VACE: Learning Geometrically Structured Representations for Time Series Anomaly Detection
Pith reviewed 2026-05-25 05:08 UTC · model grok-4.3
The pith
VACE shapes time series embeddings into compact directionally coherent regions using velocity consistency to detect anomalies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VACE trains a channel-aware encoder through a velocity-consistency objective, with no negatives and no synthetic anomalies, so that normal trajectories are locally smooth and aligned. At test time, a Mahalanobis positional score and a velocity-bank directional score are combined multiplicatively, flagging points that are simultaneously off-distribution and dynamically atypical.
What carries the argument
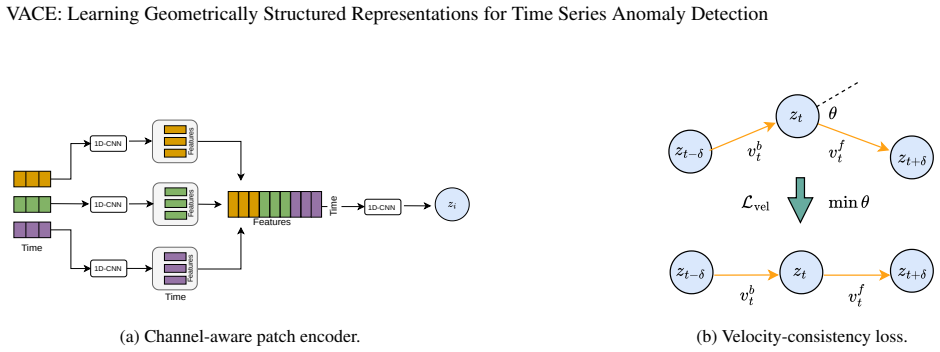
The velocity-consistency objective, which aligns the direction of movement between consecutive embeddings of normal data to create a directionally coherent normal region.
If this is right
- Time series anomaly detection does not require contrastive pair sampling or anomaly generation to achieve high performance.
- The geometric structure of the embedding space can be shaped directly to support distance-based and direction-based scoring.
- Simple objectives can outperform complex methods even when the latter use larger training budgets.
- Channel-aware encoding helps capture multivariate dependencies in the velocity alignment.
Where Pith is reading between the lines
- If velocity consistency produces coherent regions, similar consistency objectives might improve representation learning in other sequential data tasks like forecasting.
- The multiplicative scoring suggests that anomalies must violate both positional and directional normality, which could be tested by ablating each score separately.
- Since no negatives are used, the method might generalize to settings where generating negatives is difficult or biased.
Load-bearing premise
Enforcing velocity consistency on normal trajectories alone will create an embedding space where anomalies deviate clearly in both position and velocity direction.
What would settle it
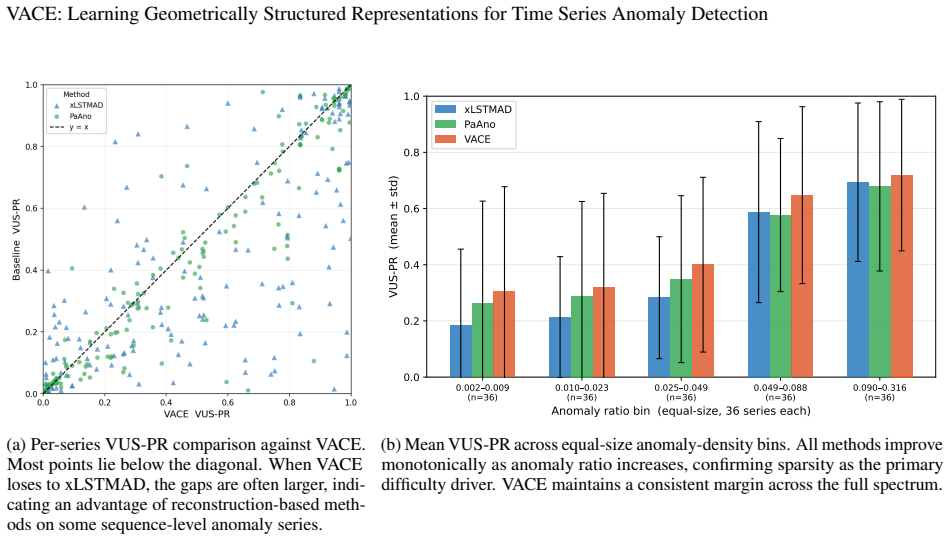
Running VACE on the TSB-AD-M dataset and finding that its performance does not exceed that of the more complex baseline methods under the same rigorous evaluation protocol.
