MTR-Suite: A Framework for Evaluating and Synthesizing Conversational Retrieval Benchmarks
Pith reviewed 2026-05-21 05:32 UTC · model grok-4.3
The pith
MTR-Suite introduces an LLM-based framework to audit and synthesize conversational retrieval benchmarks that capture real production challenges.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that MTR-Suite, featuring MTR-Eval for quantifying alignment gaps, MTR-Pipeline for multi-agent greedy traversal clustering to generate dialogues at 1/400th human cost, and MTR-Bench that mimics production-style challenges, provides a rigorous general-domain benchmark with superior discriminative power.
What carries the argument
MTR-Pipeline, the multi-agent system that uses greedy traversal clustering to synthesize high-fidelity dialogues reflecting real user behavior.
Load-bearing premise
The assumption that LLM-based auditing and multi-agent greedy traversal clustering produce high-fidelity dialogues that accurately reflect real user behavior without substantial human validation or bias from the underlying models.
What would settle it
Human evaluation comparing the topic switching patterns and verbosity in MTR-Bench dialogues to those observed in actual production user interactions with RAG systems.
Figures



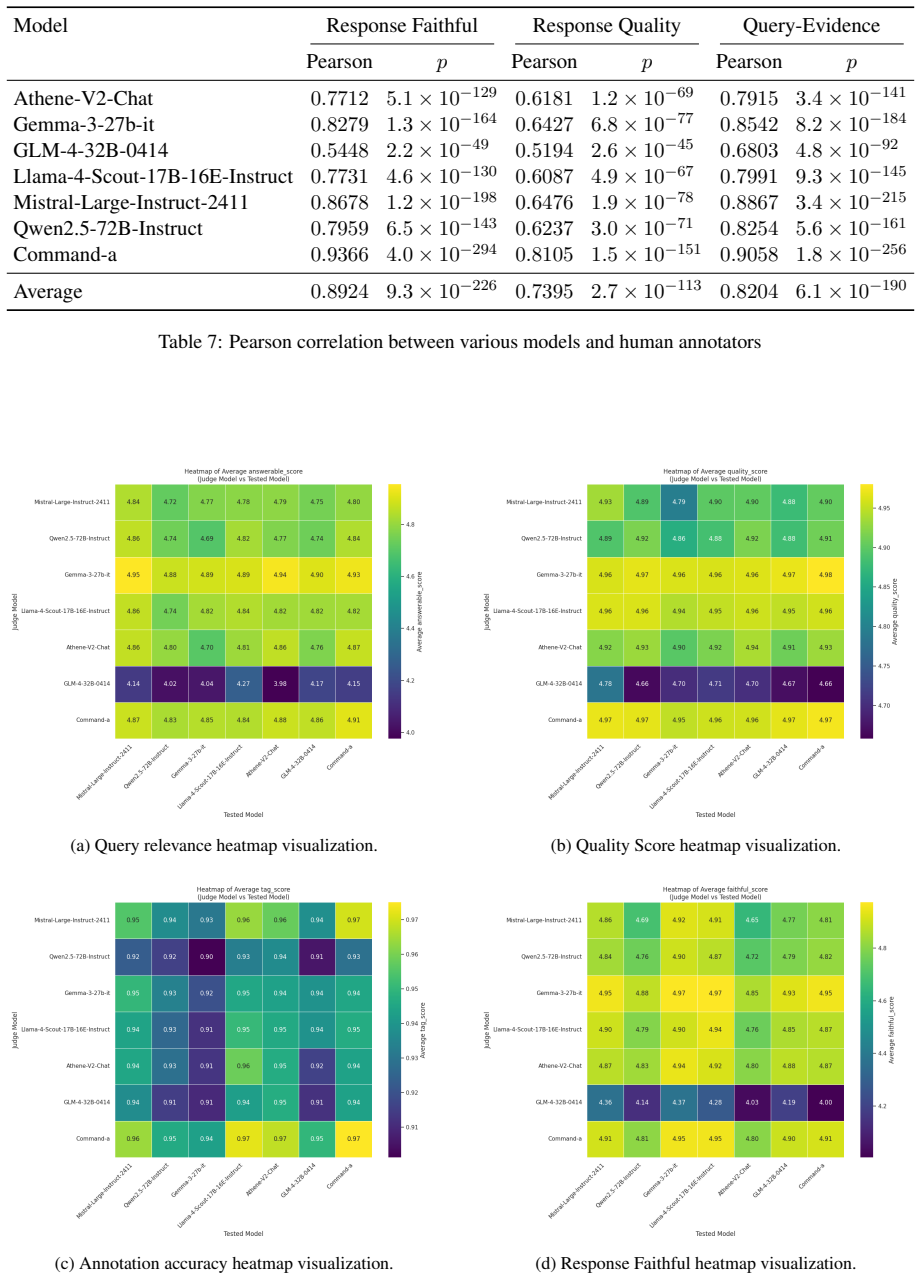
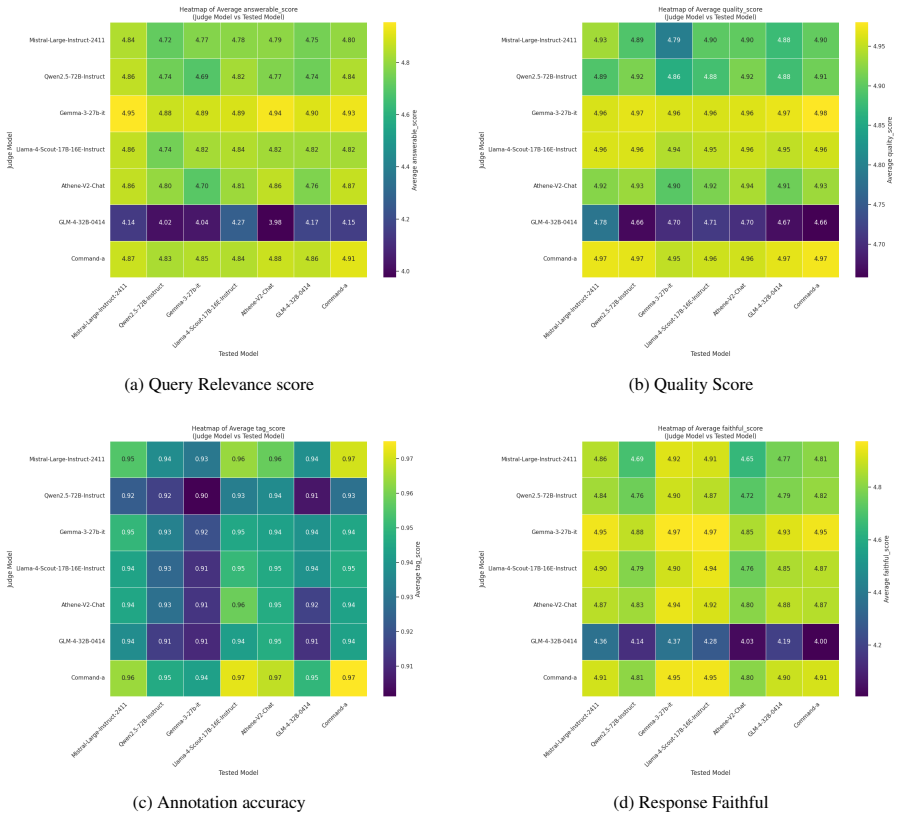

read the original abstract
Accurate evaluation of conversational retrieval is pivotal for advancing Retrieval-Augmented Generation (RAG) systems. However, existing conversational retrieval benchmarks suffer from costly, sparse human annotation or rigid, unnatural automated heuristics. To address these challenges, we introduce MTR-Suite, a unified framework for