E-ReCON: An Energy- and Resource-Efficient Precision-Configurable Sparse nvCIM Macro for Conventional and Spiking Neural Edge Inference
Pith reviewed 2026-05-21 02:34 UTC · model grok-4.3
The pith
A 3T1R ReRAM bitcell with interleaved adder tree powers a sparse nvCIM macro reaching 419 TOPS/W for CNN and SNN edge inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The 3T1R ReRAM bitcell enables direct in-memory AND multiplication that works for both dense CNN and sparse SNN workloads; paired with the interleaved adder tree, this yields a precision-configurable nvCIM macro whose measured performance reaches 0.48 ns minimum latency, 2.31-3.1 TOPS throughput, and 419 TOPS/W energy efficiency while preserving accuracy under full PVT and ReRAM variability.
What carries the argument
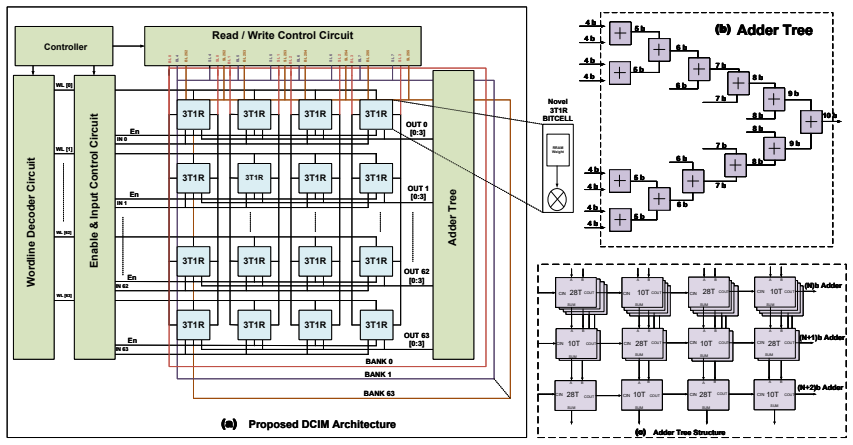
The 3T1R ReRAM bitcell that performs AND-based in-memory multiplication, together with the interleaved 10T/28T adder tree that reduces transistor count and power consumption.
If this is right
- 40 percent weight pruning reduces MAC operations and cycle count while retaining nearly 99.8 percent of baseline accuracy.
- The same bitcell supports 2A2W spike-weight multiplication for SNNs with accuracy close to floating-point baselines on CIFAR-10, CIFAR-100 and ImageNet-1K.
- Reported latency and energy improvements of 30-40 percent versus prior ADC-based ReRAM-CIM designs translate directly into faster, lower-power edge inference.
- The macro scales to IoT, biomedical sensing and neuromorphic workloads that require both CNN and SNN support in a single hardware block.
Where Pith is reading between the lines
- Lower energy per inference could extend operating time for battery-powered sensors or wearables that run continuous edge classification.
- The precision-configurable feature may allow dynamic trade-offs between accuracy and power on the same chip when network conditions change.
- Similar bitcell and adder-tree techniques could be ported to other emerging non-volatile memories to test whether the efficiency gains generalize beyond ReRAM.
Load-bearing premise
The 3T1R ReRAM bitcell continues to produce correct multiplication results under full process, voltage, temperature variations and ReRAM device variability.
What would settle it
A silicon measurement in which accuracy on LeNet-5, VGG-8 or ResNet-18 falls more than a few percent below the reported figures when the macro is operated across the full PVT corner set with real ReRAM variability.