Figures



read the original abstract
Anomaly detection in multivariate time series is a critical task across a wide range of real-world applications, where abnormal behaviour is rare, labels are unavailable, and the cost of a miss is high. The central challenge is learning a characterisation of normality precise enough to flag deviations. Representation self-supervised learning, typically through contrastive approaches, addresses this by embedding temporal patches into a latent space where normality occupies a well-defined region, with anomalies detected by geometric deviation. However, contrastive approaches shape this space indirectly through pair-sampling heuristics, providing no explicit control over the geometric structure that distance-based scoring requires. This means how tightly normal representations are grouped, and whether distances are directionally meaningful. We present VACE (Velocity-Aligned Channel Embeddings), a self-supervised anomaly detection method that represents normality as a compact, directionally coherent region in the embedding space. To this end, VACE trains a channel-aware encoder through a velocity-consistency objective, with no negatives and no synthetic anomalies, so that normal trajectories are locally smooth and aligned. At test time, a Mahalanobis positional score and a velocity-bank directional score are combined multiplicatively, flagging points that are simultaneously off-distribution and dynamically atypical. Despite its simplicity, VACE achieves state-of-the-art performance on TSB-AD-M under rigorous evaluation, significantly outperforming more complex methods trained on substantially larger budgets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VACE, a self-supervised anomaly detection method for multivariate time series. It trains a channel-aware encoder with a velocity-consistency objective (no negatives, no synthetic anomalies) to produce embeddings where normal trajectories are locally smooth and aligned, forming a compact, directionally coherent region. At test time, anomalies are flagged by the product of a Mahalanobis positional score and a velocity-bank directional score. The central empirical claim is state-of-the-art performance on the TSB-AD-M benchmark under rigorous evaluation, outperforming more complex methods trained with substantially larger budgets.
Significance. If the results hold under the claimed evaluation protocol, the work is significant because it demonstrates that an explicit velocity-alignment signal, without contrastive repulsion, can produce geometrically structured representations sufficient for competitive distance-based anomaly detection. This provides a simpler, lower-budget alternative to contrastive approaches and directly targets the geometric properties (compactness and directional coherence) required by the scoring functions.
major comments (2)
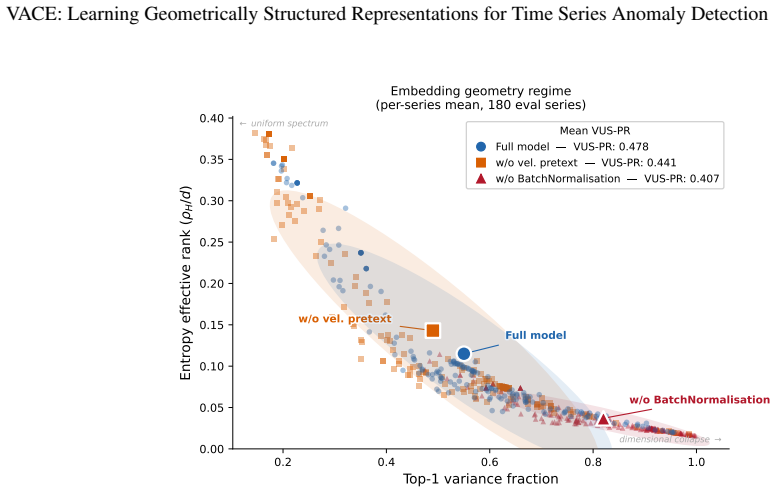
- [§3.2] §3.2 (velocity-consistency objective): the claim that this loss alone produces a compact normal region whose covariance supports reliable Mahalanobis scoring is load-bearing for the method. The loss contains no explicit variance-regularization or anti-collapse term, and the manuscript provides no auxiliary analysis (e.g., eigenvalue spectra of the fitted covariance on normal data or embedding-norm histograms) showing that the resulting distribution is sufficiently ellipsoidal rather than collapsed or isotropic.
