AIR: Amortized Image Reconstruction Framework for Self-Supervised Feed-Forward 2D Gaussian Splatting
Pith reviewed 2026-05-21 05:13 UTC · model grok-4.3
The pith
A single trained network predicts 2D Gaussian primitives stage by stage from reconstruction residuals to reconstruct images without any per-image optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
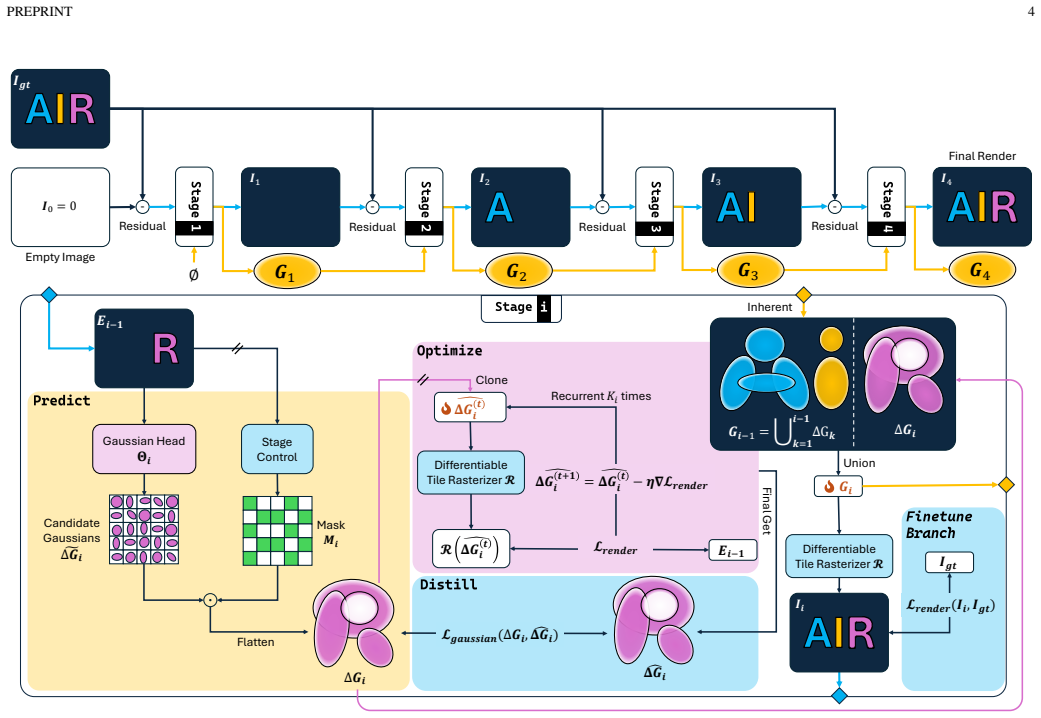
AIR shows that 2D Gaussian splatting for image reconstruction can be fully amortized into a feed-forward network: a stage-wise residual predictor generates additional primitives from the current error map, an explicit Stage Control activates them only in under-reconstructed areas, and a Predict-Optimize-Distill training procedure stabilizes the multi-stage process so that the final model needs no test-time optimization or handcrafted priors.
What carries the argument
Stage-wise residual architecture with explicit Stage Control that activates new Gaussian primitives only in under-reconstructed regions.
If this is right
- Reconstruction quality on Kodak and DIV2K exceeds that of representative Gaussian-based baselines.
- Encoding completes in 160-300 ms without any test-time iteration.
- An image-adaptive quantizer produces compact Gaussian storage after joint fine-tuning across stages.
- The Predict-Optimize-Distill strategy allows stable multi-stage prediction without divergence.
Where Pith is reading between the lines
- The same residual-plus-control pattern could be tried for other explicit scene representations such as 3D Gaussians or point clouds.
- If the stage control generalizes, it removes the need for hand-designed allocation rules in many reconstruction pipelines.
