Cumulative Meta-Learning from Active Learning Queries for Robustness to Spurious Correlations
Pith reviewed 2026-05-21 06:25 UTC · model grok-4.3
The pith
CAML meta-learns a cumulative inductive bias from active-learning queries to reduce reliance on spurious correlations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CAML casts each active-learning round as a meta-learning task: the current labeled set serves as meta-train data for adaptation, while the newly queried batch serves as meta-test data for evaluating generalization. Unlike conventional meta-learning, which treats tasks as independent and identically distributed, CAML exploits the sequential dependence between active-learning rounds by maintaining a cumulative inductive bias that is progressively refined. Theoretically, this cumulative formulation introduces interaction terms that couple earlier meta-learned inductive biases with later query-induced objectives, capturing dependencies absent from standard meta-learning.
What carries the argument
the cumulative inductive bias that is progressively refined across active-learning rounds and introduces interaction terms coupling earlier meta-learned biases with later query-induced objectives
If this is right
- Minority-group accuracy improves across spurious-correlation benchmarks and acquisition strategies.
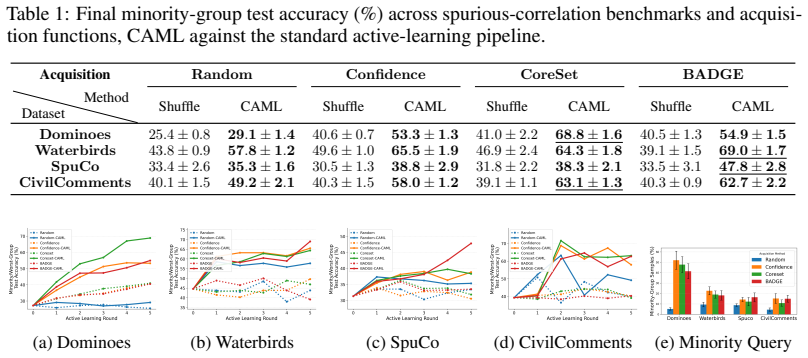
- Gains reach up to 27.8 percent on Dominoes, 29.9 percent on Waterbirds, 14.3 percent on SpuCo, and 24.0 percent on CivilComments.
- The influence of informative samples is preserved instead of being diluted by larger labeled sets because the prior is meta-learned.
- Sequential dependencies between rounds are captured through interaction terms that standard meta-learning omits.
Where Pith is reading between the lines
- The cumulative bias could be carried forward into deployment to guide adaptation on new incoming data streams without restarting the meta-learning process.
- Combining CAML with group-aware objectives or reweighting might amplify the separation of core features on datasets where queries alone are insufficient.
- The approach suggests a path for active learning in non-stationary environments where the nature of spurious correlations changes over time.
Load-bearing premise
The sequential dependence between active-learning rounds can be productively exploited by maintaining a single progressively refined cumulative inductive bias, and that the queried batch functions as effective meta-test data capable of distinguishing core features from spurious ones without additional modeling choices.
What would settle it
Running the same active-learning loops and benchmarks but replacing the cumulative bias update with an independent meta-learning reset each round and finding no loss in minority-group accuracy gains would show the cumulative mechanism is not required.
Figures



read the original abstract
Spurious correlations in real-world datasets cause machine learning models to rely on irrelevant patterns, undermining reliability, generalization, and fairness. Active learning offers a promising way to address this failure mode by querying informative samples that distinguish core features from spurious ones. However, standard active-learning methods simply append queried examples to the labeled set, effectively updating only the likelihood term. In deep learning regimes, the influence of these informative samples can be diluted by the larger labeled set and memorized by overparameterized models. We propose Cumulative Active Meta-Learning (CAML), an active-learning framework that uses queried examples to meta-learn the prior, or inductive bias, governing how the model adapts. CAML casts each active-learning round as a meta-learning task: the current labeled set serves as meta-train data for adaptation, while the newly queried batch serves as meta-test data for evaluating generalization. Unlike conventional meta-learning, which treats tasks as independent and identically distributed, CAML exploits the sequential dependence between active-learning rounds by maintaining a cumulative inductive bias that is progressively refined. Theoretically, we show that this cumulative formulation introduces interaction terms that couple earlier meta-learned inductive biases with later query-induced objectives, capturing dependencies absent from standard meta-learning. Empirically, CAML improves minority-group accuracy across spurious-correlation benchmarks and acquisition strategies, with gains of up to 27.8% on Dominoes, 29.9% on Waterbirds, 14.3% on SpuCo, and 24.0% on CivilComments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Cumulative Active Meta-Learning (CAML), an active-learning framework that meta-learns a cumulative inductive bias from queried examples to improve robustness to spurious correlations. Each active-learning round is cast as a meta-learning task with the current labeled set as meta-train data and the newly queried batch as meta-test data; a single progressively refined prior is maintained across rounds rather than treating tasks as i.i.d. The paper derives interaction terms that couple earlier meta-learned biases with later query-induced objectives and reports empirical gains in minority-group accuracy of up to 27.8% on Dominoes, 29.9% on Waterbirds, 14.3% on SpuCo, and 24.0% on CivilComments across multiple acquisition strategies.
