Distributed Direct Preference Optimization
Pith reviewed 2026-05-21 05:53 UTC · model grok-4.3
The pith
Direct Preference Optimization converges in distributed environments at rates determined by communication and preference heterogeneity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We provide the first convergence and time-complexity analysis of DPO in distributed environments. Modeling personalized offline RL with user-specific preference distributions, we characterize the induced global optimization landscape. For federated DPO, we derive convergence rates that quantify the impact of client drift, communication frequency, and preference heterogeneity; for decentralized DPO, we establish convergence over general communication graphs and show how spectral connectivity governs optimization speed and consensus.
What carries the argument
User-specific preference distributions that induce a global optimization landscape amenable to convergence analysis under federated client drift and decentralized graph spectral properties.
If this is right
- Convergence rates for federated DPO explicitly incorporate the effects of client drift, communication frequency, and preference heterogeneity.
- Convergence for decentralized DPO holds over general communication graphs, with optimization speed and consensus governed by spectral connectivity.
- Time-complexity bounds are provided for both settings, enabling practical deployment decisions.
- Empirical validation on alignment benchmarks shows robust performance consistent with the theoretical predictions.
Where Pith is reading between the lines
- Such distributed DPO could allow training on user devices while keeping personal preferences private.
- The analysis framework might extend to other preference optimization algorithms in similar distributed regimes.
- Practitioners could use the derived rates to choose communication schedules that balance speed and cost.
Load-bearing premise
User-specific preference distributions induce a global optimization landscape that admits convergence characterization under both federated and decentralized dynamics.
What would settle it
Observation of divergence or failure to achieve consensus in a distributed DPO run when preference heterogeneity exceeds levels where the theory predicts convergence.
Figures

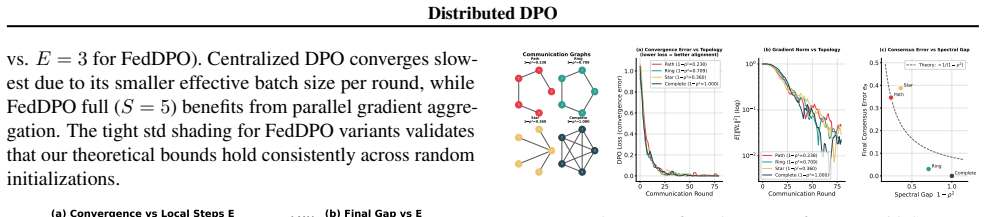

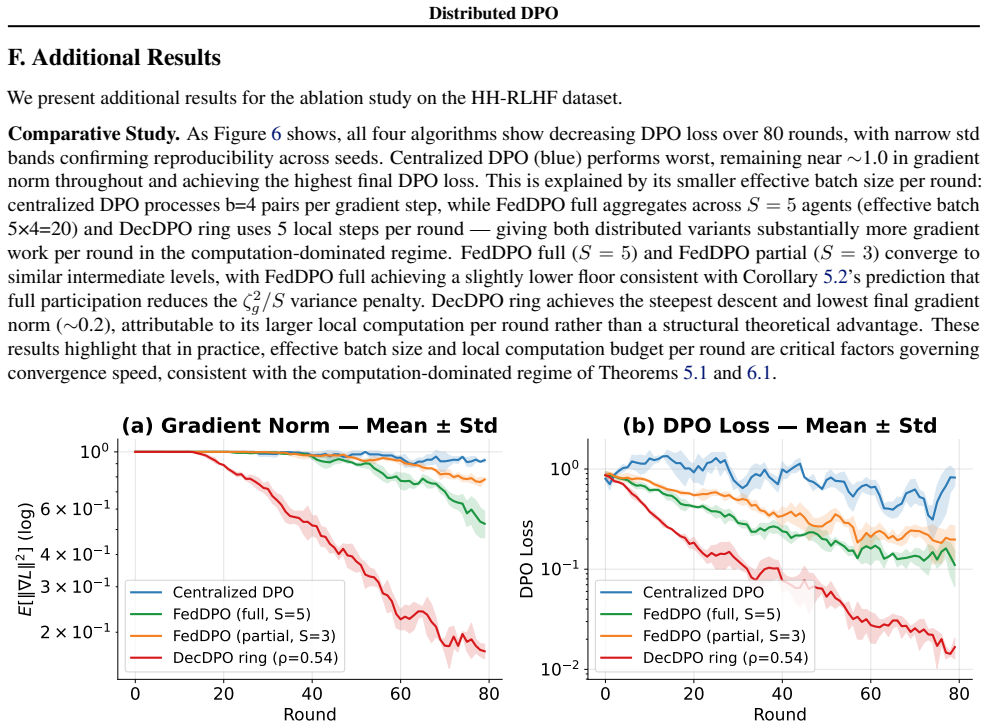
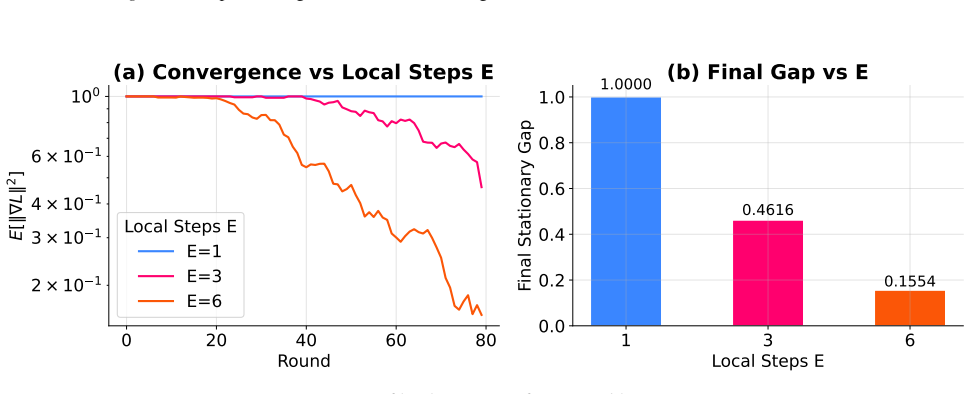





read the original abstract
Preference-based reinforcement learning (RL) is a key paradigm for aligning policies with human judgments, yet its theoretical behavior in distributed settings where preference data are fragmented across heterogeneous users remains poorly understood. Direct Preference Optimization (DPO) avoids explicit reward modeling but lacks convergence guarantees under federated and decentralized training, where communication constraints and non-IID preferences fundamentally alter optimization dynamics. We provide the first convergence and time-complexity analysis of DPO in distributed environments. Modeling personalized offline RL with user-specific preference distributions, we characterize the induced global