Decomposing Subject-Driven Image Generation via Intermediate Structural Prediction
Pith reviewed 2026-05-21 05:27 UTC · model grok-4.3
The pith
Predicting an intermediate Canny map before final rendering preserves high-frequency details like logos and text in subject-driven image generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
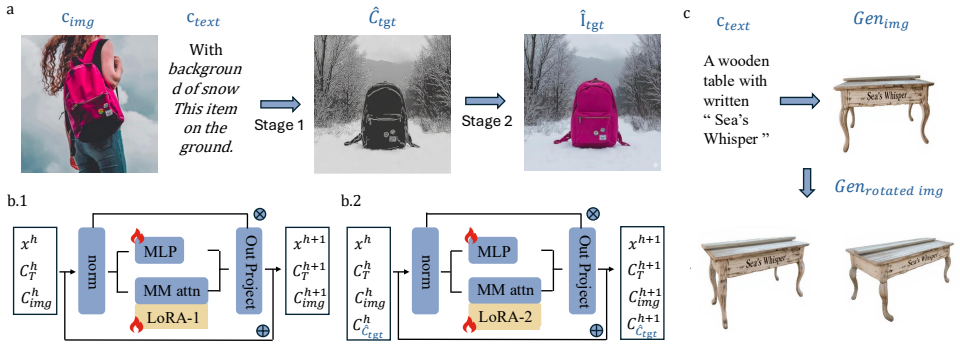
A two-stage framework decouples structure from appearance by first predicting a Canny map and then rendering the final image conditioned on both the source appearance and the predicted structure, with an automatic pipeline creating a 100k-pair text-aware dataset to aid text handling.
What carries the argument
The two-stage decomposition that first predicts a Canny map as structural guidance before appearance-conditioned rendering.
If this is right
- High-frequency identity elements remain sharper across edits than in single-stage RGB approaches.
- Text consistency improves when the dataset construction pipeline enforces cross-view agreement.
- The method demonstrates gains in both automated metrics and GPT-4.1-based human preference studies.
- Knowledge distillation from the two-stage model yields a lighter single-stage variant that retains some fidelity benefits.
Where Pith is reading between the lines
- The same structural-intermediate idea could be tested with other edge or depth representations to see if Canny edges are uniquely effective.
- This decoupling might extend to video or 3D subject-driven generation where consistent structure across frames is required.
- Future pipelines could insert additional intermediate predictions, such as segmentation or normal maps, for even finer control.
Load-bearing premise
Predicting a Canny map as an intermediate structural representation and conditioning the final rendering on both this map and source appearance will avoid the detail degradation that occurs when methods operate directly in RGB space under substantial edits.
What would settle it
A controlled test on subjects containing fine text, logos, or patterns under large pose or viewpoint changes, measuring whether detail retention metrics exceed those of direct RGB baselines.
Figures








read the original abstract
Subject-driven text-to-image generation still struggles to preserve high-frequency identity details such as logos, patterns, and text. Existing methods typically operate directly in RGB space, which often leads to detail degradation under substantial edits. We propose a two-stage framework that decouples structure from appearance by first predicting a Canny map and then rendering the final image conditioned on both the source appearance and the predicted structure. To improve text handling, we further introduce a fully automatic pipeline that constructs a 100k-pair text-aware dataset with cross-view textual consistency. Experiments, including GPT-4.1-based evaluation and a knowledge distillation study, show clear gains over selected baselines and suggest that intermediate structural prediction is an effective route for high-fidelity subject-driven generation. Our dataset and code will be made publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a two-stage framework for subject-driven text-to-image generation. In the first stage, it predicts an intermediate Canny edge map from the subject image and text prompt. In the second stage, it generates the final image by conditioning on both the predicted Canny map and the source appearance features. To address challenges with text and logos, the authors construct a 100k-pair text-aware dataset ensuring cross-view textual consistency using an automatic pipeline. The experiments, including evaluations with GPT-4.1 and a knowledge distillation study, report improvements over selected baselines, suggesting that intermediate structural prediction helps in maintaining high-fidelity details.
