USV: Towards Understanding the User-generated Short-form Videos
Pith reviewed 2026-05-21 04:48 UTC · model grok-4.3
The pith
A dataset of 224K short videos collected via label queries enables benchmarks for topic recognition and video-text retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
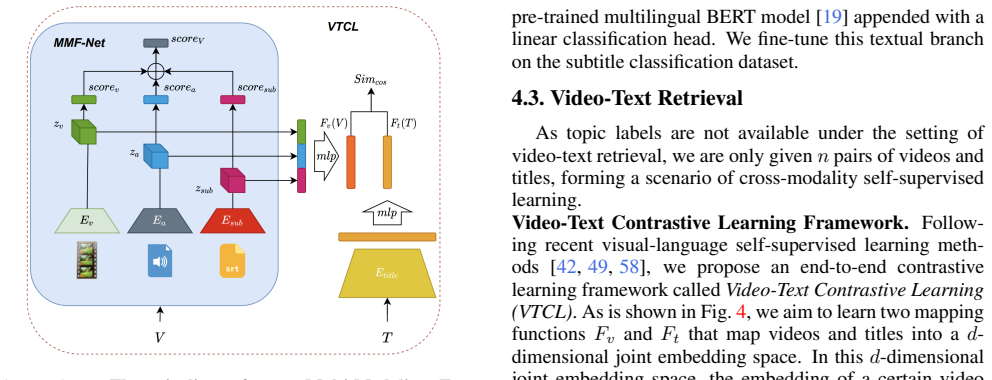
USV contains approximately 224K videos gathered from user-generated content platforms using label queries without extra manual verification or trimming. The dataset defines topic recognition and video-text retrieval as tasks that target high-level semantic information beyond instance-level recognition. MMF-Net and VTCL serve as unified baselines that perform these tasks and produce initial benchmark results on the collection.
What carries the argument
The USV dataset, built automatically through label queries on UGC platforms, supplies the raw material and defines the two tasks that allow high-level semantic video understanding to be measured at scale.
If this is right
- High-level semantic understanding can be studied directly on short-form videos rather than only on instance-level recognition.
- Topic recognition becomes a measurable capability for user-generated content.
- Video-text retrieval can be benchmarked on a large collection of short clips without curated annotations.
- Unified baselines like MMF-Net and VTCL provide starting points for comparing future methods on the same data.
Where Pith is reading between the lines
- Platforms that host short videos could use similar label-query collection to bootstrap internal semantic search or recommendation systems.
- The same construction method might be tested on other video lengths or domains to see whether manual cleaning remains unnecessary.
- Performance gaps between the two baselines could highlight which modalities matter most for short-form semantics.
Load-bearing premise
Videos collected by label queries alone carry accurate enough high-level semantic labels to support reliable topic recognition and video-text retrieval.
What would settle it
A random sample of videos from the dataset is manually inspected and found to contain a high rate of mismatched or ambiguous labels that cause the proposed baselines to perform no better than random guessing on the tasks.
