Rethinking Fraud Safety Evaluation: Multi-Round Attacks Reveal Safety-Utility Tradeoffs in Graph-Context LLM Defenders
Pith reviewed 2026-05-21 04:29 UTC · model grok-4.3
The pith
Graph-context LLM defenders refuse fraud earlier in multi-round attacks than text baselines but over-refuse more on benign inputs because they respond mainly to the presence of structured fields.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
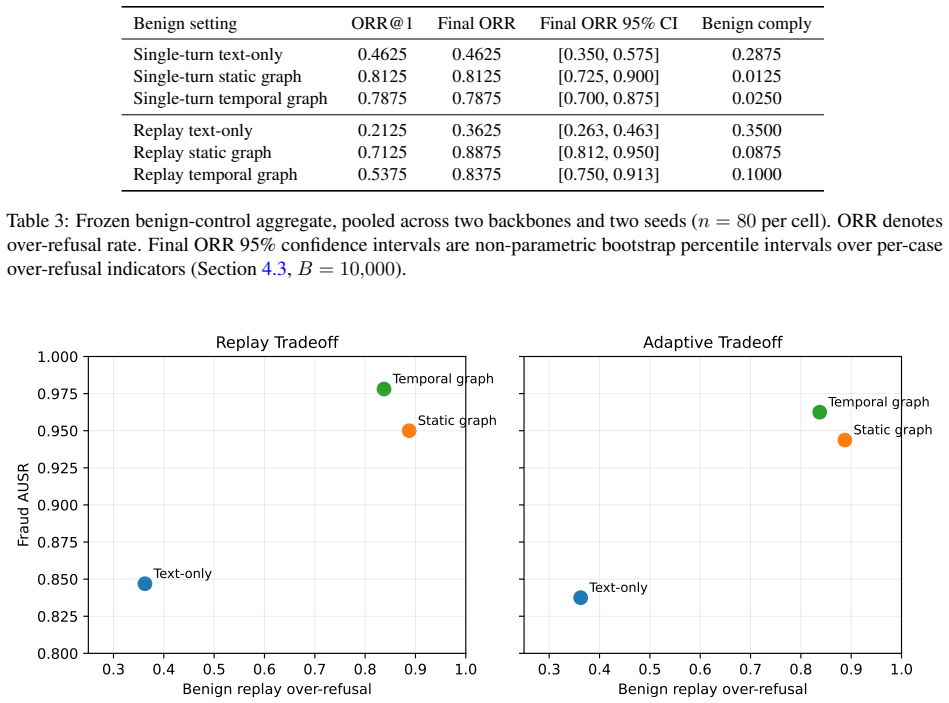
Graph-context defenders improve early safe refusal relative to text-only baselines under both replay and adaptive fraud pressure, but they also produce substantially more benign over-refusal. Direct probing of the trained graph encoder together with paired shuffle-risk ablations localizes this cost to how the defender LLM consumes structured context rather than to graph-encoder quality: the encoder cleanly separates fraud from benign, while the LLM responds primarily to the presence of structured graph fields and only secondarily, and asymmetrically, to risk-score magnitude. Temporal graph context is directionally stronger than static and significantly better grounded, but is not yet clearly
What carries the argument
The paired shuffle-risk ablations that isolate the graph encoder's ability to separate fraud from benign cases from the LLM's primary sensitivity to the mere presence of structured graph fields in its input.
If this is right
- Fraud defender evaluation must shift to multi-round attacks that measure not only whether but when refusals occur.
- Safety gains from added context must be weighed against increases in benign over-refusal.
- Robust assessment requires localizing observed costs to the graph signal itself or to the LLM's consumption of that signal.
- Temporal graph context shows directional advantages in grounding compared with static context on the main metrics.
Where Pith is reading between the lines
- Context-masking or abstraction layers before the LLM input could reduce over-refusal while retaining the encoder's separation benefits.
- Comparable sensitivity to structured fields may appear in other safety or compliance settings that inject external data into LLM decisions.
- Experiments that vary backbone size or add balanced refusal training data could test whether the consumption effect diminishes with scale.
Load-bearing premise
That the frozen multi-round attack suite together with the paired shuffle-risk ablations sufficiently isolates the source of over-refusal to how the LLM consumes graph fields rather than to other unmeasured factors in the evaluation setup.
What would settle it
An experiment that supplies risk scores to the LLM while entirely removing the structured graph fields from its input would show whether benign over-refusal rates fall back toward baseline levels.
