BioDefect: The First Dataset for Defect Detection in Bioinformatics Software
Pith reviewed 2026-05-21 04:07 UTC · model grok-4.3
The pith
BioDefect supplies the first dataset built for defect detection in bioinformatics software and raises detection scores by keeping full code context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
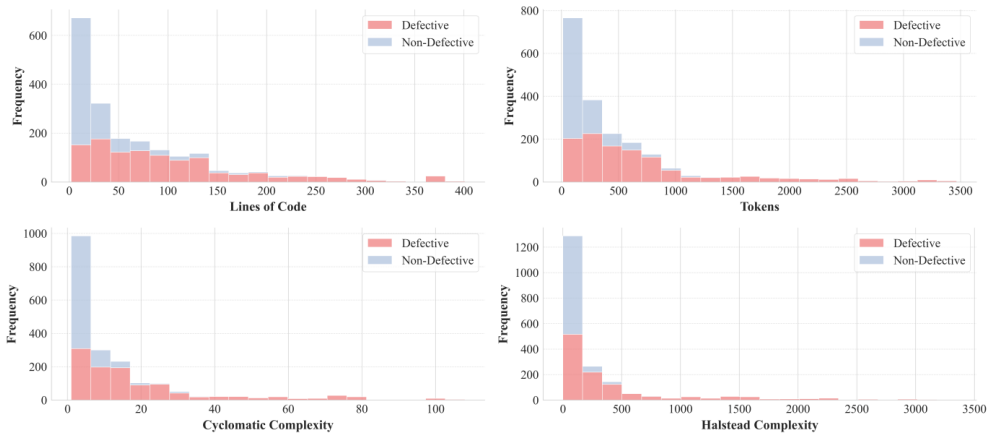
We introduce BioDefect, the first dataset specifically designed for defect detection in bioinformatics software. Unlike prior datasets, BioDefect includes complete source code repositories, preserving the actual contextual information of defective code and thereby more accurately reflecting real-world defect scenarios. It also mitigates label inconsistency and data leakage. Systematic evaluation on nine language models demonstrates average F1-score improvements of 29.61 percent to 38.04 percent compared with existing datasets.
What carries the argument
The BioDefect dataset of complete source code repositories that preserve contextual information around defective code while reducing label inconsistency and data leakage.
If this is right
- Models trained on complete code contexts identify defects in bioinformatics programs more reliably than models trained on fragmented snippets.
- Bioinformatics software maintainers gain a practical resource for automated quality checks that better matches real development conditions.
- Future studies can extend the same complete-repository approach to defect detection in other scientific computing domains.
- Reduced label inconsistency in training data produces more stable and reproducible detection results across different language models.
Where Pith is reading between the lines
- Developers of scientific software in fields such as computational chemistry could adopt similar full-repository datasets to improve automated bug finding.
- The design emphasis on avoiding data leakage may become a standard requirement when building specialized code datasets beyond bioinformatics.
- Integration of BioDefect-style collections with general-purpose code datasets could produce hybrid training sets that improve cross-domain detection.
- Higher defect detection accuracy may reduce downstream errors in tools used for sequence alignment and protein structure prediction.
Load-bearing premise
The measured performance gains arise directly from the dataset design choices of full repositories and reduced inconsistencies rather than from uncontrolled differences in model training or evaluation.
What would settle it
If the same nine models achieve comparable F1 scores on a dataset that matches BioDefect in size and labels but uses only isolated code snippets without full repository context, the claim that complete repositories drive the gains would be undermined.