Figures




read the original abstract
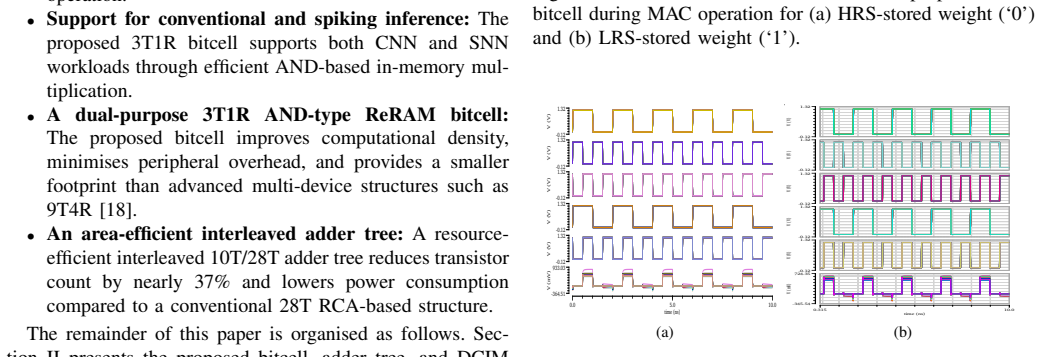
This work presents E-ReCON, a 16 Kb energy and resource-efficient digital compute-in-memory (DCIM) macro based on a compact 3T1R ReRAM bitcell for edge-AI inference. The proposed bitcell occupies only 0.85 um^2 and supports reliable AND-based in-memory multiplication for both conventional convolutional neural network (CNN) and spiking neural network (SNN) workloads. To reduce accumulation overhead, a novel interleaved 10T/28T adder tree is introduced, reducing transistor count and power consumption by 37% and 28%, respectively, compared to a conventional 28T RCA-based design. Implemented in 65 nm CMOS at 1.2 V, the proposed macro achieves a minimum latency of 0.48 ns, throughput of 2.31-3.1 TOPS, and energy efficiency of up to 419 TOPS/W. When evaluated on LeNet-5, AlexNet, and CNN-8 models, the macro achieves 97.81%, 93.23%, and 96.51% accuracy on MNIST/A-Z, CIFAR10, and SVHN datasets, respectively. In addition, 40% pruning preserves nearly 99.8% of the original accuracy while reducing MAC operations and computation cycles. For SNN-oriented workloads, the proposed AND-type bitcell efficiently supports spike-weight multiplication with low switching activity, where the 2A2W configuration achieves accuracy close to the FP32 baseline across VGG-8, VGG-16, and ResNet-18 networks on CIFAR-10, CIFAR-100, and ImageNet-1K datasets. Compared to prior ADC-based ReRAM-CIM designs, the proposed architecture improves latency and energy efficiency by nearly 30-40% while maintaining robust operation under full PVT and ReRAM variability. Overall, E-ReCON provides a scalable, low-latency, and energy-efficient nvCIM platform for next-generation edge-AI, IoT, biomedical sensing, and neuromorphic applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents E-ReCON, a 16 Kb digital compute-in-memory (DCIM) macro in 65 nm CMOS based on a compact 3T1R ReRAM bitcell that supports AND-based in-memory multiplication for both CNN and SNN workloads. It introduces an interleaved 10T/28T adder tree to reduce transistor count and power, reports a minimum latency of 0.48 ns, throughput of 2.31-3.1 TOPS, and energy efficiency up to 419 TOPS/W at 1.2 V, along with accuracy results (97.81% on MNIST, 93.23% on CIFAR-10, etc.) for LeNet-5, AlexNet, VGG, and ResNet models. The work claims 30-40% improvements in latency and energy efficiency over prior ADC-based ReRAM-CIM designs while maintaining robustness under full PVT and ReRAM variability, plus support for 40% pruning with minimal accuracy loss and efficient spike-weight multiplication in SNN configurations.
Significance. If the performance metrics and robustness claims hold, the work would offer a concrete advance in compact, low-latency nvCIM hardware for edge inference, with notable strengths in its dual support for CNN and SNN workloads, the resource-efficient adder tree, and explicit benchmarking on standard models including ImageNet-1K. The reported transistor-count and power reductions (37% and 28%) and pruning results provide practical value for resource-constrained applications.
major comments (2)
- [Abstract] Abstract: The central claim that the 3T1R bitcell 'maintains robust operation under full PVT and ReRAM variability' while enabling the reported 0.48 ns latency, 419 TOPS/W efficiency, and 30-40% improvement over prior designs is load-bearing, yet the manuscript provides no Monte-Carlo simulations, corner-analysis results, or quantitative data on how resistance variation, temperature, or voltage shifts affect the effective multiply-accumulate value or accuracy.
