Assessing Estimate of CATE from Observational Data via an RCT Study
Pith reviewed 2026-05-21 02:50 UTC · model grok-4.3
The pith
A framework called CAFE directly tests how well CATE estimates from observational data match randomized trial results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that partitioning the randomized trial's covariate space according to propensity scores estimated from observational data allows direct comparison of observationally derived CATE values with unbiased group-level experimental averages, providing a goodness-of-fit assessment for the CATE estimator with theoretical guarantees under null and alternative hypotheses, including a maximum-type test for localized issues, and a two-stage procedure to detect unobserved confounders.
What carries the argument
The CAFE framework, which partitions RCT covariate space by propensity scores to benchmark observational CATE estimates against experimental group averages.
If this is right
- If the CAFE test passes, the observational CATE estimate can be considered reliable for the population covered by the trial.
- The method works for a wide range of CATE learners including machine learning approaches.
- It can detect the presence of unobserved confounders using both data sources.
- Maximum-type tests improve power for finding localized poor fit.
Where Pith is reading between the lines
- This validation step could encourage more routine use of observational data for personalized treatment decisions when paired with RCTs.
- Future work might extend the partitioning to other balancing methods beyond propensity scores.
- If successful, it provides a practical tool for model selection among different CATE estimators.
Load-bearing premise
The observational and RCT populations must have sufficient overlap in covariates so that propensity score groups allow fair comparison where the trial averages serve as unbiased checks for the observational estimates.
What would settle it
A simulation in which a deliberately misspecified observational CATE learner is tested against RCT data with known true effects should produce rejection by the CAFE procedure at high rate, while a correct learner should not; failure to distinguish these cases would falsify the guarantees.
Figures
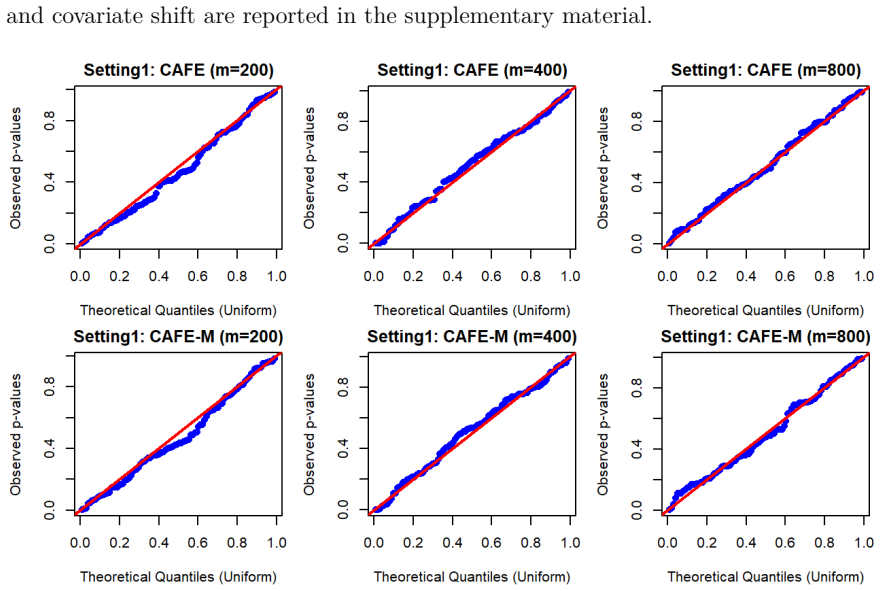
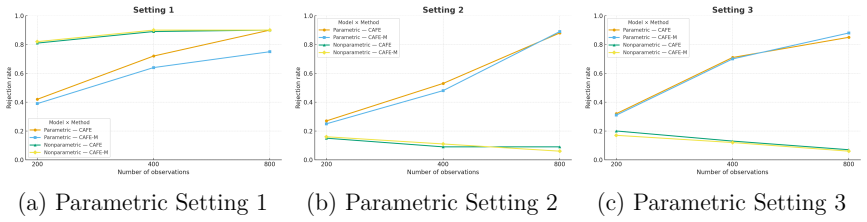


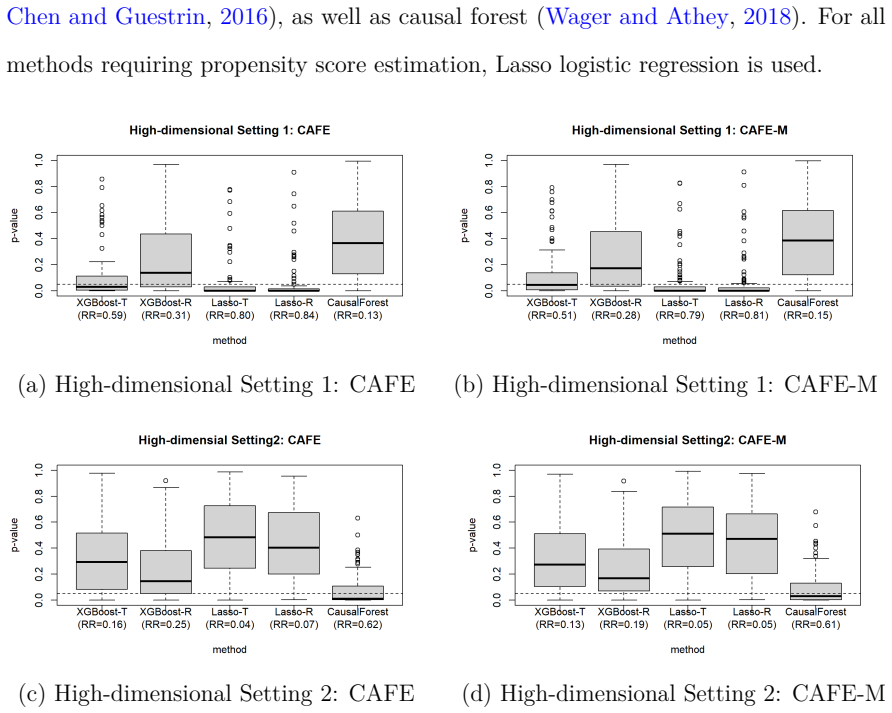
read the original abstract
Conditional average treatment effects (CATEs) are increasingly estimated from observational data and used to guide policy and individualized treatment decisions. Before such estimates can be trusted in practice, their predictive fitness needs to be assessed, yet observational data alone offer limited opportunities for doing so. We propose CATE Assessment via Fitness Evaluation (CAFE), a formal framework for directly assessing the goodness-of-fit of a CATE estimate learned