Figures
read the original abstract
Software defect detection is a critical task in software engineering. However, no prior studies have specifically addressed defect detection in bioinformatics software. Given that the performance of defect detection tasks is primarily influenced by both models and datasets, our experiments controlled for model-related factors and confirmed the limitations of existing datasets in bioinformatics software. To address this issue, we introduce BioDefect, the first dataset specifically designed for defect detection in bioinformatics software, aiming to overcome the limitations of existing datasets in this context. Unlike prior datasets, BioDefect includes complete source code repositories, preserving the actual contextual information of defective code, thereby more accurately reflecting real-world defect scenarios in bioinformatics software. Additionally, BioDefect mitigates issues related to label inconsistency and data leakage, ensuring high data quality and experimental reliability. To evaluate the effectiveness of BioDefect, we conduct a systematic assessment on nine language models (LMs), including DeepSeek-R1. The results demonstrate that BioDefect significantly enhances defect detection performance for bioinformatics software. Compared to existing datasets, BioDefect achieves an average F1-score improvement of 29.61% to 38.04% across all models, highlighting its superior advantages. This study fills a critical research gap in bioinformatics software defect detection, laying a foundation for future studies in this field and offering new insights for improving bioinformatics software quality assurance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces BioDefect as the first dataset for defect detection in bioinformatics software. It claims that existing datasets suffer from limitations such as incomplete repositories, label inconsistency, and data leakage; by addressing these through complete source code repositories and improved data quality, BioDefect yields average F1-score improvements of 29.61% to 38.04% over prior datasets when evaluated on nine language models including DeepSeek-R1. The work positions itself as filling a research gap in bioinformatics software quality assurance.
Significance. If the performance gains can be causally linked to the dataset design choices rather than test-set mismatches, BioDefect would provide a valuable, domain-specific benchmark that advances defect detection for bioinformatics tools. The empirical evaluation across multiple models is a positive feature of the contribution.
major comments (3)
- [Abstract] Abstract: The headline claim of 29.61%–38.04% average F1 improvement is presented without any description of the dataset construction process, labeling protocol, or error analysis, leaving the central performance assertion unsupported by methodological detail.
- [Experiments] Experiments: The evaluation controls only for model choice but reports no ablation isolating the contributions of complete repositories, reduced label inconsistency, or absence of data leakage; without such controls the attribution of gains to these specific design features cannot be verified.
- [Results] Results / Evaluation: No evidence is provided that the held-out test splits for BioDefect and the baseline datasets share comparable defect-type distributions, code-length statistics, or repository overlap; unmatched test distributions could fully explain the observed F1 lift.
minor comments (2)
- Provide a table of basic dataset statistics (number of files, defect types, average LOC) for BioDefect and each baseline to allow direct comparison.
- Clarify the exact versions, fine-tuning procedures, and prompting strategies used for the nine language models.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. The comments identify areas where additional methodological detail and controls would strengthen the presentation. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim of 29.61%–38.04% average F1 improvement is presented without any description of the dataset construction process, labeling protocol, or error analysis, leaving the central performance assertion unsupported by methodological detail.
Authors: We agree that the abstract is concise and does not summarize the construction and quality-assurance steps. The full details appear in Sections 3 and 4 of the manuscript. In the revision we will add a single sentence to the abstract that briefly outlines the repository-completion, labeling-consistency, and leakage-mitigation procedures. revision: yes
-
Referee: [Experiments] Experiments: The evaluation controls only for model choice but reports no ablation isolating the contributions of complete repositories, reduced label inconsistency, or absence of data leakage; without such controls the attribution of gains to these specific design features cannot be verified.
Authors: The present experiments hold the model fixed while varying the dataset, which already isolates dataset effects from model effects. We did not include explicit ablations of each design choice in the submitted version. We will add a new subsection with controlled ablations that successively restore incomplete repositories, re-introduce label noise, and re-allow leakage, thereby quantifying the marginal contribution of each factor. revision: yes
-
Referee: [Results] Results / Evaluation: No evidence is provided that the held-out test splits for BioDefect and the baseline datasets share comparable defect-type distributions, code-length statistics, or repository overlap; unmatched test distributions could fully explain the observed F1 lift.
