On Unified and Sharpened CMI Bounds for Generalization Errors
Pith reviewed 2026-05-21 02:14 UTC · model grok-4.3
The pith
A unified conditional mutual information bound envelops many known generalization bounds and yields sharper ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Within the leave-m-out framework, a unified CMI-based bound is proposed that envelops and reproduces many known CMI-based bounds, bridges the gap between MI- and CMI-based bounds when m tends to infinity, and develops new sharper bounds which are further tightened by reducing the number of conditional terms under bounded loss.
What carries the argument
Unified CMI-based generalization bound using leave-m-out cross-validation error, with tightening via reduced conditional terms for bounded losses.
If this is right
- The proposed bound can envelop and reproduce many known CMI-based bounds.
- It bridges the gap between MI- and CMI-based bounds as m tends to infinity.
- New sharper bounds are obtained that improve on existing results in examples where prior bounds are inapplicable or looser.
- The framework is enhanced by tightening CMI quantities through fewer conditional terms when the loss is bounded.
- Empirical evaluation confirms improvements over previously known bounds.
Where Pith is reading between the lines
- This unification might allow deriving bounds for new learning settings by choosing appropriate m.
- The connection to MI bounds could inspire hybrid information measures for generalization analysis.
- Reducing conditional terms may apply to other information-theoretic quantities beyond CMI.
- Future work could test the bounds on complex models like deep neural networks to see practical gains.
Load-bearing premise
The loss function is bounded, which is used to reduce the number of conditional terms in the CMI quantities.
What would settle it
Finding a case with bounded loss where the proposed bound fails to be sharper than existing CMI bounds or does not reproduce them would challenge the unification and sharpening claims.
Figures






read the original abstract
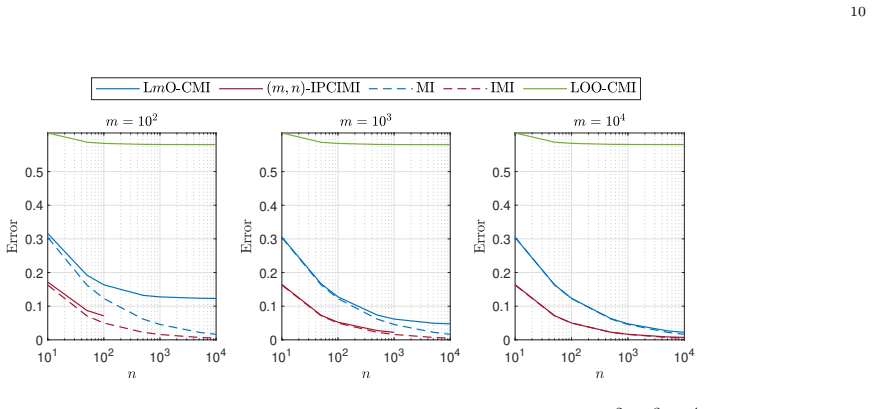
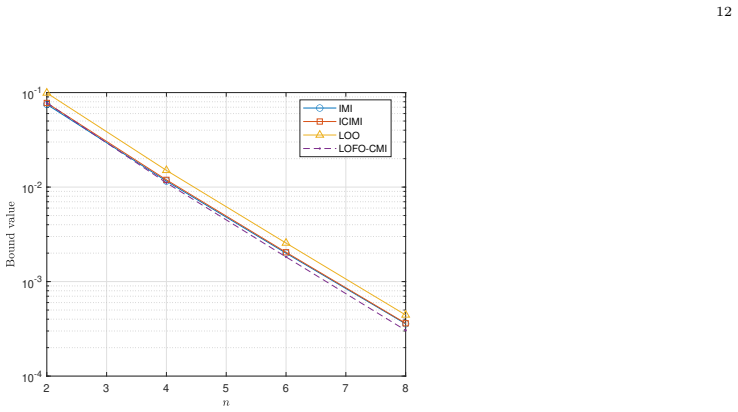
We present a new family of information-theoretic generalization bounds within the framework of conditional mutual information (CMI). Most of our results are established based on the leave-$m$-out (L$m$O) cross-validation error, with $m$ denoting the number of the hold-out supersamples. Under this setting, we propose a unified CMI-based bound, allowing to envelop and reproduce many known CMI-based bounds and also bridge the gap between the MI- and CMI-based bounds when $m$ tends to infinity. The proposed framework not only provides a unified description of the existing bounds but also develops new, sharper bounds. We show the benefits of the proposed bounds through several simple examples, where the existing results are either inapplicable or looser. Moreover, under the premise that the loss function is bounded, we tighten the CMI quantities involved in the proposed bounds by reducing the number of conditional terms, thereby enhancing the proposed framework. We show empirically that the resulting new bounds improve upon the previously known ones.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a unified family of conditional mutual information (CMI) generalization bounds based on the leave-m-out (LmO) cross-validation error. It claims this framework envelops and reproduces many existing CMI bounds, bridges the gap to mutual information (MI) bounds in the limit as m tends to infinity, yields new sharper bounds, and tightens the involved CMI quantities by reducing conditional terms when the loss is bounded, with supporting examples and empirical checks.