Figures


read the original abstract
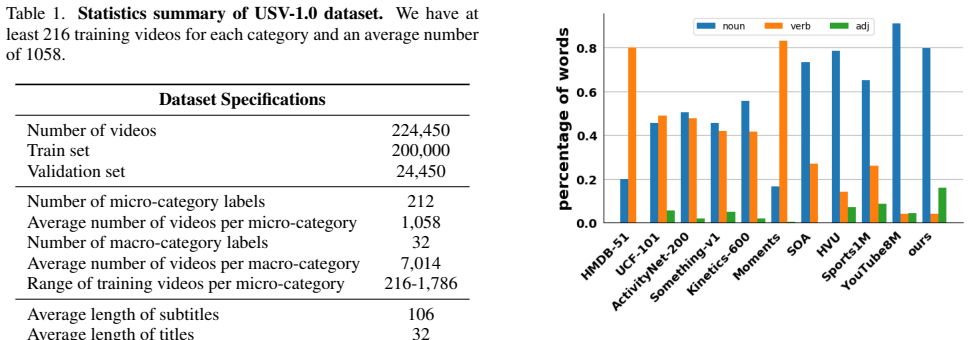
Several large-scale video datasets have been published these years and have advanced the area of video understanding. However, the newly emerged user-generated short-form videos have rarely been studied. This paper presents USV, the User-generated Short-form Video dataset for high-level semantic video understanding. The dataset contains around 224K videos collected from UGC platforms by label queries without extra manual verification and trimming. Although video understanding has achieved plausible improvement these years, most works focus on instance-level recognition, which is not sufficient for learning the representation of the high-level semantic information of videos. Therefore, we further establish two tasks: topic recognition and video-text retrieval on USV. We propose two unified and effective baseline methods Multi-Modality Fusion Network (MMF-Net) and Video-Text Contrastive Learning (VTCL), to tackle the topic recognition task and video-text retrieval respectively, and carry out comprehensive benchmarks to facilitate future research. Our project page is https://usvdataset.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the USV dataset of approximately 224K user-generated short-form videos collected from UGC platforms via label queries without manual verification or trimming. It defines two tasks for high-level semantic video understanding—topic recognition and video-text retrieval—and proposes unified baselines MMF-Net and VTCL, along with comprehensive benchmarks to support future research.
Significance. If the unverified query-based labels prove sufficiently accurate, the work would address an under-studied area by providing a large-scale resource focused on high-level semantics in short-form UGC videos rather than instance-level tasks. The baselines and benchmarks could usefully seed follow-on research, though the absence of label-quality validation limits immediate impact.
major comments (2)
- [Abstract / Dataset Construction] Abstract and Dataset Construction section: the central premise that label-query collection without extra manual verification or trimming yields videos with accurate high-level semantic content is load-bearing for both the topic-recognition and video-text-retrieval tasks, yet the manuscript provides no quantitative analysis of label noise, mismatch rates, or semantic fidelity; this directly affects benchmark validity.
- [Experiments] Experiments / Baselines section: no performance numbers, error bars, or ablation on label quality appear for MMF-Net or VTCL; without such evidence the claim that the dataset 'enables' high-level understanding cannot be evaluated.
minor comments (2)
- [Dataset Construction] Clarify the exact query terms and UGC platforms used; this would aid reproducibility.
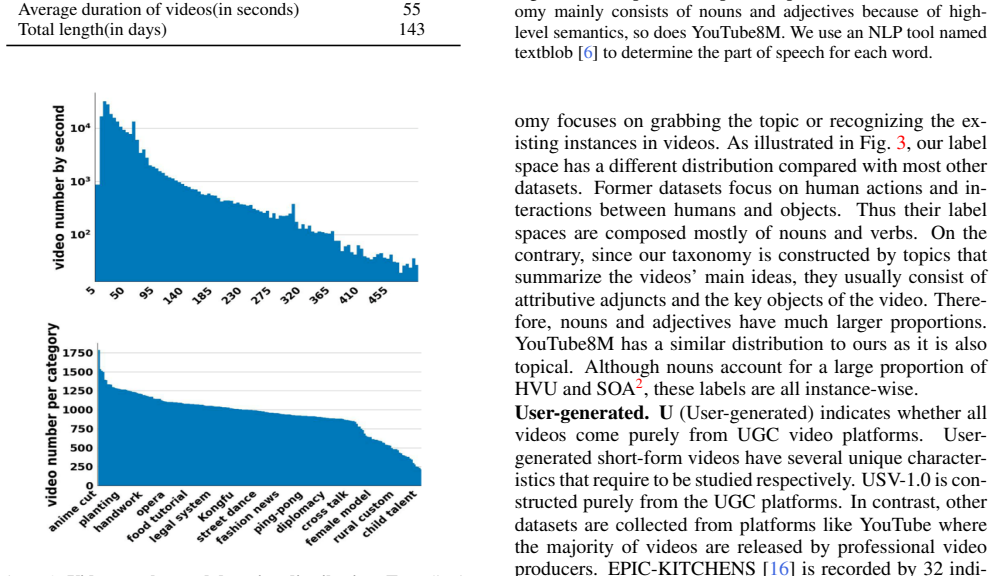
- [Dataset] Add a table summarizing dataset statistics (e.g., topic distribution, average duration) to support the scale claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address the two major concerns point by point below and commit to revisions that will strengthen the presentation of label quality and experimental validation.
