Modular Multimodal Classification Without Fine-Tuning: A Simple Compositional Approach
Pith reviewed 2026-05-21 06:03 UTC · model grok-4.3
The pith
Composing frozen modality encoders with tabular foundation models via PCA delivers state-of-the-art multimodal classification without any training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
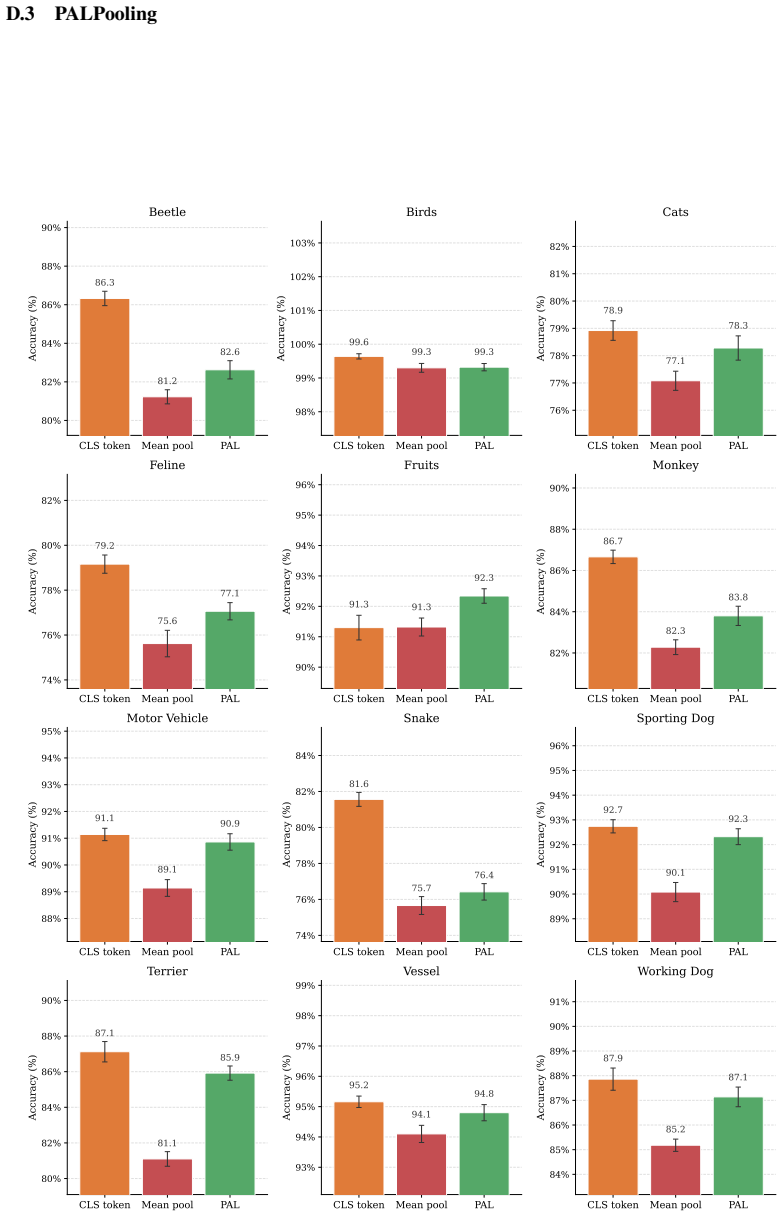
By passing each modality through a frozen pre-trained backbone, compressing the embeddings with PCA, and concatenating them as input to a Tabular Foundation Model, the method achieves state-of-the-art performance on diverse multimodal classification tasks without any training. When CLS tokens align poorly, PALPooling provides an adaptive token pooler that improves results. This compositional approach reaches state-of-the-art results on various benchmarks and scales to datasets with hundreds of thousands of samples and thousands of classes without any training.
What carries the argument
CoMET, the compositional pipeline of frozen modality encoders, PCA dimensionality reduction, and tabular foundation model prediction, with PALPooling as an adaptive token aggregator when needed.