- [Results] Results and evaluation sections: Accuracy figures (e.g., 97.81% on MNIST for LeNet-5, close-to-FP32 for 2A2W SNN on VGG-8) are stated without accompanying error bars, simulation-setup details, or explicit validation that post-hoc pruning and variability do not introduce bit errors in the AND-based multiplication.
minor comments (2)
- [Abstract] Abstract: The throughput range (2.31-3.1 TOPS) should specify the operating conditions or precision configurations that produce each value.
- [Related Work] Related work or comparison sections: Direct citations and tabulated metrics for the specific prior ADC-based ReRAM-CIM designs should be included to allow verification of the stated 30-40% latency and energy-efficiency gains.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review of our manuscript. We agree that strengthening the presentation of robustness data and accuracy evaluation details will improve the paper. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the 3T1R bitcell 'maintains robust operation under full PVT and ReRAM variability' while enabling the reported 0.48 ns latency, 419 TOPS/W efficiency, and 30-40% improvement over prior designs is load-bearing, yet the manuscript provides no Monte-Carlo simulations, corner-analysis results, or quantitative data on how resistance variation, temperature, or voltage shifts affect the effective multiply-accumulate value or accuracy.
Authors: We acknowledge that the manuscript does not present explicit Monte-Carlo or corner-analysis results quantifying the effects of resistance variation, temperature, and voltage on MAC values or accuracy. The robustness statement is grounded in the fully digital AND-based multiplication performed by the 3T1R bitcell, which produces a binary result and is therefore inherently less sensitive to analog-level variations than current-summing ADC-based ReRAM CIM designs. To directly address the concern, we will add Monte-Carlo simulation results and corner analyses in the revised manuscript, reporting the resulting variation in effective MAC outputs and end-to-end accuracy. revision: yes
-
Referee: [Results] Results and evaluation sections: Accuracy figures (e.g., 97.81% on MNIST for LeNet-5, close-to-FP32 for 2A2W SNN on VGG-8) are stated without accompanying error bars, simulation-setup details, or explicit validation that post-hoc pruning and variability do not introduce bit errors in the AND-based multiplication.
Authors: The reported accuracies were obtained from post-layout circuit simulations of the macro interfaced with the neural-network models. We will expand the results section to include (i) explicit simulation-setup details (tools, models, and flow), (ii) error bars derived from multiple Monte-Carlo runs that incorporate device and process variation, and (iii) a direct validation that the digital AND operation combined with the chosen bitcell sizing produces zero bit errors under the considered pruning ratios and variability conditions. These additions will be presented alongside the existing accuracy numbers. revision: yes
Circularity Check
No circularity: hardware implementation results are independent of any self-referential derivation
full rationale