read point-by-point responses
-
Referee: [Abstract / Dataset Construction] Abstract and Dataset Construction section: the central premise that label-query collection without extra manual verification or trimming yields videos with accurate high-level semantic content is load-bearing for both the topic-recognition and video-text-retrieval tasks, yet the manuscript provides no quantitative analysis of label noise, mismatch rates, or semantic fidelity; this directly affects benchmark validity.
Authors: We acknowledge that a quantitative assessment of label noise would further support the dataset's utility. The collection process relies on platform-provided labels from UGC sites, which are generated by users and content creators and typically reflect high-level semantic topics rather than fine-grained instance details. To directly address this point, we will add a new subsection in Dataset Construction that reports results from manual verification of a randomly sampled subset of 2,000 videos, including measured label accuracy, mismatch rates, and examples of semantic fidelity. This analysis will be included in the revised manuscript. revision: yes
-
Referee: [Experiments] Experiments / Baselines section: no performance numbers, error bars, or ablation on label quality appear for MMF-Net or VTCL; without such evidence the claim that the dataset 'enables' high-level understanding cannot be evaluated.
Authors: Performance numbers for both MMF-Net and VTCL are already reported in the Experiments section (Tables 2–4), where we compare against multiple baselines on the two tasks. We agree that error bars and a label-quality ablation would improve interpretability. In the revision we will add standard deviations from three independent runs for all reported metrics and include an ablation that retrains the models on a verified subset versus the full query-labeled set to quantify the effect of label noise on benchmark performance. revision: yes
Circularity Check
No circularity: new dataset and tasks introduced without self-referential derivations
full rationale
The paper presents a new dataset (USV) collected via label queries and defines two tasks (topic recognition, video-text retrieval) along with baseline models MMF-Net and VTCL. No equations, parameter fits, or load-bearing self-citations are described that would reduce any claim to an input by construction. The contribution is self-contained as data release plus benchmarks, with no derivation chain that collapses to prior results or definitions from the same authors.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Label queries without extra manual verification and trimming produce videos whose high-level semantic labels are accurate enough for topic recognition and video-text retrieval.
Reference graph
Works this paper leans on
- [1]
-
[2]
Ffmpeg.www.ffmpeg.com. 3
-
[3]
Kwai.https://www.kwai.com/. 1
-
[4]
mmaction2.https://github.com/open- mmlab/ mmaction2/. 9
-
[5]
Reels.https://about.instagram.com/blog/ announcements / introducing - instagram - reels-announcement. 1
- [6]
-
[7]
Tiktok.https://www.tiktok.com/. 1
-
[8]
Tiktok statistics.https://www.oberlo.ca/blog/ tiktok-statistics. 1
-
[9]
Youtube revenue analysis.https : / / www . businessofapps . com / data / youtube - statistics/. 1
-
[10]
YouTube-8M: A Large-Scale Video Classification Benchmark
Sami Abu-El-Haija, Nisarg Kothari, Joonseok Lee, Paul Natsev, George Toderici, Balakrishnan Varadarajan, and Sudheendra Vijayanarasimhan. Youtube-8m: A large- scale video classification benchmark.arXiv preprint arXiv:1609.08675, 2016. 2, 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[11]
Localizing mo- ments in video with natural language
