Jointly Learning Predicates and Actions Enables Zero-Shot Skill Composition
Pith reviewed 2026-05-21 05:07 UTC · model grok-4.3
The pith
Jointly generating actions and predicates in one model enables robots to compose learned skills zero-shot.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PACTS models skills as a joint generative process over action and predicate belief trajectories, producing coherent action-outcome rollouts inside a single policy. Joint generation improves both action accuracy and predicate classification through shared representations. These predicate predictions function as a reliable symbolic layer for sequencing and monitoring execution, which enables zero-shot composition of previously learned skills via planning.
What carries the argument
Predicate Action Skills (PACTS), closed-loop visuomotor policies that jointly generate action trajectories and predicate belief trajectories to link continuous control with symbolic outcomes.
If this is right
- Skills learned independently can be sequenced into new tasks through planning without retraining the policy.
- The joint model produces more accurate action generation and more reliable predicate classification than separate models.
- Online predicate predictions provide a symbolic interface that sequences and monitors skill execution in real time.
- Zero-shot generalization to unseen skill combinations becomes possible for visuomotor policies.
Where Pith is reading between the lines
- This joint modeling could reduce reliance on task-specific retraining by supporting modular reuse of skills across longer horizons.
- The approach points toward hybrid systems that combine learned continuous policies with classical symbolic planners.
- Evaluating the method on tasks with sensor noise or partial observability would test whether the shared representations stay robust.
Load-bearing premise
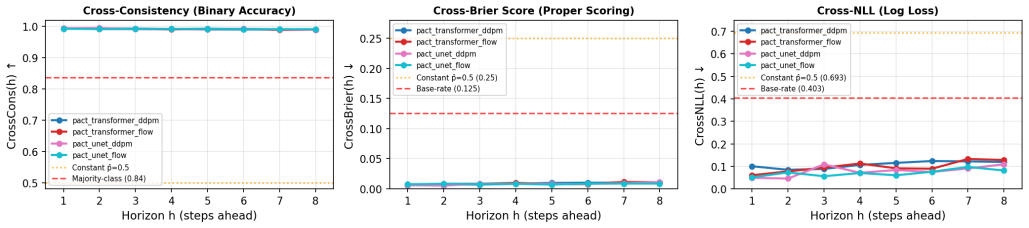
The online predicate predictions must remain accurate and stable enough during execution to serve as a reliable symbolic interface for planning and monitoring without accumulating errors.
What would settle it
Execute a novel sequence of composed skills on a robot and check whether the model's predicate predictions match actual state changes at each step without drift or failure.
Figures


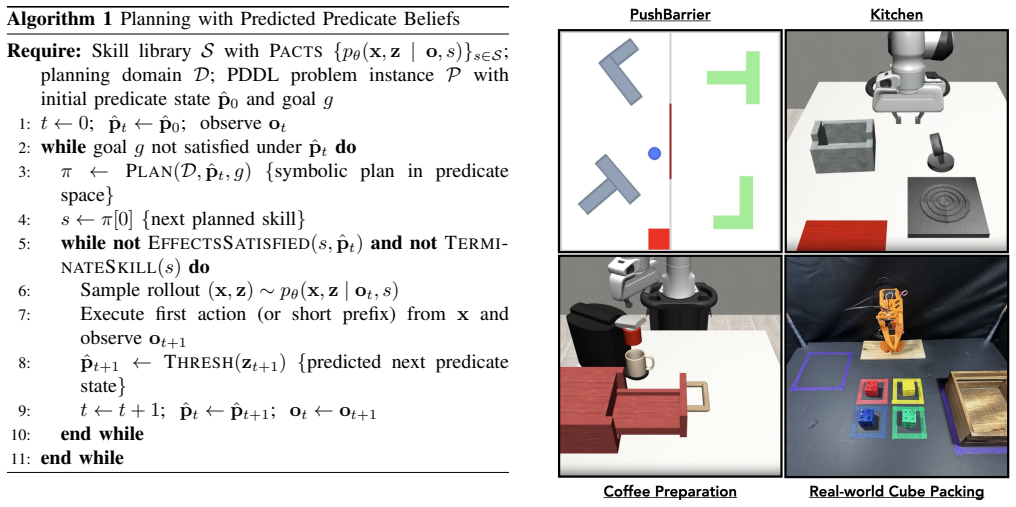

read the original abstract
Learning from Demonstration (LfD) enables robots to learn complex behaviors from expert examples, yet existing approaches often fail to generalize to new compositions of known skills without retraining. Modern generative policies model distributions over action trajectories alone, thus are unable to reason about the symbolic outcomes required for robust composition. We propose that skills should jointly model action trajectories and the symbolic outcomes they induce. To address this gap, we introduce Predicate Action Skills (PACTS), a class of closed-loop visuomotor policies that model skills as a joint generative process over action and predicate belief trajectories, producing coherent action-outcome rollouts within a single model. Jointly generating actions and predicates enables PACTS to learn internal representations that improve both action generation and predicate classification. Furthermore, we demonstrate zero-shot composition of learned skills via planning by leveraging online predicate predictions from PACTS as a symbolic interface for sequencing and monitoring execution. Project website: https://planpacts.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Predicate Action Skills (PACTS), a class of closed-loop visuomotor policies that model skills as a joint generative process over action trajectories and predicate belief trajectories. The central claims are that this joint modeling improves internal representations for both action generation and predicate classification, and that the resulting online predicate predictions can serve as a reliable symbolic interface for zero-shot skill composition via planning and execution monitoring.