Significance. If validated, this decomposition approach could significantly improve the preservation of high-frequency identity details like text, patterns, and logos in subject-driven generation tasks, offering a more robust alternative to direct RGB-space methods that suffer from detail degradation under edits. The public release of the dataset and code would further enhance its impact by enabling reproducibility and further research.
major comments (3)
- §3.1: The central claim that first-stage Canny prediction plus appearance conditioning reliably prevents high-frequency detail loss under substantial edits rests on an assumption that may not hold, because Canny is a fixed low-level edge detector that discards texture, color gradients, and fine semantic layout (e.g., exact stroke order in logos or text). If the predicted Canny deviates from the edit-specified geometry on these elements, the second-stage renderer still operates from incomplete structure.
- §5.2, Table 3: The GPT-4.1-based evaluation and knowledge distillation study are described as showing 'clear gains,' but the manuscript provides no quantitative metrics, baseline details, ablation results, or statistical significance tests. Without these, it is not possible to verify whether the data actually support the central claim that intermediate structural prediction is effective.
- §4.1: The 100k text-aware dataset targets cross-view consistency but does not guarantee that the learned Canny predictor will produce geometrically accurate maps for novel prompts involving text or logos; the automatic construction pipeline lacks reported human verification or error analysis on semantic fidelity.
minor comments (2)
- §2: The related-work discussion could include more recent references on structural conditioning and edge-based guidance in diffusion models to better situate the contribution.
- Figure 2: The pipeline diagram would benefit from clearer labeling of the conditioning inputs to the second-stage renderer.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment point by point below, indicating where revisions have been made to the manuscript.
read point-by-point responses
-
Referee: §3.1: The central claim that first-stage Canny prediction plus appearance conditioning reliably prevents high-frequency detail loss under substantial edits rests on an assumption that may not hold, because Canny is a fixed low-level edge detector that discards texture, color gradients, and fine semantic layout (e.g., exact stroke order in logos or text). If the predicted Canny deviates from the edit-specified geometry on these elements, the second-stage renderer still operates from incomplete structure.
Authors: We agree that Canny is a low-level edge detector and does not encode texture or fine semantic details on its own. In our framework the second stage is explicitly conditioned on appearance features extracted from the source subject image; these features are responsible for supplying texture, color gradients, and high-frequency identity elements while the predicted Canny map supplies only geometric guidance. We have revised §3.1 to clarify this complementary relationship and added qualitative examples that illustrate preservation of text and logos under edits where the Canny map is only approximate. revision: yes
-
Referee: §5.2, Table 3: The GPT-4.1-based evaluation and knowledge distillation study are described as showing 'clear gains,' but the manuscript provides no quantitative metrics, baseline details, ablation results, or statistical significance tests. Without these, it is not possible to verify whether the data actually support the central claim that intermediate structural prediction is effective.
Authors: We acknowledge that the original presentation of the GPT-4.1 evaluation and knowledge-distillation study lacked sufficient quantitative detail. In the revised manuscript we have expanded §5.2 and updated Table 3 to report concrete metrics (preference scores, consistency rates), baseline specifications, ablation results, and statistical significance (paired t-tests with p-values). These additions directly support the claim that intermediate structural prediction yields measurable improvements. revision: yes
-
Referee: §4.1: The 100k text-aware dataset targets cross-view consistency but does not guarantee that the learned Canny predictor will produce geometrically accurate maps for novel prompts involving text or logos; the automatic construction pipeline lacks reported human verification or error analysis on semantic fidelity.