The paper is a circuit design and benchmarking study reporting post-layout or measured metrics (0.48 ns latency, 419 TOPS/W, 97.81% MNIST accuracy) from a 65 nm CMOS implementation of the 3T1R bitcell and interleaved adder tree. These quantities are obtained directly from the physical design flow and workload execution rather than from any equation, fitted parameter, or model that reduces to its own inputs by construction. Comparisons to prior ADC-based ReRAM-CIM designs cite external literature numbers and do not rely on self-citation chains or uniqueness theorems imported from the authors' prior work. No mathematical derivation chain exists that could be circular; the central claims rest on circuit-level simulation/measurement and standard neural-network accuracy evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption ReRAM bitcell supports reliable AND-based in-memory multiplication under PVT and variability conditions
Reference graph
Works this paper leans on
-
[1]
Flex-PE: Flexible and SIMD Multiprecision Processing Element for AI Workloads,
M. Lokhande, G. Raut, and S. K. Vishvakarma, “Flex-PE: Flexible and SIMD Multiprecision Processing Element for AI Workloads,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 33, no. 6, pp. 1610–1623, 2025
work page 2025
-
[2]
A computing-in-memory macro based on three-dimensional resistive random-access memory,
Q. Huo, Y . Yang, Y . Wang, D. Lei, X. Fu, Q. Ren, X. Xu, Q. Luo, G. Xing, C. Chen,et al., “A computing-in-memory macro based on three-dimensional resistive random-access memory,”Nature Electronics, vol. 5, no. 7, pp. 469–477, 2022
work page 2022
-
[3]
ARIES: ADC-Less 3T1R-based nvCIM macro for Edge AI applica- tions,
A. K. Tenwar, R. Sharma, M. Lokhande, and S. K. Vishvakarma, “ARIES: ADC-Less 3T1R-based nvCIM macro for Edge AI applica- tions,” in29th International Symposium on VLSI Design and Test, pp. 1– 6, July 2025
work page 2025
-
[4]
A NOR8T SRAM Digital Compute-in-memory Macro for Sparse and Scalable edge-AI Processing,
P. Sharma, M. Lokhande, A. Sankhe, K. T. Chui, B. B. Gupta, and S. K. Vishvakarma, “A NOR8T SRAM Digital Compute-in-memory Macro for Sparse and Scalable edge-AI Processing,” in21st IEEE Asia Pacific Conference on Circuits and System, pp. 1–5, July 2025
work page 2025
-
[5]
Memristive tonotopic mapping with volatile resistive switching memory devices,
A. Milozzi, S. Ricci, and D. Ielmini, “Memristive tonotopic mapping with volatile resistive switching memory devices,”Nature Communica- tions, vol. 15, no. 1, p. 2812, 2024
work page 2024
-
[6]
M. Lokhande, A. Sankhe, and S. K. Vishvakarma, “REFLEX-PIM: A Resource-Efficient and Flexible Trans-Precision Digital Processing-in- Memory SRAM Macro for AI Workloads,” in2025 IEEE 7th Interna- tional Conference on Emerging Electronics (ICEE), pp. 1–4, 2025
work page 2025
-
[8]
H. Kim, T. Yoo, T. T.-H. Kim, and B. Kim, “Colonnade: A re- configurable SRAM-based digital bit-serial compute-in-memory macro for processing neural networks,”IEEE Journal of Solid-State Circuits, vol. 56, no. 7, pp. 2221–2233, 2021
work page 2021
-
[9]
FERMI-ML: A Flexible and Resource-Efficient Memory-In- Situ SRAM Macro for TinyML Acceleration,
M. Lokhande, A. Sankhe, S. V . J. Chand, S. Mishra, and S. K. Vish- vakarma, “FERMI-ML: A Flexible and Resource-Efficient Memory-In- Situ SRAM Macro for TinyML Acceleration,” in2025 37th International Conference on Microelectronics (ICM), pp. 1–6, 2025
work page 2025
-
[10]
V . Sharma, H. Kim, and T. T.-H. Kim, “A 64 kb reconfigurable full-precision digital ReRAM-based compute-in-memory for artificial intelligence applications,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 69, no. 8, pp. 3284–3296, 2022
work page 2022
-
[11]