If this is right
- Enables fast and scalable classification on hierarchical tasks with over 500,000 samples and 2,000 classes without fine-tuning.
- Demonstrates that PCA can effectively adapt foundation model embeddings for downstream multimodal tasks.
- Shows that the composition of foundation models provides a competitive alternative to end-to-end trained multimodal systems.
- Allows out-of-the-box application to new multimodal problems by reusing pre-trained components.
Where Pith is reading between the lines
- This suggests tabular foundation models could serve as effective fusion layers for multimodal tasks beyond the classification settings tested.
- Individual modality encoders could be swapped for newer versions as they emerge without retraining the fusion component.
- Linear projections like PCA may suffice for aligning representations from disparate foundation models in many practical cases.
Load-bearing premise
That principal component analysis alone provides sufficient adaptation of the frozen embeddings for effective input to the tabular foundation model across different modalities and tasks.
What would settle it
Replacing the tabular foundation model with a simple linear classifier on the same PCA-compressed concatenated embeddings and observing comparable accuracy on the benchmarks would indicate that the performance stems primarily from the embeddings rather than the specific compositional use of the TFM.
Figures
















read the original abstract
We introduce CoMET, \textit{\textbf{C}omposing \textbf{M}odality \textbf{E}ncoders with \textbf{T}abular foundation models}, a simple yet highly competitive method for multimodal classification: pass each modality through a frozen pre-trained backbone, compress the resulting embeddings with PCA, and concatenate as input into a Tabular Foundation Model (TFM) for prediction. We show that PCA alone suffices to act as an adaptor yielding strong, robust performance across modalities. When the \texttt{CLS} tokens of the foundation model align poorly with downstream tasks, we propose \textbf{PALPooling}, a lightweight adaptive token pooler that consistently improves representation quality. By composing strong frozen representation learning backbones with TFMs, our approach achieves state-of-the-art results across diverse multimodal benchmarks without any training. On hierarchical tasks with large fine-grained class spaces, our approach enables fast and scalable classification, handling datasets with over 500,000 samples and 2,000 classes without any fine-tuning. Overall, our results show that the composition of foundation models is a simple, yet powerful, out-of-the-box solution for multimodal learning, challenging the necessity of complex, end-to-end training pipelines for new problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CoMET, a compositional method for multimodal classification: each modality is passed through a frozen pre-trained backbone, the resulting embeddings are compressed via PCA, and the concatenated features are fed to a Tabular Foundation Model (TFM) for prediction with no task-specific training. When standard CLS tokens align poorly, the authors propose PALPooling, a lightweight adaptive token pooler. The central claim is that this pipeline achieves state-of-the-art results across diverse multimodal benchmarks, including large-scale hierarchical tasks with >500k samples and >2k classes, while demonstrating that PCA alone suffices as an adaptor.
Significance. If the empirical claims are substantiated, the work would be significant for showing that simple, training-free composition of existing foundation models can match or exceed complex end-to-end multimodal pipelines. The emphasis on scalability to large class spaces and the introduction of PALPooling as a targeted fix for misalignment are potentially useful contributions, provided they are supported by rigorous ablations and comparisons.
major comments (2)
- [§3] §3 (Method) and the abstract: the assertion that 'PCA alone suffices to act as an adaptor yielding strong, robust performance' is load-bearing for the no-training SOTA claim, yet PCA is unsupervised and retains maximum-variance directions; when CLS tokens already align poorly (the regime motivating PALPooling), lower-variance directions may carry task signal, so the reported gains could be attributable to backbone strength rather than the compositional recipe.
- [Experimental results] Experimental sections (e.g., Tables reporting benchmark results): the abstract and introduction assert state-of-the-art results and robustness across diverse benchmarks, but without explicit baselines, error bars, dataset details, or ablations isolating the contribution of PCA versus the frozen backbones, it is impossible to assess whether the data support the central claim.
minor comments (2)
- [§3.3] The description of PALPooling would benefit from a formal equation or pseudocode to clarify its adaptive pooling mechanism and ensure reproducibility.