- Real-time image compression or view synthesis systems could adopt the one-pass predictor directly.
Load-bearing premise
A single trained network with stage control can reliably detect and correct under-reconstructed regions in images it has never seen, without any per-image optimization or handcrafted priors.
What would settle it
Run the network on a held-out image set where iterative Gaussian optimization is known to close large residual errors; if the network's final PSNR or visual quality falls measurably short of that iterative baseline while still using only the predicted primitives, the amortization claim is falsified.
Figures








read the original abstract
2D Gaussian splatting provides an efficient explicit representation for image reconstruction, but existing methods still require costly per-image iterative optimization or rely on handcrafted priors for primitive allocation. We present AIR, a self-supervised feed-forward framework that amortizes iterative Gaussian fitting into a single network pass, eliminating per-image test-time optimization. AIR adopts a stage-wise residual architecture that progressively predicts additional Gaussian primitives from reconstruction residuals, together with an explicit Stage Control mechanism that activates new primitives only in under-reconstructed regions. A Predict--Optimize--Distill training strategy stabilizes multi-stage prediction by distilling short-horizon optimized Gaussian increments back into the predictor. The stabilized predictor is then jointly finetuned across stages and equipped with an image-adaptive quantizer for compact Gaussian storage. Experiments on Kodak and DIV2K show that AIR achieves better reconstruction quality than representative Gaussian-based baselines while reducing encoding time to 160--300\,ms. Code: https://github.com/whoiszzj/AIR.git
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AIR, a self-supervised feed-forward framework for 2D Gaussian splatting that amortizes per-image iterative optimization into a single network pass. It uses a stage-wise residual architecture to progressively predict additional Gaussian primitives from reconstruction residuals, an explicit Stage Control mechanism to activate primitives only in under-reconstructed regions, and a Predict-Optimize-Distill training strategy that distills short-horizon optimized increments into the predictor before joint finetuning and image-adaptive quantization. Experiments on Kodak and DIV2K report better reconstruction quality than representative Gaussian baselines with encoding times of 160-300 ms and no test-time per-image optimization.
Significance. If the generalization holds, the work would be significant for enabling practical, fast deployment of explicit Gaussian representations in image reconstruction tasks by removing the per-image optimization bottleneck. Strengths include the self-supervised Predict-Optimize-Distill loop, reproducible code at the provided GitHub link, and the compact storage via quantizer. The result is defensible on the tested datasets but its broader impact depends on confirming reliable transfer of residual decisions to unseen images.
major comments (2)
- [Experiments and Method] The central amortization claim rests on the Stage Control and residual predictor generalizing without per-image optimization; however, the manuscript provides no per-stage residual maps, activation visualizations, or out-of-distribution failure analysis on held-out images to demonstrate that the network reliably locates under-reconstructed regions on novel data (see Experiments section and the Predict-Optimize-Distill description).
- [Experiments] Quantitative gains versus Gaussian baselines are reported, but baseline fairness is unclear without explicit details on whether comparison methods use equivalent total primitive counts, the same optimization horizon, or identical evaluation protocols (see quantitative results on Kodak and DIV2K).
minor comments (2)
- [Abstract] The abstract states the encoding time range but does not clarify whether 160-300 ms is per-image average, worst-case, or includes all stages; adding this would improve clarity.
- [Method] Notation for the image-adaptive quantizer and Stage Control activation threshold could be formalized with an equation to aid exact reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and have revised the manuscript to strengthen the presentation of our amortization claims and experimental details.
read point-by-point responses
-
Referee: [Experiments and Method] The central amortization claim rests on the Stage Control and residual predictor generalizing without per-image optimization; however, the manuscript provides no per-stage residual maps, activation visualizations, or out-of-distribution failure analysis on held-out images to demonstrate that the network reliably locates under-reconstructed regions on novel data (see Experiments section and the Predict-Optimize-Distill description).
