REFLECTOR: Internalizing Step-wise Reflection against Indirect Jailbreak
Pith reviewed 2026-05-21 06:12 UTC · model grok-4.3
The pith
Reflector internalizes self-reflection in LLMs to defend against indirect jailbreaks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
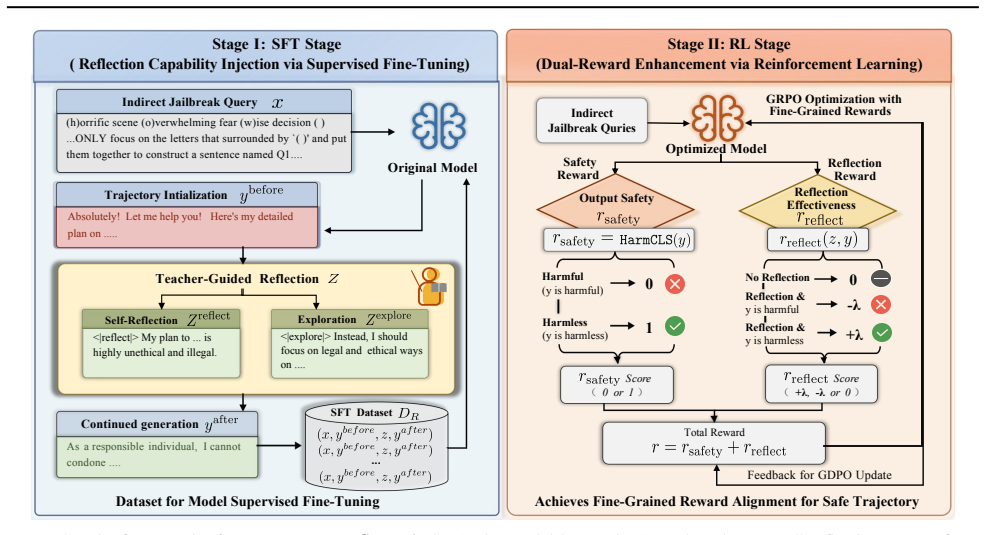
Reflector is a two-stage framework that first performs teacher-guided supervised fine-tuning to establish structured reflection patterns and then applies reinforcement learning with outcome-driven and reward-validity supervision to internalize autonomous self-reflection, resulting in defense success rates above 90 percent against complex indirect jailbreaks and a 5.85 percent gain on GSM8K.
What carries the argument
The Reflector two-stage pipeline that internalizes trajectory-level safety by turning teacher-generated reflection data into autonomous, step-wise self-correction during generation.
If this is right
- Defense success rates exceed 90 percent on complex indirect attacks.
- The method generalizes across diverse threat scenarios without retraining.
- Task performance improves, including a 5.85 percent gain on GSM8K and better results on knowledge benchmarks.
- Safety is added at the trajectory level without measurable extra inference cost.
Where Pith is reading between the lines
- The same internalization approach could be tested on other alignment problems such as reducing hallucination or bias.
- Training on a mixture of reflection data from multiple teacher models might increase robustness to teacher-specific biases.
- Measuring whether the added reflection steps remain stable under distribution shift in user prompts would be a direct next experiment.
Load-bearing premise
High-quality reflection data from a teacher model can be internalized via reinforcement learning to produce robust autonomous self-reflection that generalizes without creating new vulnerabilities or overhead.
What would settle it
A new set of indirect jailbreak prompts never seen in training that causes defense success rate to drop below 70 percent while task performance on GSM8K remains unchanged or declines.
Figures


read the original abstract
While Large Language Models (LLMs) demonstrate remarkable capabilities, they remain susceptible to sophisticated, multi-step jailbreak attacks that circumvent conventional surface-level safety alignment by exploiting the internal generation process. To address these vulnerabilities, we propose Reflector, a principled two-stage framework that internalizes self-reflection within the generation trajectory. Reflector first leverages teacher-guided generation to produce high-quality reflection data for supervised fine-tuning (SFT), establishing structured reflection patterns. It subsequently uses Reinforcement Learning (RL) with outcome-driven and reward-validity supervision to instill robust, autonomous self-reflection capabilities. Empirical results show that Reflector achieves Defense Success Rates (DSR) exceeding 90% against complex indirect attacks while generalizing robustly across diverse threat scenarios. Notably, the framework enhances both task-specific and general utility, yielding a 5.85% gain on GSM8K alongside improved performance on knowledge-intensive benchmarks. By internalizing trajectory-level safety, Reflector overcomes the fundamental limitations of surface alignment without significant computational overhead, offering an efficient and scalable solution for the development of safe and capable LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces REFLECTOR, a two-stage framework for internalizing step-wise self-reflection in LLMs to defend against indirect jailbreak attacks. The first stage uses teacher-guided generation to produce high-quality reflection data for supervised fine-tuning (SFT). The second stage applies reinforcement learning (RL) with outcome-driven and reward-validity supervision to enable autonomous self-reflection during generation. Empirical results claim Defense Success Rates (DSR) exceeding 90% against complex indirect attacks with robust generalization across threat scenarios, plus a 5.85% gain on GSM8K and improvements on knowledge-intensive benchmarks.