L. Wang, W. Ye, C. Dou, X. Si, X. Xu, J. Liu, D. Shang, J. Gao, F. Zhang, Y . Liu,et al., “Efficient and robust nonvolatile computing-in- memory based on voltage division in 2T2R RRAM with input-dependent sensing control,”IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 68, no. 5, pp. 1640–1644, 2021
work page 2021
-
[12]
M. Ezzadeen, A. Majumdar, M. Bocquet, B. Giraud,et al., “Low- overhead implementation of binarized neural networks employing robust 2t2r resistive ram bridges,” inIEEE 47th European Solid State Circuits Conference (ESSCIRC), pp. 83–86, IEEE, 2021
work page 2021
-
[13]
P. K. Saragada, S. Manna, A. Singh, and B. P. Das, “A configurable 10T SRAM-based IMC accelerator with scaled-voltage-based pulse count modulation for MAC and high-throughput XAC,”IEEE Transactions on Nanotechnology, vol. 22, pp. 222–227, 2023
work page 2023
-
[14]
H. Fujiwara, H. Mori, W.-C. Zhao,et al., “A 5-nm 254-TOPS/W 221-TOPS/mm2 Fully-Digital Computing-in-Memory Macro Support- ing Wide-Range Dynamic-V oltage-Frequency Scaling and Simultaneous MAC and Write Operations,” inIEEE International Solid-State Circuits Conference (ISSCC), vol. 65, pp. 1–3, 2022
work page 2022
-
[15]
P. Tyagi and S. Mittal, “A 101 TOPS/W and 1.73 TOPS/mm 2 6T SRAM-Based Digital Compute-in-Memory Macro Featuring a Novel 2T Multiplier,” inDesign, Automation & Test in Europe Conference (DATE), pp. 1–7, 2025
work page 2025
-
[16]
Compute-in-memory chips for deep learning: Recent trends and prospects,
S. Yu, H. Jiang, S. Huang, X. Peng, and A. Lu, “Compute-in-memory chips for deep learning: Recent trends and prospects,”IEEE circuits and systems magazine, vol. 21, no. 3, pp. 31–56, 2021
work page 2021
-
[17]
C. Zhao, L. Lun, Z. Dai,et al., “A Reconfigurable Digital Compute-In- Memory Heterogeneous Macro for Differential Frame Convolution and Spiking Neural Network,” inIEEE International Symposium on Circuits and Systems (ISCAS), pp. 1–5, 2025
work page 2025
-
[18]
A 9T4R RRAM-Based ACAM for Analogue Template Matching at the Edge,
G. Papandroulidakis, S. Agwa, A. Cirakoglu, and T. Prodromakis, “A 9T4R RRAM-Based ACAM for Analogue Template Matching at the Edge,”IEEE Transactions on Circuits and Systems I: Regular Papers, pp. 1–14, 2025
work page 2025
-
[19]
ReRAM device and circuit co-design challenges in nano-scale CMOS technology,
L. Lu, J. E. Kim, V . Sharma, and T. T.-H. Kim, “ReRAM device and circuit co-design challenges in nano-scale CMOS technology,” in 2020 IEEE Asia Pacific Conference on Circuits and Systems (APCCAS), pp. 213–216, IEEE, 2020
work page 2020
-
[20]
Reconfigurable 2T2R ReRAM architecture for versatile data storage and computing in- memory,
Y . Chen, L. Lu, B. Kim, and T. T.-H. Kim, “Reconfigurable 2T2R ReRAM architecture for versatile data storage and computing in- memory,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 28, no. 12, pp. 2636–2649, 2020
work page 2020
-
[21]
C. Bengel, A. Siemon, F. C ¨uppers, S. Hoffmann-Eifert,et al., “Variability-aware modeling of filamentary oxide-based bipolar resistive switching cells using SPICE level compact models,”IEEE Trans. on Cir. and Syst. I: Regular Papers, vol. 67, no. 12, pp. 4618–4630, 2020
work page 2020
-
[22]
M.-F. Chang, C.-C. Lin, A. Lee, Y .-N. Chiang,et al., “A 3T1R nonvolatile TCAM using MLC ReRAM for frequent-off instant-on filters in IoT and big-data processing,”IEEE Journal of Solid-State Circuits, vol. 52, no. 6, pp. 1664–1679, 2017
work page 2017
-
[23]
V . Sharma, X. Zhang, N. S. Dhakad, and T. T.-H. Kim, “FlexDCIM: A 400 MHz 249.1 TOPS/W 64 Kb Flexible Digital Compute-in-Memory SRAM Macro for CNN Acceleration,”IEEE Transactions on Circuits and Systems I: Regular Papers, pp. 1–12, 2025