Significance. If the central claim holds, the work provides a principled way to exploit sequential dependence in active learning to refine inductive biases against spurious features, addressing the dilution of informative samples in overparameterized regimes. The combination of a cumulative meta-objective with active querying is a natural extension of existing robustness techniques and could influence practical pipelines on benchmarks where spurious correlations are known to degrade minority-group performance.
major comments (2)
- [Theoretical Analysis] §3 (Theoretical Analysis): the derivation of the interaction terms shows coupling between successive meta-objectives, but does not establish that the resulting cumulative bias must penalize spurious-feature reliance; because both the meta-train set and the queried meta-test batch are drawn from the same training distribution that exhibits the spurious correlation by construction, it is not immediate that the meta-test loss distinguishes core from spurious features without additional assumptions on the acquisition function or the form of the adaptation.
- [Empirical Evaluation] §5 (Empirical Evaluation): the reported minority-group accuracy improvements are presented without ablations that isolate the cumulative aspect from standard (non-cumulative) meta-learning or from simply appending the queried batch; likewise, no variance across random seeds, statistical significance tests, or sensitivity to the inner-loop adaptation steps are provided, making it difficult to assess whether the gains are robust or attributable to the proposed interaction terms.
minor comments (2)
- [Method] Notation for the cumulative prior (e.g., how the meta-parameters are updated across rounds) is introduced without an explicit recurrence or pseudocode; a compact algorithm box would clarify the difference from standard MAML-style updates.
- [Experiments] The abstract states gains 'across acquisition strategies' but the main text should tabulate per-strategy results (including random sampling) to substantiate the claim that CAML is acquisition-agnostic.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address each of the major comments below, indicating the revisions we plan to make to strengthen the paper.
read point-by-point responses
-
Referee: [Theoretical Analysis] §3 (Theoretical Analysis): the derivation of the interaction terms shows coupling between successive meta-objectives, but does not establish that the resulting cumulative bias must penalize spurious-feature reliance; because both the meta-train set and the queried meta-test batch are drawn from the same training distribution that exhibits the spurious correlation by construction, it is not immediate that the meta-test loss distinguishes core from spurious features without additional assumptions on the acquisition function or the form of the adaptation.
Authors: We appreciate this observation. The theoretical analysis in §3 derives the interaction terms arising from the cumulative formulation, which couple the meta-learned bias from previous rounds with the current query-induced objective. While the meta-train and meta-test sets are indeed drawn from the same distribution, the key is that the acquisition function selects batches that are informative with respect to distinguishing core and spurious features. We will revise the manuscript to explicitly state the assumptions on the acquisition function (e.g., that it prioritizes examples where spurious correlations are less predictive) and discuss how the meta-test loss on such batches encourages adaptation that penalizes spurious reliance. This will include a new paragraph clarifying the conditions under which the cumulative bias reduces spurious correlations. revision: yes
-
Referee: [Empirical Evaluation] §5 (Empirical Evaluation): the reported minority-group accuracy improvements are presented without ablations that isolate the cumulative aspect from standard (non-cumulative) meta-learning or from simply appending the queried batch; likewise, no variance across random seeds, statistical significance tests, or sensitivity to the inner-loop adaptation steps are provided, making it difficult to assess whether the gains are robust or attributable to the proposed interaction terms.
