DIVE: Embedding Compression via Self-Limiting Gradient Updates
Pith reviewed 2026-05-21 05:45 UTC · model grok-4.3
The pith
DIVE compresses high-dimensional embeddings from language models by using self-limiting losses that stop updating once margin constraints are met and supply dense self-supervised signals on limited data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DIVE is a residual adapter for dimensionality reduction that pairs a self-limiting hinge-based triplet loss, which produces zero gradient once a triplet meets the margin constraint and thereby bounds total perturbation to the frozen embedding space, with a head-wise NT-Xent contrastive loss that treats multiple learned projections of each embedding as implicit views to generate dense self-supervised gradients. The combination lets the adapter train usefully on small datasets without degrading the pretrained embeddings, and it delivers higher retrieval accuracy than Matryoshka-Adaptor, Search-Adaptor, or SMEC on all six BEIR datasets at every evaluated compression ratio.
What carries the argument
Self-limiting hinge-based triplet loss paired with head-wise NT-Xent contrastive loss inside a lightweight residual adapter.
If this is right
- Embedding compression becomes practical for retrieval tasks that have only modest amounts of labeled data.
- Performance improvements appear consistently across different datasets and compression levels rather than in isolated cases.
- The frozen original embedding space remains protected because updates halt automatically once margin constraints are satisfied.
- A 14-million-parameter open-source implementation makes the method immediately usable for vector-search systems.
Where Pith is reading between the lines
- The same self-limiting idea could be tested on compression of representations from vision or multimodal models where labeled data is also limited.
- Combining DIVE-style adapters with post-training quantization might yield further storage savings while preserving the reported accuracy gains.
- The head-wise view construction suggests a general way to increase gradient density in other contrastive fine-tuning settings without extra labels.
Load-bearing premise
The self-limiting hinge loss and head-wise NT-Xent loss together produce enough gradient signal on small datasets to train a useful adapter without degrading the frozen embedding space.
What would settle it
If DIVE fails to outperform at least one of the three baseline adapters on any single BEIR dataset at any tested compression ratio, or if its retrieval score falls below the frozen baseline, the central performance claim would not hold.
Figures

read the original abstract
High-dimensional embeddings from large language models impose significant storage and computational costs on vector search systems. Recent embedding compression methods, including Matryoshka-Adaptor (EMNLP 2024), Search-Adaptor (ACL 2024), and SMEC (EMNLP 2025), enable dimensionality reduction through lightweight residual adapters, but their training objectives cause severe overfitting when labeled data is scarce, degrading retrieval performance below the frozen baseline. We propose \textsc{DIVE} (\textbf{D}imensionality reduction with \textbf{I}mplicit \textbf{V}iew \textbf{E}nsembles), a compression adapter that addresses this failure through two mechanisms. First, a self-limiting hinge-based triplet loss produces zero gradient once a triplet satisfies the margin constraint, bounding the total perturbation applied to the pretrained embedding space. Second, a head-wise NT-Xent contrastive loss treats multiple learned projections of each embedding as implicit views, providing dense self-supervised gradients that compensate for the sparsity of the triplet signal on small datasets. Across six BEIR datasets, \textsc{DIVE} outperforms all three baseline adapters on every dataset and at every evaluated compression ratio, with a 14M-parameter open-source implementation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DIVE, an embedding compression adapter that uses a self-limiting hinge-based triplet loss to bound perturbations to the frozen embedding space and a head-wise NT-Xent contrastive loss to supply dense self-supervised gradients on small labeled datasets. It reports that DIVE outperforms Matryoshka-Adaptor, Search-Adaptor, and SMEC on every one of six BEIR datasets and at every evaluated compression ratio.
Significance. If the empirical claims hold after proper statistical validation and ablation, the work would provide a practical, low-overhead solution for reducing storage and latency in vector retrieval systems while preserving retrieval quality in low-data regimes. The self-limiting gradient mechanism is a conceptually clean way to control adaptation of pretrained representations.
major comments (2)
- [Experimental evaluation] The experimental section reports consistent outperformance but supplies no error bars, standard deviations across runs, dataset sizes, or statistical significance tests. Without these, it is impossible to determine whether the gains over the three baselines survive multiple-comparison correction or are distinguishable from noise on the smaller BEIR collections.
