SpineContextResUNet: A Computationally Efficient Residual UNet for Spine CT Segmentation
Pith reviewed 2026-05-21 05:58 UTC · model grok-4.3
The pith
A residual U-Net with parallel multi-dilated convolutions segments the spine in CT scans while running on commodity hardware where transformers and large ensembles fail.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
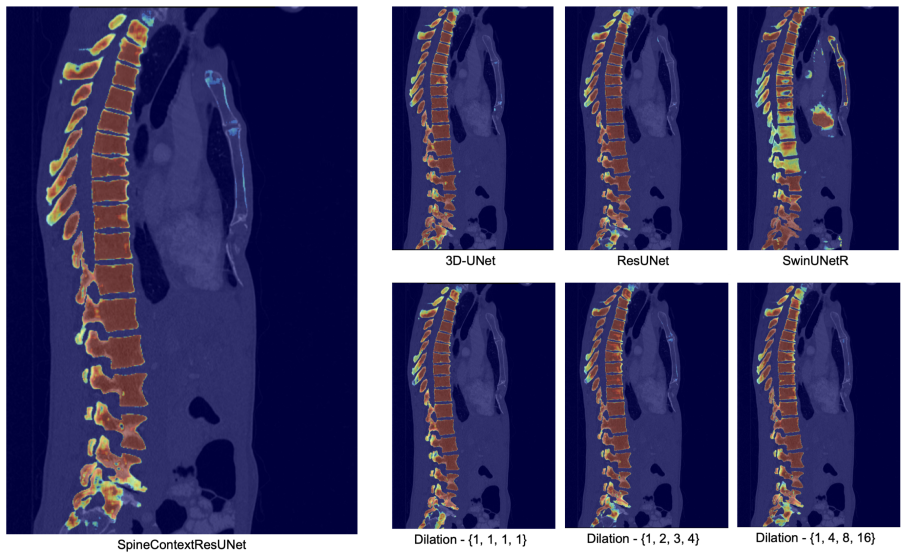
SpineContextResUNet integrates a lightweight Context Block that employs parallel multi-dilated convolutions into a 3D Residual U-Net to capture long-range anatomical dependencies without RNN latency or self-attention memory overhead. The resulting model achieves Dice scores of 88.17 percent on VerSe2020 and 88.13 percent on CTSpine1K while supporting inference on commodity hardware where a constrained SwinUNETR degrades and TotalSegmentator fails due to memory exhaustion.
What carries the argument
The lightweight Context Block that runs parallel multi-dilated convolutions to gather long-range spatial context inside the residual U-Net.
If this is right
- The model reaches Dice scores above 88 percent on two public spine CT benchmarks while using only about 1.7 million parameters.
- Inference succeeds on an Intel Core i5 processor with 8 GB RAM and on the Nvidia Jetson Orin Nano.
- A size-matched transformer loses accuracy in the same limited-data setting because it lacks spatial inductive biases.
- Heavy ensemble baselines cannot load into memory on the same commodity hardware.
Where Pith is reading between the lines
- The same block design could be inserted into other 3D segmentation networks that need distant context but must stay small.
- Further parameter reduction might allow real-time spine segmentation directly on portable ultrasound or X-ray devices.
- Testing generalization across scanner vendors would clarify how much the dilated-convolution context compensates for limited training data.
Load-bearing premise
The parallel multi-dilated convolutions supply enough long-range anatomical context to keep segmentation accuracy high without attention mechanisms or greater network capacity.
What would settle it
A large drop in Dice score on CT scans from unseen scanners or patient cohorts would show that the context block does not supply adequate long-range dependencies.