Authors: We agree that additional ablations and statistical reporting would strengthen the empirical evaluation. In the revised manuscript, we will add ablations comparing CAML to (i) standard meta-learning without the cumulative aspect and (ii) simply appending the queried batch to the labeled set without meta-learning. We will report mean and standard deviation of minority-group accuracies over 5 random seeds for all experiments. We will also include statistical significance tests (e.g., paired t-tests) comparing CAML to baselines. Finally, we will provide sensitivity analysis to the number of inner-loop adaptation steps, showing results for varying step counts. These additions will help isolate the contribution of the cumulative interaction terms. revision: yes
Circularity Check
No significant circularity; derivation introduces new cumulative terms independently of inputs
full rationale
The paper defines CAML by casting active-learning rounds as sequential meta-tasks where the labeled set is meta-train and the queried batch is meta-test, then maintains a cumulative inductive bias across rounds. The theoretical contribution is the derivation of interaction terms that couple earlier biases to later objectives; this follows directly from the sequential formulation but does not reduce any performance claim to a fitted quantity or self-referential definition. Empirical gains are reported on external public benchmarks (Dominoes, Waterbirds, etc.) rather than on quantities defined inside the method. No self-citation is load-bearing for the central result, no ansatz is smuggled, and no prediction is statistically forced by construction. The framework is therefore self-contained against external validation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Active-learning rounds exhibit sequential dependence that can be captured by a single cumulative inductive bias rather than independent tasks.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CAML casts each active-learning round as a meta-learning task: the current labeled set serves as meta-train data for adaptation, while the newly queried batch serves as meta-test data for evaluating generalization... introduces interaction terms that couple earlier meta-learned inductive biases with later query-induced objectives
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
theoretically, we show that this cumulative formulation introduces interaction terms that couple earlier meta-learned inductive biases with later query-induced objectives
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Lewis, David D. and Gale, William A. , editor =. A Sequential Algorithm for Training Text Classifiers , booktitle =. 1994 , pages =
work page 1994
-
[2]
and Ghahramani, Zoubin and Jordan, Michael I
Cohn, David A. and Ghahramani, Zoubin and Jordan, Michael I. , title =. Journal of Artificial Intelligence Research , volume =. 1996 , doi =
work page 1996
-
[3]
Kingma, Diederik P. and Ba, Jimmy , title =. International Conference on Learning Representations , year =
-
[4]
International Conference on Learning Representations , year =
Lovering, Charles and Jha, Rohan and Linzen, Tal and Pavlick, Ellie , title =. International Conference on Learning Representations , year =
-
[5]
A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference , author =. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , month = jun, year =. doi:10.18653/v1/N18-1101 , url =
work page internal anchor Pith review doi:10.18653/v1/n18-1101 2018
-
[6]
Companion Proceedings of The 2019 World Wide Web Conference , year =
Borkan, Daniel and Dixon, Lucas and Sorensen, Jeffrey and Thain, Nithum and Vasserman, Lucy , title =. Companion Proceedings of The 2019 World Wide Web Conference , year =. doi:10.1145/3308560.3317593 , url =
-
[7]
International Conference on Learning Representations , year =
Deep Batch Active Learning by Diverse, Uncertain Gradient Lower Bounds , author =. International Conference on Learning Representations , year =
-
[8]
Advances in Neural Information Processing Systems , volume =
On Warm-Starting Neural Network Training , author =. Advances in Neural Information Processing Systems , volume =. 2020 , url =
work page 2020
-
[9]
International Conference on Learning Representations , year =