Lisa Anne Hendricks, Oliver Wang, Eli Shechtman, Josef Sivic, Trevor Darrell, and Bryan Russell. Localizing mo- ments in video with natural language. InProceedings of the IEEE international conference on computer vision, pages 5803–5812, 2017. 3, 5
work page 2017
-
[12]
Relja Arandjelovic and Andrew Zisserman. Look, listen and learn. InProceedings of the IEEE International Conference on Computer Vision, pages 609–617, 2017. 2, 6
work page 2017
-
[13]
A Short Note about Kinetics-600
Joao Carreira, Eric Noland, Andras Banki-Horvath, Chloe Hillier, and Andrew Zisserman. A short note about kinetics- 600.arXiv preprint arXiv:1808.01340, 2018. 5
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
Quo vadis, action recognition? a new model and the kinetics dataset
Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. Inpro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6299–6308, 2017. 6, 7, 9
work page 2017
-
[15]
Scaling egocentric vision: The epic-kitchens dataset
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, et al. Scaling egocentric vision: The epic-kitchens dataset. InPro- ceedings of the European Conference on Computer Vision (ECCV), pages 720–736, 2018. 3
work page 2018
-
[16]
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, et al. The epic-kitchens dataset: Collection, challenges and base- lines.IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(11):4125–4141, 2020. 4, 5
work page 2020
-
[17]
The youtube video recommendation system
James Davidson, Benjamin Liebald, Junning Liu, Palash Nandy, Taylor Van Vleet, Ullas Gargi, Sujoy Gupta, Yu He, Mike Lambert, Blake Livingston, et al. The youtube video recommendation system. InProceedings of the fourth ACM conference on Recommender systems, pages 293–296, 2010. 1
work page 2010
-
[18]
Zhengyu Deng, Ming Yan, Jitao Sang, and Changsheng Xu. Twitter is faster: Personalized time-aware video recom- mendation from twitter to youtube.ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), 11(2):1–23, 2015. 1 13
work page 2015
-
[19]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding.arXiv preprint arXiv:1810.04805, 2018. 2, 6, 9
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
Large scale holistic video understanding
Ali Diba, Mohsen Fayyaz, Vivek Sharma, Manohar Paluri, J¨urgen Gall, Rainer Stiefelhagen, and Luc Van Gool. Large scale holistic video understanding. InEuropean Conference on Computer Vision, pages 593–610. Springer, 2020. 5
work page 2020
-
[21]
Holistic large scale video understanding.arXiv preprint arXiv:1904.11451, 2019
Ali Diba, Mohsen Fayyaz, Vivek Sharma, Manohar Paluri, Jurgen Gall, Rainer Stiefelhagen, and Luc Van Gool. Holistic large scale video understanding.arXiv preprint arXiv:1904.11451, 2019. 2, 3
-
[22]
Haoqi Fan, Yanghao Li, Bo Xiong, Wan-Yen Lo, and Christoph Feichtenhofer. Pyslowfast.https://github. com/facebookresearch/slowfast, 2020. 9
work page 2020
-
[23]
Slowfast networks for video recognition
Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. In Proceedings of the IEEE international conference on com- puter vision, pages 6202–6211, 2019. 5, 7
work page 2019
-
[24]
Self-supervised video representation learn- ing with odd-one-out networks
Basura Fernando, Hakan Bilen, Efstratios Gavves, and Stephen Gould. Self-supervised video representation learn- ing with odd-one-out networks. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 3636–3645, 2017. 2
work page 2017
-
[25]
The” something something” video database for learning and evaluating visual common sense
Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michal- ski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, et al. The” something something” video database for learning and evaluating visual common sense. InICCV, volume 1, page 5, 2017. 3, 5, 6
work page 2017
-
[26]
Ava: A video dataset of spatio-temporally localized atomic visual actions