Authors: We agree that explicit visualizations would better support the generalization of the residual predictor and Stage Control. In the revised manuscript we have added per-stage residual maps and activation visualizations in the supplementary material. We have also included quantitative results on held-out images from the DIV2K test split demonstrating that the network activates primitives in under-reconstructed regions on unseen data, consistent with the Predict-Optimize-Distill training. These additions directly address the concern while preserving the self-supervised nature of the framework. revision: yes
-
Referee: [Experiments] Quantitative gains versus Gaussian baselines are reported, but baseline fairness is unclear without explicit details on whether comparison methods use equivalent total primitive counts, the same optimization horizon, or identical evaluation protocols (see quantitative results on Kodak and DIV2K).
Authors: We thank the referee for highlighting the need for clearer protocol details. The revised manuscript now specifies that all Gaussian baselines are configured with the same total primitive count as AIR to ensure equivalent storage budgets. The optimization horizon for iterative baselines is aligned with the short-horizon increments used in our distillation stage, and all methods are evaluated with identical metrics (PSNR, SSIM, LPIPS) and the same train/test splits on Kodak and DIV2K. A new table in Section 4 summarizes these settings. revision: yes
Circularity Check
No significant circularity in the amortization derivation.
full rationale
The paper's central claim rests on a Predict-Optimize-Distill loop that generates short-horizon optimization targets on training images to supervise a feed-forward network, followed by joint finetuning and evaluation of reconstruction quality on held-out Kodak and DIV2K images without any test-time optimization. This does not reduce the reported metrics or the Stage Control mechanism to the inputs by construction; the network must learn to generalize residual predictions and primitive allocation to novel images, which is an empirical outcome rather than a definitional equivalence. No self-citations, fitted-input renamings, or uniqueness theorems are invoked in the provided derivation chain to force the result.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of stages and primitives per stage
axioms (1)
- domain assumption A feed-forward network can learn to map image features and residuals to accurate Gaussian primitive increments.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
stage-wise residual Gaussian prediction... explicit Stage Control mechanism that activates new primitives only in under-reconstructed regions
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Predict–Optimize–Distill training strategy... distilling short-horizon optimized Gaussian increments
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Deep learning techniques for inverse problems in imaging,
G. Ongie, A. Jalal, C. A. Metzler, R. G. Baraniuk, A. G. Dimakis, and R. Willett, “Deep learning techniques for inverse problems in imaging,” IEEE Journal on Selected Areas in Information Theory, vol. 1, no. 1, pp. 39–56, 2020
work page 2020
-
[2]
Neural fields in visual computing and beyond,
Y. Xie, T. Takikawa, S. Saito, O. Litany, S. Yan, N. Khan, F. Tombari, J. Tompkin, V. Sitzmann, and S. Sridhar, “Neural fields in visual computing and beyond,” inComputer graphics forum, vol. 41, no. 2. Wiley Online Library, 2022, pp. 641–676
work page 2022
-
[3]
Where do we stand with implicit neural representations? a technical and performance survey,
A. Essakine, Y. Cheng, C.-W. Cheng, L. Zhang, Z. Deng, L. Zhu, C.-B. Sch ¨onlieb, and A. I. Aviles-Rivero, “Where do we stand with implicit neural representations? a technical and performance survey,” arXiv preprint arXiv:2411.03688, 2024
-
[4]
Hypernetwork functional image representation,