Active Learning for Convolutional Neural Networks: A Core-Set Approach , author =. International Conference on Learning Representations , year =
-
[10]
Proceedings of the 34th International Conference on Machine Learning , pages =
Deep Bayesian Active Learning with Image Data , author =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , editor =
work page 2017
-
[11]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Active Learning by Learning , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2015 , doi =
work page 2015
-
[12]
Advances in Neural Information Processing Systems , volume =
Active Learning by Querying Informative and Representative Examples , author =. Advances in Neural Information Processing Systems , volume =. 2010 , publisher =
work page 2010
-
[13]
Journal of Machine Learning Research , volume =
Online Choice of Active Learning Algorithms , author =. Journal of Machine Learning Research , volume =. 2004 , url =
work page 2004
-
[14]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Active Discriminative Text Representation Learning , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =
-
[15]
Proceedings of the 23rd International Conference on Machine Learning , pages =
Batch Mode Active Learning and Its Application to Medical Image Classification , author =. Proceedings of the 23rd International Conference on Machine Learning , pages =. 2006 , doi =
work page 2006
-
[16]
International Conference on Learning Representations , year =
Last Layer Re-Training is Sufficient for Robustness to Spurious Correlations , author =. International Conference on Learning Representations , year =
-
[17]
Proceedings of the 38th International Conference on Machine Learning , pages =
Just Train Twice: Improving Group Robustness without Training Group Information , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
work page 2021
-
[18]
Proceedings of the 39th International Conference on Machine Learning , pages =
Correct-N-Contrast: A Contrastive Approach for Improving Robustness to Spurious Correlations , author =. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , editor =
work page 2022
-
[19]
Proceedings of the IEEE International Conference on Computer Vision , pages =
Deep Learning Face Attributes in the Wild , author =. Proceedings of the IEEE International Conference on Computer Vision , pages =. 2015 , url =
work page 2015
-
[20]
Advances in Neural Information Processing Systems , volume =
Learning from Failure: Training Debiased Classifier from Biased Classifier , author =. Advances in Neural Information Processing Systems , volume =. 2020 , publisher =
work page 2020
-
[21]
International Conference on Learning Representations , year =
Distributionally Robust Neural Networks for Group Shifts: On the Importance of Regularization for Worst-Case Generalization , author =. International Conference on Learning Representations , year =
-
[22]
Proceedings of the First Conference on Causal Learning and Reasoning , pages =
Simple Data Balancing Achieves Competitive Worst-Group-Accuracy , author =. Proceedings of the First Conference on Causal Learning and Reasoning , pages =. 2022 , editor =
work page 2022
-
[23]
International Conference on Learning Representations , year =
Reinforcement Learning with Unsupervised Auxiliary Tasks , author =. International Conference on Learning Representations , year =
-
[24]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Learning to Generalize: Meta-Learning for Domain Generalization , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2018 , doi =
work page 2018
-
[25]
Koh, Pang Wei and Sagawa, Shiori and Marklund, Henrik and Xie, Sang Michael and Zhang, Marvin and Balsubramani, Akshay and Hu, Weihua and Yasunaga, Michihiro and Phillips, Richard Lanas and Gao, Irena and Lee, Tony and David, Etienne and Stavness, Ian and Guo, Wei and Earnshaw, Berton A. and Haque, Imran S. and Beery, Sara M. and Leskovec, Jure and Kundaj...
work page 2021
-
[26]
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , booktitle =. 2019 , publisher =
work page 2019
-
[27]
International Conference on Learning Representations , year =
Decoupled Weight Decay Regularization , author =. International Conference on Learning Representations , year =
-
[28]
Proceedings of the 34th International Conference on Machine Learning , pages =