Significance. If the empirical results hold and demonstrate stable predicate predictions sufficient for multi-step planning, the work would offer a concrete advance in bridging continuous visuomotor control with symbolic reasoning in learning from demonstration, enabling generalization to novel skill compositions without retraining.
major comments (2)
- [Abstract] Abstract: the claim that 'online predicate predictions from PACTS' enable reliable sequencing and monitoring for zero-shot composition is load-bearing, yet the description provides no quantitative evaluation of predicate accuracy, drift, or accumulation of errors over execution horizons under partial observability or visual noise; this directly affects whether the symbolic interface functions as asserted.
- [Experiments / Planning Interface] The weakest assumption identified in the stress-test (stability of predicate beliefs during closed-loop execution) is not addressed with dedicated experiments or analysis showing that joint training prevents compounding errors; without such evidence the planning results cannot be attributed to the joint model rather than to favorable test conditions.
minor comments (1)
- [Abstract] Abstract: include at least one key quantitative result (e.g., predicate classification accuracy or composition success rate versus baselines) to ground the claims.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We appreciate the emphasis on rigorously validating the stability of predicate predictions for reliable symbolic planning. We address each major comment below, clarifying the evidence already present and outlining planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'online predicate predictions from PACTS' enable reliable sequencing and monitoring for zero-shot composition is load-bearing, yet the description provides no quantitative evaluation of predicate accuracy, drift, or accumulation of errors over execution horizons under partial observability or visual noise; this directly affects whether the symbolic interface functions as asserted.
Authors: We agree that the abstract would benefit from referencing quantitative support for predicate stability to make the central claim more concrete. The full manuscript already reports predicate classification accuracies (Table 1) and closed-loop planning success rates over multi-step compositions (Section 5.2 and Figure 6), which rely on online predicate predictions during execution. These results were obtained under visual noise and partial observability in the simulated environments. To directly address the concern, we will revise the abstract to briefly note the predicate accuracy metrics and add a new analysis subsection (or supplementary figure) quantifying predicate belief drift and error accumulation over execution horizons. revision: yes
-
Referee: [Experiments / Planning Interface] The weakest assumption identified in the stress-test (stability of predicate beliefs during closed-loop execution) is not addressed with dedicated experiments or analysis showing that joint training prevents compounding errors; without such evidence the planning results cannot be attributed to the joint model rather than to favorable test conditions.