- [§3.1] Notation for concatenated embeddings after PCA should be defined consistently (e.g., explicit dimension symbols) to avoid ambiguity when describing input to the TFM.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, providing clarifications and committing to revisions that strengthen the experimental rigor and methodological discussion without altering the core claims.
read point-by-point responses
-
Referee: [§3] §3 (Method) and the abstract: the assertion that 'PCA alone suffices to act as an adaptor yielding strong, robust performance' is load-bearing for the no-training SOTA claim, yet PCA is unsupervised and retains maximum-variance directions; when CLS tokens already align poorly (the regime motivating PALPooling), lower-variance directions may carry task signal, so the reported gains could be attributable to backbone strength rather than the compositional recipe.
Authors: We acknowledge that PCA is unsupervised and primarily retains high-variance directions, which could in principle miss task-relevant signals in lower-variance components when CLS tokens are misaligned. However, the manuscript's central empirical finding is that, across the evaluated benchmarks, the combination of frozen backbones, PCA compression, and a TFM yields competitive or superior performance without any task-specific training. To isolate the contribution, we have added a new ablation study in the revised §4 that compares PCA against supervised alternatives (e.g., LDA) and against using raw high-dimensional embeddings; results indicate PCA remains effective and often preferable for computational reasons. We also clarify in the updated §3 that the compositional recipe's advantage stems from leveraging the complementary strengths of modality-specific encoders and tabular foundation models rather than from PCA in isolation. PALPooling is presented as a lightweight, optional module precisely for the poor-alignment regime, and we include additional token-level analysis demonstrating its benefit prior to PCA application. revision: partial
-
Referee: [Experimental results] Experimental sections (e.g., Tables reporting benchmark results): the abstract and introduction assert state-of-the-art results and robustness across diverse benchmarks, but without explicit baselines, error bars, dataset details, or ablations isolating the contribution of PCA versus the frozen backbones, it is impossible to assess whether the data support the central claim.
Authors: We agree that greater transparency in the experimental presentation is warranted. In the revised manuscript we have expanded the experimental sections to: (i) provide full dataset descriptions including sample counts, class hierarchies, and splits; (ii) list all baselines with explicit citations and implementation details; (iii) report error bars or standard deviations over multiple random seeds for the primary tables; and (iv) add targeted ablations that separately vary the dimensionality-reduction step (PCA vs. raw embeddings vs. linear projection) while holding the frozen backbones and TFM fixed. These additions directly address the request to isolate PCA's role and allow readers to evaluate the support for the no-training SOTA claim. revision: yes
Circularity Check
No significant circularity; empirical composition of external models
full rationale
The paper proposes a pipeline that feeds frozen pre-trained backbone embeddings through PCA compression into a Tabular Foundation Model, with optional PALPooling for misaligned CLS tokens. All performance claims rest on external benchmarks and the capabilities of independently trained upstream models rather than any internal derivation, fitted parameter, or self-citation that reduces the result to the method's own inputs by construction. The approach is therefore self-contained against external evaluation and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Frozen pre-trained backbones provide strong representations suitable for downstream multimodal tasks without fine-tuning
invented entities (1)
-
PALPooling
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Alan Arazi, Eilam Shapira, and Roi Reichart. Tabstar: A tabular foundation model for tabular data with text fields.arXiv preprint arXiv:2505.18125,
-
[2]
Causalpfn: Amortized causal effect estimation via in-context learning