- [Table 3, §5.3] Table 3 and §5.3 (TSB-AD-M results): the reported SOTA margins are presented without per-dataset standard deviations across random seeds or statistical significance tests against the strongest baselines. Given that the central claim attributes superiority to the geometric structure rather than implementation details, these statistics are necessary to establish that the gains are robust and not attributable to a single favorable run or post-hoc hyperparameter choice.
minor comments (2)
- [§4.1] Notation for the velocity-bank score is introduced without an explicit equation reference in the main text; adding a numbered equation would improve traceability when the multiplicative combination is later defined.
- [Abstract] The abstract states 'rigorous evaluation' but does not enumerate the protocol (e.g., fixed splits, no test-set tuning). A one-sentence clarification in the introduction would help readers locate the corresponding experimental details.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below.
read point-by-point responses
-
Referee: [§3.2] §3.2 (velocity-consistency objective): the claim that this loss alone produces a compact normal region whose covariance supports reliable Mahalanobis scoring is load-bearing for the method. The loss contains no explicit variance-regularization or anti-collapse term, and the manuscript provides no auxiliary analysis (e.g., eigenvalue spectra of the fitted covariance on normal data or embedding-norm histograms) showing that the resulting distribution is sufficiently ellipsoidal rather than collapsed or isotropic.
Authors: We agree that additional empirical validation of the embedding geometry would strengthen the manuscript. In the revised version we will include eigenvalue spectra of the covariance estimated on normal embeddings together with embedding-norm histograms, confirming that the learned distribution remains compact and ellipsoidal rather than collapsed or isotropic. revision: yes
-
Referee: [Table 3, §5.3] Table 3 and §5.3 (TSB-AD-M results): the reported SOTA margins are presented without per-dataset standard deviations across random seeds or statistical significance tests against the strongest baselines. Given that the central claim attributes superiority to the geometric structure rather than implementation details, these statistics are necessary to establish that the gains are robust and not attributable to a single favorable run or post-hoc hyperparameter choice.
Authors: We acknowledge that reporting variability and significance strengthens the central empirical claim. We will rerun all experiments with multiple random seeds, add per-dataset standard deviations to Table 3, and include statistical significance tests (e.g., paired Wilcoxon tests) against the strongest baselines in §5.3 of the revision. revision: yes
Circularity Check
No circularity: method defines its own objective and scores with no reduction of claims to inputs by construction
full rationale
The provided abstract and context contain no equations, fitting procedures, or self-citations. VACE is defined by its velocity-consistency objective (no negatives, no synthetic anomalies) and the subsequent multiplicative combination of Mahalanobis positional and velocity-bank scores. These are presented as design choices that produce the desired geometric structure, with SOTA performance reported as an empirical outcome on TSB-AD-M rather than a first-principles derivation or prediction that reduces to the inputs. No load-bearing step equates a claimed result to a fitted quantity or self-citation chain. This is the common case of a self-contained empirical method whose central claims do not collapse by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