Authors: The automatic pipeline was designed for scalability while enforcing cross-view textual consistency through filtering heuristics. We accept that human verification strengthens the claim. The revised manuscript now includes a human evaluation on a 500-pair random subset together with an error analysis of semantic fidelity; these results are reported in §4.1 and the supplementary material. revision: yes
Circularity Check
No load-bearing circularity; empirical pipeline with external grounding
full rationale
The paper presents a two-stage empirical framework that first predicts a Canny edge map as intermediate structure and then conditions a renderer on both the predicted map and source appearance, augmented by an automatically constructed 100k text-aware dataset. No equations, parameter fits, or derivations are described that reduce to self-definition or rename fitted inputs as predictions. The central claim rests on comparative experiments (including GPT-4.1 evaluation and distillation) rather than any self-citation chain or uniqueness theorem imported from prior author work. Standard Canny detection and conditioning provide independent grounding, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
two-stage framework that decouples structure from appearance by first predicting a Canny map and then rendering the final image conditioned on both the source appearance and the predicted structure
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Canny edge maps provide a sparse yet powerful representation of an object’s high-frequency structural information
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Stephen Batifol, Andreas Blattmann, Frederic Boesel, Sak- sham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv e-prints, pages arXiv–2506,
-
[2]
Black Forest Labs. FLUX: A New Era for Fast and High- Quality Image Generation.https://github.com/ black-forest-labs/flux, 2024. Accessed: Septem- ber 5, 2025. 4, 6
work page 2024
-
[3]
A computational approach to edge detection
John Canny. A computational approach to edge detection. IEEE Transactions on pattern analysis and machine intelli- gence, (6):679–698, 1986. 2
work page 1986
-
[4]
Textdif- fuser: Diffusion models as text painters.arXiv preprint arXiv:2305.10855, 2023
Jingye Chen, Yupan Zhang, Qing Li, Zhaoliang Liu, Gyun- gin Yang, Seung-Hwan Lee, and Jinyoung Kim. Textdif- fuser: Diffusion models as text painters.arXiv preprint arXiv:2305.10855, 2023. 3
-
[5]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
DreamDA: Generative data augmentation with diffusion models.arXiv preprint arXiv:2403.12803, 2024
Yunxiang Fu, Chaoqi Chen, Yu Qiao, and Yizhou Yu. DreamDA: Generative data augmentation with diffusion models.arXiv preprint arXiv:2403.12803, 2024. 3
-
[7]
LaMamba-Diff: Linear-time high-fidelity diffusion models based on local at- tention and mamba
Yunxiang Fu, Chaoqi Chen, and Yizhou Yu. LaMamba-Diff: Linear-time high-fidelity diffusion models based on local at- tention and mamba. InProceedings of the British Machine Vision Conference, Sheffield, UK, 2025. 3
work page 2025
-
[8]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patash- nik, Amit H Bermano, Gal Chechik, and Daniel Cohen- Or. An image is worth one word: Personalizing text-to- image generation using textual inversion.arXiv preprint arXiv:2208.01618, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
Yu Gao, Lixue Gong, Qiushan Guo, Xiaoxia Hou, Zhichao Lai, Fanshi Li, Liang Li, Xiaochen Lian, Chao Liao, Liyang Liu, et al. Seedream 3.0 technical report.arXiv preprint arXiv:2504.11346, 2025. 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Hanzhong Guo, Shen Nie, Chao Du, Tianyu Pang, Hao Sun, and Chongxuan Li. Real-time identity defenses against ma- licious personalization of diffusion models.arXiv preprint arXiv:2412.09844, 2024. 3
-
[11]
Hanzhong Guo, Hongwei Yi, Daquan Zhou, Alexan- der William Bergman, Michael Lingelbach, and Yizhou Yu. Real-time one-step diffusion-based expressive portrait videos generation.arXiv preprint arXiv:2412.13479, 2024. 3
-
[12]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilib- rium.Advances in neural information processing systems, 30, 2017. 6