optimization landscape. For federated DPO, we derive convergence rates that quantify the impact of client drift, communication frequency, and preference heterogeneity; for decentralized DPO, we establish convergence over general communication graphs and show how spectral connectivity governs optimization speed and consensus. Empirically, we corroborate our theoretical insights on standard alignment benchmarks, demonstrating that our proposed methods not only enjoy strong theoretical guarantees but also deliver robust and scalable performance in practice. The code base is available here.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to provide the first convergence and time-complexity analysis of Direct Preference Optimization (DPO) in distributed federated and decentralized environments. It models personalized offline RL using user-specific preference distributions (under the Bradley-Terry model implicit in DPO), characterizes the induced global optimization landscape, derives rates for federated DPO that quantify client drift, communication frequency, and preference heterogeneity, and establishes convergence for decentralized DPO over general communication graphs governed by spectral connectivity. Empirical results on standard alignment benchmarks are presented to support the theoretical findings, with code made available.
Significance. If the central modeling choice and resulting convergence rates hold, the work would be significant for bridging theoretical gaps in preference-based RL under realistic distributed constraints, where data fragmentation and communication limits are common. It offers practical guidance for scalable alignment methods and includes reproducible code, which strengthens its contribution. The analysis extends standard optimization tools to DPO but its impact depends on whether the global landscape characterization is robust to heterogeneity.
major comments (2)
- [§3] §3 (Global Optimization Landscape Characterization): The central claim requires that heterogeneous user-specific preference distributions aggregate into a global objective whose gradient and Hessian satisfy the uniform Lipschitz and strong-convexity bounds used to derive the federated client-drift term and decentralized spectral-gap contraction. The per-user log-ratio terms may introduce additional non-smoothness or higher-order heterogeneity variance when averaged; without an explicit bound showing these effects are absorbed into the existing O(1/T) or O(1/sqrt(T)) rates, the derivations rest on an unverified assumption.
- [§4.2] §4.2 (Decentralized DPO Analysis): The convergence result over general graphs assumes the averaged DPO loss inherits the smoothness parameters needed for the graph-dependent contraction factor. If the mixture of user-specific Bradley-Terry preferences violates this (e.g., via non-uniform Hessian bounds across clients), the spectral-gap dependence would require additional terms not currently accounted for in the stated rate.
minor comments (2)
- [§5] The empirical section would benefit from an ablation varying the degree of preference heterogeneity to directly test the theoretical predictions on client-drift impact.