Vahid Balazadeh, Hamidreza Kamkari, Valentin Thomas, Benson Li, Junwei Ma, Jesse C Cresswell, and Rahul G Krishnan. Causalpfn: Amortized causal effect estimation via in-context learning. arXiv preprint arXiv:2506.07918,
-
[3]
Revisiting multimodal transformers for tabular data with text fields
Thomas Bonnier. Revisiting multimodal transformers for tabular data with text fields. InFindings of the Association for Computational Linguistics: ACL 2024, pages 1481–1500,
work page 2024
-
[4]
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
Kevin Clark, Minh-Thang Luong, Quoc V Le, and Christopher D Manning. Electra: Pre-training text encoders as discriminators rather than generators.arXiv preprint arXiv:2003.10555,
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[5]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186,
work page 2019
-
[6]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[7]
Codebert: A pre-trained model for programming and natural languages
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, et al. Codebert: A pre-trained model for programming and natural languages. InFindings of the association for computational linguistics: EMNLP 2020, pages 1536–1547,
work page 2020
-
[8]
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
Léo Grinsztajn, Klemens Flöge, Oscar Key, Felix Birkel, Philipp Jund, Brendan Roof, Benjamin Jäger, Dominik Safaric, Simone Alessi, Adrian Hayler, et al. Tabpfn-2.5: Advancing the state of the art in tabular foundation models.arXiv preprint arXiv:2511.08667,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. Tabpfn: A transformer that solves small tabular classification problems in a second.arXiv preprint arXiv:2207.01848,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
The iNaturalist Species Classification and Detection Dataset
URLhttps://arxiv.org/abs/1707.06642. Yupeng Hou, Jiacheng Li, Zhankui He, An Yan, Xiusi Chen, and Julian McAuley. Bridging language and items for retrieval and recommendation.arXiv preprint arXiv:2403.03952,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Ex- ploiting global and local hierarchies for hierarchical text classification
Ting Jiang, Deqing Wang, Leilei Sun, Zhongzhi Chen, Fuzhen Zhuang, and Qinghong Yang. Ex- ploiting global and local hierarchies for hierarchical text classification. InProceedings of the 2022 conference on empirical methods in natural language processing, pages 4030–4039,
work page 2022
-
[12]
MultiModalPFN: Extending Prior-Data Fitted Networks for Multimodal Tabular Learning
Wall Kim, Chaeyoung Song, and Hanul Kim. Multimodalpfn: Extending prior-data fitted networks for multimodal tabular learning.arXiv preprint arXiv:2602.20223,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Hdltex: Hierarchical deep learning for text classification
Kamran Kowsari, Donald E Brown, Mojtaba Heidarysafa, Kiana Jafari Meimandi, , Matthew S Gerber, and Laura E Barnes. Hdltex: Hierarchical deep learning for text classification. InMachine Learning and Applications (ICMLA), 2017 16th IEEE International Conference on. IEEE,
work page 2017
-
[14]
Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Uijlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Alexander Kolesnikov, et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. International journal of computer vision, 128(7):1956–1981,
work page 1956
-
[15]
NewsWeeder: Learning to filter netnews
Ken Lang. NewsWeeder: Learning to filter netnews. InMachine Learning Proceedings 1995, pages 331–339. Morgan Kaufmann,
work page 1995
-
[16]
David D Lewis, Yiming Yang, Tony G Rose, and Fan Li
doi: 10.1016/B978-1-55860-377-6.50048-7. David D Lewis, Yiming Yang, Tony G Rose, and Fan Li. Rcv1: A new benchmark collection for text categorization research.Journal of machine learning research, 5(Apr):361–397,
-
[17]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692,
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[18]
Jiaqi Luo, Yuan Yuan, and Shixin Xu. Time: Tabpfn-integrated multimodal engine for robust tabular-image learning.arXiv preprint arXiv:2506.00813,
-
[19]
TabDPT: Scaling tabular foundation models on real data.arXiv preprint arXiv:2410.18164,
Junwei Ma, Valentin Thomas, Rasa Hosseinzadeh, Alex Labach, Hamidreza Kamkari, Jesse C Cresswell, Keyvan Golestan, Guangwei Yu, Anthony L Caterini, and Maksims V olkovs. Tabdpt: Scaling tabular foundation models on real data.arXiv preprint arXiv:2410.18164,
- [20]
-
[21]