S. Klocek, L. Maziarka, M. Wo lczyk, J. Tabor, J. Nowak, and M. ´Smieja, “Hypernetwork functional image representation,” inInternational Con- ference on Artificial Neural Networks. Springer, 2019, pp. 496–510
work page 2019
-
[5]
Implicit neural representations with periodic activation functions,
V. Sitzmann, J. N. P. Martel, A. W. Bergman, D. B. Lindell, and G. Wetzstein, “Implicit neural representations with periodic activation functions,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 7462–7473
work page 2020
-
[6]
Gaussianimage: 1000 fps image representation and compression by 2d gaussian splatting,
X. Zhang, X. Ge, T. Xu, D. He, Y. Wang, H. Qin, G. Lu, J. Geng, and J. Zhang, “Gaussianimage: 1000 fps image representation and compression by 2d gaussian splatting,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 327–345
work page 2024
-
[7]
Image-gs: Content-adaptive image representation via 2d gaussians,
Y. Zhang, B. Li, A. Kuznetsov, A. Jindal, S. Diolatzis, K. Chen, A. Sochenov, A. Kaplanyan, and Q. Sun, “Image-gs: Content-adaptive image representation via 2d gaussians,” inProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Con- ference Conference Papers, 2025, pp. 1–11
work page 2025
-
[8]
L. Zhu, G. Lin, J. Chen, X. Zhang, Z. Jin, Z. Wang, and L. Yu, “Large images are gaussians: High-quality large image representation with levels of 2d gaussian splatting,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 10, 2025, pp. 10 977–10 985
work page 2025
-
[9]
Z. Zeng, Y. Wang, T. Guan, C. Yang, and L. Ju, “Instant gaussianimage: A generalizable and self-adaptive image representation via 2d gaussian splatting,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2025, pp. 27 896–27 905
work page 2025
-
[10]
Tutorial on amortized optimization,
B. Amos, “Tutorial on amortized optimization,”Foundations and Trends in Machine Learning, vol. 16, no. 5, pp. 592–732, 2023
work page 2023
-
[11]
Learning continuous image representation with local implicit image function,
Y. Chen, S. Liu, and X. Wang, “Learning continuous image representation with local implicit image function,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 8628– 8638
work page 2021
-
[12]
Coin: Compression with implicit neural representations,
E. Dupont, A. Goli ´nski, M. Alizadeh, Y. W. Teh, and A. Doucet, “COIN: COmpression with implicit neural representations,”arXiv preprint arXiv:2103.03123, 2021
-
[13]
COIN++: Neural compression across modalities,
E. Dupont, H. Loya, M. Alizadeh, A. Goli ´nski, Y. W. Teh, and A. Doucet, “COIN++: Neural compression across modalities,” Transactions on Machine Learning Research, 2022. [Online]. Available: https://openreview.net/forum?id=NXB0rEM2Tq
work page 2022
-
[14]
Nerf: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,”Communications of the ACM, vol. 65, no. 1, pp. 99–106, 2021
work page 2021
-
[15]
Mip-nerf 360: Unbounded anti-aliased neural radiance fields,
J. T. Barron, B. Mildenhall, D. Verbin, P. P. Srinivasan, and P. Hedman, “Mip-nerf 360: Unbounded anti-aliased neural radiance fields,”CVPR, 2022
work page 2022
-
[16]
Fourier features let networks learn high frequency functions in low dimensional domains,
M. Tancik, P. Srinivasan, B. Mildenhall, S. Fridovich-Keil, N. Raghavan, U. Singhal, R. Ramamoorthi, J. Barron, and R. Ng, “Fourier features let networks learn high frequency functions in low dimensional domains,” Advances in neural information processing systems, vol. 33, pp. 7537– 7547, 2020
work page 2020
-
[17]
Seeing implicit neural repre- sentations as fourier series,
N. Benbarka, T. H ¨ofer, A. Zellet al., “Seeing implicit neural repre- sentations as fourier series,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2022, pp. 2041–2050
work page 2022
-
[18]
Acorn: Adaptive coordinate networks for neural scene representation.arXiv preprint arXiv:2105.02788,
J. N. Martel, D. B. Lindell, C. Z. Lin, E. R. Chan, M. Monteiro, and G. Wetzstein, “Acorn: Adaptive coordinate networks for neural scene representation,”arXiv preprint arXiv:2105.02788, 2021
-
[19]