Authors: We acknowledge that the current experiments focus on end-to-end planning success rather than isolating predicate stability as a function of joint versus separate training. The manuscript does compare PACTS against non-joint baselines on composed tasks, with higher success rates for PACTS (Table 2), but does not include a dedicated ablation on compounding predicate errors. We will add a targeted analysis in the revised experiments section measuring predicate prediction consistency and drift over time for the joint model versus decoupled action/predicate models, directly testing whether joint training mitigates error accumulation under the stress-test conditions. revision: yes
Circularity Check
No circularity; empirical claims rest on experimental validation without self-referential reductions
full rationale
The paper introduces PACTS as a class of closed-loop visuomotor policies that jointly model action trajectories and predicate belief trajectories. The central claims—that joint generation improves internal representations for both action generation and predicate classification, and enables zero-shot skill composition via planning—are presented as empirical outcomes of this modeling choice rather than as derivations from first principles or fitted parameters. No equations, uniqueness theorems, ansatzes, or self-citations are invoked in the abstract or described structure to create a load-bearing reduction where a result is equivalent to its inputs by construction. The approach is self-contained against external benchmarks through experimental demonstration of the joint model, with no evidence of self-definitional loops or renamed known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On the necessity of abstraction,
G. Konidaris, “On the necessity of abstraction,”Current Opinion in Behavioral Sciences, vol. 29, pp. 1–7, 2019, artificial Intelligence. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ S2352154618302080
work page 2019
-
[2]
Integrated task and motion planning,
C. R. Garrett, R. Chitnis, R. Holladay, B. Kim, T. Silver, L. P. Kaelbling, and T. Lozano-P ´erez, “Integrated task and motion planning,”
-
[3]
Available: https://arxiv.org/abs/2010.01083
[Online]. Available: https://arxiv.org/abs/2010.01083
-
[4]
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Mart ´ın-Mart´ın, “What matters in learning from offline human demonstrations for robot manipulation,” inarXiv preprint arXiv:2108.03298, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Mimicgen: A data generation system for scalable robot learning using human demonstrations,
A. Mandlekar, S. Nasiriany, B. Wen, I. Akinola, Y . Narang, L. Fan, Y . Zhu, and D. Fox, “Mimicgen: A data generation system for scalable robot learning using human demonstrations,” in7th Annual Conference on Robot Learning, 2023
work page 2023
-
[6]
Behavioral Cloning from Observation
F. Torabi, G. Warnell, and P. Stone, “Behavioral cloning from observation,” 2018. [Online]. Available: https://arxiv.org/abs/1805.01954
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,” 2024. [Online]. Available: https://arxiv.org/abs/2303.04137
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Learning robotic manipulation policies from point clouds with conditional flow matching,
E. Chisari, N. Heppert, M. Argus, T. Welschehold, T. Brox, and A. Valada, “Learning robotic manipulation policies from point clouds with conditional flow matching,”Conference on Robot Learning (CoRL), 2024
work page 2024
-
[9]
Vision-language models for vision tasks: A survey,
J. Zhang, J. Huang, S. Jin, and S. Lu, “Vision-language models for vision tasks: A survey,” 2024. [Online]. Available: https: //arxiv.org/abs/2304.00685
-
[10]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky, “π 0: A vision-language-action flow model for general robot control,” 2024. [Online]. Availabl...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
D. Wang, S. Hart, D. Surovik, T. Kelestemur, H. Huang, H. Zhao, M. Yeatman, J. Wang, R. Walters, and R. Platt, “Equivariant diffusion policy,” 2024. [Online]. Available: https://arxiv.org/abs/2407.01812
-
[12]
Sornet: Spatial object- centric representations for sequential manipulation,
W. Yuan, C. Paxton, K. Desingh, and D. Fox, “Sornet: Spatial object- centric representations for sequential manipulation,” 2022. [Online]. Available: https://arxiv.org/abs/2109.03891
-
[13]