Figures


read the original abstract
Single-turn safety evaluation is a poor proxy for real fraud defense, where attackers escalate across multiple rounds. This paper evaluates fraud defenders under replay and adaptive multi-round attacks and measures when a defender refuses, not just whether it eventually refuses. On a frozen multi-round suite built from Fraud-R1, graph-context defenders improve early safe refusal relative to text-only baselines under both replay and adaptive fraud pressure, but they also produce substantially more benign over-refusal. Direct probing of the trained graph encoder, together with paired shuffle-risk ablations on both fraud and benign sides replicated across two seeds on the Qwen-1.5B backbone, localises this cost to how the defender LLM consumes structured context rather than to graph-encoder quality: the encoder cleanly separates fraud from benign, while the LLM responds primarily to the presence of structured graph fields and only secondarily, and asymmetrically, to risk-score magnitude. Temporal graph context is directionally stronger than static and significantly better grounded, but is not yet conclusively superior on the main refusal metrics. The contribution is evaluative and measurement-oriented: robust fraud assessment must be multi-round, must report refusal timing, must account for benign false positives alongside fraud-side safety gains, and must localize observed costs to the graph signal or to how the LLM consumes it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that single-turn safety evaluations inadequately capture real-world fraud defense, where attacks unfold over multiple rounds. On a frozen multi-round suite derived from Fraud-R1, graph-context defenders improve early safe refusal relative to text-only baselines under both replay and adaptive pressure, yet they incur substantially higher benign over-refusal. Direct encoder probing combined with paired shuffle-risk ablations (replicated across two seeds on the Qwen-1.5B backbone) localizes this cost to the defender LLM's consumption of structured graph fields rather than to graph-encoder quality; the encoder separates fraud from benign cleanly, while the LLM reacts primarily to the presence of graph structure and only secondarily to risk-score magnitude. Temporal graph context is directionally stronger than static but not yet conclusively superior on refusal metrics.
Significance. If the localization holds, the work demonstrates that robust fraud assessment requires multi-round protocols that jointly measure refusal timing, fraud-side gains, and benign false-positive costs. The evaluative contribution—frozen suite, ablations across seeds, and explicit separation of encoder quality from LLM context consumption—provides a concrete template for dissecting safety-utility tradeoffs in graph-augmented LLM systems and could guide targeted mitigation of over-refusal.
major comments (1)
- [§5.2] §5.2 (Shuffle-risk ablations): The central localization—that over-refusal stems from the LLM reacting to structured graph fields rather than encoder quality—rests on these paired ablations. However, shuffling risk scores or fields necessarily alters serialized input format, token count, and embedding positions. Without an explicit control that preserves exact token length, field ordering, and formatting while removing semantic graph structure (e.g., length-matched dummy delimiters), the observed increase in over-refusal may be driven by surface-level input changes rather than interpretation of graph context per se.
minor comments (2)
- [Table 2] Table 2 and Figure 4: Error bars or standard deviations across the two seeds are not reported for the over-refusal rates; adding them would clarify whether the reported differences are stable.
- [§3.1] §3.1: The description of how the frozen multi-round suite is constructed from Fraud-R1 would benefit from an explicit statement of the number of rounds and the exact criteria used to terminate each trajectory.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the shuffle-risk ablations. We address the concern directly below and indicate the planned revision.
read point-by-point responses
-
Referee: [§5.2] §5.2 (Shuffle-risk ablations): The central localization—that over-refusal stems from the LLM reacting to structured graph fields rather than encoder quality—rests on these paired ablations. However, shuffling risk scores or fields necessarily alters serialized input format, token count, and embedding positions. Without an explicit control that preserves exact token length, field ordering, and formatting while removing semantic graph structure (e.g., length-matched dummy delimiters), the observed increase in over-refusal may be driven by surface-level input changes rather than interpretation of graph context per se.