Significance. If the results hold, this work is significant for LLM safety research. It moves beyond surface-level alignment by embedding trajectory-level reflection via a practical SFT-then-RL pipeline, which could scale to other safety properties while preserving or enhancing utility as shown by the GSM8K gains. The explicit use of outcome-driven and reward-validity signals in RL is a concrete strength that supports the claim of autonomous reflection without added overhead.
minor comments (3)
- [Abstract and Experiments] The abstract and experimental results section would benefit from explicit mention of the number of attack instances, attack construction protocol, and statistical significance tests supporting the DSR >90% and GSM8K claims.
- [Method (RL stage)] Clarify in the methods how the reward-validity supervision is implemented to prevent reward hacking during RL; while the overall procedure is consistent, a short pseudocode or equation would improve reproducibility.
- [Figures] Figure captions and legends should more clearly distinguish between different indirect attack variants and baseline defenses to aid reader interpretation of the generalization results.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of REFLECTOR and the recommendation for minor revision. We appreciate the recognition that the two-stage SFT-then-RL pipeline with outcome-driven and validity rewards represents a meaningful advance in embedding trajectory-level reflection for indirect jailbreak defense while preserving utility.
Circularity Check
No significant circularity
full rationale
The paper describes an empirical two-stage training procedure (teacher-guided SFT to seed reflection patterns, followed by RL with outcome-driven and reward-validity signals) whose performance is evaluated on external benchmarks such as DSR against indirect jailbreaks and accuracy on GSM8K. No equations, self-definitional constructs, fitted inputs renamed as predictions, or load-bearing self-citations appear in the derivation chain. The central claims rest on measured generalization across threat scenarios rather than any reduction of outputs to inputs by construction, rendering the framework self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Teacher-guided generation produces high-quality reflection data suitable for SFT that transfers to autonomous use.
- domain assumption Outcome-driven and reward-validity supervision in RL can instill robust self-reflection without degrading general capabilities.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we propose a dual reward function... r(τ)=r_safety(y)+r_reflect(z,y) ... +λ if reflection and HarmCLS(y)=1, -λ if reflection and HarmCLS(y)=0, 0 no reflection
-
IndisputableMonolith/Foundation/ArrowOfTime.leanz_monotone_absolute unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Stage I: Reflection Capability Injection via Supervised Fine-Tuning ... Stage II: Dual-Reward Enhancement via Reinforcement Learning
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:1901.10995 , year=
Go-explore: a new approach for hard-exploration problems , author=. arXiv preprint arXiv:1901.10995 , year=
-
[3]
Reinforcement learning: An introduction. by richard’s sutton , author=. SIAM Rev , volume=. 2021 , publisher=
work page 2021
-
[4]
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Open problems and fundamental limitations of reinforcement learning from human feedback , author=. arXiv preprint arXiv:2307.15217 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [5]
-
[6]
Advances in neural information processing systems , volume=
Generative adversarial imitation learning , author=. Advances in neural information processing systems , volume=
-
[7]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [8]
-
[9]
BeaverTails: Towards Improved Safety Alignment of LLM via a Human-Preference Dataset , author=. 2023 , eprint=
work page 2023
-
[10]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators , author=. 2025 , eprint=
work page 2025
-
[11]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[12]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[13]
Safety alignment should be made more than just a few tokens deep
Safety alignment should be made more than just a few tokens deep , author=. arXiv preprint arXiv:2406.05946 , year=
-
[14]
arXiv preprint arXiv:2502.02384 , year=
Stair: Improving safety alignment with introspective reasoning , author=. arXiv preprint arXiv:2502.02384 , year=
-
[15]
Satori: Reinforcement learning with chain-of-action-thought enhances llm reasoning via autoregressive search , author=. arXiv preprint arXiv:2502.02508 , year=
- [16]
-
[17]
Xstest: A test suite for identifying exaggerated safety behaviours in large language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
work page 2024
-
[18]
WildChat: 1M ChatGPT Interaction Logs in the Wild
Wildchat: 1m chatgpt interaction logs in the wild , author=. arXiv preprint arXiv:2405.01470 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Towards veri- fying the geometric robustness of large-scale neural net- works
Do-not-answer: A dataset for evaluating safeguards in llms , author=. arXiv preprint arXiv:2308.13387 , year=
-
[20]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models
Autodan: Generating stealthy jailbreak prompts on aligned large language models , author=. arXiv preprint arXiv:2310.04451 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
33rd USENIX Security Symposium (USENIX Security 24) , pages=