Significance. If the derivations and limit arguments hold without gaps, the work offers a valuable unification of information-theoretic generalization bounds, potentially allowing tighter or more widely applicable results than prior CMI or MI approaches. Credit is due for the explicit reproduction of known bounds, the development of sharper variants, and the empirical demonstrations in cases where existing bounds are inapplicable or loose. The bounded-loss tightening is a practical enhancement, though its interaction with the unification requires verification.
major comments (2)
- [Section discussing the m→∞ limit and MI-CMI bridging (likely §5 or the main theorem on the unified bound)] The central bridging claim (that the unified LmO-CMI bound recovers an MI bound as m→∞) is load-bearing for the unification narrative. The manuscript does not specify the growth regime relating m to the training size n; if m remains fixed or grows slower than n, residual conditioning in the supersample construction may prevent exact recovery of the standard MI bound, contradicting the abstract's statement that the gap is bridged.
- [Section on the unified CMI-based bound] §3 (or the section deriving the unified LmO-CMI bound): the reproduction of prior CMI results is asserted via envelopment, but the proof sketch does not explicitly verify that the new bound reduces exactly to each cited prior result (e.g., specific equations for known CMI bounds) without additional assumptions on m or the loss; this must be shown to substantiate the 'envelop and reproduce' claim.
minor comments (2)
- [Abstract and introduction] The abstract states that 'proofs exist' and empirical checks support improvement, yet the main text should include a clear statement of the precise conditions under which the bounded-loss tightening preserves all enveloped prior bounds.
- [Preliminaries or setup section] Notation for the supersample and LmO error should be introduced with an explicit definition of the ratio m/n early in the setup section to aid readability when discussing the limit.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address each major comment below and have revised the manuscript to incorporate clarifications and explicit verifications.
read point-by-point responses
-
Referee: The central bridging claim (that the unified LmO-CMI bound recovers an MI bound as m→∞) is load-bearing for the unification narrative. The manuscript does not specify the growth regime relating m to the training size n; if m remains fixed or grows slower than n, residual conditioning in the supersample construction may prevent exact recovery of the standard MI bound, contradicting the abstract's statement that the gap is bridged.
Authors: We thank the referee for highlighting this ambiguity. The intended regime is m → ∞ with the training size n held fixed in the supersample of size n + m; under this ordering the residual conditioning on the training set vanishes, recovering the standard MI bound. To eliminate any confusion we have added an explicit statement of the asymptotic regime together with a short derivation in the relevant section (now §5) showing the exact recovery. revision: yes
-
Referee: §3 (or the section deriving the unified LmO-CMI bound): the reproduction of prior CMI results is asserted via envelopment, but the proof sketch does not explicitly verify that the new bound reduces exactly to each cited prior result (e.g., specific equations for known CMI bounds) without additional assumptions on m or the loss; this must be shown to substantiate the 'envelop and reproduce' claim.
Authors: We agree that explicit specialization is needed to fully substantiate the claim. In the revised manuscript we have expanded the unified-bound section with a new subsection that derives the exact parameter settings (including admissible ranges for m and any loss-function assumptions) under which the general bound recovers each cited prior CMI result, such as the m = 1 case and other standard leave-m-out variants. revision: yes
Circularity Check
Derivation rests on standard information-theoretic identities with no reduction to inputs by construction
full rationale
The proposed unified LmO-CMI bound is constructed from the definition of conditional mutual information applied to the leave-m-out cross-validation error and standard bounding techniques under the bounded-loss assumption. Reproduction of prior CMI bounds follows directly from specializing the general expression (e.g., by choosing particular values of m or conditioning sets), while the m→∞ limit recovers an MI-style bound via explicit vanishing of conditional terms in the information quantities. These steps are algebraic consequences of the CMI definition and the supersample construction rather than parameter fitting or self-referential closure. No load-bearing step reduces to a fitted quantity renamed as prediction or to a self-citation whose validity depends on the present paper.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Standard chain rule and non-negativity properties of conditional mutual information hold.