Authors: We acknowledge that direct comparability of the test distributions is necessary to rule out distributional confounds. The submitted manuscript reports only aggregate F1 scores. In the revision we will add a table and accompanying text that compare defect-type histograms, mean and variance of code lengths, and repository-overlap statistics across the held-out splits of BioDefect and the baseline datasets. revision: yes
Circularity Check
No significant circularity in empirical dataset contribution
full rationale
The paper presents BioDefect as a new dataset for bioinformatics defect detection and reports empirical F1-score gains (29.61–38.04%) from controlled experiments on nine language models. No derivations, equations, or first-principles claims exist that reduce to fitted parameters, self-definitions, or self-citation chains; the evaluation uses standard metrics on held-out data and attributes gains to dataset properties without circular reduction. The work is self-contained as a dataset introduction with direct experimental comparison.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Teresa K Attwood, Sarah Blackford, Michelle D Brazas, Angela Davies, and Maria Victoria Schneider. 2019. A global perspective on evolving bioinformatics and data science training needs. Briefings in Bioinformatics 20, 2, 398-404. https://doi.org/10.1093/bib/bbx100
-
[2]
Xu-Kai Ma, Yan Yu, Tao Huang, Dake Zhang, Caihuan Tian, Wenli Tang, Ming Luo, Pufeng Du, Guangchuang Yu, and Li Yang. 2024. Bioinformatics software development: Principles and future directions. The Innovation Life 2, 3, 100083. https://doi.org/10.59717/j.xinn-life.2024.100083
-
[3]
Adeeb Noor. 2022. Improving bioinformatics software quality through incorporation of software engineering practices. PeerJ Computer Science 8e839. https://doi.org/10.7717/peerj-cs.839
-
[4]
Christof Koch, and Allan Jones. 2016. Big Science, Team Science, and Open Science for Neuroscience. Neuron 92, 3, 612 -616. https://doi.org/10.1016/j.neuron.2016.10.019
-
[5]
Michael Fu, and Chakkrit Tantithamthavorn. 2022. Linevul: A transformer -based line-level vulnerability prediction. In Proceedings of the Proceedings of the 19th International Conference on Mining Software Repositories, 2022, 608 -620
work page 2022
-
[6]
Jimin An, YunSeok Choi, and Jee -Hyong Lee. 2024. Code Defect Detection Using Pre -trained Language Models with Encoder -Decoder via Line -Level Defect Localization. In Proceedings of the Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), May, 2024, Torino, Italia. ELR...
work page 2024
-
[7]
Benjamin Steenhoek, Md Mahbubur Rahman, Shaila Sharmin, and Wei Le
-
[8]
Do Language Models Learn Semantics of Code? A Case Study in Vulnerability Detection. ArXiv abs/2311.04109
-
[9]
Yue Wang, Hung Le, Akhilesh Gotmare, Nghi Bui, Junnan Li, and Steven Hoi
-
[10]
CodeT5+: Open Code Large Language Models for Code Understanding and Generation. In Proceedings of the Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, December, 2023, Singapore. Association for Computational Linguistics, 1069 -1088. https://doi.org/10.18653/v1/2023.emnlp-main.68
-
[11]
Saikat Chakraborty, Rahul Krishna, Yangruibo Ding, and Baishakhi Ray. 2022. Deep Learning Based Vulnerability Detection: Are We There Yet? IEEE Transactions on Software Engineering 48, 9, 3280 -3296. https://doi.org/10.1109/TSE.2021.3087402
-
[12]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, and Xiao Bi. 2025. DeepSeek -R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. ArXiv abs/2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
StarCoder 2 and The Stack v2: The Next Generation
Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy - Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen - Ding Li, Megan L. Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Ev...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Yaqin Zhou, Shangqing Liu, Jingkai Siow, Xiaoning Du, and Yang Liu. 2019. Devign: effective vulnerability identification by learning comprehensive program semantics via graph neural networks. In Pro ceedings of the Proceedings of the 33rd International Conference on Neural Information Processing Systems, 2019. Curran Associates Inc., 10197 - 10207
work page 2019
-
[15]
Yue Wang, Weishi Wang, Shafiq Joty, and Steven C.H. Hoi. 2021. CodeT5: Identifier-aware Unified Pr e-trained Encoder -Decoder Models for Code Understanding and Generation. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, November, 2021, Online and Punta Cana, Dominican Republic. Association for ...