auditing, synthesizing, and benchmarking retrieval. It features: (1) MTR-Eval, an LLM-based auditor quantifying alignment gaps in previous benchmarks; (2) MTR-Pipeline, a multi-agent system using greedy traversal clustering to generate high-fidelity dialogues at 1/400th human cost; and (3) MTR-Bench, a rigorous general-domain benchmark. MTR-Bench mimics production-style challenges (hard topic switching, verbosity), offering superior discriminative power. We make our code and data publicly available to facilitate future research at https://github.com/rangehow/mtr-suite.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MTR-Suite, a unified framework for auditing, synthesizing, and benchmarking conversational retrieval. It comprises MTR-Eval (an LLM-based auditor to quantify alignment gaps in prior benchmarks), MTR-Pipeline (a multi-agent system employing greedy traversal clustering to synthesize dialogues at 1/400th human cost), and MTR-Bench (a new general-domain benchmark designed to replicate production challenges such as hard topic switching and verbosity, with claimed superior discriminative power). Code and data are released publicly.
Significance. If the fidelity and discriminative-power claims hold after validation, the framework could meaningfully reduce annotation costs while improving benchmark realism for conversational retrieval evaluation in RAG systems. The public release of code and data is a clear strength that supports reproducibility.
major comments (3)
- [Abstract and §4] Abstract and §4 (MTR-Pipeline description): the 1/400th human-cost claim is presented without quantitative breakdown, timing data, or comparison table, which is load-bearing for the practicality argument.