Instant neural graphics primitives with a multiresolution hash encoding,
T. M¨ uller, A. Evans, C. Schied, and A. Keller, “Instant neural graphics primitives with a multiresolution hash encoding,”ACM Transactions on Graphics, vol. 41, no. 4, pp. 102:1–102:15, 2022
work page 2022
-
[20]
Bacon: Band-limited coordinate networks for multiscale scene representation,
D. B. Lindell, D. Van Veen, J. J. Park, and G. Wetzstein, “Bacon: Band-limited coordinate networks for multiscale scene representation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 16 252–16 262
work page 2022
-
[21]
WIRE: Wavelet implicit neural representations,
V. Saragadam, D. LeJeune, J. Tan, G. Balakrishnan, A. Veeraraghavan, and R. G. Baraniuk, “WIRE: Wavelet implicit neural representations,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 18 507–18 516
work page 2023
-
[22]
Implicit neural representations for image compression,
Y. Str¨ umpler, J. Postels, R. Yang, L. V. Gool, and F. Tombari, “Implicit neural representations for image compression,” inEuropean conference on computer vision. Springer, 2022, pp. 74–91
work page 2022
-
[23]
Meta-learning sparse implicit neural representations,
J. Lee, J. Tack, N. Lee, and J. Shin, “Meta-learning sparse implicit neural representations,”Advances in Neural Information Processing Systems, vol. 34, pp. 11 769–11 780, 2021
work page 2021
-
[24]
Meta-learning sparse compression networks,
J. R. Schwarz and Y. W. Teh, “Meta-learning sparse compression networks,”arXiv preprint arXiv:2205.08957, 2022
-
[25]
3d gaussian splatting for real-time radiance field rendering,
B. Kerbl, G. Kopanas, T. Leimk¨ uhler, and G. Drettakis, “3d gaussian splatting for real-time radiance field rendering,” inACM SIGGRAPH 2023 Conference Proceedings, 2023, pp. 1–14
work page 2023
-
[26]
Structure-guided allocation of 2d gaussians for image representation and compression,
H. Liang, Y. Chen, Y. Pan, S. Wang, J. Dai, G. Lu, and W. Zhang, “Structure-guided allocation of 2d gaussians for image representation and compression,”arXiv preprint arXiv:2512.24018, 2025
-
[27]
Gaussianimage++: Boosted image representation and compression with 2d gaussian splatting,
T. Li, X. Zhang, X. Ge, T. Xu, D. He, J. Zhang, and Y. Wang, “Gaussianimage++: Boosted image representation and compression with 2d gaussian splatting,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 8, 2026, pp. 6442–6449
work page 2026
-
[28]
Iterative amortized inference,
J. Marino, Y. Yue, and S. Mandt, “Iterative amortized inference,” in Proceedings of the 35th International Conference on Machine Learning, 2018, pp. 3403–3412
work page 2018
-
[29]
Learned primal-dual reconstruction,
J. Adler and O. ¨Oktem, “Learned primal-dual reconstruction,”IEEE Transactions on Medical Imaging, vol. 37, no. 6, pp. 1322–1332, 2018
work page 2018
-
[30]
Recurrent inference machines for solving inverse problems,
P. Putzky and M. Welling, “Recurrent inference machines for solving inverse problems,” inWorkshop Track of the International Conference on Learning Representations, 2017
work page 2017
-
[31]
Resplat: Learning recurrent gaussian splatting,
H. Xu, D. Barath, A. Geiger, and M. Pollefeys, “Resplat: Learning recurrent gaussian splatting,”arXiv preprint arXiv:2510.08575, 2025
-
[32]
Gifsplat: Generative prior-guided iterative feed-forward 3d gaussian splatting from sparse views,
T. Chen, W. Xiang, K. Han, Y. Lu, D. Wu, G. Liu, and R. R. Kompella, “Gifsplat: Generative prior-guided iterative feed-forward 3d gaussian splatting from sparse views,”arXiv preprint arXiv:2602.22571, 2026
-
[33]
Predict-optimize-distill: A self-improving cycle for 4d object under- standing,
M. Wu, H. Huang, J. Kerr, C. M. Kim, A. Zhang, B. Yi, and A. Kanazawa, “Predict-optimize-distill: A self-improving cycle for 4d object under- standing,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 6575–6584
work page 2025
-
[34]
Stochastic floyd-steinberg dithering on gpu: image quality and processing time improved,