Authors: We acknowledge that shuffling risk scores or fields can change token counts, serialization format, and embedding positions, which introduces a potential surface-level confound. Our existing paired ablations keep field ordering and names fixed while only permuting risk values (or vice versa), and we compare against text-only baselines that use no graph serialization at all; the encoder-probing results further show clean fraud/benign separation before any LLM input formatting occurs. Nevertheless, the referee’s suggestion for a stricter control is well-taken. In the revised manuscript we will add an explicit length-matched dummy-delimiter condition that preserves exact token length, field ordering, and formatting while stripping semantic graph content. This will allow us to isolate the contribution of structured graph interpretation more cleanly. revision: yes
Circularity Check
No significant circularity: results are empirical measurements against external benchmarks
full rationale
The paper presents an evaluative, measurement-oriented study that relies on the external Fraud-R1 suite, direct encoder probing, and shuffle-risk ablations replicated across seeds on the Qwen-1.5B backbone. No derivation chain, equations, or first-principles claims reduce to self-defined quantities, fitted parameters renamed as predictions, or load-bearing self-citations. The localization of over-refusal costs to LLM consumption of structured context is an empirical finding supported by independent ablations rather than a tautological reduction by construction. The work is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Language Models are Few-Shot Learners,
T. B. Brownet al., “Language Models are Few-Shot Learners,”Advances in Neural Information Processing Systems, vol. 33, pp. 1877–1901, 2020
work page 1901
-
[2]
Training Language Models to Follow Instructions with Human Feedback,
L. Ouyanget al., “Training Language Models to Follow Instructions with Human Feedback,”Advances in Neural Information Processing Systems, vol. 35, pp. 27730–27744, 2022. 17
work page 2022
-
[3]
Graph Neural Networks for Financial Fraud Detection: A Review,
D. Cheng, Y . Zou, S. Xiang, and C. Jiang, “Graph Neural Networks for Financial Fraud Detection: A Review,” Frontiers of Computer Science, vol. 19, no. 9, p. 199609, 2025
work page 2025
-
[4]
A Comprehensive Survey on Graph Neural Networks,
Z. Wu, S. Pan, F. Chen, G. Long, C. Zhang, and P. S. Yu, “A Comprehensive Survey on Graph Neural Networks,” IEEE Transactions on Neural Networks and Learning Systems, vol. 32, no. 1, pp. 4–24, 2021
work page 2021
-
[5]
Survey on Graph Neural Networks,
G. Gkarmpounis, C. Vranis, N. Vretos, and P. Daras, “Survey on Graph Neural Networks,”IEEE Access, vol. 12, pp. 128816–128832, 2024
work page 2024
-
[6]
Pick and Choose: A GNN-based Imbalanced Learning Approach for Fraud Detection,
K. Liuet al., “Pick and Choose: A GNN-based Imbalanced Learning Approach for Fraud Detection,”Proceedings of the Web Conference 2021, pp. 3168–3177, 2021
work page 2021
-
[7]
D. Saldaña-Ulloa, G. De Ita Luna, and J. R. Marcial-Romero, “A Temporal Graph Network Algorithm for Detecting Fraudulent Transactions on Online Payment Platforms,”Algorithms, vol. 17, no. 12, p. 552, 2024
work page 2024
-
[8]
Temporal Graph Networks for Graph Anomaly Detection in Financial Data,
K. Shah and L. Kumar, “Temporal Graph Networks for Graph Anomaly Detection in Financial Data,”arXiv preprint arXiv:2407.20156, 2024
-
[9]
CaT-GNN: Enhancing Credit Card Fraud Detection via Causal Temporal Graph Neural Networks,
Y . Duanet al., “CaT-GNN: Enhancing Credit Card Fraud Detection via Causal Temporal Graph Neural Networks,” arXiv preprint arXiv:2402.14708, 2024
-
[10]
Temporal Graph Networks for Deep Learning on Dynamic Graphs
E. Rossi, B. Chamberlain, F. Frasca, D. Eynard, F. Monti, and M. Bronstein, “Temporal Graph Networks for Deep Learning on Dynamic Graphs,”arXiv preprint arXiv:2006.10637, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[11]
Inductive Representation Learning on Temporal Graphs,
D. Xu, C. Ruan, E. Korpeoglu, S. Kumar, and K. Achan, “Inductive Representation Learning on Temporal Graphs,” International Conference on Learning Representations, 2020
work page 2020
-
[12]
DetoxBench: Benchmarking Large Language Models for Multitask Fraud & Abuse Detection,
J. Chakrabortyet al., “DetoxBench: Benchmarking Large Language Models for Multitask Fraud & Abuse Detection,”arXiv preprint arXiv:2409.06072, 2024
-
[13]
S. Yanget al., “Fraud-R1: A Multi-Round Benchmark for Assessing the Robustness of LLM Against Augmented Fraud and Phishing Inducements,”arXiv preprint arXiv:2502.12904, 2025
-
[14]
Attacks, defenses and evaluations for llm conversation safety: A survey
Z. Dong, Z. Zhou, C. Yang, J. Shao, and Y . Qiao, “Attacks, Defenses and Evaluations for LLM Conversation Safety: A Survey,”arXiv preprint arXiv:2402.09283, 2024
-
[15]
Large language model safety: A holistic survey,
D. Shiet al., “Large Language Model Safety: A Holistic Survey,”arXiv preprint arXiv:2412.17686, 2024
-
[16]
A Survey on Large Language Model Security and Privacy: The Good, The Bad, and The Ugly,
Y . Yao, J. Duan, K. Xu, Y . Cai, Z. Sun, and Y . Zhang, “A Survey on Large Language Model Security and Privacy: The Good, The Bad, and The Ugly,”High-Confidence Computing, vol. 4, no. 2, p. 100211, 2024
work page 2024
-
[17]
Jailbroken: How Does LLM Safety Training Fail?