work page 2017
-
[13]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022. 4
work page 2022
-
[14]
Multi-concept customization of text-to-image diffusion,
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Customdiffusion: Multi- concept customization of text-to-image diffusion.arXiv preprint arXiv:2212.04488, 2022. 3
-
[15]
Photomaker: Customizing re- alistic human photos via stacked id embedding
Zhen Li, Mingdeng Cao, Xintao Wang, Zhongang Qi, Ming- Ming Cheng, and Ying Shan. Photomaker: Customizing re- alistic human photos via stacked id embedding. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8640–8650, 2024. 3
work page 2024
-
[16]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximil- ian Nickel, and Matt Le. Flow matching for generative mod- eling.arXiv preprint arXiv:2210.02747, 2022. 4
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Prodigy: An expeditiously adaptive parameter-free learner.arXiv preprint arXiv:2306.06101, 2023
Konstantin Mishchenko and Aaron Defazio. Prodigy: An expeditiously adaptive parameter-free learner.arXiv preprint arXiv:2306.06101, 2023. 6
-
[18]
Chong Mou, Xintao Wang, Liangbin Xie, Jian Zhang, Zhon- gang Qi, Ying Shan, and Xiaohu Qie. T2I-Adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models.arXiv preprint arXiv:2302.08453, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 4195–4205,
-
[20]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision.arXiv preprint arXiv:2103.00020, 2021. 6
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[21]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 2
work page 2022
-
[22]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhe Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22500– 22510, 2023. 2, 6
work page 2023
-
[23]
Seedream 4.0: Toward Next-generation Multimodal Image Generation
Team Seedream, Yunpeng Chen, Yu Gao, Lixue Gong, Meng Guo, Qiushan Guo, Zhiyao Guo, Xiaoxia Hou, Weilin Huang, Yixuan Huang, et al. Seedream 4.0: Toward next- generation multimodal image generation.arXiv preprint arXiv:2509.20427, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Zhenxiong Tan, Songhua Liu, Xingyi Yang, Qiaochu Xue, and Xinchao Wang. Ominicontrol: Minimal and uni- versal control for diffusion transformer.arXiv preprint arXiv:2401.15098, 2024. 1, 2, 3, 6, 7
-
[25]
InstantID: Zero-shot Identity-Preserving Generation in Seconds
Qixun Wang, Xu Bai, Haofan Wang, Zekui Qin, Anthony Chen, Huaxia Li, Xu Tang, and Yao Hu. Instantid: Zero-shot identity-preserving generation in seconds.arXiv preprint arXiv:2401.07519, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Automatic photo adjustment using deep neu- ral networks.ACM Trans
Zhicheng Yan, Hao Zhang, Baoyuan Wang, Sylvain Paris, and Yizhou Yu. Automatic photo adjustment using deep neu- ral networks.ACM Trans. Graph., 35(2):11:1–11:15, 2016. 3
work page 2016
-
[27]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. IP- Adapter: Text compatible image prompt adapter for text-to- image diffusion models.arXiv preprint arXiv:2308.06721,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Yuxin Zeng, Yahan Zhang, Yang Chen, Yidong Liu, and Yuan Zhang. Glyphcontrol: A conditional control module for accurate and consistent font generation.arXiv preprint arXiv:2402.13426, 2024. 3
-
[29]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023. 3
work page 2023
-
[30]
CarveMix: A sim- ple data augmentation method for brain lesion segmentation
Xinru Zhang, Chenghao Liu, Ni Ou, Xiangzhu Zeng, Zhizheng Zhuo, Yunyun Duan, Xiaoliang Xiong, Yizhou Yu, Zhiwen Liu, Yaou Liu, and Chuyang Ye. CarveMix: A sim- ple data augmentation method for brain lesion segmentation. NeuroImage, 271:120041, 2023. 3
work page 2023
-
[31]
Yuxuan Zhang, Yiren Song, Jiaming Liu, Rui Wang, Jinpeng Yu, Hao Tang, Huaxia Li, Xu Tang, Yao Hu, Han Pan, et al. Ssr-encoder: Encoding selective subject representation for subject-driven generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8069–8078, 2024. 6 Decomposing Subject-Driven Image Generation vi...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.