- domain assumption The loss function is bounded.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present a new family of information-theoretic generalization bounds within the framework of conditional mutual information (CMI). ... unified CMI-based bound ... when m tends to infinity.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the expected LmO cross-validation error is equivalent to the classical expected generalization error (Lemma 1)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
S. Shalev-Shwartz and S. Ben-David, Understanding machine learning: From theory to algorithms. Cambridge university press, 2014
work page 2014
-
[2]
Controlling bias in adaptive data analysis using information theory,
D. Russo and J. Zou, “Controlling bias in adaptive data analysis using information theory,” in Artificial Intelligence and Statistics. PMLR, 2016, pp. 1232–1240
work page 2016
-
[3]
Information-theoretic analysis of generalization capability of learning algorithms,
A. Xu and M. Raginsky, “Information-theoretic analysis of generalization capability of learning algorithms,” Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[4]
Tightening mutual information-based bounds on generalization error,
Y. Bu, S. Zou, and V. V. Veeravalli, “Tightening mutual information-based bounds on generalization error,” IEEE Journal on Selected Areas in Information Theory, vol. 1, no. 1, pp. 121–130, 2020
work page 2020
-
[5]
Information-theoretic generalization bounds for black-box learning algorithms,
H. Harutyunyan, M. Raginsky, G. Ver Steeg, and A. Galstyan, “Information-theoretic generalization bounds for black-box learning algorithms,” Advances in Neural Information Processing Systems, vol. 34, pp. 24 670–24 682, 2021
work page 2021
-
[6]
B. Rodríguez-Gálvez, G. Bassi, R. Thobaben, and M. Skoglund, “On random subset generalization error bounds and the stochastic gradient langevin dynamics algorithm,” in 2020 IEEE Information Theory Workshop (ITW). IEEE, 2021, pp. 1–5
work page 2020
-
[7]
Information-theoretic generalization bounds for sgld via data- dependent estimates,
J. Negrea, M. Haghifam, G. K. Dziugaite, A. Khisti, and D. M. Roy, “Information-theoretic generalization bounds for sgld via data- dependent estimates,” Advances in Neural Information Processing Systems, vol. 32, 2019
work page 2019
-
[8]
Chaining mutual information and tightening generalization bounds,
A. Asadi, E. Abbe, and S. Verdú, “Chaining mutual information and tightening generalization bounds,” Advances in Neural Information Processing Systems, vol. 31, 2018
work page 2018
-
[9]
Stochastic chaining and strengthened information-theoretic generalization bounds,
R. Zhou, C. Tian, and T. Liu, “Stochastic chaining and strengthened information-theoretic generalization bounds,” Journal of the Franklin Institute, vol. 360, no. 6, pp. 4114–4134, 2023
work page 2023
-
[10]
Reasoning about generalization via conditional mutual information,
T. Steinke and L. Zakynthinou, “Reasoning about generalization via conditional mutual information,” in Conference on Learning Theory. PMLR, 2020, pp. 3437–3452
work page 2020
-
[11]
M. Haghifam, J. Negrea, A. Khisti, D. M. Roy, and G. K. Dziugaite, “Sharpened generalization bounds based on conditional mutual information and an application to noisy, iterative algorithms,” Advances in Neural Information Processing Systems, vol. 33, pp. 9925–9935, 2020
work page 2020
-
[12]
Individually conditional individual mutual information bound on generalization error,
R. Zhou, C. Tian, and T. Liu, “Individually conditional individual mutual information bound on generalization error,” IEEE Transactions on Information Theory, vol. 68, no. 5, pp. 3304–3316, 2022
work page 2022
-
[13]
On leave-one-out conditional mutual information for generalization,
M. R. Rammal, A. Achille, A. Golatkar, S. Diggavi, and S. Soatto, “On leave-one-out conditional mutual information for generalization,” Advances in Neural Information Processing Systems, vol. 35, pp. 10 179–10 190, 2022
work page 2022
-
[14]
Understanding generalization via leave-one-out conditional mutual information,
M. Haghifam, S. Moran, D. M. Roy, and G. K. Dziugiate, “Understanding generalization via leave-one-out conditional mutual information,” in 2022 IEEE International Symposium on Information Theory (ISIT). IEEE, 2022, pp. 2487–2492