Figures


read the original abstract
Automated segmentation of the vertebral column in Computed Tomography (CT) scans is a prerequisite for pathological assessment and surgical planning. However, state-of-the-art methods, particularly those based on Transformers or large-scale ensembles, demand substantial GPU resources, creating a barrier for clinical adoption in resource-constrained environments or on edge devices. To address this, we introduce SpineContextResUNet, a computationally efficient 3D Residual U-Net designed for rapid spinal localization. Our architecture integrates a lightweight Context Block that employs parallel multi-dilated convolutions to capture long-range anatomical dependencies without the high latency of Recurrent Neural Networks (RNNs) or the memory overhead of Self-Attention mechanisms. Extensive validation on two public benchmarks, VerSe2020 and CTSpine1K, demonstrates that our model achieves a Dice score of 88.17% and 88.13% respectively. To evaluate performance under strict hardware constraints, we compared our model against a bottlenecked SwinUNETR scaled to match our ~1.7M hardware footprint. While the constrained Transformer suffers severe performance degradation due to a lack of spatial inductive biases in a limited-data regime, our CNN-based approach successfully maintains high accuracy. Crucially, heavy baselines like TotalSegmentator fail due to memory exhaustion on commodity hardware (Intel Core i5, 8GB RAM), our model performs robust inference, making it a viable solution for point-of-care diagnostics and deployment on edge platforms like the Nvidia Jetson Orin Nano.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SpineContextResUNet, a computationally efficient 3D Residual U-Net for vertebral column segmentation in CT scans. It integrates a lightweight Context Block with parallel multi-dilated convolutions to capture long-range dependencies without RNN latency or self-attention memory overhead. The central claims are Dice scores of 88.17% on VerSe2020 and 88.13% on CTSpine1K, plus robust inference on commodity hardware (Intel Core i5, 8GB RAM) where TotalSegmentator fails due to memory exhaustion and a parameter-matched SwinUNETR degrades severely due to missing spatial inductive biases in limited-data regimes.
Significance. If the empirical results and baseline comparison hold after clarification, the work offers a practical, low-footprint (~1.7M parameters) CNN alternative for spine segmentation that could enable deployment on edge devices and resource-constrained clinical environments. The focus on inductive biases versus attention mechanisms in limited-data medical imaging is timely and could inform efficient architecture design.
major comments (2)
- [Experiments] Experiments section (and abstract): The scaling procedure for the 'bottlenecked SwinUNETR scaled to match our ~1.7M hardware footprint' is unspecified. No details are given on whether this involved uniform channel reduction, layer pruning, or other modifications, nor is there an ablation confirming that performance degradation arises from absent spatial inductive biases rather than reduced capacity alone. This directly undercuts the load-bearing contrast drawn between the Context Block and the constrained Transformer.
- [Methods/Experiments] Methods and Experiments sections: Training protocol details (data splits, augmentations, optimizer, loss, epochs, and any statistical tests or confidence intervals on the reported Dice scores) are absent. Without these, the concrete performance numbers cannot be reproduced or verified, weakening the central empirical claims.
minor comments (2)
- [Abstract/Experiments] The abstract and text refer to 'heavy baselines like TotalSegmentator' failing on 8GB RAM; clarify the exact memory footprint measured and whether any optimization (e.g., mixed precision) was attempted for fairness.
- [Architecture] Notation for the Context Block (parallel multi-dilated convolutions) should include a diagram or explicit equation showing dilation rates and fusion to improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper accordingly to improve clarity and reproducibility.
read point-by-point responses
-
Referee: [Experiments] Experiments section (and abstract): The scaling procedure for the 'bottlenecked SwinUNETR scaled to match our ~1.7M hardware footprint' is unspecified. No details are given on whether this involved uniform channel reduction, layer pruning, or other modifications, nor is there an ablation confirming that performance degradation arises from absent spatial inductive biases rather than reduced capacity alone. This directly undercuts the load-bearing contrast drawn between the Context Block and the constrained Transformer.
Authors: We acknowledge the need for greater detail on the SwinUNETR scaling. The procedure involved uniform reduction of channel dimensions across all layers to reach approximately 1.7M parameters while preserving the overall architecture. This ensures a direct comparison under identical hardware constraints. We attribute the observed degradation to the lack of spatial inductive biases in the limited-data regime, as our CNN model with the Context Block maintains performance. In the revision we will explicitly describe the scaling method and add a brief discussion or supporting analysis to separate capacity effects from inductive bias effects. revision: yes
-
Referee: [Methods/Experiments] Methods and Experiments sections: Training protocol details (data splits, augmentations, optimizer, loss, epochs, and any statistical tests or confidence intervals on the reported Dice scores) are absent. Without these, the concrete performance numbers cannot be reproduced or verified, weakening the central empirical claims.