-
[16]
OPT: Open Pre-trained Transformer Language Models
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona T. Diab, Xian Li, Xi Victoria Lin, Todor Mihaylov, Myle Ott, Sam Shleifer, Kurt Shuster, Daniel Simig, Punit Singh Koura, Anjali Sridhar, Tianlu Wang, and Luke Zettlemoyer. 2022. OPT: Open Pre-trained Transformer Language Models. ArXiv abs/2205.01068
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
T. Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollár. 2020. Focal Loss for Dense Object Detection. IEEE Transactions on Pattern Analysis and Machine Intelligence 42, 2, 318-327. https://doi.org/10.1109/TPAMI.2018.2858826
-
[18]
Yizheng Chen, Zhoujie Ding, Lamya Alowain, Xinyun Chen, and David Wagner. 2023. DiverseVul: A New Vulnerable Source Code Dataset for Deep Learning Based Vulnerability Detection. In Proceedings of the Proceedings of the 26th International Symposium on Research in Attacks, Intrusions and Defenses, 2023, Hong Kong, China. Association for Computing Machinery,...
- [19]
-
[20]
Hao -Nan Zhu, and Cindy Rub io-González. 2023. On the Reproducibility of Software Defect Datasets. In Proceedings of the 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), 14 -20 May 2023, 2023, 2324-2335. https://doi.org/10.1109/ICSE48619.2023.00195
-
[21]
René Just, Darioush Jalali, and Michael D. Ernst. 2014. Defects4J: a database of existing faults to enable controlled testing studies for Java programs. In Proceedings of the Proceedings of the 2014 International Symposium on Software Testing and Analysis, 2014, San Jose, CA, USA. Association for Computing Machinery, 437–440. https://doi.org/10.1145/26103...
-
[22]
Ruchika Malhotra, Sonali C hawla, and Anjali Sharma. 2023. Software defect prediction using hybrid techniques: a systematic literature review. Soft Computing 27, 12, 8255-8288. https://doi.org/10.1007/s00500-022-07738-w
-
[23]
Nima Shiri Harzevili, Alvine Boaye Belle, Junjie Wang, Song Wang, Zhen Ming Jiang, and Nachiappan Nagappan. 2024. A Systematic Literature Review on Automated Software Vulnerability Detection Using Machine Learning. ACM Comput. Surv. https://doi.org/10.1145/3699711
-
[24]
Michael Pradel, and Koushik Sen. 2018. DeepBugs: a learning approach to name-based bug detection. Proceedings of the ACM on Programming Languages 2, OOPSLA, 1-25. https://doi.org/10.1145/3276517
-
[25]
Miltiadis Allamanis, Henry Jackson -Flux, and Marc Brockschmidt. 2021. Self - supervised bug detection and repair. Advances in Neural Information Processing Systems 3427865-27876
work page 2021
-
[26]
Jiahao Fan, Yi Li, Shaohua Wang, and Tien N. Nguyen. 2020. A C/C++ Code Vulnerability Dataset with Code Changes and CVE Summaries. In Proceedings of the 2020 IEEE/ACM 17th International Conference on Mining Software Repositories (MSR), 25 -26 May 2020, 2020, 508 -512. https://doi.org/10.1145/3379597.3387501
-
[27]
Miltiadis Allamanis. 2019. The adverse effects of code duplication in machine learning models of code. In Proceedings of the Proceedings of the 2019 ACM SIGPLAN I nternational Symposium on New Ideas, New Paradigms, and Reflections on Programming and Software, 2019, Athens, Greece. Association for Computing Machinery, 143–153. https://doi.org/10.1145/33595...