work page 2022
-
[15]
A new family of generalization bounds using samplewise evaluated cmi,
F. Hellström and G. Durisi, “A new family of generalization bounds using samplewise evaluated cmi,” Advances in Neural Information Processing Systems, vol. 35, pp. 10 108–10 121, 2022
work page 2022
-
[16]
Tighter information-theoretic generalization bounds from supersamples,
Z. Wang and Y. Mao, “Tighter information-theoretic generalization bounds from supersamples,” in International Conference on Machine Learning. PMLR, 2023, pp. 36 111–36 137
work page 2023
-
[17]
Exactly tight information-theoretic generalization bounds via binary jensen-shannon divergence,
Y. Dong, H. Guo, T. Gong, W. Wen, and C. Li, “Exactly tight information-theoretic generalization bounds via binary jensen-shannon divergence,” in Forty-second International Conference on Machine Learning
- [18]
-
[19]
Fast rate information-theoretic bounds on generalization errors,
X. Wu, J. H. Manton, U. Aickelin, and J. Zhu, “Fast rate information-theoretic bounds on generalization errors,” IEEE Transactions on Information Theory, 2025
work page 2025
-
[20]
A PAC-Bayesian Tutorial with A Dropout Bound
D. McAllester, “A pac-bayesian tutorial with a dropout bound,” arXiv preprint arXiv:1307.2118, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[21]
Comparing comparators in generalization bounds,
F. Hellström and B. Guedj, “Comparing comparators in generalization bounds,” in International Conference on Artificial Intelligence and Statistics. PMLR, 2024, pp. 73–81
work page 2024
-
[22]
Error probability analysis of binary asymmetric channels,
S. M. Moser, P.-N. Chen, and H.-Y. Lin, “Error probability analysis of binary asymmetric channels,” Dept. El. & Comp. Eng., Nat. Chiao Tung Univ, 2009
work page 2009
-
[23]
Concentration of measure inequalities in information theory, communications, and coding,
M. Raginsky, I. Sason et al., “Concentration of measure inequalities in information theory, communications, and coding,” Foundations and Trends® in Communications and Information Theory, vol. 10, no. 1-2, pp. 1–246, 2013
work page 2013
-
[24]
The bounded difference inequality,
C. Scott, “The bounded difference inequality,” https://web.eecs.umich.edu/~cscott/past_courses/eecs598w14/notes/09_bounded_dif ference.pdf, [Online]
-
[25]
Y. Polyanskiy and Y. Wu, Information theory: From coding to learning. Cambridge university press, 2025
work page 2025
-
[26]
Roch, Modern discrete probability: An essential toolkit
S. Roch, Modern discrete probability: An essential toolkit. Cambridge University Press, 2024
work page 2024
-
[27]
Durrett, Probability: theory and examples
R. Durrett, Probability: theory and examples. Cambridge university press, 2019, vol. 49
work page 2019
-
[28]
The theory of error-correcting codes,
F. MacWilliams, “The theory of error-correcting codes,” Elsevier Science Publishers BV google schola, vol. 2, pp. 39–47, 1977. 20 Appendix I Prerequisite Lemmas Lemma 5 (Hoeffding’s Lemma [ 23, Lemma 2.2.1]). Let X be a random variable, such that X ∈ [a, b] almost surely for some finite constants a ≤ b. Then, for all λ ∈ R, E h eλ(X−E[X]) i ≤ e− λ2 (b−a)2...
work page 1977
-
[29]
To see this, we next prove lim m→∞ I(W ; ˆZ[n+m]) = 0 . Using the tower property of conditional expectation and the fact that U[n] ⊥ ⊥ˆZ[n+m], we get PW | ˆZ[n+m] (w|ˆz[n+m]) = EU[n] h PW | ˆZ[n+m],U[n] (w|ˆz[n+m], U[n]) i = 1 n+m kn k k X u[n] PW | ˆZ[n+m],U[n] (w|ˆz[n+m], u[n]) = 1 n+m kn k k X u[n] PW |Z[n] (w|ˆzu[n] ). (108) Let gw : Z n+m → [0, 1] be...
-
[30]
Proof of ( 54): First, by the property of dKL, we get dKL bLn n n + m bLn + m n + m Lµ (a) = sup γ dγ bLn n n + m bLn + m n + m Lµ (52),(53) = sup γ dγ 0 BB@ 1 k kX i=1 EΛ(i) [ n+m k ] ,U (i) [ n k ] 2 664 k n X j∈U (i) [ n k ] Λ(i) j 3 775 1 k kX i=1 EΛ(i) [ n+m k ] ,U (i) [ n k ] 2 4 k n + m n+m kX j=1 Λ(i) j 3 5 1 CCA (b) ≤ sup γ 1 k kX i=1 EΛ(i) [ n+m...
-
[31]
Proof of ( 55): First, following the same way as it did for ( 128) and ( 129), ( 52) and ( 53) are further simplified as bLn = 1 n + m kX i=1 n+m kX j=1 EΛ(i) j |T (i) j =1 h Λ(i) j i (160) Lµ = 1 n + m kX i=1 n+m kX j=1 EΛ(i) j |T (i) j =0 h Λ(i) j i . (161) Applying Jensen’s inequality on the convex function dKL(·∥·), it follows that dKL bLn n n + m bLn...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.