Chunhui Gu, Chen Sun, David A Ross, Carl V ondrick, Car- oline Pantofaru, Yeqing Li, Sudheendra Vijayanarasimhan, George Toderici, Susanna Ricco, Rahul Sukthankar, et al. Ava: A video dataset of spatio-temporally localized atomic visual actions. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6047– 6056, 2018. 1
work page 2018
-
[27]
Video rep- resentation learning by dense predictive coding
Tengda Han, Weidi Xie, and Andrew Zisserman. Video rep- resentation learning by dense predictive coding. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision Workshops, pages 0–0, 2019. 2
work page 2019
-
[28]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016. 6
work page 2016
-
[29]
Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. Activitynet: A large-scale video benchmark for human activity understanding.2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 961–970, 2015. 1, 3, 5
work page 2015
-
[30]
A hierarchical deep temporal model for group activity recognition
Mostafa S Ibrahim, Srikanth Muralidharan, Zhiwei Deng, Arash Vahdat, and Greg Mori. A hierarchical deep temporal model for group activity recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion, pages 1971–1980, 2016. 2
work page 1971
-
[31]
Zhong Ji, Yaru Ma, Yanwei Pang, and Xuelong Li. Query- aware sparse coding for web multi-video summarization.In- formation Sciences, 478:152–166, 2019. 1
work page 2019
-
[32]
Thumos challenge: Action recognition with a large number of classes, 2014
Yu-Gang Jiang, Jingen Liu, A Roshan Zamir, George Toderici, Ivan Laptev, Mubarak Shah, and Rahul Sukthankar. Thumos challenge: Action recognition with a large number of classes, 2014. 1
work page 2014
-
[33]
Large-scale video classification with convolutional neural networks
Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, and Li Fei-Fei. Large-scale video classification with convolutional neural networks. InPro- ceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 1725–1732, 2014. 2, 3
work page 2014
-
[34]
Large-scale video classification with convolutional neural networks
Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, and Li Fei-Fei. Large-scale video classification with convolutional neural networks. InCVPR,
-
[35]
The Kinetics Human Action Video Dataset
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. The kinetics hu- man action video dataset.arXiv preprint arXiv:1705.06950,
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Unifying Visual-Semantic Embeddings with Multimodal Neural Language Models
Ryan Kiros, Ruslan Salakhutdinov, and Richard S Zemel. Unifying visual-semantic embeddings with multimodal neu- ral language models.arXiv preprint arXiv:1411.2539, 2014. 2
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[37]
Cooperative Learning of Audio and Video Models from Self-Supervised Synchronization
Bruno Korbar, Du Tran, and Lorenzo Torresani. Coopera- tive learning of audio and video models from self-supervised synchronization.arXiv preprint arXiv:1807.00230, 2018. 2
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[38]
Dense-captioning events in videos
Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles. Dense-captioning events in videos. In Proceedings of the IEEE international conference on com- puter vision, pages 706–715, 2017. 3, 5
work page 2017
-
[39]
Hmdb: a large video database for human motion recognition
Hildegard Kuehne, Hueihan Jhuang, Est ´ıbaliz Garrote, Tomaso Poggio, and Thomas Serre. Hmdb: a large video database for human motion recognition. In2011 Interna- tional Conference on Computer Vision, pages 2556–2563. IEEE, 2011. 1, 2, 3, 5
work page 2011
-
[40]
Unsupervised representation learning by sort- ing sequences
Hsin-Ying Lee, Jia-Bin Huang, Maneesh Singh, and Ming- Hsuan Yang. Unsupervised representation learning by sort- ing sequences. InProceedings of the IEEE International Conference on Computer Vision, pages 667–676, 2017. 2