Authors: We agree that these implementation details were omitted from the original submission. The revised manuscript will include the exact data splits, augmentation pipeline, optimizer settings, loss function, training epochs, and any statistical tests or confidence intervals associated with the Dice scores to support full reproducibility. revision: yes
Circularity Check
No circularity: empirical validation on independent benchmarks
full rationale
The paper proposes a new CNN architecture (SpineContextResUNet with Context Block) motivated by efficiency needs and evaluates it via standard Dice scores on external public datasets (VerSe2020, CTSpine1K). No derivation chain exists that reduces predictions or uniqueness claims to self-referential fits, self-citations, or definitional loops; architectural choices and performance claims are independent of the reported metrics and rest on reproducible benchmark comparisons rather than tautological constructions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Parallel multi-dilated convolutions capture long-range anatomical dependencies without RNN latency or attention memory cost
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.lean (LogicNat orbit and 8-tick periodicity); Cost/FunctionalEquation.lean (J-cost uniqueness)reality_from_one_distinction; washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our architecture integrates a lightweight Context Block that employs parallel multi-dilated convolutions... four parallel branches, each employing a 3×3×3 convolution with a different dilation rate r∈{1,2,4,8}
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Yufan He, Vishwesh Nath, Dong Yang, Yucheng Tang, Andriy Myronenko, and Daguang Xu. Swinunetr-v2: Stronger swin transformers with stagewise convolutions for 3d med- 8 ical image segmentation. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 416–426. Springer, 2023
work page 2023
-
[2]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2021
work page 2021
-
[3]
nnu-net: a self-configuring method for deep learning-based biomedical image segmentation
Fabian Isensee, Paul F Jaeger, Simon AA Kohl, Jens Petersen, and Klaus H Maier-Hein. nnu-net: a self-configuring method for deep learning-based biomedical image segmentation. Nature methods, 18(2):203–211, 2021
work page 2021
-
[4]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. InProceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023
work page 2023
-
[5]
Segment anything in medical images.Nature communications, 15(1):654, 2024
Jun Ma, Yuting He, Feifei Li, Lin Han, Chenyu You, and Bo Wang. Segment anything in medical images.Nature communications, 15(1):654, 2024
work page 2024
-
[6]
A 3d coarse-to-fine framework for volumetric medical image segmentation
Zhuotun Zhu, Yingda Xia, Wei Shen, Elliot Fishman, and Alan Yuille. A 3d coarse-to-fine framework for volumetric medical image segmentation. In2018 International conference on 3D vision (3DV), pages 682–690. IEEE, 2018
work page 2018
-
[7]
3d u-net: learning dense volumetric segmentation from sparse annotation
¨Ozg¨ un C ¸ i¸ cek, Ahmed Abdulkadir, Soeren S Lienkamp, Thomas Brox, and Olaf Ron- neberger. 3d u-net: learning dense volumetric segmentation from sparse annotation. In International conference on medical image computing and computer-assisted intervention, pages 424–432. Springer, 2016
work page 2016
-
[8]
Foivos I Diakogiannis, Fran¸ cois Waldner, Peter Caccetta, and Chen Wu. Resunet-a: A deep learning framework for semantic segmentation of remotely sensed data.ISPRS Journal of Photogrammetry and Remote Sensing, 162:94–114, 2020
work page 2020
-
[9]