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks , author =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , editor =
work page 2017
-
[29]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages =
Deep Residual Learning for Image Recognition , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages =. 2016 , url =
work page 2016
-
[30]
Proceedings of the European Conference on Computer Vision (ECCV) , pages =
Recognition in Terra Incognita , author =. Proceedings of the European Conference on Computer Vision (ECCV) , pages =. 2018 , url =
work page 2018
-
[31]
Proceedings of the 35th International Conference on Machine Learning , pages =
Learning to Reweight Examples for Robust Deep Learning , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
work page 2018
-
[32]
Advances in Neural Information Processing Systems , volume =
Active Learning Helps Pretrained Models Learn the Intended Task , author =. Advances in Neural Information Processing Systems , volume =. 2022 , publisher =
work page 2022
-
[33]
Advances in Neural Information Processing Systems , volume =
On Feature Learning in the Presence of Spurious Correlations , author =. Advances in Neural Information Processing Systems , volume =. 2022 , publisher =
work page 2022
- [34]
- [35]
-
[36]
Adversarial Active Learning for Deep Networks: a Margin Based Approach , author=. 2018 , eprint=
work page 2018
-
[37]
and Genewein, Tim and Nurnberger, Andreas and Kohler, Jan M
Beluch, William H. and Genewein, Tim and Nurnberger, Andreas and Kohler, Jan M. , booktitle=. The Power of Ensembles for Active Learning in Image Classification , year=
-
[38]
Margin-Based Active Learning for Structured Output Spaces
Roth, Dan and Small, Kevin. Margin-Based Active Learning for Structured Output Spaces. Machine Learning: ECML 2006. 2006
work page 2006
-
[39]
Cost-Effective Active Learning for Deep Image Classification , year=
Wang, Keze and Zhang, Dongyu and Li, Ya and Zhang, Ruimao and Lin, Liang , journal=. Cost-Effective Active Learning for Deep Image Classification , year=
-
[40]
A new active labeling method for deep learning , year=
Wang, Dan and Shang, Yi , booktitle=. A new active labeling method for deep learning , year=
-
[41]
Bayesian Active Learning for Classification and Preference Learning , author=. 2011 , eprint=
work page 2011
-
[42]
Active Learning Literature Survey , Type =
Burr Settles , Institution =. Active Learning Literature Survey , Type =
- [43]
-
[44]
Liu, Peng and Wang, Lizhe and Ranjan, Rajiv and He, Guojin and Zhao, Lei , title =. ACM Comput. Surv. , month =. 2022 , issue_date =. doi:10.1145/3510414 , abstract =
-
[45]
Theory of Optimal Experimental Design , volume =
Fedorov, Valerii , year =. Theory of Optimal Experimental Design , volume =. Wiley Interdisciplinary Reviews: Computational Statistics , doi =
- [46]
-
[47]
IEEE Transactions on Medical Imaging , year=
Intelligent Labeling Based on Fisher Information for Medical Image Segmentation Using Deep Learning , author=. IEEE Transactions on Medical Imaging , year=
-
[48]
Active Learning for Speech Recognition: the Power of Gradients , author=. 2016 , eprint=
work page 2016
-
[49]
Deep Active Learning: Unified and Principled Method for Query and Training , author =. Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics , pages =. 2020 , editor =
work page 2020
-
[50]
Agnostic active learning , journal =
Maria-Florina Balcan and Alina Beygelzimer and John Langford , keywords =. Agnostic active learning , journal =. 2009 , note =. doi:https://doi.org/10.1016/j.jcss.2008.07.003 , url =
-
[51]
Angluin, Dana , title =. Mach. Learn. , month =. 1988 , issue_date =. doi:10.1023/A:1022821128753 , abstract =
-
[52]
Functional genomic hypothesis generation and experimentation by a robot scientist , author=. Nature , year=
-
[53]
Ido Dagan and Sean P. Engelson , abstract =. Committee-Based Sampling For Training Probabilistic Classifiers , editor =. Machine Learning Proceedings 1995 , publisher =. 1995 , isbn =. doi:https://doi.org/10.1016/B978-1-55860-377-6.50027-X , url =
-
[54]
Proceedings of the 40th International Conference on Machine Learning , pages =
Why does Throwing Away Data Improve Worst-Group Error? , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
work page 2023
-
[55]
What is the Effect of Importance Weighting in Deep Learning?