work page 2017
-
[41]
Jie Lei, Linjie Li, Luowei Zhou, Zhe Gan, Tamara L Berg, Mohit Bansal, and Jingjing Liu. Less is more: Clipbert for video-and-language learning via sparse sampling.arXiv preprint arXiv:2102.06183, 2021. 2
-
[42]
Tianhao Li and Limin Wang. Learning spatiotemporal fea- tures via video and text pair discrimination.arXiv preprint arXiv:2001.05691, 2020. 6
-
[43]
Visual semantic search: Retrieving videos via complex tex- tual queries
Dahua Lin, Sanja Fidler, Chen Kong, and Raquel Urtasun. Visual semantic search: Retrieving videos via complex tex- tual queries. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2657–2664,
-
[44]
Tsm: Temporal shift module for efficient video understanding
Ji Lin, Chuang Gan, and Song Han. Tsm: Temporal shift module for efficient video understanding. InProceedings of the IEEE International Conference on Computer Vision, pages 7083–7093, 2019. 7, 8
work page 2019
-
[45]
PKU-MMD: A Large Scale Benchmark for Continuous Multi-Modal Human Action Understanding
Chunhui Liu, Yueyu Hu, Yanghao Li, Sijie Song, and Jiay- ing Liu. Pku-mmd: A large scale benchmark for continu- ous multi-modal human action understanding.arXiv preprint arXiv:1703.07475, 2017. 1
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
Towards micro-video understanding by joint sequential- sparse modeling
Meng Liu, Liqiang Nie, Meng Wang, and Baoquan Chen. Towards micro-video understanding by joint sequential- sparse modeling. InProceedings of the 25th ACM interna- tional conference on Multimedia, pages 970–978, 2017. 2
work page 2017
-
[47]
Visualiz- ing data using t-sne.Journal of machine learning research, 9(Nov):2579–2605, 2008
Laurens van der Maaten and Geoffrey Hinton. Visualiz- ing data using t-sne.Journal of machine learning research, 9(Nov):2579–2605, 2008. 3 14
work page 2008
-
[48]
The jester dataset: A large-scale video dataset of human gestures
Joanna Materzynska, Guillaume Berger, Ingo Bax, and Roland Memisevic. The jester dataset: A large-scale video dataset of human gestures. InProceedings of the IEEE Inter- national Conference on Computer Vision Workshops, pages 0–0, 2019. 2
work page 2019
-
[49]
End-to-end learning of visual representations from uncurated instruc- tional videos
Antoine Miech, Jean-Baptiste Alayrac, Lucas Smaira, Ivan Laptev, Josef Sivic, and Andrew Zisserman. End-to-end learning of visual representations from uncurated instruc- tional videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9879– 9889, 2020. 2, 6
work page 2020
-
[50]
Antoine Miech, Ivan Laptev, and Josef Sivic. Learning a text-video embedding from incomplete and heterogeneous data.arXiv preprint arXiv:1804.02516, 2018. 2
-
[51]
Howto100m: Learning a text-video embedding by watching hundred million narrated video clips
Antoine Miech, Dimitri Zhukov, Jean-Baptiste Alayrac, Makarand Tapaswi, Ivan Laptev, and Josef Sivic. Howto100m: Learning a text-video embedding by watching hundred million narrated video clips. InProceedings of the IEEE international conference on computer vision, pages 2630–2640, 2019. 2, 3, 5
work page 2019
-
[52]
Moments in time dataset: one million videos for event understanding
Mathew Monfort, Alex Andonian, Bolei Zhou, Kandan Ra- makrishnan, Sarah Adel Bargal, Tom Yan, Lisa Brown, Quanfu Fan, Dan Gutfreund, Carl V ondrick, et al. Moments in time dataset: one million videos for event understanding. IEEE transactions on pattern analysis and machine intelli- gence, 42(2):502–508, 2019. 1, 2, 3, 5
work page 2019
-
[53]
Mathew Monfort, Kandan Ramakrishnan, Alex Andonian, Barry A McNamara, Alex Lascelles, Bowen Pan, Quanfu Fan, Dan Gutfreund, Rogerio Feris, and Aude Oliva. Multi-moments in time: Learning and interpreting mod- els for multi-action video understanding.arXiv preprint arXiv:1911.00232, 2019. 2
