Conflict-Aware Additive Guidance for Flow Models under Compositional Rewards
Pith reviewed 2026-05-21 05:05 UTC · model grok-4.3
The pith
Conflict-Aware Additive Guidance rectifies off-manifold drift in flow models by resolving gradient conflicts during compositional reward guidance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We identify root causes of this off-manifold drift and find that the approximation error scales severely with gradient misalignment. Building on these findings, we propose Conflict-Aware Additive Guidance (g^car), a lightweight and learnable method, which actively rectifies off-manifold drift by dynamically detecting and resolving gradient conflicts. We validate g^car across diverse domains, ranging from synthetic datasets and image editing to generative decision-making for planning and control.
What carries the argument
Conflict-Aware Additive Guidance (g^car), which dynamically detects and resolves gradient conflicts to prevent off-manifold drift while composing multiple external constraints or rewards.
Load-bearing premise
The root cause of off-manifold drift is approximation error that scales severely with gradient misalignment, which the method assumes can be actively detected and resolved through a learnable adjustment.
What would settle it
Run the guidance procedure on a multi-reward task while disabling the conflict-detection component and measure whether manifold deviation increases in proportion to observed gradient misalignment.
Figures



















read the original abstract
Inference-time guided sampling steers state-of-the-art diffusion and flow models without fine-tuning by interpreting the generation process as a controllable trajectory. This provides a simple and flexible way to inject external constraints (e.g., cost functions or pre-trained verifiers) for controlled generation. However, existing methods often fail when composing multiple constraints simultaneously, which leads to deviations from the true data manifold. In this work, we identify root causes of this off-manifold drift and find that the approximation error scales severely with gradient misalignment. Building on these findings, we propose Conflict-Aware Additive Guidance ($g^\text{car}$), a lightweight and learnable method, which actively rectifies off-manifold drift by dynamically detecting and resolving gradient conflicts. We validate $g^\text{car}$ across diverse domains, ranging from synthetic datasets and image editing to generative decision-making for planning and control. Our results demonstrate that $g^\text{car}$ effectively rectifies off-manifold drift, surpassing baselines in generation fidelity while using light compute. Code is available at https://github.com/yuxuehui/CAR-guidance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that off-manifold drift in compositional guided sampling for flow models arises because approximation error scales severely with gradient misalignment between constraints. It introduces Conflict-Aware Additive Guidance (g^car), a lightweight learnable rectification that dynamically detects and resolves these conflicts, and reports improved generation fidelity over baselines on synthetic data, image editing, and planning/control tasks while using light compute.
Significance. If the scaling relationship is confirmed and g^car rectifies drift without new instabilities, the approach could offer a practical, training-free way to compose constraints in diffusion and flow models. The cross-domain validation and public code release strengthen reproducibility and potential impact for controlled generation.
major comments (1)
- [Abstract] Abstract: the central claim that 'the approximation error scales severely with gradient misalignment' is presented as the identified root cause and the direct motivation for g^car, yet no derivation, error bound (e.g., in terms of angle between guidance vectors or Lipschitz constants of the rewards), quantitative analysis, or experimental controls are supplied to support the scaling. This leaves open whether pairwise conflict resolution is the appropriate fix or whether other factors dominate drift.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We appreciate the acknowledgment of the potential practical impact of our method for compositional guidance in flow models, as well as the positive comments on cross-domain validation and code release. We address the major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'the approximation error scales severely with gradient misalignment' is presented as the identified root cause and the direct motivation for g^car, yet no derivation, error bound (e.g., in terms of angle between guidance vectors or Lipschitz constants of the rewards), quantitative analysis, or experimental controls are supplied to support the scaling. This leaves open whether pairwise conflict resolution is the appropriate fix or whether other factors dominate drift.