velocity-consistency objective ... normal trajectories are locally smooth and aligned ... piecewise linear ... Lvel = 1/N Σ (1 − ⟨vb_t , vf_t ⟩)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Detecting spacecraft anomalies using lstms and nonparametric dynamic thresholding
Kyle Hundman, Valentino Constantinou, Christopher Laporte, Ian Colwell, and Tom Soderstrom. Detecting spacecraft anomalies using lstms and nonparametric dynamic thresholding. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, pages 387–395, 2018
work page 2018
-
[2]
Scott David Greenwald, Ramesh S Patil, and Roger G Mark.Improved detection and classification of arrhythmias in noise-corrupted electrocardiograms using contextual information. IEEE, 1990. 9 V ACE: Learning Geometrically Structured Representations for Time Series Anomaly Detection
work page 1990
-
[3]
Anomaly detection in time series: a comprehensive evaluation
Sebastian Schmidl, Phillip Wenig, and Thorsten Papenbrock. Anomaly detection in time series: a comprehensive evaluation. 2022
work page 2022
-
[4]
Ane Blázquez-García, Angel Conde, Usue Mori, and Jose A Lozano. A review on outlier/anomaly detection in time series data.ACM computing surveys (CSUR), 54(3):1–33, 2021
work page 2021
-
[5]
Representation learning: A review and new perspectives
Yoshua Bengio, Aaron Courville, and Pascal Vincent. Representation learning: A review and new perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(8):1798–1828, 2013
work page 2013
-
[6]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational conference on machine learning, pages 1597–1607. PMLR, 2020
work page 2020
-
[7]
PaAno: Patch-based representation learning for time-series anomaly detection
Jinju Park and Seokho Kang. PaAno: Patch-based representation learning for time-series anomaly detection. International Conference on Learning Representations, 2026
work page 2026
-
[8]
Zahra Zamanzadeh Darban, Geoffrey I Webb, Shirui Pan, Charu C Aggarwal, and Mahsa Salehi. Carla: Self- supervised contrastive representation learning for time series anomaly detection.Pattern Recognition, 157:110874, 2025
work page 2025
-
[9]
Self-supervised visual feature learning with deep neural networks: A survey
Longlong Jing and Yingli Tian. Self-supervised visual feature learning with deep neural networks: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(11):4037–4058, 2020
work page 2020
-
[10]
Tongzhou Wang and Phillip Isola. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. InProceedings of the 37th International Conference on Machine Learning, pages 9929–9939. PMLR, 2020
work page 2020
-
[11]
Ts2vec: Towards universal representation of time series
Zhihan Yue, Yujing Wang, Juanyong Duan, Tianmeng Yang, Congrui Huang, Yunhai Tong, and Bixiong Xu. Ts2vec: Towards universal representation of time series. InProceedings of the AAAI conference on artificial intelligence, volume 36, pages 8980–8987, 2022
work page 2022
-
[12]
Understanding contrastive learning requires incorporating inductive biases
Nikunj Saunshi, Jordan Ash, Surbhi Goel, Dipendra Misra, Cyril Zhang, Sanjeev Arora, Sham Kakade, and Akshay Krishnamurthy. Understanding contrastive learning requires incorporating inductive biases. InProceedings of the 39th International Conference on Machine Learning, pages 19250–19286. PMLR, 2022
work page 2022
-
[13]
Jiahao Yu, Xin Gao, Feng Zhai, Baofeng Li, Bing Xue, Shiyuan Fu, Lingli Chen, and Zhihang Meng. An adversarial contrastive autoencoder for robust multivariate time series anomaly detection.Expert Systems with Applications, 245:123010, 2024
work page 2024
-
[14]
Xin Xie, Kexuan Liu, Ying Wang, Mengqi Wu, Huichaoyi Zhang, and Tao Wan. CAAE: Contrastive adversarial autoencoder for multivariate time series anomaly detection.Pattern Recognition, page 113687, 2026
work page 2026
-
[15]