K. Rana, J. Abou-Chakra, S. Garg, R. Lee, I. Reid, and N. Suenderhauf, “Affordance-centric policy learning: Sample efficient and generalisable robot policy learning using affordance-centric task frames,” 2024. [Online]. Available: https://arxiv.org/abs/2410.12124
-
[14]
Planning with Diffusion for Flexible Behavior Synthesis
M. Janner, Y . Du, J. B. Tenenbaum, and S. Levine, “Planning with diffu- sion for flexible behavior synthesis,”arXiv preprint arXiv:2205.09991, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
M. Ghallab, D. Nau, and P. Traverso,Automated planning and acting. Cambridge University Press, 2016
work page 2016
-
[16]
Pddl - the planning domain definition language,
M. Ghallab, C. Knoblock, D. Wilkins, A. Barrett, D. Christianson, M. Friedman, C. Kwok, K. Golden, S. Penberthy, D. Smith, Y . Sun, and D. Weld, “Pddl - the planning domain definition language,” 08 1998
work page 1998
-
[17]
Statecharts: a visual formalism for complex systems,
D. Harel, “Statecharts: a visual formalism for complex systems,” Science of Computer Programming, vol. 8, no. 3, pp. 231–274, 1987. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ 0167642387900359
work page 1987
-
[18]
Behavior trees in robotics and ai,
M. Colledanchise and P. ¨Ogren, “Behavior trees in robotics and ai,” Jul
-
[19]
[Online]. Available: http://dx.doi.org/10.1201/9780429489105
-
[20]
Symbolic state estimation with predicates for contact-rich manipulation tasks,
T. Migimatsu, W. Lian, J. Bohg, and S. Schaal, “Symbolic state estimation with predicates for contact-rich manipulation tasks,” 2022. [Online]. Available: https://arxiv.org/abs/2203.02468
-
[21]
Skillman — a skill-based robotic manipulation framework based on perception and reasoning,
M. Diab, M. Pomarlan, D. Beßler, A. Akbari, J. Rosell, J. Bateman, and M. Beetz, “Skillman — a skill-based robotic manipulation framework based on perception and reasoning,”Robotics and Autonomous Systems, vol. 134, p. 103653, 2020. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0921889020304930
work page 2020
-
[22]
Plansys2: A planning system framework for ros2,
F. Mart ´ın, J. Gin ´es, V . Matell ´an, and F. J. Rodr ´ıguez, “Plansys2: A planning system framework for ros2,” 2021. [Online]. Available: https://arxiv.org/abs/2107.00376
-
[23]
Skiros2: A skill-based robot control platform for ros,
M. Mayr, F. Rovida, and V . Krueger, “Skiros2: A skill-based robot control platform for ros,” 2023. [Online]. Available: https: //arxiv.org/abs/2306.17030
-
[24]
Bootstrapping object-level planning with large language models,
D. Paulius, A. Agostini, B. Quartey, and G. Konidaris, “Bootstrapping object-level planning with large language models,” in2025 IEEE Inter- national Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 16 233–16 239
work page 2025
-
[25]
Verifiably following complex robot instructions with foundation models,
B. Quartey, E. Rosen, S. Tellex, and G. Konidaris, “Verifiably following complex robot instructions with foundation models,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 1–8
work page 2025
-
[26]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in neural information processing systems, vol. 33, pp. 6840– 6851, 2020
work page 2020
-
[27]
Improving and generalizing flow-based generative models with minibatch optimal transport
A. Tong, K. Fatras, N. Malkin, G. Huguet, Y . Zhang, J. Rector-Brooks, G. Wolf, and Y . Bengio, “Improving and generalizing flow-based generative models with minibatch optimal transport,”arXiv preprint arXiv:2302.00482, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,”arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
Lerobot: State-of-the-art machine learning for real-world robotics in pytorch,
R. Cadene, S. Alibert, A. Soare, Q. Gallouedec, A. Zouitine, S. Palma, P. Kooijmans, M. Aractingi, M. Shukor, D. Aubakirova, M. Russi, F. Capuano, C. Pascal, J. Choghari, J. Moss, and T. Wolf, “Lerobot: State-of-the-art machine learning for real-world robotics in pytorch,” https://github.com/huggingface/lerobot, 2024
work page 2024
-
[30]
From pixels to predicates: Learning symbolic world models via pretrained vlms,
A. Athalye, N. Kumar, T. Silver, Y . Liang, J. Wang, T. Lozano-P´erez, and L. P. Kaelbling, “From pixels to predicates: Learning symbolic world models via pretrained vlms,”IEEE Robotics and Automation Letters, 2026
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.