from observational data, rather than the full underlying outcome model, using evidence from a randomized trial. CAFE partitions the trial covariate space according to estimated propensity scores (or the like) and compares observationally derived conditional treatment effects with group-level experimental averages. The framework accommodates a broad class of CATE learners, including parametric models and flexible machine learning methods such as causal forest and boosting. We establish theoretical guarantees under both the null and alternative hypotheses, and introduce a maximum-type extension to improve sensitivity to localized lack of fit. When both randomized trial and observational data are available, we further develop a two-stage procedure to detect the existence of unobserved confounders. Extensive numerical studies show the utility of the CAFE approach when assessing observational-derived CATE estimates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the CAFE framework for assessing the goodness-of-fit of CATE estimates learned from observational data by leveraging an RCT. It partitions RCT samples according to propensity scores (or similar) estimated from the observational data and compares the observational CATE values to within-bin experimental average treatment effects from the RCT. The framework claims theoretical guarantees under both null and alternative hypotheses for a broad class of CATE learners, introduces a maximum-type statistic for localized lack of fit, develops a two-stage procedure for detecting unobserved confounders when both data sources are available, and presents numerical studies demonstrating utility.
Significance. If the central construction is valid, CAFE offers a targeted way to validate CATE estimates rather than the full outcome model, which is practically relevant when observational data are plentiful and RCTs provide a benchmark. The accommodation of flexible learners such as causal forests and the extension to unobserved-confounder detection are constructive. The numerical studies are a positive element, but the overall significance is limited by the strength of the transportability assumption required for the benchmark to be unbiased.
major comments (2)
- [theoretical guarantees and test statistic derivation] The theoretical guarantees (abstract and the development of the test statistic) rest on the implicit assumption that the true CATE function is identical across the observational and RCT populations within propensity-score strata. This is load-bearing: any population-specific effect modification produces systematic discrepancy even when the observational learner is correctly specified and there is no confounding. The paper should state this assumption explicitly, provide a relaxation or sensitivity analysis, and clarify whether the null hypothesis tests correct specification, transportability, or both.