- [§3.2 and §5] §3.2 (auditor validation) and §5 (discriminative-power experiments): no human validation, inter-annotator agreement, or side-by-side ratings against real production logs are reported for the LLM auditor or generated dialogues; this directly undermines the claim that MTR-Bench offers superior discriminative power due to authentic fidelity rather than synthetic artifacts.
- [§5] §5 (results): the superior discriminative power is asserted but no statistical tests, effect sizes, or cross-retriever significance comparisons are shown to support it over existing benchmarks.
minor comments (2)
- [§3.1] Notation for the greedy traversal clustering algorithm could be clarified with a pseudocode listing or explicit definition of the traversal objective.
- [Abstract] The abstract states 'rigorous general-domain benchmark' without specifying the number of dialogues, topics, or retrieval models evaluated in MTR-Bench.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each of the major comments point by point below, indicating the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (MTR-Pipeline description): the 1/400th human-cost claim is presented without quantitative breakdown, timing data, or comparison table, which is load-bearing for the practicality argument.
Authors: We agree that a quantitative breakdown would strengthen the practicality argument. In the revised version, we will add a table in §4 comparing the costs, including timing data for the multi-agent synthesis process versus estimated human annotation efforts, to substantiate the 1/400th cost claim. revision: yes
-
Referee: [§3.2 and §5] §3.2 (auditor validation) and §5 (discriminative-power experiments): no human validation, inter-annotator agreement, or side-by-side ratings against real production logs are reported for the LLM auditor or generated dialogues; this directly undermines the claim that MTR-Bench offers superior discriminative power due to authentic fidelity rather than synthetic artifacts.
Authors: This is a valid concern. While our current validation relies on automated metrics and alignment with production challenges, we will incorporate human validation for a subset of the data in the revision. Specifically, we will report inter-annotator agreement scores and include qualitative side-by-side comparisons with real production logs to better support the fidelity and discriminative power claims. revision: yes
-
Referee: [§5] §5 (results): the superior discriminative power is asserted but no statistical tests, effect sizes, or cross-retriever significance comparisons are shown to support it over existing benchmarks.
Authors: We will revise §5 to include appropriate statistical tests (e.g., paired significance tests), effect sizes, and cross-retriever comparisons to rigorously demonstrate the superior discriminative power of MTR-Bench over existing benchmarks. revision: yes
Circularity Check
No circularity; framework introduces independent components without self-referential reductions
full rationale
The paper introduces MTR-Suite with three new elements: MTR-Eval (LLM auditor), MTR-Pipeline (multi-agent greedy traversal for dialogue synthesis), and MTR-Bench (new benchmark mimicking topic switching and verbosity). No equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or description that reduce claims to inputs by construction. Superior discriminative power is asserted from the benchmark design itself rather than derived tautologically. This matches the reader's assessment of no evident circularity and qualifies as a self-contained framework introduction against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can reliably quantify alignment gaps between benchmarks and real production needs
- domain assumption Greedy traversal clustering in a multi-agent system produces high-fidelity dialogues comparable to human annotation
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MTR-PIPELINE, a multi-agent system using greedy traversal clustering to generate high-fidelity dialogues at 1/400th human cost
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MTR-BENCH mimics production-style challenges (hard topic switching, verbosity), offering superior discriminative power
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Coral: Benchmarking multi-turn conversa- tional retrieval-augmentation generation.Preprint, arXiv:2410.23090. Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anasta- sios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael Jordan, Joseph E. Gonzalez, and Ion Stoica. 2024. Chatbot arena: An open platform for evaluating llms by human pre...
-
[2]
The faiss library.Preprint, arXiv:2401.08281. Song Feng, Hui Wan, Chulaka Gunasekara, Siva Patel, Sachindra Joshi, and Luis Lastras. 2020. doc2dial: A goal-oriented document-grounded dialogue dataset. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 8118–8128, Online. Association for Computa- tional L...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[3]
Multi-document grounded multi-turn synthetic dialog generation.Preprint, arXiv:2409.11500. Lewis and 1 others. 2020. Retrieval-augmented gen- eration for knowledge-intensive nlp tasks. InAd- vances in Neural Information Processing Systems, volume 33, pages 9459–9474. Curran Associates, Inc. Chaofan Li, MingHao Qin, Shitao Xiao, Jianlyu Chen, Kun Luo, Ying...