Byrd, Jonathon and Lipton, Zachary C. , keywords =. What is the Effect of Importance Weighting in Deep Learning? , publisher =. 2018 , copyright =. doi:10.48550/ARXIV.1812.03372 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1812.03372 2018
-
[56]
Grad -CAM: Visual Explanations from Deep Networks via Gradient -based Localization
Ramprasaath R. Selvaraju and Michael Cogswell and Abhishek Das and Ramakrishna Vedantam and Devi Parikh and Dhruv Batra , title =. doi:10.1007/s11263-019-01228-7 , url =
-
[57]
Singla, Sahil and Feizi, Soheil , keywords =. Salient ImageNet: How to discover spurious features in Deep Learning? , publisher =. 2021 , copyright =. doi:10.48550/ARXIV.2110.04301 , url =
-
[58]
Zech, John R and Badgeley, Marcus A and Liu, Manway and Costa, Anthony B and Titano, Joseph J and Oermann, Eric Karl. Variable generalization performance of a deep learning model to detect pneumonia in chest radiographs: A cross-sectional study. PLoS Med
-
[59]
Wah, Catherine and Branson, Steve and Welinder, Peter and Perona, Pietro and Belongie, Serge , year=. CUB-200-2011 , DOI=
work page 2011
-
[60]
The Pitfalls of Simplicity Bias in Neural Networks , url =
Shah, Harshay and Tamuly, Kaustav and Raghunathan, Aditi and Jain, Prateek and Netrapalli, Praneeth , booktitle =. The Pitfalls of Simplicity Bias in Neural Networks , url =
-
[61]
Approximating CNNs with Bag-of-local-Features models works surprisingly well on ImageNet
Wieland Brendel and Matthias Bethge , title =. CoRR , volume =. 2019 , url =. 1904.00760 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[62]
CoRR abs/1811.12231 (2018), http://arxiv.org/ abs/1811.12231
Robert Geirhos and Patricia Rubisch and Claudio Michaelis and Matthias Bethge and Felix A. Wichmann and Wieland Brendel , title =. CoRR , volume =. 2018 , url =. 1811.12231 , timestamp =
- [63]
-
[64]
Module-Aware Optimization for Auxiliary Learning , url =
Chen, Hong and Wang, Xin and Liu, Yue and Zhou, Yuwei and Guan, Chaoyu and Zhu, Wenwu , booktitle =. Module-Aware Optimization for Auxiliary Learning , url =
-
[65]
Adaptive Auxiliary Task Weighting for Reinforcement Learning , url =
Lin, Xingyu and Baweja, Harjatin and Kantor, George and Held, David , booktitle =. Adaptive Auxiliary Task Weighting for Reinforcement Learning , url =
-
[66]
Auxiliary Task Reweighting for Minimum-data Learning , author=. 2020 , eprint=
work page 2020
-
[67]
Fine-Grained Visual Categorization using Meta-Learning Optimization with Sample Selection of Auxiliary Data , author=. 2018 , eprint=
work page 2018
-
[68]
Diversify and Disambiguate: Learning From Underspecified Data , author=. 2023 , eprint=
work page 2023
-
[69]
Invariant Risk Minimization , author =. arXiv preprint arXiv:1907.02893 , year =
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[70]
Jia Liu and Jing Qi and Wei Chen and Yongjian Nian , keywords =. Multi-branch fusion auxiliary learning for the detection of pneumonia from chest X-ray images , journal =. 2022 , issn =. doi:https://doi.org/10.1016/j.compbiomed.2022.105732 , url =
-
[71]
Mohammad Pezeshki and S. Gradient Starvation:. CoRR , volume =. 2020 , url =. 2011.09468 , timestamp =
-
[72]
Spurious Correlations in Machine Learning: A Survey , author=. 2024 , eprint=
work page 2024
-
[73]
Shortcut Learning in Deep Neural Networks , journal =
Robert Geirhos and J. Shortcut Learning in Deep Neural Networks , journal =. 2020 , url =. 2004.07780 , timestamp =
-
[74]
Journal of Machine Learning Research , volume =
Underspecification Presents Challenges for Credibility in Modern Machine Learning , author =. Journal of Machine Learning Research , volume =. 2022 , url =
work page 2022
-
[75]
MaskTune: Mitigating Spurious Correlations by Forcing to Explore , author=. 2022 , eprint=
work page 2022
-
[76]
Proceedings of the 37th International Conference on Machine Learning , pages =
Invariant Risk Minimization Games , author =. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , editor =
work page 2020
-
[77]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Lin, Yong and Dong, Hanze and Wang, Hao and Zhang, Tong , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2022 , pages =
work page 2022
-
[78]
Proceedings of the 39th International Conference on Machine Learning , pages =
Sparse Invariant Risk Minimization , author =. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , editor =
work page 2022
-
[79]
A Too-Good-to-be-True Prior to Reduce Shortcut Reliance , author=. 2021 , eprint=
work page 2021
-
[80]
Towards Debiasing NLU Models from Unknown Biases , author=. 2020 , eprint=
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.