Qinghua Liu and John Paparrizos. The elephant in the room: Towards a reliable time-series anomaly detection benchmark.Advances in Neural Information Processing Systems, 37:108231–108261, 2024
work page 2024
-
[16]
Deep learning for time series anomaly detection: A survey.ACM Computing Surveys, 57(1):1–42, 2024
Zahra Zamanzadeh Darban, Geoffrey I Webb, Shirui Pan, Charu Aggarwal, and Mahsa Salehi. Deep learning for time series anomaly detection: A survey.ACM Computing Surveys, 57(1):1–42, 2024
work page 2024
-
[17]
David E Rumelhart, James L McClelland, PDP Research Group, et al.Parallel distributed processing, volume 1: Explorations in the microstructure of cognition: Foundations. The MIT press, 1986
work page 1986
-
[18]
Long short-term memory.Neural computation, 9(8):1735–1780, 1997
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory.Neural computation, 9(8):1735–1780, 1997
work page 1997
-
[19]
Mohsin Munir, Shoaib Ahmed Siddiqui, Andreas Dengel, and Sheraz Ahmed. Deepant: A deep learning approach for unsupervised anomaly detection in time series.IEEE access, 7:1991–2005, 2018
work page 1991
-
[20]
Lag-Llama: Towards foundation models for time series forecasting
Kashif Rasul, Arjun Ashok, Andrew Robert Williams, Arian Khorasani, George Adamopoulos, Rishika Bhag- watkar, Marin Biloš, Hena Ghonia, Nadhir Hassen, Anderson Schneider, Sahil Garg, Alexandre Drouin, Nicolas Chapados, Yuriy Nevmyvaka, and Irina Rish. Lag-Llama: Towards foundation models for time series forecasting. InR0-FoMo:Robustness of Few-shot and Ze...
work page 2023
-
[21]
A decoder-only foundation model for time-series forecasting
Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou. A decoder-only foundation model for time-series forecasting. InProceedings of the 41st International Conference on Machine Learning, pages 10148–10167. PMLR, 2024
work page 2024
-
[22]
Abdul Fatir Ansari, Lorenzo Stella, Ali Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebastian Pineda Arango, Shubham Kapoor, Jasper Zschiegner, Danielle C. Maddix, Hao Wang, Michael W. Mahoney, Kari Torkkola, Andrew Gordon Wilson, Michael Bohlke-Schneider, and Bernie Wang. Chronos: Learning the langu...
work page 2024
-
[23]
xlstmad: A powerful xlstm-based method for anomaly detection
Kamil Faber, Marcin Pietron, Dominik Zurek, and Roberto Corizzo. xlstmad: A powerful xlstm-based method for anomaly detection. In2025 IEEE International Conference on Data Mining (ICDM), pages 247–256. IEEE, 2025. 10 V ACE: Learning Geometrically Structured Representations for Time Series Anomaly Detection
work page 2025
-
[24]
xLSTM: Extended long short-term memory
Maximilian Beck, Korbinian Pöppel, Markus Spanring, Andreas Auer, Oleksandra Prudnikova, Michael Kopp, Günter Klambauer, Johannes Brandstetter, and Sepp Hochreiter. xLSTM: Extended long short-term memory. Advances in Neural Information Processing Systems, 37:107547–107603, 2024
work page 2024
-
[25]
KAN-AD: Time series anomaly detection with kolmogorov–arnold networks
Quan Zhou, Changhua Pei, Fei Sun, Han Jing, Zhengwei Gao, Haiming Zhang, Gaogang Xie, Dan Pei, and Jianhui Li. KAN-AD: Time series anomaly detection with kolmogorov–arnold networks. InProceedings of the 42nd International Conference on Machine Learning, pages 79136–79149. PMLR, 2025
work page 2025
-
[26]
USAD: Unsupervised anomaly detection on multivariate time series
Julien Audibert, Pietro Michiardi, Frédéric Guyard, Sébastien Marti, and Maria A Zuluaga. USAD: Unsupervised anomaly detection on multivariate time series. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, pages 3395–3404, 2020
work page 2020
-
[27]
Robust anomaly detection for multivariate time series through stochastic recurrent neural network
Ya Su, Youjian Zhao, Chenhao Niu, Rong Liu, Wei Sun, and Dan Pei. Robust anomaly detection for multivariate time series through stochastic recurrent neural network. InProceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, pages 2828–2837, 2019