-
[4]
Making text embedders few-shot learners. Preprint, arXiv:2409.15700. Sheng-Chieh Lin, Akari Asai, Minghan Li, Barlas Oguz, Jimmy Lin, Yashar Mehdad, Wen tau Yih, and Xilun Chen. 2023. How to train your dragon: Diverse augmentation towards generalizable dense retrieval. Preprint, arXiv:2302.07452. Zihan Liu, Wei Ping, Rajarshi Roy, Peng Xu, Chankyu Lee, Mo...
-
[5]
ChatQA: Surpassing GPT-4 on conversational QA and RAG. InThe Thirty-eighth Annual Confer- ence on Neural Information Processing Systems. Llama and 1 others. 2024. The llama 3 herd of models. Preprint, arXiv:2407.21783. Yu Meng, Mengzhou Xia, and Danqi Chen. 2024. Simpo: Simple preference optimization with a reference-free reward. InAdvances in Neural In- ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Direct preference optimization: Your lan- guage model is secretly a reward model.Preprint, arXiv:2305.18290. Siva Reddy, Danqi Chen, and Christopher D. Manning
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
CoQA: A conversational question answering challenge.Transactions of the Association for Com- putational Linguistics, 7:249–266. Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettle- moyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach themselves to use tools. InAdvances in...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Fully automated benchmark synthesis for con- versational retrieval remains a challenging open problem, and quality assurance mech- anisms are essential
-
[9]
MTR-EVALcan serve as an effective and ac- tionable diagnostic tool, facilitating iterative improvement of benchmark quality across re- search groups. A.3 Case Study on Annotation Cognition Boundaries Human annotation is inherently limited by a "Cog- nition Boundary." Annotators typically formulate queries based on the specific document they are reading at...
work page 1980
-
[10]
and other comprehensive evaluation re- sults, we selected seven SOTA open-source LLMs for our study. Due to hardware resource lim- itations, models such as DeepSeek-V3/R1 and 3langchain doc: Recursively split by character Dataset Query Annotated Evidence (Gold) Alternative Valid Evidence (Re- trieved) QReCC Tell me about the types of irregular heart beat....
-
[11]
and Doc2Dial (Feng et al., 2020). While QReCC did not disclose specific costs, Doc2Dial utilized the Appen.com crowdsourcing platform, reporting a cost of $1.50–$2.00 per annotated di- alogue. It is noteworthy that Doc2Dial dialogues are, on average, shorter and less verbose than those generated in our work. We estimate the generation cost using the pric-...
work page 2020
-
[12]
Can be directly answered by ONLY ONE specific document
-
[13]
Sounds like a human question (don’t mention the document)
-
[14]
Do not mention any document names or source information in your response
Starts with the corresponding [Document ID] Format: [Document ID] Your question here Here is an example: {SEED} Here is the real user input: **Documents:** {DOCUMENTS} Table 12: Questioner Prompt RESPONSE Based on the provided documents (and considering previous conversation, if applicable), think step-by-step and provide a detailed and complete answer to...
-
[15]
**Naturalness:** It should flow smoothly and sound like spontaneous human speech
-
[16]
**Incorporate Conversational Features:** * **Coreference:** Use pronouns (e.g., "it," "they," "that one") or other referring expressions where appropriate, leveraging the context from the preceding dialogue turns. * **Ellipsis:** Omit words or phrases that are easily understood from the context (e.g., "What about Paris?" instead of "What is the weather fo...
-
[17]
The rewritten query MUST retain the exact original intent and meaning of the original query
**Meaning Preservation:** This is CRUCIAL. The rewritten query MUST retain the exact original intent and meaning of the original query. Do not add new information, change the core question, or introduce ambiguity that wasn’t there. Ensure the rewritten query seeks the same information or performs the same function as the original. **Example:** [USER]: Wha...
-
[18]
It is one of the most recognizable structures globally and stands 330 meters tall
The Eiffel Tower, located in Paris, France, was completed in 1889 for the World’s Fair. It is one of the most recognizable structures globally and stands 330 meters tall. Gustave Eiffel’s company designed and built the tower. —
-
[19]
It was dedicated on October 28, 1886
The Statue of Liberty, a gift from France to the United States, stands on Liberty Island in New York Harbor. It was dedicated on October 28, 1886. It represents Libertas, the Roman goddess of freedom. —
-
[20]
Gustave Eiffel’s company designed and built the tower
Big Ben is the nickname for the Great Bell of the striking clock at the north end of the Palace of Westminster in London, UK. The tower housing the clock is officially named the Elizabeth Tower. It was completed in 1859. **Question:** Who designed the Eiffel Tower? **Justification:** Document [1] is the only document that discusses the Eiffel Tower and ex...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.