- [partitioning and maximum-type extension] Partitioning on a one-dimensional propensity-score summary (Section on partitioning procedure) can leave residual imbalance on higher-dimensional effect modifiers within bins. This can bias the RCT benchmark without being detected by the proposed maximum-type statistic. The manuscript should either derive bounds on the resulting bias or demonstrate via simulation that the procedure remains valid under plausible violations of common support in the effect-modifier space.
minor comments (2)
- [methods] Notation for the propensity-score-based bins and the within-bin averages should be introduced earlier and used consistently to improve readability.
- [numerical studies] The numerical studies would benefit from explicit reporting of the overlap diagnostics between observational and RCT covariate distributions within each bin.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: The theoretical guarantees (abstract and the development of the test statistic) rest on the implicit assumption that the true CATE function is identical across the observational and RCT populations within propensity-score strata. This is load-bearing: any population-specific effect modification produces systematic discrepancy even when the observational learner is correctly specified and there is no confounding. The paper should state this assumption explicitly, provide a relaxation or sensitivity analysis, and clarify whether the null hypothesis tests correct specification, transportability, or both.
Authors: We agree that the assumption of CATE transportability within propensity-score strata is central to the theoretical results. In the revised manuscript we will state this assumption explicitly in the introduction and in the section on the test statistic. We will clarify that the null hypothesis is a joint test of correct specification of the observational CATE estimator and transportability of the CATE across populations within the strata. For relaxation, we will add a brief sensitivity analysis in the numerical studies that perturbs the CATE by population-specific effect modifiers and reports the resulting size and power of the procedure; we will also note that the two-stage unobserved-confounder procedure can be used to flag gross violations of transportability. revision: yes
-
Referee: Partitioning on a one-dimensional propensity-score summary (Section on partitioning procedure) can leave residual imbalance on higher-dimensional effect modifiers within bins. This can bias the RCT benchmark without being detected by the proposed maximum-type statistic. The manuscript should either derive bounds on the resulting bias or demonstrate via simulation that the procedure remains valid under plausible violations of common support in the effect-modifier space.
Authors: We acknowledge that one-dimensional propensity-score partitioning does not guarantee balance on higher-dimensional effect modifiers. In the revision we will derive a simple bound on the bias in the RCT benchmark that arises from residual imbalance, assuming the effect modification is Lipschitz continuous with a known constant. We will also add a targeted simulation study that introduces higher-dimensional modifiers, varies the degree of common support, and reports the empirical coverage and power of both the original and maximum-type statistics under these violations. revision: yes
Circularity Check
No circularity: CAFE assessment relies on external RCT benchmarks independent of observational CATE fit.
full rationale
The derivation chain in the paper establishes a framework that partitions RCT covariate space by observational propensity scores and directly compares observationally estimated CATE values against within-bin experimental averages from the RCT. This comparison uses an independent data source (the randomized trial) as the benchmark rather than any quantity fitted or derived solely from the observational data inputs. Theoretical guarantees under null and alternative hypotheses are stated under explicit assumptions of overlap, common support, and transportability within strata; these assumptions are external to the observational learner and do not create a self-referential loop where the assessment result is forced by construction from the same fitted parameters. No self-citations appear as load-bearing steps, and the method accommodates a broad class of CATE learners without renaming or smuggling prior results. The framework is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Randomized trial provides unbiased estimates of treatment effects within propensity-defined groups
- domain assumption Sufficient overlap exists between observational and trial covariate distributions
Reference graph
Works this paper leans on
-
[1]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Regression shrinkage and selection via the lasso , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 1996 , publisher=
work page 1996
-
[2]
Journal of the American Statistical Association , number=
On the comparative analysis of average treatment effects estimation via data combination , author=. Journal of the American Statistical Association , number=. 2024 , publisher=