- [§2] Notation for the global objective (e.g., the precise definition of the averaged loss) should be introduced earlier to aid readability of the rate derivations.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments on our manuscript. We address each major comment below in detail. We have revised the manuscript to provide additional clarifications and explicit bounds where needed to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [§3] §3 (Global Optimization Landscape Characterization): The central claim requires that heterogeneous user-specific preference distributions aggregate into a global objective whose gradient and Hessian satisfy the uniform Lipschitz and strong-convexity bounds used to derive the federated client-drift term and decentralized spectral-gap contraction. The per-user log-ratio terms may introduce additional non-smoothness or higher-order heterogeneity variance when averaged; without an explicit bound showing these effects are absorbed into the existing O(1/T) or O(1/sqrt(T)) rates, the derivations rest on an unverified assumption.
Authors: We appreciate the referee raising this point regarding the aggregation of heterogeneous preferences. In Section 3, the global objective is explicitly defined as the expectation over the mixture of user-specific Bradley-Terry distributions, and we derive the gradient and Hessian of the averaged DPO loss. The per-user log-ratio terms are Lipschitz continuous under the standard boundedness assumptions on the policy and reference model (as in the original DPO analysis). We bound the Lipschitz constant of the global gradient by the maximum per-user constant plus an additive term proportional to the preference heterogeneity measure (defined as the variance of the per-user reward differences). This heterogeneity term is then propagated into the client-drift bound for the federated analysis, preserving the O(1/T) rate without introducing higher-order terms or non-smoothness. A similar argument applies to the Hessian for strong convexity. To address the concern directly, we have added a new supporting lemma (Lemma 3.2) that states the explicit uniform bounds and shows absorption into the existing rates. We believe this makes the derivation fully rigorous. revision: partial
-
Referee: [§4.2] §4.2 (Decentralized DPO Analysis): The convergence result over general graphs assumes the averaged DPO loss inherits the smoothness parameters needed for the graph-dependent contraction factor. If the mixture of user-specific Bradley-Terry preferences violates this (e.g., via non-uniform Hessian bounds across clients), the spectral-gap dependence would require additional terms not currently accounted for in the stated rate.
Authors: We thank the referee for this observation on the decentralized setting. The analysis in Section 4.2 proceeds by showing that the averaged loss remains L-smooth and μ-strongly convex, where L and μ are taken as the worst-case values over all users (i.e., L = max_i L_i and μ = min_i μ_i). The heterogeneity is controlled by the same variance term introduced in Section 3, which appears as a multiplicative factor in the contraction but does not change the dependence on the spectral gap of the communication graph. The proof of Theorem 4.1 explicitly uses the graph Laplacian eigenvalues and absorbs the client-wise variation into a constant that multiplies the 1/(1-λ) term, where λ is the second-largest eigenvalue. No additional terms are needed beyond what is already stated. We have inserted a short paragraph after Theorem 4.1 clarifying this worst-case bounding and the role of the heterogeneity measure to prevent any ambiguity. revision: partial
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper derives convergence rates for distributed DPO by first modeling user-specific preference distributions under the Bradley-Terry model to induce a global optimization landscape, then applying standard federated and decentralized optimization analyses (client drift, spectral gap) to obtain rates under stated smoothness/convexity assumptions. No step reduces a claimed prediction or first-principles result to a fitted parameter or self-citation by construction; the landscape characterization and rate derivations remain independent of the target claims and rely on external optimization theory rather than self-referential fitting or renaming. The analysis is therefore self-contained against the provided modeling assumptions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Personalized offline RL can be modeled with user-specific preference distributions that induce a global optimization landscape.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We derive closed-form expressions for the smoothness constant L and gradient variance ζ_g² in terms of RL horizon H, bounded feature norms ζ_ϕ², inverse temperature β, and trajectory mixing rate C_mix