Authors: We agree with the referee that the abstract states this scaling relationship as a central finding without accompanying formal support in the current version of the manuscript. Our identification of gradient misalignment as a root cause of off-manifold drift is primarily grounded in the empirical results on synthetic data, where we observed a clear correlation between increasing misalignment (measured via cosine similarity of guidance vectors) and larger deviations from the data manifold. However, we did not include an explicit derivation, error bound, or dedicated experimental controls isolating this factor while holding others fixed. We will revise the manuscript to add a short theoretical subsection deriving a first-order error bound under the assumption of Lipschitz-continuous rewards, showing that the accumulated approximation error grows with (1 - cos θ), where θ is the angle between guidance gradients. We will also insert quantitative plots and ablation controls that vary only the misalignment angle. These changes will better justify the focus on pairwise conflict resolution while noting that higher-order interactions among more than two constraints remain an open direction for future work. revision: yes
Circularity Check
No significant circularity; central proposal is an independent learnable method.
full rationale
The paper identifies off-manifold drift causes via analysis of approximation error scaling with gradient misalignment, then introduces g^car as a new lightweight learnable rectification step that dynamically detects and resolves conflicts. This chain does not reduce by construction to self-defined quantities, fitted inputs renamed as predictions, or load-bearing self-citations. The method is validated empirically across domains rather than derived tautologically from prior results or ansatzes, keeping the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable parameters of g^car
axioms (1)
- domain assumption Approximation error in existing additive guidance scales severely with gradient misalignment.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
approximation error scales severely with gradient misalignment (1−cosϕ) ... gcar(xt,t)=(1−wt)gapprox+wt gψ
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 4.2 (Upper Bound of Approximation Error) ... G(G−1)μ² ∫ E[1−cosϕt(xt)] dt
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URL https://proceedings.mlr.press/ v270/chisari25a.html. Chung, H., Kim, J., McCann, M. T., Klasky, M. L., and Ye, J. C. Diffusion posterior sampling for general noisy in- verse problems. InInternational Conference on Learning Representations, 2023. Domingo-Enrich, C., Drozdzal, M., Karrer, B., and Chen, R. T. Q. Adjoint matching: Fine-tuning flow and dif...
-
[2]
URL https://openreview.net/forum? id=PLIt3a4yTm. Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., and Sutskever, I. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, 2021. R¨omer, R., von Rohr, A., and S...
-
[3]
Springer, 2009. Wallace, B., Dang, M., Rafailov, R., Zhou, L., Lou, A., Purushwalkam, S., Ermon, S., Xiong, C., Joty, S., and Naik, N. Diffusion model alignment using direct pref- erence optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8228–8238, 2024. Wang, J., Chan, K. C., and Loy, C. C. Exploring CL...
-
[4]
rather than through reward maximization.2 As the trajectory approaches the basin of anyx †, it drifts off-manifold. Energy dissipation under gradient misalignment.To characterize the mechanism that drives trajectories off-manifold, we quantify the effective driving force of the compositional guidance via its squared norm. Expanding ∥gt(xt)∥2 at any 2From ...
work page 2020
-
[5]
= inf (pt, vt):p 0 vt − →p⋆ 1 Z 1 0 Ext∼pt ∥vt(xt)∥2 dt= Z 1 0 E ∥vbase t +g ⋆ t ∥2 dt,(29) where g⋆ t is the optimal guidance field that steers mass toward the reward-tilted targetp⋆
-
[6]
The realized field ˆvt =v base t +g approx t therefore only transportsp 0 toˆp1 ̸=p ⋆ 1
Under the two-stage approximation (CIA + Localized Approximation) for compositional rewards R= P j rj, g⋆ t is replaced by the realized guidance gapprox t =P j gapprox j , where each gapprox j =∇ xt rj(ˆx1) with ˆx1 =E[x 1 |x t]. The realized field ˆvt =v base t +g approx t therefore only transportsp 0 toˆp1 ̸=p ⋆ 1. We quantify the resulting approximatio...
-
[7]
using the stability of the continuity equation (Villani et al., 2009), which bounds the terminal distributional discrepancy by the time-integrated squared velocity field difference along the optimal pathp ⋆ t : E≜W 2 2 (ˆp1, p⋆ 1)≤ Z 1 0 Ext∼p⋆ t ∥v⋆ t (xt)−ˆvt(xt)∥2 dt= Z 1 0 Ext∼p⋆ t ∥g⋆ t −g approx t ∥2 dt.(30) Since compositional guided sampling sums ...