-
[28]
Roland Croft, M. Ali Babar, and M. Mehdi Kholoosi. 2023. Data Quality for Software Vulnerability Datasets. In Proceedings of the Proceedings of the 45th International Conference on Software Engineering, 2023, Melbourne, Victoria, Australia. IEEE Press, 121–133. https://doi.org/10.1109/icse48619.2023.00022
-
[29]
Shaojie Yang, Haoran Xu, Fangliang Xu, and Yongjun Wang. 2024. S2Vul: Vulnerability Analysis Based on Self -supervised Information Integration. In Proceedings of the 2024 IEEE 35th International Symposium on Software Reliability Engineering (ISSRE), 28 -31 Oct. 2024, 2024, 84 -95. https://doi.org/10.1109/ISSRE62328.2024.00019
-
[30]
Alexander Wolf, Philipp Angerer, and Fabian J
F. Alexander Wolf, Philipp Angerer, and Fabian J. Theis. 2018. SCANPY: large-scale single -cell gene expression data analysis. Genome Biology 19, 1,
work page 2018
-
[31]
https://doi.org/10.1186/s13059-017-1382-0
-
[32]
H. Li, and R. Durbin. 2009. Fast and accurate short read alignment with Burrows-Wheeler transform. Bioinformatics (Oxford, England) 25, 14, (2009/05/20), 1754-1760. https://doi.org/10.1093/bioinformatics/btp324
-
[33]
Ben Langmead, and Steven L. Salzberg. 2012. Fast gapped -read alignment with Bowtie 2. Nature Methods 9, 4, 357-359. https://doi.org/10.1038/nmeth.1923
-
[34]
Shuai Lu, Daya Guo, Shuo Ren, Junjie Huang, Alexey Svyatkovskiy, Ambrosio Blanco, Colin Clement, Dawn Drain, Daxin Jiang, and Duyu Tang. 2021. Codexglue: A machine learning benchmark dataset for code understanding and generation. ArXiv abs/2102.04664
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[35]
Benjamin Steenhoek, Md Mahbubur Rahman, Richard Jiles, and Wei Le. 2023. An Empirical Study of Deep Learning Models for Vulnerability Detection. In Proceedings of the Proceedings of the 45th International Conference on Software Engineering, 2023, Melbourne, Victoria, Austral ia. IEEE Press, 2237–
work page 2023
-
[36]
https://doi.org/10.1109/icse48619.2023.00188
-
[37]
Partha Chakraborty, Krishna Kanth Arumugam, Mahmoud Alfadel, Meiyappan Nagappan, and Shane McIntosh. 2024. Revisiting the Performance of Deep Learning-Based Vulnerability Detection on Realistic Datasets. IEEE Transactions on Software Engineering 50, 8, 2163 -2177. https://doi.org/10.1109/TSE.2024.3423712
-
[38]
Daya Gu o, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie Liu, Long Zhou, Nan Duan, Jian Yin, Daxin Jiang, and M. Zhou. 2020. GraphCodeBERT: Pre-training Code Representations with Data Flow. ArXiv abs/2009.08366
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[39]
Jacob Devlin, Ming -Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre -training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), J...
-
[40]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, and Ming Zhou. 2020. CodeBERT: A Pre-Trained Model for Programming and Natural Languages. In Proceedings of the Findings of the Asso ciation for Computational Linguistics: EMNLP 2020, 2020, Online. Association for Computational Linguistic...
work page 2020
-
[41]
https://doi.org/10.18653/v1/2020.findings-emnlp.139
-
[42]
Colin Raffel , Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text -to-text transformer. The Journal of Machine Learning Research 21, 1, Article 140
work page 2020
-
[43]
Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Haiquan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. 2023. CodeGen: An Open Large Language Model for Code with Multi -Turn Program Synthesis. In Proceedings of the International Conference on Learning Representations, 2023,
work page 2023
-
[44]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. 2020. Transformers: State -of-the...
