bhaskaran, Pradeep Sharma, Pallavi Singh, Swati Phuljhele, Rohit Saxena, and Shorya Vardhan Azad. Optical coherence tomography angiography in neuro- ophthalmology: Current clinical role and future perspectives. Survey of Ophthalmology, 66(3):471–481, 2021. 1
work page 2021
-
[31]
Xiongwen Quan, Guangyao Hou, Wenya Yin, and Han Zhang. A multi-modal and multi-stage fusion enhancement network for segmentation based on oct and octa images.In- formation Fusion, 113:102594, 2025. 2
work page 2025
-
[32]
Spikepoint: An ef- ficient point-based spiking neural network for event cameras action recognition
Hongwei Ren, Yue Zhou, Xiaopeng LIN, Yulong Huang, Haotian FU, Jie Song, and Bojun Cheng. Spikepoint: An ef- ficient point-based spiking neural network for event cameras action recognition. InThe Twelfth International Conference on Learning Representations, 2024. 2
work page 2024
-
[33]
Hongwei Ren, Yue Zhou, Jiadong Zhu, Xiaopeng Lin, Hao- tian Fu, Yulong Huang, Yuetong Fang, Fei Ma, Hao Yu, and Bojun Cheng. Rethinking efficient and effective point- based networks for event camera classification and regres- sion, 2025. 2
work page 2025
-
[34]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InMedical Image Computing and Computer-Assisted Inter- vention – MICCAI 2015, pages 234–241. Springer Interna- tional Publishing, 2015. 2, 6
work page 2015
-
[35]
Danuta M. Sampson, Adam M. Dubis, Fred K. Chen, Robert J. Zawadzki, and David D. Sampson. Towards stan- dardizing retinal optical coherence tomography angiogra- phy: a review.Light: Science Applications, 11(1):63, 2022. 1, 2
work page 2022
-
[36]
Hailan Shen, Zheng Tang, Yajing Li, Xuanchu Duan, and Za- iliang Chen. Haic-net: Semi-supervised octa vessel segmen- tation with self-supervised pretext task and dual consistency training.Pattern Recognition, 151:110429, 2024. 2
work page 2024
-
[37]
Y . I. Shin, K. Y . Nam, S. E. Lee, H. B. Lim, M. W. Lee, Y . J. Jo, and J. Y . Kim. Changes in peripapillary microvas- culature and retinal thickness in the fellow eyes of patients with unilateral retinal vein occlusion: An octa study.Invest Ophthalmol Vis Sci, 60(2):823–829, 2019. 1
work page 2019
-
[38]
Norihiro Suzuki, Yoshio Hirano, Munenori Yoshida, Taneto Tomiyasu, Akiyoshi Uemura, Tsutomu Yasukawa, and Yuichiro Ogura. Microvascular abnormalities on optical co- herence tomography angiography in macular edema associ- ated with branch retinal vein occlusion.American Journal of Ophthalmology, 161:126–132.e1, 2016. 1, 2
work page 2016
-
[39]
Xiao Tan, Xinjian Chen, Qingquan Meng, Fei Shi, De- hui Xiang, Zhongyue Chen, Lingjiao Pan, and Weifang Zhu. Oct2former: A retinal oct-angiography vessel seg- mentation transformer.Computer Methods and Programs in Biomedicine, 233:107454, 2023. 1, 2, 6
work page 2023
-
[40]
Gomez, Łukasz Kaiser, and Il- lia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Il- lia Polosukhin. Attention is all you need. InProceedings of the 31st International Conference on Neural Information Processing Systems, page 6000–6010, Red Hook, NY , USA,
-
[41]
Curran Associates Inc. 2
-
[42]
C. Wang, H. Ning, X. Chen, and S. Li. Db-unet: Mlp based dual branch unet for accurate vessel segmentation in octa im- ages. InICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5, 2023. 1, 2
work page 2023
-
[43]
C. Wang, X. Chen, H. Ning, and S. Li. Sam-octa: A fine- tuning strategy for applying foundation model octa image segmentation tasks. InICASSP 2024 - 2024 IEEE Interna- tional Conference on Acoustics, Speech and Signal Process- ing (ICASSP), pages 1771–1775, 2024. 1, 2
work page 2024
-
[44]
Huisi Wu, Wei Wang, Jiafu Zhong, Baiying Lei, Zhenkun Wen, and Jing Qin. Scs-net: A scale and context sensi- tive network for retinal vessel segmentation.Medical Image Analysis, 70:102025, 2021. 2
work page 2021
-
[45]
Vessel-net: Reti- nal vessel segmentation under multi-path supervision
Yicheng Wu, Yong Xia, Yang Song, Donghao Zhang, Dong- nan Liu, Chaoyi Zhang, and Weidong Cai. Vessel-net: Reti- nal vessel segmentation under multi-path supervision. In Medical Image Computing and Computer Assisted Interven- tion – MICCAI 2019, pages 264–272. Springer International Publishing, 2019. 2, 6
work page 2019
-
[46]
Nfn+: A novel network followed network for retinal vessel segmentation.Neural Networks, 126:153–162,
Yicheng Wu, Yong Xia, Yang Song, Yanning Zhang, and Weidong Cai. Nfn+: A novel network followed network for retinal vessel segmentation.Neural Networks, 126:153–162,
-
[47]
Y . Ye, C. Pan, Y . Wu, S. Wang, and Y . Xia. Mfi-net: Mul- tiscale feature interaction network for retinal vessel segmen- tation.IEEE Journal of Biomedical and Health Informatics, 26(9):4551–4562, 2022. 2
work page 2022
-
[48]
Y . Yuan, L. Zhang, L. Wang, and H. Huang. Multi-level at- tention network for retinal vessel segmentation.IEEE Jour- nal of Biomedical and Health Informatics, 26(1):312–323,
-
[49]
W. Zhu, L. Sun, J. Huang, L. Han, and D. Zhang. Dual at- tention multi-instance deep learning for alzheimer’s disease diagnosis with structural mri.IEEE Trans Med Imaging, 40 (9):2354–2366, 2021. 3
work page 2021
-
[50]
Global partition with local enhance- ment network for multitask learning of malignant melanoma
Yang Zuo, Chen Pang, Chunyu Hu, Chunmeng Kang, Hong- bin Lv, and Lei Lyu. Global partition with local enhance- ment network for multitask learning of malignant melanoma. Biomedical Signal Processing and Control, 106, 2025. 3
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.