work page 2019
-
[28]
Beatgan: Anomalous rhythm detection using adversarially generated time series
Bin Zhou, Shenghua Liu, Bryan Hooi, Xueqi Cheng, and Jing Ye. Beatgan: Anomalous rhythm detection using adversarially generated time series. InIJCAI, volume 2019, pages 4433–4439, 2019
work page 2019
-
[29]
Anomaly Transformer: Time series anomaly detection with association discrepancy
Jiehui Xu, Haixu Wu, Jianmin Wang, and Mingsheng Long. Anomaly Transformer: Time series anomaly detection with association discrepancy. InInternational Conference on Learning Representations, 2021
work page 2021
-
[30]
TimesNet: Temporal 2d-variation modeling for general time series analysis
Haixu Wu, Tengge Hu, Yong Liu, Hang Zhou, Jianmin Wang, and Mingsheng Long. TimesNet: Temporal 2d-variation modeling for general time series analysis. InInternational Conference on Learning Representations, 2023
work page 2023
-
[31]
MOMENT: A family of open time-series foundation models
Mononito Goswami, Konrad Szafer, Arjun Choudhry, Yifu Cai, Shuo Li, and Artur Dubrawski. MOMENT: A family of open time-series foundation models. InProceedings of the 41st International Conference on Machine Learning, pages 16115–16152. PMLR, 2024
work page 2024
-
[32]
Hao Zhou, Ke Yu, Xuan Zhang, Guanlin Wu, and Anis Yazidi. Contrastive autoencoder for anomaly detection in multivariate time series.Information Sciences, 610:266–280, 2022
work page 2022
-
[33]
A time series is worth 64 words: Long-term forecasting with transformers
Yuqi Nie, Nam H Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. A time series is worth 64 words: Long-term forecasting with transformers. InInternational Conference on Learning Representations, 2023
work page 2023
-
[34]
ModernTCN: A modern pure convolution structure for general time series analysis
Donghao Luo and Xue Wang. ModernTCN: A modern pure convolution structure for general time series analysis. InInternational Conference on Learning Representations, 2024
work page 2024
-
[35]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
Yooju Shin, Jaehyun Park, Hwanjun Song, Susik Yoon, Byung S Lee, and Jae-Gil Lee. Exploiting representation curvature for boundary detection in time series.Advances in Neural Information Processing Systems, 37: 5974–5995, 2024
work page 2024
-
[37]
The effective rank: A measure of effective dimensionality
Olivier Roy and Martin Vetterli. The effective rank: A measure of effective dimensionality. In2007 15th European Signal Processing Conference, pages 606–610. IEEE, 2007
work page 2007
-
[38]
Quentin Garrido, Randall Balestriero, Laurent Najman, and Yann Lecun. Rankme: Assessing the downstream performance of pretrained self-supervised representations by their rank. InProceedings of the 40th International Conference on Machine Learning, pages 10929–10974. PMLR, 2023
work page 2023
-
[39]
Understanding dimensional collapse in contrastive self-supervised learning
Li Jing, Pascal Vincent, Yann LeCun, and Yuandong Tian. Understanding dimensional collapse in contrastive self-supervised learning. InInternational Conference on Learning Representations, 2022
work page 2022
-
[40]
Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. A simple unified framework for detecting out-of- distribution samples and adversarial attacks.Advances in Neural Information Processing Systems, 31, 2018
work page 2018
-
[41]
Towards total recall in industrial anomaly detection
Karsten Roth, Latha Pemula, Joaquin Zepeda, Bernhard Schölkopf, Thomas Brox, and Peter Gehler. Towards total recall in industrial anomaly detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14318–14328, 2022
work page 2022
-
[42]
Local evaluation of time series anomaly detection algorithms