A. Wei, N. Haghtalab, and J. Steinhardt, “Jailbroken: How Does LLM Safety Training Fail?”Advances in Neural Information Processing Systems, vol. 36, 2023
work page 2023
-
[18]
Universal and Transferable Adversarial Attacks on Aligned Language Models
A. Zou, Z. Wang, J. Z. Kolter, and M. Fredrikson, “Universal and Transferable Adversarial Attacks on Aligned Language Models,”arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Constitutional AI: Harmlessness from AI Feedback
Y . Baiet al., “Constitutional AI: Harmlessness from AI Feedback,”arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
TrustLLM: Trustworthiness in Large Language Models,
L. Sunet al., “TrustLLM: Trustworthiness in Large Language Models,”Proceedings of the 41st International Conference on Machine Learning, 2024
work page 2024
-
[21]
DecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT Models,
B. Wanget al., “DecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT Models,”Advances in Neural Information Processing Systems, vol. 36, 2023
work page 2023
-
[22]
Ignore Previous Prompt: Attack Techniques For Language Models
F. Perez and I. Ribeiro, “Ignore Previous Prompt: Attack Techniques For Language Models,”arXiv preprint arXiv:2211.09527, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
K. Greshakeet al., “Not What You’ve Signed Up For: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection,”arXiv preprint arXiv:2302.12173, 2023. 18
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Semi-Supervised Classification with Graph Convolutional Networks,
T. N. Kipf and M. Welling, “Semi-Supervised Classification with Graph Convolutional Networks,”International Conference on Learning Representations, 2017
work page 2017
-
[25]
P. Veliˇckovi´c, G. Cucurull, A. Casanova, A. Romero, P. Liò, and Y . Bengio, “Graph Attention Networks,” International Conference on Learning Representations, 2018
work page 2018
-
[26]
Inductive Representation Learning on Large Graphs
W. L. Hamilton, R. Ying, and J. Leskovec, “Inductive Representation Learning on Large Graphs,”arXiv preprint arXiv:1706.02216, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
F. Xiaet al., “Graph Learning: A Survey,”IEEE Transactions on Artificial Intelligence, vol. 2, no. 2, pp. 109–127, 2021
work page 2021
-
[28]
A Survey of Large Language Models for Graphs,
S. Panet al., “A Survey of Large Language Models for Graphs,”arXiv preprint arXiv:2410.00130, 2024
-
[29]
N. Ibrahim, S. Aboulela, A. Ibrahim, and R. Kashef, “A Survey on Augmenting Knowledge Graphs with Large Language Models: Methods, Challenges, and Future Directions,”Discover Artificial Intelligence, vol. 5, no. 1, p. 134, 2024
work page 2024
-
[30]
LLM-Based Multi-Hop Question Answering with Knowledge Graph Integration in Evolving Environments,
J. N. Panda, B. Dash, D. Sahu, and B. P. Biswal, “LLM-Based Multi-Hop Question Answering with Knowledge Graph Integration in Evolving Environments,”arXiv preprint arXiv:2408.15903, 2024
-
[31]
CNFinBench: A Chinese Financial Safety Benchmark for Large Language Models,
Y . Dinget al., “CNFinBench: A Chinese Financial Safety Benchmark for Large Language Models,”arXiv preprint arXiv:2512.09506, 2025
-
[32]
SafeDialBench: A Fine-Grained Safety Benchmark for Large Language Models in Multi-Turn Dialogues,
X. Caoet al., “SafeDialBench: A Fine-Grained Safety Benchmark for Large Language Models in Multi-Turn Dialogues,”arXiv preprint arXiv:2502.11090, 2025
-
[33]
FinSafetyBench: Evaluating LLM Safety in Real-World Financial Scenarios
J. Houet al., “FinSafetyBench: Evaluating LLM Safety in Real-World Financial Scenarios,”arXiv preprint arXiv:2605.00706, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvronet al., “Llama 2: Open Foundation and Fine-Tuned Chat Models,”arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena,
L. Zhenget al., “Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena,”Advances in Neural Information Processing Systems, vol. 36, 2023. 19
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.