Lorenzo Mur-Labadia, Matthew Muckley, Amir Bar, Mido Assran, Koustuv Sinha, Mike Rabbat, Yann LeCun, Nicolas Ballas, and Adrien Bardes. V-jepa 2.1: Unlocking dense features in video self-supervised learning.arXiv preprint arXiv:2603.14482,
-
[22]
Visually consistent hierarchical image classification.arXiv preprint arXiv:2406.11608,
Seulki Park, Youren Zhang, Stella X Yu, Sara Beery, and Jonathan Huang. Visually consistent hierarchical image classification.arXiv preprint arXiv:2406.11608,
-
[23]
Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. TabICLv2: A better, faster, scalable, and open tabular foundation model.arXiv preprint arXiv:2602.11139,
-
[24]
Large-scale Classification of Fine-Art Paintings: Learning The Right Metric on The Right Feature
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 11 2019a. URL http://arxiv.org/abs/1908. 10084. Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siame...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[25]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Zhiqiang Tang, Haoyang Fang, Su Zhou, Taojiannan Yang, Zihan Zhong, Tony Hu, Katrin Kirchhoff, and George Karypis. Autogluon-multimodal (automm): Supercharging multimodal automl with foundation models.arXiv preprint arXiv:2404.16233,
-
[27]
Shashanka Venkataramanan, Valentinos Pariza, Mohammadreza Salehi, Lukas Knobel, Spyros Gidaris, Elias Ramzi, Andrei Bursuc, and Yuki M. Asano. Franca: Nested matryoshka clustering for scalable visual representation learning.arXiv preprint arXiv:2507.14137,
work page internal anchor Pith review Pith/arXiv arXiv
- [28]
-
[29]
Match: Metadata-aware text classification in a large hierarchy
Yu Zhang, Zhihong Shen, Yuxiao Dong, Kuansan Wang, and Jiawei Han. Match: Metadata-aware text classification in a large hierarchy. InProceedings of the Web Conference 2021, pages 3246–3257,
work page 2021
-
[30]
(2011) consists of movie reviews represented using ELECTRA mean- pooled embeddings
Table 6 Dataset Train Val Classes Terrier 12,608 500 10 Snakes 21,871 850 17 Beetle 10,400 400 8 Feline 13,000 500 10 Vehicles 56,956 2,200 44 Dogs 147,873 5,900 118 A.3 Text-only datasets • IMDBMaas et al. (2011) consists of movie reviews represented using ELECTRA mean- pooled embeddings. The task is binary sentiment classification (positive vs. negative...
work page 2011
-
[31]
15 Table 7: ImageNet subsets used in our experiments and their constituent classes. Subset Class Names Terrier Staffordshire bullterrier, American Staffordshire terrier, Bedlington terrier, Border terrier, Kerry blue terrier, Irish terrier, Norfolk terrier, Norwich terrier, Yorkshire terrier, wire- haired fox terrier. Snakes thunder snake, ringneck snake,...
work page 2018
-
[32]
For Open Images, the process was similar, but since this dataset had a lot more fine-grained labels (e.g., Human arm), the list of ignored common labels (presented in Table 11b) needed to be substantially longer to avoid too many co-occurrences. The final dataset included 600 train and 200 test samples of each class, shown in Table 11a (30 000 /10 000 tot...
work page 2024
-
[33]
Image features were extracted using DINOv3
Text features were extracted using Sentence-BERT on all texts concatenated. Image features were extracted using DINOv3. 9 top-level categories were used. These were:Arts crafts and sewing,Automotive,Beauty and personal care,Cell phones and accessories,Clothing shoes and jewelry,Electronics,Home and kitchen,Sports and outdoors,Tools and home improvement. W...
work page 2078
-
[34]
We only use DinoV3 features for this experiment, no tabular data. We observe accuracy gains from PCA up to 64-dimensional embeddings, after which performance degrades as the latent becomes over-compressed at 32 and 16 dimensions. The curve plotting the product of explained variance and effective rank closely mirrors the accuracy curve, suggesting a tradeo...
work page 2025
-
[35]
22 Table 14: Results across a few multimodal and single modality datasets for RoBERTa and Franca
Our results on different backbones show that our method is not limited to DinoV3 and ELECTRA, and that the benefits of PCA are due to TabICL, not the backbones. 22 Table 14: Results across a few multimodal and single modality datasets for RoBERTa and Franca. Dataset / Modality Raw PCA-256 PetFinder (tabular + franca) 0.37300.3991 PetFinder (tabular + robe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.