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
For federated DPO, we derive convergence rates that quantify the impact of client drift, communication frequency, and preference heterogeneity
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Direct preference optimization with an offset
Amini, A., Vieira, T., and Cotterell, R. Direct preference optimization with an offset. InFindings of the Asso- ciation for Computational Linguistics: ACL 2024, pp. 9954–9972,
work page 2024
-
[2]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Bai, Y ., Jones, A., Ndousse, K., Askell, A., Chen, A., Das- Sarma, N., Drain, D., Fort, S., Ganguli, D., Henighan, T., et al. Training a helpful and harmless assistant with rein- forcement learning from human feedback.arXiv preprint arXiv:2204.05862,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Cai, Z., Cao, H., Lu, W., Zhang, L., and Xiong, H. Safe multi-agent reinforcement learning through decentral- ized multiple control barrier functions.arXiv preprint arXiv:2103.12553,
-
[4]
Decen- tralized semantic traffic control in avs using rl and dqn for dynamic roadblocks
Figetakis, E., Bello, Y ., Refaey, A., and Shami, A. Decen- tralized semantic traffic control in avs using rl and dqn for dynamic roadblocks. InICC 2024-IEEE International Conference on Communications, pp. 5449–5454. IEEE,
work page 2024
-
[5]
Uncertainty-penalized direct preference optimization
Houliston, S., Pace, A., Immer, A., and R ¨atsch, G. Uncertainty-penalized direct preference optimization. arXiv preprint arXiv:2410.20187,
-
[6]
J., Kim, B., Lee, H., Bae, K., and Lee, M
Kim, G.-H., Jang, Y ., Kim, Y . J., Kim, B., Lee, H., Bae, K., and Lee, M. Safedpo: A simple approach to direct prefer- ence optimization with enhanced safety.arXiv preprint arXiv:2505.20065,
-
[7]
On the convergence of FedAvg on non- IID data
Li, G., Gomez, R., Nakamura, K., and He, B. Human- centered reinforcement learning: A survey.IEEE Trans- actions on Human-Machine Systems, 49(4):337–349, 2019a. Li, X., Huang, K., Yang, W., Wang, S., and Zhang, Z. On the convergence of fedavg on non-iid data.arXiv preprint arXiv:1907.02189, 2019b. Liu, L., Guan, Y ., Wang, Z., Shen, R., Zheng, G., Fu, X.,...
-
[8]
Mak, H. Y ., Fan, F. X., Lanzend¨orfer, L. A., Tan, C., Ooi, W. T., and Wattenhofer, R. Caesar: Enhancing federated rl in heterogeneous mdps through convergence-aware sam- pling with screening.arXiv preprint arXiv:2403.20156,
-
[9]
Healthcare data security technology: Hipaa compliance
Mbonihankuye, S., Nkunzimana, A., and Ndagijimana, A. Healthcare data security technology: Hipaa compliance. Wireless communications and mobile computing, 2019 (1):1927495,
work page 2019
-
[10]
Disentan- gling length from quality in direct preference optimiza- tion
Park, R., Rafailov, R., Ermon, S., and Finn, C. Disentan- gling length from quality in direct preference optimiza- tion. InFindings of the Association for Computational Linguistics: ACL 2024, pp. 4998–5017,
work page 2024
-
[11]
Sabry, F., Eltaras, T., Labda, W., Alzoubi, K., and Malluhi, Q. Machine learning for healthcare wearable devices: the big picture.Journal of Healthcare Engineering, 2022(1): 4653923,
work page 2022
-
[12]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Wang, J., Yan, Y ., Hu, Y ., and Yang, X. A reinforcement learning from human feedback based method for task allo- cation of human robot collaboration assembly considering human preference.Advanced Engineering Informatics, 66:103497, 2025a. 11 Distributed DPO Wang, P., Xu, A., Zhou, Y ., Xiong, C., and Joty, S. Direct judgement preference optimization. In...
-
[14]
Xu, P., Gao, F., and Gu, Q. Sample efficient policy gradient methods with recursive variance reduction.arXiv preprint arXiv:1909.08610,
-
[15]
Zhang, G. and Kashima, H. Learning state importance for preference-based reinforcement learning.Machine Learning, 113(4):1885–1901,
work page 1901
-
[16]
Zhu, K., Yi, L., Zhao, Z., Qi, Z., Yu, H., and Hu, Q. Fed- pdpo: Federated personalized direct preference optimiza- tion for large language model alignment.arXiv preprint arXiv:2603.19741,
-
[17]
12 Distributed DPO A. Technical Remark on Log-Linear Softmax Parameterization The log-linear softmax parameterization is primarily introduced to enable explicit characterization of the smoothness and variance constants appearing in the distributed DPO convergence analysis. In particular, for policies of the form πθ(u|s) = exp(θ⊤ϕ(s, u))P u′∈A exp(θ⊤ϕ(s, u...
work page 2008
-
[18]
presents a cleaner asymptotic form that emphasizes the dominant scaling behavior with respect to the number of rounds R, participation level S, local update stepsE, heterogeneityκ 2, and stochastic gradient varianceζ 2 g as follows: O Lθ0 − L∗ ηER +L 2η2Eκ2 + L2η2E2ζ2 g S + Lηζ2 g S More precisely, Eq. 9 should be interpreted as a coarsened upper bound ob...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.