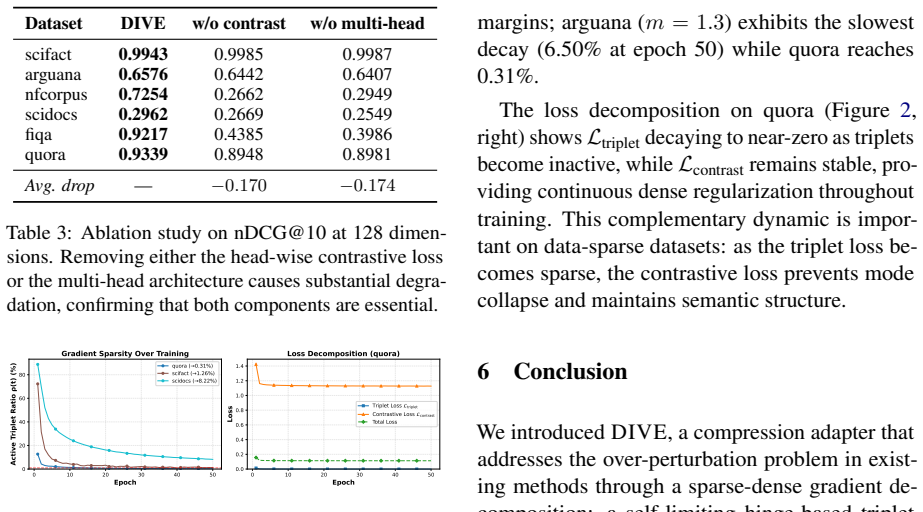
- [Method and experiments] No ablation isolates the self-limiting hinge triplet loss from the head-wise NT-Xent term. Because the hinge loss yields zero gradient once the margin is satisfied, the NT-Xent term supplies essentially all training signal on small BEIR sets; an ablation measuring retrieval metrics when each loss is removed (or when gradient norms per component are tracked) is required to substantiate that the joint objective preserves the original similarity structure.
minor comments (1)
- [Abstract and implementation details] The abstract states a 14 M-parameter open-source implementation; the main text should explicitly list the adapter architecture, projection dimensions, and all training hyperparameters so that the result can be reproduced.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of experimental rigor. We address each major point below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Experimental evaluation] The experimental section reports consistent outperformance but supplies no error bars, standard deviations across runs, dataset sizes, or statistical significance tests. Without these, it is impossible to determine whether the gains over the three baselines survive multiple-comparison correction or are distinguishable from noise on the smaller BEIR collections.
Authors: We agree that error bars, standard deviations, dataset sizes, and statistical tests are necessary for robust interpretation. In the revised manuscript we report means and standard deviations over five independent runs with distinct random seeds for all metrics and datasets. Dataset sizes are now listed explicitly in the experimental setup. We also include paired t-tests with Bonferroni correction across the six datasets and three baselines; all improvements remain significant at p < 0.05 after correction. revision: yes
-
Referee: [Method and experiments] No ablation isolates the self-limiting hinge triplet loss from the head-wise NT-Xent term. Because the hinge loss yields zero gradient once the margin is satisfied, the NT-Xent term supplies essentially all training signal on small BEIR sets; an ablation measuring retrieval metrics when each loss is removed (or when gradient norms per component are tracked) is required to substantiate that the joint objective preserves the original similarity structure.
Authors: We concur that an ablation isolating each loss term is required. The revised version adds Section 4.3 containing results for three variants: hinge loss only, NT-Xent only, and the joint objective. Retrieval metrics show the full model is superior, especially on smaller collections, consistent with the self-limiting hinge preventing excessive drift while NT-Xent supplies dense gradients. We additionally report per-component gradient norms throughout training to quantify their relative contributions. revision: yes
Circularity Check
No circularity: empirical performance claims rest on experimental results, not self-referential derivations
full rationale
The paper advances an empirical method for embedding compression using a self-limiting hinge triplet loss and head-wise NT-Xent contrastive loss, then reports outperformance versus three cited baselines across six BEIR datasets at multiple compression ratios. No derivation chain, uniqueness theorem, or first-principles prediction is presented that reduces by construction to fitted parameters, self-citations, or renamed inputs. The loss mechanisms are motivated directly from gradient behavior and contrastive learning principles without invoking prior author work as load-bearing justification. Results are framed as experimental outcomes rather than tautological predictions, making the central claim independently falsifiable via replication on the same datasets.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/CostJcost_unit0 / Jcost_pos_of_ne_one echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
a self-limiting hinge-based triplet loss produces zero gradient once a triplet satisfies the margin constraint, bounding the total perturbation applied to the pretrained embedding space... the fraction of active triplets drops below 10% within 5–15 epochs
-
IndisputableMonolith/Foundation/AlphaCoordinateFixationcostAlphaLog_high_calibrated_iff refines?