G. Franchini, R. Cavicchioli, and J. C. Hu, “Stochastic floyd-steinberg dithering on gpu: image quality and processing time improved,” in2019 Fifth International Conference on Image Information Processing (ICIIP). IEEE, 2019, pp. 1–6
work page 2019
-
[35]
Computing the n-dimensional delaunay tessellation with application to voronoi polytopes,
D. F. Watson, “Computing the n-dimensional delaunay tessellation with application to voronoi polytopes,”The Computer Journal, vol. 24, no. 2, pp. 167–172, 1981
work page 1981
-
[36]
Variable-rate deep image compression through spatially-adaptive feature transform,
M. Song, J. Choi, and B. Han, “Variable-rate deep image compression through spatially-adaptive feature transform,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 2380– 2389
work page 2021
-
[37]
Spatially adaptive image compression using a tiled deep network,
D. Minnen, G. Toderici, M. Covell, T. Chinen, N. Johnston, J. Shor, S. J. Hwang, D. Vincent, and S. Singh, “Spatially adaptive image compression using a tiled deep network,” in2017 IEEE International Conference on Image Processing (ICIP). IEEE, 2017, pp. 2796–2800
work page 2017
-
[38]
Spatially adaptive computation time for residual networks,
M. Figurnov, M. D. Collins, Y. Zhu, L. Zhang, J. Huang, D. Vetrov, and R. Salakhutdinov, “Spatially adaptive computation time for residual networks,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1039–1048
work page 2017
-
[39]
Image quality assessment: from error visibility to structural similarity,
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,”IEEE transactions on image processing, vol. 13, no. 4, pp. 600–612, 2004
work page 2004
-
[40]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[41]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Y. Bengio, N. L ´eonard, and A. Courville, “Estimating or propagating gradients through stochastic neurons for conditional computation,”arXiv preprint arXiv:1308.3432, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[42]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255
work page 2009
-
[43]
Ntire 2017 challenge on single image super- resolution: Dataset and study,
E. Agustsson and R. Timofte, “Ntire 2017 challenge on single image super- resolution: Dataset and study,” inProceedings of the IEEE conference on computer vision and pattern recognition workshops, 2017, pp. 126–135
work page 2017
-
[44]
Multiscale structural similarity for image quality assessment,
Z. Wang, E. P. Simoncelli, and A. C. Bovik, “Multiscale structural similarity for image quality assessment,” inThe thrity-seventh asilomar PREPRINT 13 conference on signals, systems & computers, 2003, vol. 2. Ieee, 2003, pp. 1398–1402
work page 2003
-
[45]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 586–595
work page 2018
-
[46]
Very Deep Convolutional Networks for Large-Scale Image Recognition
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,”arXiv preprint arXiv:1409.1556, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[47]
O. Sim ´eoni, H. V. Vo, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V. Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoaet al., “Dinov3,” arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
R. Wang, S. Xu, C. Dai, J. Xiang, Y. Deng, X. Tong, and J. Yang, “Moge: Unlocking accurate monocular geometry estimation for open- domain images with optimal training supervision,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 5261– 5271
work page 2025
-
[49]
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
R. Wang, S. Xu, Y. Dong, Y. Deng, J. Xiang, Z. Lv, G. Sun, X. Tong, and J. Yang, “Moge-2: Accurate monocular geometry with metric scale and sharp details,” 2025. [Online]. Available: https://arxiv.org/abs/2507.02546
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[51]
H. Abdi and L. J. Williams, “Principal component analysis,”Wiley interdisciplinary reviews: computational statistics, vol. 2, no. 4, pp. 433– 459, 2010
work page 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.