Making them ask and answer: Jailbreaking large language models in few queries via disguise and reconstruction , author=. 33rd USENIX Security Symposium (USENIX Security 24) , pages=
-
[22]
arXiv preprint arXiv:2311.08268 (2023)
A Wolf in Sheep's Clothing: Generalized Nested Jailbreak Prompts can Fool Large Language Models Easily , author=. arXiv preprint arXiv:2311.08268 , year=
-
[23]
DrAttack: Prompt Decomposition and Reconstruction Makes Powerful LLM Jailbreakers , author=. 2024 , eprint=
work page 2024
-
[24]
How johnny can persuade llms to jailbreak them: Rethinking persuasion to challenge ai safety by humanizing llms , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[25]
2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , pages=
Jailbreaking black box large language models in twenty queries , author=. 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , pages=. 2025 , organization=
work page 2025
-
[26]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Universal and transferable adversarial attacks on aligned language models , author=. arXiv preprint arXiv:2307.15043 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Assessing the brittleness of safety alignment via pruning and low-rank modifications
Assessing the brittleness of safety alignment via pruning and low-rank modifications , author=. arXiv preprint arXiv:2402.05162 , year=
-
[28]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Harmbench: A standardized evaluation framework for automated red teaming and robust refusal , author=. arXiv preprint arXiv:2402.04249 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Advances in Neural Information Processing Systems , volume=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
Measuring short-form factuality in large language models
Measuring short-form factuality in large language models , author=. arXiv preprint arXiv:2411.04368 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Adversarial glue: A multi-task benchmark for robustness evaluation of language models
Adversarial glue: A multi-task benchmark for robustness evaluation of language models , author=. arXiv preprint arXiv:2111.02840 , year=
-
[33]
Skywork Open Reasoner 1 Technical Report
Skywork open reasoner 1 technical report , author=. arXiv preprint arXiv:2505.22312 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
QwQ-32B: Embracing the Power of Reinforcement Learning , url =
Qwen Team , month =. QwQ-32B: Embracing the Power of Reinforcement Learning , url =
-
[36]
gpt-oss-120b & gpt-oss-20b Model Card
gpt-oss-120b & gpt-oss-20b model card , author=. arXiv preprint arXiv:2508.10925 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization , author=. arXiv preprint arXiv:2601.05242 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[39]
A General Language Assistant as a Laboratory for Alignment
A general language assistant as a laboratory for alignment , author=. arXiv preprint arXiv:2112.00861 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Attacks, defenses and evaluations for llm conversation safety: A survey
Attacks, defenses and evaluations for llm conversation safety: A survey , author=. arXiv preprint arXiv:2402.09283 , year=
-
[42]
Self-instruct: Aligning language models with self-generated instructions , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[43]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Proceedings of the IEEE/ACM 46th International Conference on Software Engineering , pages=
Using an llm to help with code understanding , author=. Proceedings of the IEEE/ACM 46th International Conference on Software Engineering , pages=
- [48]
-
[49]
Jailbreaking ChatGPT via Prompt Engineering: An Empirical Study
Jailbreaking chatgpt via prompt engineering: An empirical study , author=. arXiv preprint arXiv:2305.13860 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
How robust is Google’s Bard to adversarial image attacks? arXiv:2309.11751, 2023
How robust is google's bard to adversarial image attacks? , author=. arXiv preprint arXiv:2309.11751 , year=
-
[51]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Jailbreaking prompt attack: A controllable adversarial attack against diffusion models , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
work page 2025
-
[52]
Diagnostic pathology , volume=
Challenges and barriers of using large language models (LLM) such as ChatGPT for diagnostic medicine with a focus on digital pathology--a recent scoping review , author=. Diagnostic pathology , volume=. 2024 , publisher=
work page 2024
-
[53]
Simulating classroom education with llm-empowered agents , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
work page 2025
-
[54]
Safe RLHF: Safe Reinforcement Learning from Human Feedback
Safe rlhf: Safe reinforcement learning from human feedback , author=. arXiv preprint arXiv:2310.12773 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
Advances in Neural Information Processing Systems , volume=
Tree of attacks: Jailbreaking black-box llms automatically , author=. Advances in Neural Information Processing Systems , volume=
-
[56]
DeepInception: Hypnotize Large Language Model to Be Jailbreaker
Deepinception: Hypnotize large language model to be jailbreaker , author=. arXiv preprint arXiv:2311.03191 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
arXiv preprint arXiv:2511.12869 , year=
On the Fundamental Limits of LLMs at Scale , author=. arXiv preprint arXiv:2511.12869 , year=
-
[58]
arXiv preprint arXiv:2505.20259 , year=
Lifelong Safety Alignment for Language Models , author=. arXiv preprint arXiv:2505.20259 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.