-
[54]
Liqiang Nie, Meng Liu, and Xuemeng Song. Multimodal learning toward micro-video understanding.Synthesis Lec- tures on Image, Video, and Multimedia Processing, 9(4):1– 186, 2019. 1, 2
work page 2019
-
[55]
Enhancing micro-video understanding by harnessing external sounds
Liqiang Nie, Xiang Wang, Jianglong Zhang, Xiangnan He, Hanwang Zhang, Richang Hong, and Qi Tian. Enhancing micro-video understanding by harnessing external sounds. In Proceedings of the 25th ACM international conference on Multimedia, pages 1192–1200, 2017. 2
work page 2017
-
[56]
A large- scale benchmark dataset for event recognition in surveillance video
Sangmin Oh, Anthony Hoogs, Amitha Perera, Naresh Cun- toor, Chia-Chih Chen, Jong Taek Lee, Saurajit Mukherjee, JK Aggarwal, Hyungtae Lee, Larry Davis, et al. A large- scale benchmark dataset for event recognition in surveillance video. InCVPR 2011, pages 3153–3160. IEEE, 2011. 1, 2
work page 2011
-
[57]
Learning joint representations of videos and sentences with web image search
Mayu Otani, Yuta Nakashima, Esa Rahtu, Janne Heikkil ¨a, and Naokazu Yokoya. Learning joint representations of videos and sentences with web image search. InEuropean Conference on Computer Vision, pages 651–667. Springer,
-
[58]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision.arXiv preprint arXiv:2103.00020, 2021. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[59]
Scenes-objects- actions: A multi-task, multi-label video dataset
Jamie Ray, Heng Wang, Du Tran, Yufei Wang, Matt Feis- zli, Lorenzo Torresani, and Manohar Paluri. Scenes-objects- actions: A multi-task, multi-label video dataset. InPro- ceedings of the European Conference on Computer Vision (ECCV), pages 635–651, 2018. 3, 5
work page 2018
-
[60]
A dataset for movie description
Anna Rohrbach, Marcus Rohrbach, Niket Tandon, and Bernt Schiele. A dataset for movie description. InProceedings of the IEEE conference on computer vision and pattern recog- nition, pages 3202–3212, 2015. 5
work page 2015
-
[61]
Movie description.International Journal of Computer Vision, 123(1):94–120, 2017
Anna Rohrbach, Atousa Torabi, Marcus Rohrbach, Niket Tandon, Christopher Pal, Hugo Larochelle, Aaron Courville, and Bernt Schiele. Movie description.International Journal of Computer Vision, 123(1):94–120, 2017. 2, 3, 7, 9
work page 2017
-
[62]
Ntu rgb+ d: A large scale dataset for 3d human activity anal- ysis
Amir Shahroudy, Jun Liu, Tian-Tsong Ng, and Gang Wang. Ntu rgb+ d: A large scale dataset for 3d human activity anal- ysis. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1010–1019, 2016. 2
work page 2016
-
[63]
Finegym: A hierarchical video dataset for fine-grained action understand- ing
Dian Shao, Yue Zhao, Bo Dai, and Dahua Lin. Finegym: A hierarchical video dataset for fine-grained action understand- ing. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 2616–2625,
-
[64]
Abhinav Shukla, Stavros Petridis, and Maja Pantic. Learning speech representations from raw audio by joint audiovisual self-supervision.arXiv preprint arXiv:2007.04134, 2020. 6
-
[65]
Two-stream con- volutional networks for action recognition in videos
Karen Simonyan and Andrew Zisserman. Two-stream con- volutional networks for action recognition in videos. InAd- vances in neural information processing systems, pages 568– 576, 2014. 5
work page 2014
-
[66]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild.arXiv preprint arXiv:1212.0402, 2012. 1, 2, 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[67]
Chen Sun, Fabien Baradel, Kevin Murphy, and Cordelia Schmid. Learning video representations using contrastive bidirectional transformer.arXiv preprint arXiv:1906.05743,
-
[68]
Learning Language-Visual Embedding for Movie Understanding with Natural-Language