-
[45]
Davide Chicco, Matthijs J. Warrens, and Giuseppe Jurman. 2021. The Matthews Correlation Coefficient (MCC) is More Informative Than Cohen’s Kappa and Brier Score in Binary Classification Assessment. IEEE Access 978368 -78381. https://doi.org/10.1109/ACCESS.2021.3084050
-
[46]
Shiqi Tang, Song Huang, Changyou Zheng, Erhu Liu, Cheng Zong, and Yixian Ding. 2022. A novel cross -project software defect prediction algorithm based on transfer learning. Tsinghua Science a nd Technology 27, 1, 41 -57. https://doi.org/10.26599/TST.2020.9010040
-
[47]
Bo Li, Yongqiang Yao, Jingru Tan, Gang Zhang, Fengwei Yu, Jianwei Lu, and Ye Luo. 2022. Equalized focal loss for dense long -tailed object detection. In Proceedings of the Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, 6990-6999
work page 2022
-
[48]
Zhen Li, Deqing Zou, Shouhuai Xu, Xinyu Ou, Hai Jin, Sujuan Wang, Zhijun Deng, and Yuyi Zhong. 2018. V ulDeePecker: A Deep Learning -Based System for Vulnerability Detection. In Proceedings of the Proceedings 2018 Network and Distributed System Security Symposium, 2018, https://doi.org/10.14722/ndss.2018.23165
-
[49]
Tomas Mikolov, Kai Chen, Gregory S. Corrado, and Jeffrey Dean. 2013. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the International Conference on Learning Representations, 2013,
work page 2013
-
[50]
Z. Li, D. Zou, S. Xu, Z . Chen, Y. Zhu, and H. Jin. 2022. VulDeeLocator: A Deep Learning-Based Fine-Grained Vulnerability Detector. IEEE Transactions on Dependable and Secure Computing 19, 4, 2821 -2837. https://doi.org/10.1109/TDSC.2021.3076142
-
[51]
Z. Li, D. Zou, S. Xu, H. Jin, Y. Zhu, and Z. Chen. 2022. SySeVR: A Framework for Using Deep Learning to Detect Software Vulnerabilities. IEEE Transactions on Dependable and Secure Computing 19, 4, 2244 -2258. https://doi.org/10.1109/TDSC.2021.3051525
-
[52]
Y. Wu, D. Zou, S. Dou, W. Yang, D. Xu, and H. Jin. 2022. VulCNN: An Image - inspired Scalable Vulnerability Detection System. In Proceedings of the 2022 IEEE/ACM 44th International Conference on Software Engineering (ICSE), 25 - 27 May 2022, 2022, 2365-2376. https://doi.org/10.1145/3510003.3510229
-
[53]
Daya Guo, Shuai Lu, Nan Duan, Yanlin Wang, Ming Zhou, and Jian Yin. 202 2. UniXcoder: Unified Cross -Modal Pre -training for Code Representation. In Proceedings of the Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), May, 2022, Dublin, Ireland. Association for Compu tational Linguistics, 7212...
-
[54]
Aditya Kanade, Petros Maniatis, Gogul Balakrishnan, and Kensen Shi. 2020. Learning and evaluating contextual e mbedding of source code. In Proceedings of the Proceedings of the 37th International Conference on Machine Learning,
work page 2020
-
[55]
Xin Zhou, DongGyun Han, and David Lo. 2021. Assessing Generalizability of CodeBERT. In Proceedings of the 2021 IEEE International Conference on Software Maintenance and Evolution (ICSME), 27 Sept. -1 Oct. 2021, 2021, 425-436. https://doi.org/10.1109/ICSME52107.2021.00044
-
[56]
Fangcheng Qiu, Zhongxin Liu, Xing Hu, Xin Xia, Gang Chen, and Xinyu Wang. 2024. Vulnerability Detection via Multiple -Graph-Based Code Representation. IEEE Transactions on Software Engineering 50, 8, 2178 -2199. https://doi.org/10.1109/TSE.2024.3427815
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.