work page 2009
-
[8]
By Cauchy–Schwarz: ∥g⋆ t (xt)−g CI t (xt)∥2 2 = Ez∼π CI(·|xt) (P(z)−1)v t|z(xt|z) 2 2 ≤E z∼π CI(·|xt) (P(z)−1) 2 ·E z∼π CI(·|xt) ∥vt|z(xt|z)∥2 2 .(32) Term (A) is small when the coupling shift is negligible (P(z)≈1 ), which holds for flow matching methods with dependent couplings such as mini-batch OT-FM (Tong et al., 2024a), but not for vanilla OT-FM (On...
work page 2021
-
[9]
The error is small when thereward landscape is smooth, i.e., small λh =∥∇ 2er∥2. A flat reward landscape without sharp peaks or valleys implies less aggressive curvature, thereby minimizing the linearization error in Term (C)
-
[10]
This is the case when the flow time t→1 (and σt →0), wherex t reliably predictsx 1
The error is small when σ1 is small, i.e., the conditional covariance Σ1|t has small spectral norm, meaning that at the current state xt the uncertainty about the terminal point x1 is low. This is the case when the flow time t→1 (and σt →0), wherex t reliably predictsx 1
-
[11]
Themagnitude of er(ˆx1) reflects how well the predicted endpoint ˆx1 =E[x 1|xt] matches the reward objective. If ˆx1 lies inside the region where r is large, the approximate guidance is more accurate, as the optimization is conducted locally and the gradient reflects the landscape well. If er(ˆx1) is small, the gradient explores the sample space almost ra...
-
[12]
20 Conflict-Aware Additive Guidance for Flow Models under Compositional Rewards D
The error scales withthe number of reward functionsGandgradient misalignment(1−cosϕ). 20 Conflict-Aware Additive Guidance for Flow Models under Compositional Rewards D. Guided sampling through the lens of fitted value evaluation Unlike diffusion models, Flow models are governed by deterministic ODE processes. By leveraging this deterministic coupling and ...
-
[13]
The dataset is infinite, i.e.,|D|=∞
-
[14]
The Bellman residual minimization is solved exactly at each iteration
-
[15]
The function class F is simple enough to be estimated, e.g., a one-dimensional linear function class fθ(x) =θ ⊤ϕ(x)
-
[16]
The realizability assumption holds, i.e., the true value function satisfiesV∈ F. This phenomenon is commonly referred to as thedeadly triadin empirical deep reinforcement learning, which arises from the interaction of function approximation, off-policy data, and bootstrapping. In the flow matching setting, however, the dynamics are deterministic and rewar...
work page 2021
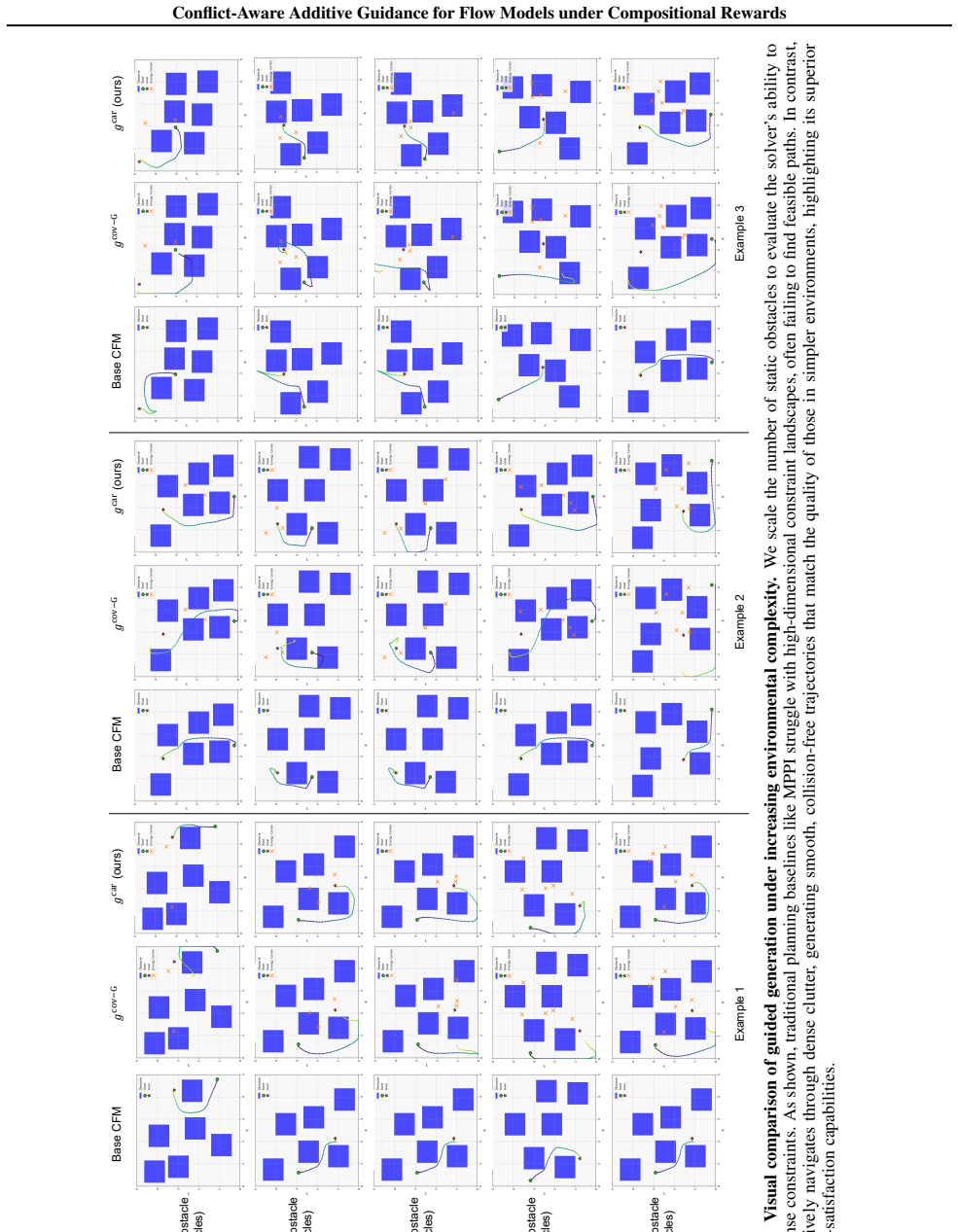
-
[17]