work page 2024
-
[3]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Robust estimation of encouragement design intervention effects transported across sites , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2017 , publisher=
work page 2017
-
[4]
Social science & medicine , volume=
Understanding and misunderstanding randomized controlled trials , author=. Social science & medicine , volume=. 2018 , publisher=
work page 2018
-
[5]
Empirical evidence of bias in treatment effect estimates in controlled trials with different interventions and outcomes: meta-epidemiological study , author=. bmj , volume=. 2008 , publisher=
work page 2008
-
[6]
Combining experimental and observational data through a power likelihood , author=. Biometrics , volume=. 2025 , publisher=
work page 2025
-
[7]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Elastic integrative analysis of randomised trial and real-world data for treatment heterogeneity estimation , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2023 , publisher=
work page 2023
-
[8]
Journal of Research on Educational Effectiveness , volume=
Assessing methods for generalizing experimental impact estimates to target populations , author=. Journal of Research on Educational Effectiveness , volume=. 2016 , publisher=
work page 2016
-
[9]
Journal of Causal Inference , volume=
Causal effect on a target population: a sensitivity analysis to handle missing covariates , author=. Journal of Causal Inference , volume=. 2022 , publisher=
work page 2022
-
[10]
Generalizing treatment effects with incomplete covariates: Identifying assumptions and multiple imputation algorithms , author=. Biometrical Journal , volume=. 2023 , publisher=
work page 2023
-
[11]
arXiv preprint arXiv:2208.10163 , year=
Identification and estimation of treatment effects on long-term outcomes in clinical trials with external observational data , author=. arXiv preprint arXiv:2208.10163 , year=
-
[12]
In: The economics of artificial intelligence, 507–552
Combining experimental and observational data to estimate treatment effects on long term outcomes , author=. arXiv preprint arXiv:2006.09676 , year=
-
[13]
Combining observational and experimental datasets using shrinkage estimators , author=. Biometrics , volume=. 2023 , publisher=
work page 2023
-
[14]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Model selection for estimating treatment effects , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2014 , publisher=
work page 2014
- [15]
-
[16]
Methods for integrating trials and non-experimental data to examine treatment effect heterogeneity , author=. Statistical Science , volume=
-
[17]
arXiv preprint arXiv:2111.15012 , year=
Adaptive combination of randomized and observational data , author=. arXiv preprint arXiv:2111.15012 , year=
-
[18]
Advances in Neural Information Processing Systems , volume=
Removing hidden confounding by experimental grounding , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
Statistics in Medicine , volume=
Propensity score methods for merging observational and experimental datasets , author=. Statistics in Medicine , volume=. 2022 , publisher=
work page 2022
-
[20]
arXiv preprint arXiv:2007.12922 , year=
Improved inference for heterogeneous treatment effects using real-world data subject to hidden confounding , author=. arXiv preprint arXiv:2007.12922 , year=
-
[21]
Conference on Causal Learning and Reasoning , pages=
Integrative R -learner of heterogeneous treatment effects combining experimental and observational studies , author=. Conference on Causal Learning and Reasoning , pages=. 2022 , organization=
work page 2022
-
[22]
Quasi-oracle estimation of heterogeneous treatment effects , author=. Biometrika , volume=. 2021 , publisher=
work page 2021
-
[23]
Combining observational and randomized data for estimating heterogeneous treatment effects , author=. arXiv preprint arXiv:2202.12891 , year=
-
[24]
A comparison of methods for model selection when estimating individual treatment effects
A comparison of methods for model selection when estimating individual treatment effects , author=. arXiv preprint arXiv:1804.05146 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
On the application of probability theory to agricultural experiments. Essay on principles , author=. Ann. Agricultural Sciences , pages=
- [26]
-
[27]
Causal inference methods for combining randomized trials and observational studies: a review , author=. Statistical Science , volume=. 2024 , publisher=
work page 2024
-
[28]
Journal of the Royal Statistical Society Series A: Statistics in Society , volume=
The use of propensity scores to assess the generalizability of results from randomized trials , author=. Journal of the Royal Statistical Society Series A: Statistics in Society , volume=. 2011 , publisher=
work page 2011
-
[29]
Generalizing causal inferences from individuals in randomized trials to all trial-eligible individuals , author=. Biometrics , volume=. 2019 , publisher=
work page 2019
-
[30]
Journal of the Royal Statistical Society Series A: Statistics in Society , volume=
Re-weighting the randomized controlled trial for generalization: finite-sample error and variable selection , author=. Journal of the Royal Statistical Society Series A: Statistics in Society , volume=. 2025 , publisher=