Alexis Huet, Jose Manuel Navarro, and Dario Rossi. Local evaluation of time series anomaly detection algorithms. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 635–645, 2022
work page 2022
-
[43]
SWaT: A water treatment testbed for research and training on ICS security
Aditya P Mathur and Nils Ole Tippenhauer. SWaT: A water treatment testbed for research and training on ICS security. InInternational Workshop on Cyber-Physical Systems for Smart Water Networks, pages 31–36. IEEE, 2016. 11 V ACE: Learning Geometrically Structured Representations for Time Series Anomaly Detection
work page 2016
-
[44]
Precision and recall for time series.Advances in Neural Information Processing Systems, 31, 2018
Nesime Tatbul, Tae Jun Lee, Stan Zdonik, Mejbah Alam, and Justin Gottschlich. Precision and recall for time series.Advances in Neural Information Processing Systems, 31, 2018
work page 2018
-
[45]
V olume under the surface: A new accuracy evaluation measure for time-series anomaly detection.Proc
John Paparrizos, Paul Boniol, Themis Palpanas, Ruey S Tsay, Aaron J Elmore, and Michael J Franklin. V olume under the surface: A new accuracy evaluation measure for time-series anomaly detection.Proc. VLDB Endow., 15 (11):2774–2787, 2022
work page 2022
-
[46]
Qichao Shentu, Beibu Li, Kai Zhao, Yang Shu, Zhongwen Rao, Lujia Pan, Bin Yang, and Chenjuan Guo. Towards a general time series anomaly detector with adaptive bottlenecks and dual adversarial decoders. InInternational Conference on Learning Representations, 2025
work page 2025
-
[47]
CrossAD: Time series anomaly detection with cross-scale associations and cross-window modeling
Beibu Li, Qichao Shentu, Yang Shu, Hui Zhang, Ming Li, Ning Jin, Bin Yang, and Chenjuan Guo. CrossAD: Time series anomaly detection with cross-scale associations and cross-window modeling. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[48]
DCDetector: Dual attention contrastive representation learning for time series anomaly detection
Yiyuan Yang, Chaoli Zhang, Tian Zhou, Qingsong Wen, and Liang Sun. DCDetector: Dual attention contrastive representation learning for time series anomaly detection. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 3033–3045, 2023
work page 2023
-
[49]
CATCH: Channel-aware multivariate time series anomaly detection via frequency patching
Xingjian Wu, Xiangfei Qiu, Zhengyu Li, Yihang Wang, Jilin Hu, Chenjuan Guo, Hui Xiong, and Bin Yang. CATCH: Channel-aware multivariate time series anomaly detection via frequency patching. InInternational Conference on Learning Representations, 2025
work page 2025
-
[50]
A novel anomaly detection scheme based on principal component classifier
Mei-Ling Shyu, Shu-Ching Chen, Kanoksri Sarinnapakorn, and LiWu Chang. A novel anomaly detection scheme based on principal component classifier. 2003
work page 2003
-
[51]
Fei Tony Liu, Kai Ming Ting, and Zhi-Hua Zhou. Isolation forest. InEighth IEEE International Conference on Data Mining, pages 413–422. IEEE, 2008
work page 2008
-
[52]
Reversible instance normalization for accurate time-series forecasting against distribution shift
Taesung Kim, Jinhee Kim, Yunwon Tae, Cheonbok Park, Jang-Ho Choi, and Jaegul Choo. Reversible instance normalization for accurate time-series forecasting against distribution shift. InInternational Conference on Learning Representations, 2022
work page 2022
-
[53]
Tspulse: Tiny pre-trained models with disentangled representations for rapid time-series analysis
Vijay Ekambaram, Subodh Kumar, Arindam Jati, Sumanta Mukherjee, Tomoya Sakai, Pankaj Dayama, Wesley M Gifford, and Jayant Kalagnanam. Tspulse: Tiny pre-trained models with disentangled representations for rapid time-series analysis. InInternational Conference on Learning Representations. 12 V ACE: Learning Geometrically Structured Representations for Time...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.