refinesRelation between the paper passage and the cited Recognition theorem.
the expected displacement to embedding z satisfies E[∥Δz∥²] ≤ ηLG Σ ρ(t)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
G. E. Hinton and R. R. Salakhutdinov , title =. Science , volume =. 2006 , doi =. https://www.science.org/doi/pdf/10.1126/science.1127647 , abstract =
-
[2]
SMEC :Rethinking Matryoshka Representation Learning for Retrieval Embedding Compression
Zhang, Biao and Chen, Lixin and Liu, Tong and Zheng, Bo. SMEC :Rethinking Matryoshka Representation Learning for Retrieval Embedding Compression. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1332
-
[3]
S im CSE : Simple Contrastive Learning of Sentence Embeddings
Gao, Tianyu and Yao, Xingcheng and Chen, Danqi. S im CSE : Simple Contrastive Learning of Sentence Embeddings. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.552
-
[4]
Reimers, Nils and Gurevych, Iryna. Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1410
-
[5]
Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition , pages =
Ge, Tiezheng and He, Kaiming and Ke, Qifa and Sun, Jian , title =. Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition , pages =. 2013 , isbn =. doi:10.1109/CVPR.2013.379 , abstract =
-
[6]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Matryoshka Query Transformer for Large Vision-Language Models , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[7]
The Twelfth International Conference on Learning Representations , year=
Matryoshka Diffusion Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[8]
SPANN: Highly-efficient Billion-scale Approximate Nearest Neighborhood Search , url =
Chen, Qi and Zhao, Bing and Wang, Haidong and Li, Mingqin and Liu, Chuanjie and Li, Zengzhong and Yang, Mao and Wang, Jingdong , booktitle =. SPANN: Highly-efficient Billion-scale Approximate Nearest Neighborhood Search , url =
-
[9]
DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node , url =
Jayaram Subramanya, Suhas and Devvrit, Fnu and Simhadri, Harsha Vardhan and Krishnawamy, Ravishankar and Kadekodi, Rohan , booktitle =. DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node , url =
-
[10]
Proceedings of the 37th International Conference on Machine Learning , articleno =
Guo, Ruiqi and Sun, Philip and Lindgren, Erik and Geng, Quan and Simcha, David and Chern, Felix and Kumar, Sanjiv , title =. Proceedings of the 37th International Conference on Machine Learning , articleno =. 2020 , publisher =
work page 2020
-
[11]
Yunchao Gong and Lazebnik, S. , title =. 2011 , isbn =. doi:10.1109/CVPR.2011.5995432 , booktitle =
-
[12]
Khosla, Prannay and Teterwak, Piotr and Wang, Chen and Sarna, Aaron and Tian, Yonglong and Isola, Phillip and Maschinot, Aaron and Liu, Ce and Krishnan, Dilip , title =. Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =. 2020 , isbn =
work page 2020
-
[13]
Proceedings of the 37th International Conference on Machine Learning , articleno =
Chen, Ting and Kornblith, Simon and Norouzi, Mohammad and Hinton, Geoffrey , title =. Proceedings of the 37th International Conference on Machine Learning , articleno =. 2020 , publisher =
work page 2020
-
[14]
In Defense of the Classification Loss for Person Re-Identification , year=
Zhai, Yao and Guo, Xun and Lu, Yan and Li, Houqiang , booktitle=. In Defense of the Classification Loss for Person Re-Identification , year=
-
[15]
Deep metric learning using Triplet network , booktitle =
Elad Hoffer and Nir Ailon , editor =. Deep metric learning using Triplet network , booktitle =. 2015 , url =
work page 2015
-
[16]
Kilian Q. Weinberger and Lawrence K. Saul , title =. Journal of Machine Learning Research , year =
-
[17]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Schroff, Florian and Kalenichenko, Dmitry and Philbin, James , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[18]