Inference-time guidance applied to pre-trained generative policy models is prone to off-manifold drift, leading to poor prior preservation (e.g., failing to reach the end point) and constraint violations (e.g., colliding with obstacles or maze walls), as shown forg cov-G in Figure 16
-
[19]
GLASS-FKS performs well on robot planning tasks. 4.g car consistently corrects off-manifold drift across all settings, improving success rate and reducing constraint violations
-
[20]
Sometimes, it still suffers from prior preservation issues under compositional constraints
MPPI is a strong planning baseline that refines generated paths from the base CFM model to satisfy runtime constraints. Sometimes, it still suffers from prior preservation issues under compositional constraints. When gcar is applied on top of MPPI, MPPI + gcar achieves the best overall performance, correcting off-manifold drift while satisfying constraint...
-
[21]
Specifically, we incorporate explicit goal conditioning, and improve success rates
for goal-conditioned manipulation. Specifically, we incorporate explicit goal conditioning, and improve success rates. The detailed architecture is illustrated in Figure 18. Conditioning.The policy is conditioned on a multimodal context vectorc, constructed as follows:
-
[22]
These are processed by a PointNet backbone to extract a dense feature vector
Observation: Raw 3D point clouds (N= 4096 ) with RGB features are fused from multi-view cameras (left, right, and gripper). These are processed by a PointNet backbone to extract a dense feature vector
-
[23]
Proprio State: A vector containing the robot’s joint angles and gripper status
-
[24]
These components are concatenated to form the conditioningc
Goal: The 3D coordinates representing the target placement location (e.g., the stacking position). These components are concatenated to form the conditioningc. Output.The model predicts action chunks of horizon T . The generative component is a Conditional 1D U-Net that predicts the time-dependent velocity field vθ(xt, t|c) . Here, the flow state xt ∈R T×...
-
[25]
Adding inference-time guidance to pre-trained generative policy models is prone to OOD, and often fails to finish tasks, e.g., the failure shown in Figure 19 ofg cov-G
-
[26]
PCGrad cannot recover from off-manifold drift
-
[27]
GLASS-FKS generally performs well, but struggles in high-precision tasks such as StackCube (i.e., stably and precisely placing one cube onto another), due to its high transition variance. On tasks such as conditional generation (e.g., decision-making tasks), as long as the condition often appears in the dataset, GLASS-FKS performs well because it is easie...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.