work page 2025
-
[31]
Journal of the American Statistical Association , volume=
Estimation and inference of heterogeneous treatment effects using random forests , author=. Journal of the American Statistical Association , volume=. 2018 , publisher=
work page 2018
-
[32]
Proceedings of the National Academy of Sciences , volume=
Metalearners for estimating heterogeneous treatment effects using machine learning , author=. Proceedings of the National Academy of Sciences , volume=. 2019 , publisher=
work page 2019
-
[33]
Causal inference in statistics, social, and biomedical sciences , author=. 2015 , publisher=
work page 2015
-
[34]
The Review of Economics and Statistics , volume=
Nonparametric tests for treatment effect heterogeneity , author=. The Review of Economics and Statistics , volume=. 2008 , publisher=
work page 2008
-
[35]
Journal of Business & Economic Statistics , volume=
Estimating conditional average treatment effects , author=. Journal of Business & Economic Statistics , volume=. 2015 , publisher=
work page 2015
-
[36]
Journal of Business & Economic Statistics , volume=
Estimation of conditional average treatment effects with high-dimensional data , author=. Journal of Business & Economic Statistics , volume=. 2022 , publisher=
work page 2022
-
[37]
Econometrica: Journal of the Econometric Society , pages=
Root-N-consistent semiparametric regression , author=. Econometrica: Journal of the Econometric Society , pages=. 1988 , publisher=
work page 1988
-
[38]
The Econometrics Journal , volume=
Double/debiased machine learning for treatment and structural parameters , author=. The Econometrics Journal , volume=. 2018 , publisher=
work page 2018
-
[39]
Theory of Probability & Its Applications , volume=
A Lyapunov-type bound in Rd , author=. Theory of Probability & Its Applications , volume=. 2005 , publisher=
work page 2005
-
[40]
Proceedings of the National Academy of Sciences , volume=
Recursive partitioning for heterogeneous causal effects , author=. Proceedings of the National Academy of Sciences , volume=. 2016 , publisher=
work page 2016
-
[41]
Xgboost: A scalable tree boosting system , author=. Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining , pages=
-
[42]
Journal of Clinical Epidemiology , volume=
Models with interactions overestimated heterogeneity of treatment effects and were prone to treatment mistargeting , author=. Journal of Clinical Epidemiology , volume=. 2019 , publisher=
work page 2019
-
[43]
Electronic Journal of Statistics , volume=
Towards optimal doubly robust estimation of heterogeneous causal effects , author=. Electronic Journal of Statistics , volume=. 2023 , publisher=
work page 2023
-
[44]
The Annals of Applied Statistics , pages=
Estimating treatment effect heterogeneity in randomized program evaluation , author=. The Annals of Applied Statistics , pages=. 2013 , publisher=
work page 2013
-
[45]
Annual Review of Statistics and Its Application , volume=
A review of generalizability and transportability , author=. Annual Review of Statistics and Its Application , volume=. 2023 , publisher=
work page 2023
-
[46]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Long-term causal inference under persistent confounding via data combination , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2025 , publisher=
work page 2025
-
[47]
Journal of the Royal Statistical Society Series A: Statistics in Society , volume=
Generalizing evidence from randomized trials using inverse probability of sampling weights , author=. Journal of the Royal Statistical Society Series A: Statistics in Society , volume=. 2018 , publisher=
work page 2018
-
[48]
American Journal of Epidemiology , volume=
Generalizing evidence from randomized clinical trials to target populations: the ACTG 320 trial , author=. American Journal of Epidemiology , volume=. 2010 , publisher=
work page 2010
-
[49]
European Journal of Epidemiology , volume=
Extending inferences from a randomized trial to a target population , author=. European Journal of Epidemiology , volume=. 2019 , publisher=
work page 2019
-
[50]
Journal of Educational and Behavioral Statistics , volume=
Improving generalizations from experiments using propensity score subclassification: Assumptions, properties, and contexts , author=. Journal of Educational and Behavioral Statistics , volume=. 2013 , publisher=
work page 2013
-
[51]
Improving trial generalizability using observational studies , author=. Biometrics , volume=. 2023 , publisher=
work page 2023
-
[52]
Journal of Computational and Graphical Statistics , volume=
Transfer learning of individualized treatment rules from experimental to real-world data , author=. Journal of Computational and Graphical Statistics , volume=. 2023 , publisher=
work page 2023
-
[53]
The Econometrics Journal , volume=
Debiased machine learning of conditional average treatment effects and other causal functions , author=. The Econometrics Journal , volume=. 2021 , publisher=
work page 2021
-
[54]
Journal of Applied Econometrics , volume=
Doubly robust uniform confidence band for the conditional average treatment effect function , author=. Journal of Applied Econometrics , volume=. 2017 , publisher=