Jia, Menglin and Tang, Luming and Chen, Bor-Chun and Cardie, Claire and Belongie, Serge and Hariharan, Bharath and Lim, Ser-Nam , title =. 2022 , isbn =. doi:10.1007/978-3-031-19827-4_41 , booktitle =
-
[19]
Sung, Yi-Lin and Cho, Jaemin and Bansal, Mohit , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =. 2022 , isbn =
work page 2022
-
[20]
AdapterFusion: Non-Destructive Task Composition for Transfer Learning , booktitle =
Jonas Pfeiffer and Aishwarya Kamath and Andreas R. AdapterFusion: Non-Destructive Task Composition for Transfer Learning , booktitle =. 2021 , url =. doi:10.18653/V1/2021.EACL-MAIN.39 , timestamp =
-
[21]
In: Moens, M.F., Huang, X., Specia, L., Yih, S.W.t
Lester, Brian and Al-Rfou, Rami and Constant, Noah. The Power of Scale for Parameter-Efficient Prompt Tuning. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.243
-
[22]
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Li, Xiang Lisa and Liang, Percy. Prefix-Tuning: Optimizing Continuous Prompts for Generation. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.18653/v1/2021.acl-long.353
-
[23]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
work page 2022
-
[24]
Parameter-Efficient Transfer Learning for
Houlsby, Neil and Giurgiu, Andrei and Jastrzebski, Stanislaw and Morrone, Bruna and De Laroussilhe, Quentin and Gesmundo, Andrea and Attariyan, Mona and Gelly, Sylvain , booktitle =. Parameter-Efficient Transfer Learning for. 2019 , editor =
work page 2019
-
[25]
Understanding the difficulty of training deep feedforward neural networks , author =. Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics , pages =. 2010 , editor =
work page 2010
-
[26]
Momentum Contrast for Unsupervised Visual Representation Learning , year=
He, Kaiming and Fan, Haoqi and Wu, Yuxin and Xie, Saining and Girshick, Ross , booktitle=. Momentum Contrast for Unsupervised Visual Representation Learning , year=
-
[27]
Malkov, Yu A. and Yashunin, D. A. , title =. 2020 , issue_date =. doi:10.1109/TPAMI.2018.2889473 , journal =
-
[28]
Jegou, Herve and Douze, Matthijs and Schmid, Cordelia , title =. 2011 , issue_date =. doi:10.1109/TPAMI.2010.57 , journal =
-
[29]
Jolliffe, Ian T. and Cadima, Jorge , title =. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences , volume =. 2016 , month =. doi:10.1098/rsta.2015.0202 , url =
-
[30]
Billion-Scale Similarity Search with GPUs , year=
Johnson, Jeff and Douze, Matthijs and Jégou, Hervé , journal=. Billion-Scale Similarity Search with GPUs , year=
-
[31]
Nandan Thakur and Nils Reimers and Andreas R. Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) , year=
-
[32]
Parishad BehnamGhader and Vaibhav Adlakha and Marius Mosbach and Dzmitry Bahdanau and Nicolas Chapados and Siva Reddy , booktitle=. 2024 , url=
work page 2024
-
[33]
Search-Adaptor: Embedding Customization for Information Retrieval
Yoon, Jinsung and Chen, Yanfei and Arik, Sercan and Pfister, Tomas. Search-Adaptor: Embedding Customization for Information Retrieval. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.661
-
[34]
Kusupati, Aditya and Bhatt, Gantavya and Rege, Aniket and Wallingford, Matthew and Sinha, Aditya and Ramanujan, Vivek and Howard-Snyder, William and Chen, Kaifeng and Kakade, Sham and Jain, Prateek and Farhadi, Ali , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =. 2022 , isbn =
work page 2022
-
[35]
Matryoshka-Adaptor: Unsupervised and Supervised Tuning for Smaller Embedding Dimensions
Yoon, Jinsung and Sinha, Rajarishi and Arik, Sercan O and Pfister, Tomas. Matryoshka-Adaptor: Unsupervised and Supervised Tuning for Smaller Embedding Dimensions. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.576
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.