Atousa Torabi, Niket Tandon, and Leonid Sigal. Learning language-visual embedding for movie understanding with natural-language.arXiv preprint arXiv:1609.08124, 2016. 2
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[69]
A closer look at spatiotemporal convolutions for action recognition
Du Tran, Heng Wang, Lorenzo Torresani, Jamie Ray, Yann LeCun, and Manohar Paluri. A closer look at spatiotemporal convolutions for action recognition. InProceedings of the IEEE conference on Computer Vision and Pattern Recogni- tion, pages 6450–6459, 2018. 7
work page 2018
-
[70]
Jiangliu Wang, Jianbo Jiao, Linchao Bao, Shengfeng He, Yunhui Liu, and Wei Liu. Self-supervised spatio-temporal representation learning for videos by predicting motion and appearance statistics. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 4006–4015, 2019. 2
work page 2019
-
[71]
Temporal segment net- works: Towards good practices for deep action recognition
Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. Temporal segment net- works: Towards good practices for deep action recognition. InEuropean conference on computer vision, pages 20–36. Springer, 2016. 5, 6, 7, 8, 9
work page 2016
-
[72]
Yinwei Wei, Xiang Wang, Weili Guan, Liqiang Nie, Zhouchen Lin, and Baoquan Chen. Neural multimodal co- operative learning toward micro-video understanding.IEEE Transactions on Image Processing, 29:1–14, 2019. 2
work page 2019
-
[73]
Audiovisual slowfast networks for video recognition.arXiv preprint arXiv:2001.08740,
Fanyi Xiao, Yong Jae Lee, Kristen Grauman, Jitendra Malik, and Christoph Feichtenhofer. Audiovisual slowfast networks for video recognition.arXiv preprint arXiv:2001.08740,
-
[74]
Msr-vtt: A large video description dataset for bridging video and language
Jun Xu, Tao Mei, Ting Yao, and Yong Rui. Msr-vtt: A large video description dataset for bridging video and language. In 15 Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5288–5296, 2016. 2, 3, 5, 7, 9
work page 2016
-
[75]
Large-scale weakly supervised audio classifi- cation using gated convolutional neural network
Yong Xu, Qiuqiang Kong, Wenwu Wang, and Mark D Plumbley. Large-scale weakly supervised audio classifi- cation using gated convolutional neural network. In2018 IEEE international conference on acoustics, speech and sig- nal processing (ICASSP), pages 121–125. IEEE, 2018. 6
work page 2018
-
[76]
A joint se- quence fusion model for video question answering and re- trieval
Youngjae Yu, Jongseok Kim, and Gunhee Kim. A joint se- quence fusion model for video question answering and re- trieval. InProceedings of the European Conference on Com- puter Vision (ECCV), pages 471–487, 2018. 2
work page 2018
-
[77]
End-to-end concept word detection for video caption- ing, retrieval, and question answering
Youngjae Yu, Hyungjin Ko, Jongwook Choi, and Gunhee Kim. End-to-end concept word detection for video caption- ing, retrieval, and question answering. InProceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion, pages 3165–3173, 2017. 2
work page 2017
-
[78]
Jing Zhang, Yuting Wu, Jinghui Liu, Peiguang Jing, and Yut- ing Su. Low-rank regularized multimodal representation for micro-video event detection.IEEE Access, 8:87266–87274,
-
[79]
Towards automatic learning of procedures from web instructional videos
Luowei Zhou, Chenliang Xu, and Jason Corso. Towards automatic learning of procedures from web instructional videos. InProceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018. 2, 3, 5, 7, 9
work page 2018
-
[80]
Videotopic: Content-based video recommendation using a topic model
Qiusha Zhu, Mei-Ling Shyu, and Haohong Wang. Videotopic: Content-based video recommendation using a topic model. In2013 IEEE International Symposium on Mul- timedia, pages 219–222. IEEE, 2013. 1 16
work page 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.