Haofu Liao, Addisu Mesfin, and Jiebo Luo. Joint vertebrae identification and localiza- tion in spinal ct images by combining short-and long-range contextual information.IEEE transactions on medical imaging, 37(5):1266–1275, 2018
work page 2018
-
[10]
Shumao Pang, Chunlan Pang, Lei Zhao, Yangfan Chen, Zhihai Su, Yujia Zhou, Meiyan Huang, Wei Yang, Hai Lu, and Qianjin Feng. Spineparsenet: spine parsing for volumetric mr image by a two-stage segmentation framework with semantic image representation. IEEE Transactions on Medical Imaging, 40(1):262–273, 2020
work page 2020
-
[11]
Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous con- volution, and fully connected crfs.IEEE transactions on pattern analysis and machine intelligence, 40(4):834–848, 2017
work page 2017
-
[12]
Rethinking Atrous Convolution for Semantic Image Segmentation
Liang-Chieh Chen, George Papandreou, Florian Schroff, and Hartwig Adam. Rethinking atrous convolution for semantic image segmentation.arXiv preprint arXiv:1706.05587, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[13]
V-net: Fully convolutional neural networks for volumetric medical image segmentation
Fausto Milletari, Nassir Navab, and Seyed-Ahmad Ahmadi. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In2016 fourth international conference on 3D vision (3DV), pages 565–571. Ieee, 2016. 9
work page 2016
-
[14]
Saeid Asgari Taghanaki, Yefeng Zheng, S Kevin Zhou, Bogdan Georgescu, Puneet Sharma, Daguang Xu, Dorin Comaniciu, and Ghassan Hamarneh. Combo loss: Handling input and output imbalance in multi-organ segmentation.Computerized Medical Imaging and Graphics, 75:24–33, 2019
work page 2019
-
[15]
Maximilian T L¨ offler, Anjany Sekuboyina, Alina Jacob, Anna-Lena Grau, Andreas Scharr, Malek El Husseini, Mareike Kallweit, Claus Zimmer, Thomas Baum, and Jan S Kirschke. A vertebral segmentation dataset with fracture grading.Radiology: Artificial Intelligence, 2(4):e190138, 2020
work page 2020
-
[16]
Anjany Sekuboyina, Malek E Husseini, Amirhossein Bayat, Maximilian L¨ offler, Hans Liebl, Hongwei Li, Giles Tetteh, Jan Kukaˇ cka, Christian Payer, Darko ˇStern, et al. Verse: a vertebrae labelling and segmentation benchmark for multi-detector ct images.Medical image analysis, 73:102166, 2021
work page 2021
-
[17]
Hans Liebl, David Schinz, Anjany Sekuboyina, Luca Malagutti, Maximilian T L¨ offler, Amirhossein Bayat, Malek El Husseini, Giles Tetteh, Katharina Grau, Eva Niederreiter, et al. A computed tomography vertebral segmentation dataset with anatomical variations and multi-vendor scanner data.Scientific data, 8(1):284, 2021
work page 2021
-
[18]
Yang Deng, Ce Wang, Yuan Hui, Qian Li, Jun Li, Shiwei Luo, Mengke Sun, Quan Quan, Shuxin Yang, You Hao, et al. Ctspine1k: A large-scale dataset for spinal vertebrae seg- mentation in computed tomography.Machine Learning for Biomedical Imaging, 3(Special Issue on MICCAI Open Data 2024-2025):824–832, 2025
work page 2024
-
[19]
Jakob Wasserthal, Hanns-Christian Breit, Manfred T Meyer, Maurice Pradella, Daniel Hinck, Alexander W Sauter, Tobias Heye, Daniel T Boll, Joshy Cyriac, Shan Yang, et al. Totalsegmentator: robust segmentation of 104 anatomic structures in ct images.Radiology: Artificial Intelligence, 5(5):e230024, 2023
work page 2023
-
[20]
Grad-cam: Visual explanations from deep networks via gradient- based localization
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient- based localization. InProceedings of the IEEE international conference on computer vision, pages 618–626, 2017
work page 2017
-
[21]
Multi-Scale Context Aggregation by Dilated Convolutions
Fisher Yu and Vladlen Koltun. Multi-scale context aggregation by dilated convolutions. arXiv preprint arXiv:1511.07122, 2015. 10
work page internal anchor Pith review Pith/arXiv arXiv 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.