work page 2025
-
[24]
Area- Optimized 2D Interleaved Adder Tree Design for Sparse DCIM Edge Processing,
A. Sankhe, M. Lokhande, R. Sharma, and S. K. Vishvakarma, “Area- Optimized 2D Interleaved Adder Tree Design for Sparse DCIM Edge Processing,” in26th International Symposium on Quality Electronic Design (ISQED), vol. 26, pp. 1–6, Dec. 2025
work page 2025
-
[25]
Single Exact Single Approximate Adders and Single Exact Dual Approximate Adders,
C. K. Jha, A. Nandi, and J. Mekie, “Single Exact Single Approximate Adders and Single Exact Dual Approximate Adders,”IEEE Trans. on Very Large Scale Integr. (VLSI) Syst., vol. 31, no. 7, pp. 907–916, 2023
work page 2023
-
[26]
An 8T SRAM Based Digital Compute-In-Memory Macro For Multiply-And-Accumulate Ac- celeration,
Z. Wang, H. Luo, Z. Peng, X. Chao, and Y . He, “An 8T SRAM Based Digital Compute-In-Memory Macro For Multiply-And-Accumulate Ac- celeration,” inISCAS, pp. 1–5, 2023
work page 2023
-
[27]
HOAA: Hybrid Overestimating Approximate Adder for Enhanced Performance Processing Engine,
O. Kokane, P. Sati, M. Lokhande, and S. K. Vishvakarma, “HOAA: Hybrid Overestimating Approximate Adder for Enhanced Performance Processing Engine,” in28th International Symposium on VLSI Design and Test (VDAT), pp. 1–6, 2024
work page 2024
-
[28]
Systematic Design of an Approximate Adder: The Optimized Lower Part Constant-OR Adder,
A. Dalloo, A. Najafi, and A. Garcia-Ortiz, “Systematic Design of an Approximate Adder: The Optimized Lower Part Constant-OR Adder,” IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 26, no. 8, pp. 1595–1599, 2018
work page 2018
-
[29]
V . Sharma, H. Kim, and T. T.-H. Kim, “A 64 Kb Reconfigurable Full-Precision Digital ReRAM-Based Compute-In-Memory for Artificial Intelligence Applications,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 69, no. 8, pp. 3284–3296, 2022
work page 2022
-
[30]
W. Yang, S. Zhou, H. Xu, Q. Zhou, J. Li,et al., “An Integration and Time-Sampling based Readout Circuit with Current Compensation for Parallel MAC operations in RRAM Arrays,” inIEEE International Symposium on Circuits and Systems (ISCAS), pp. 1–5, 2024
work page 2024
-
[31]
J. Mu, L. Lu, J. E. Kim, B. An, V . Sharma, A. J. Lekshmi, P. A. Dananjaya, W. H. Lai, W. S. Lew, and T. T.-H. Kim, “A 1-Mb RRAM Macro With 9.8 ns Read Access Time Utilizing Dynamic Reference V oltage for Reliable Sensing Operation,”IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 71, no. 5, pp. 2564–2568, 2024
work page 2024
-
[32]
An ADC-Less RRAM-Based Computing-in-Memory Macro With Binary CNN for Efficient Edge AI,
Y . Li, J. Chen, L. Wang,et al., “An ADC-Less RRAM-Based Computing-in-Memory Macro With Binary CNN for Efficient Edge AI,” IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 70, no. 6, pp. 1871–1875, 2023
work page 2023
-
[33]
L. Wang, W. Ye, C. Dou, X. Si,et al., “Efficient and Robust Nonvolatile Computing-In-Memory Based on V oltage Division in 2T2R RRAM With Input-Dependent Sensing Control,”IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 68, no. 5, pp. 1640–1644, 2021
work page 2021
-
[34]
A Reconfigurable 4T2R ReRAM Computing In-Memory Macro for Efficient Edge Applications,
Y . Chen, L. Lu, B. Kim, and T. T.-H. Kim, “A Reconfigurable 4T2R ReRAM Computing In-Memory Macro for Efficient Edge Applications,” IEEE Open Journal of Circuits and Systems, vol. 2, pp. 210–222, 2021
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.