work page 2017
-
[55]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
An omnibus non-parametric test of equality in distribution for unknown functions , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2019 , publisher=
work page 2019
-
[56]
Journal of Econometrics , volume=
Permutation test for heterogeneous treatment effects with a nuisance parameter , author=. Journal of Econometrics , volume=. 2021 , publisher=
work page 2021
-
[57]
International Conference on Artificial Intelligence and Statistics , pages=
Calibration error for heterogeneous treatment effects , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2022 , organization=
work page 2022
-
[58]
Generic machine learning inference on heterogeneous treatment effects in randomized experiments, with an application to immunization in India , author=. 2018 , institution=
work page 2018
-
[59]
International conference on predictive applications and APIs , pages=
Causal inference and uplift modelling: A review of the literature , author=. International conference on predictive applications and APIs , pages=. 2017 , organization=
work page 2017
-
[60]
International Conference on Machine Learning , pages=
Validating causal inference models via influence functions , author=. International Conference on Machine Learning , pages=. 2019 , organization=
work page 2019
-
[61]
International Conference on Machine Learning , pages=
Counterfactual cross-validation: Stable model selection procedure for causal inference models , author=. International Conference on Machine Learning , pages=. 2020 , organization=
work page 2020
-
[62]
Review of Economics and statistics , volume=
Nonparametric estimation of average treatment effects under exogeneity: A review , author=. Review of Economics and statistics , volume=. 2004 , publisher=
work page 2004
-
[63]
Tennessee Board of Education , year=
The State of Tennessee's student/teacher achievement ratio (STAR) Project , author=. Tennessee Board of Education , year=
-
[64]
The Quarterly Journal of Economics , volume=
Experimental Estimates of Education Production Functions , author=. The Quarterly Journal of Economics , volume=. 1999 , publisher=
work page 1999
-
[65]
The central role of the propensity score in observational studies for causal effects , author=. Biometrika , volume=. 1983 , publisher=
work page 1983
-
[66]
The prognostic analogue of the propensity score , author=. Biometrika , volume=. 2008 , publisher=
work page 2008
-
[67]
Journal of the American statistical Association , volume=
Statistics and causal inference , author=. Journal of the American statistical Association , volume=. 1986 , publisher=
work page 1986
-
[68]
2017 IEEE International Conference on Data Mining (ICDM) , pages=
A practically competitive and provably consistent algorithm for uplift modeling , author=. 2017 IEEE International Conference on Data Mining (ICDM) , pages=. 2017 , organization=
work page 2017
-
[69]
Policy learning with observational data , author=. Econometrica , volume=. 2021 , publisher=
work page 2021
-
[70]
A survey of cross-validation procedures for model selection , author=. Statistics Surveys , volume=
-
[71]
Statistical methodology , volume=
Asymptotics of cross-validated risk estimation in estimator selection and performance assessment , author=. Statistical methodology , volume=. 2005 , publisher=
work page 2005
-
[72]
Combining estimates of conditional treatment effects , author=. Econometric Theory , volume=. 2019 , publisher=
work page 2019
-
[73]
Marginal structural models to estimate the causal effect of zidovudine on the survival of HIV-positive men , author=. Epidemiology , volume=. 2000 , publisher=
work page 2000
-
[74]
The American economic review , pages=
Evaluating the econometric evaluations of training programs with experimental data , author=. The American economic review , pages=. 1986 , publisher=
work page 1986
-
[75]
Journal of the American statistical Association , volume=
Identification of causal effects using instrumental variables , author=. Journal of the American statistical Association , volume=. 1996 , publisher=
work page 1996
-
[76]
Journal of the Royal Statistical Society Series A: Statistics in Society , volume=
Misunderstandings between experimentalists and observationalists about causal inference , author=. Journal of the Royal Statistical Society Series A: Statistics in Society , volume=. 2008 , publisher=
work page 2008
-
[77]
Journal of the American statistical Association , volume=
Model-based direct adjustment , author=. Journal of the American statistical Association , volume=. 1987 , publisher=
work page 1987
-
[78]
Minimax-optimal policy learning under unobserved confounding , author=. Management Science , volume=. 2021 , publisher=
work page 2021
-
[79]
Learning from a biased sample , author=. arXiv preprint arXiv:2209.01754 , year=
-
[80]
Journal of the American Statistical Association , volume=
A distributional approach for causal inference using propensity scores , author=. Journal of the American Statistical Association , volume=. 2006 , publisher=
work page 2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.